Download as PPTX










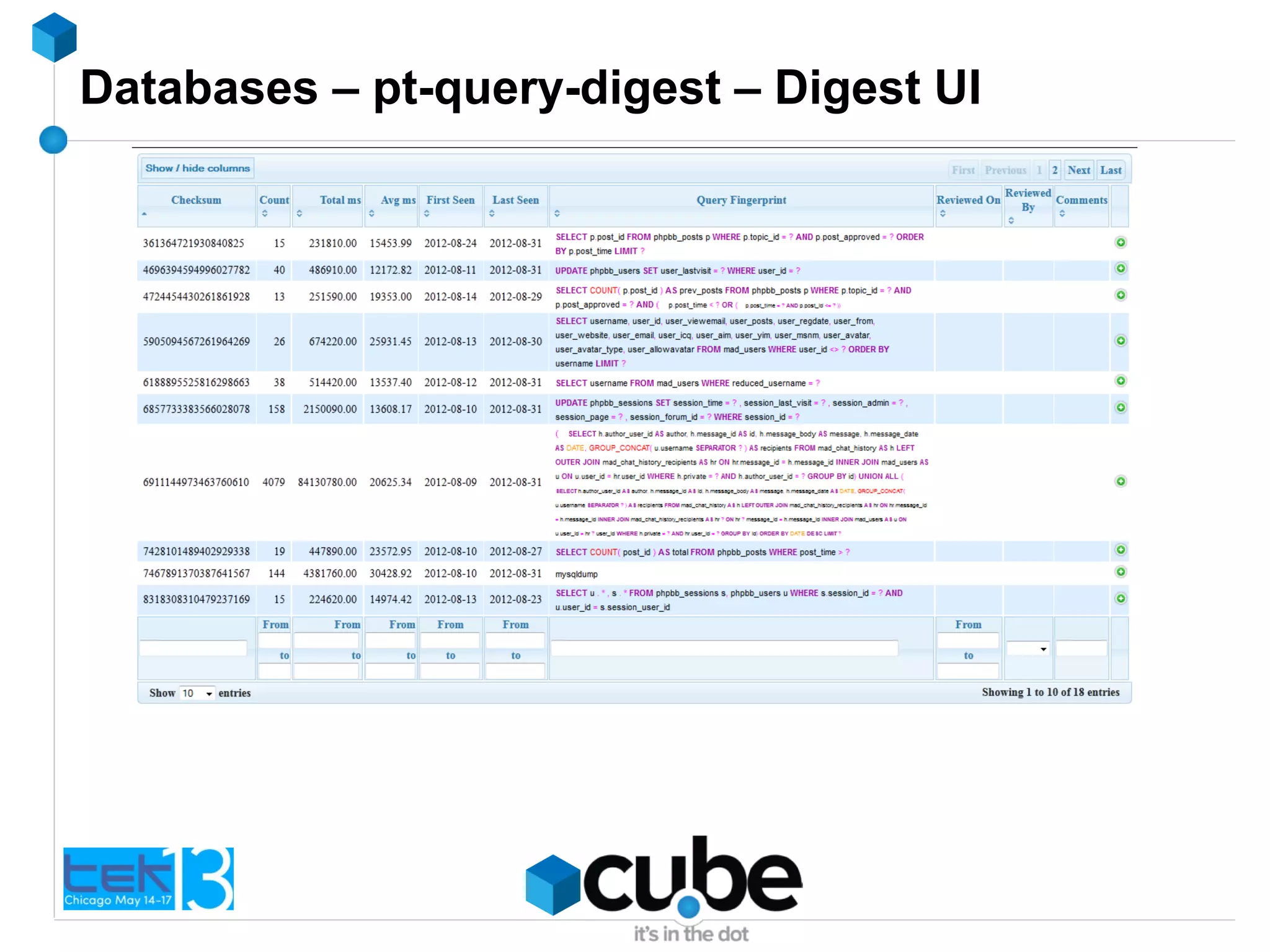
![Databases - pt-query-digest
# Query 2: 0.26 QPS, 0.00x concurrency, ID 0x92F3B1B361FB0E5B at byte 14081299
# This item is included in the report because it matches --limit.
# Scores: Apdex = 1.00 [1.0], V/M = 0.00
# Query_time sparkline: | _^ |
# Time range: 2011-12-28 18:42:47 to 19:03:10
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 1 312
# Exec time 50 4s 5ms 25ms 13ms 20ms 4ms 12ms
# Lock time 3 32ms 43us 163us 103us 131us 19us 98us
# Rows sent 59 62.41k 203 231 204.82 202.40 3.99 202.40
# Rows examine 13 73.63k 238 296 241.67 246.02 10.15 234.30
# Rows affecte 0 0 0 0 0 0 0 0
# Rows read 59 62.41k 203 231 204.82 202.40 3.99 202.40
# Bytes sent 53 24.85M 46.52k 84.36k 81.56k 83.83k 7.31k 79.83k
# Merge passes 0 0 0 0 0 0 0 0
# Tmp tables 0 0 0 0 0 0 0 0
# Tmp disk tbl 0 0 0 0 0 0 0 0
# Tmp tbl size 0 0 0 0 0 0 0 0
# Query size 0 21.63k 71 71 71 71 0 71
# InnoDB:
# IO r bytes 0 0 0 0 0 0 0 0
# IO r ops 0 0 0 0 0 0 0 0
# IO r wait 0 0 0 0 0 0 0 0
# pages distin 40 11.77k 34 44 38.62 38.53 1.87 38.53
# queue wait 0 0 0 0 0 0 0 0
# rec lock wai 0 0 0 0 0 0 0 0
# Boolean:
# Full scan 100% yes, 0% no
# String:
# Databases wp_blog_one (264/84%), wp_blog_tw… (36/11%)... 1 more
# Hosts
# InnoDB trxID 86B40B (1/0%), 86B430 (1/0%), 86B44A (1/0%)... 309 more
# Last errno 0
# Users wp_blog_one (264/84%), wp_blog_two (36/11%)... 1 more
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms ################################################################
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `wp_blog_one ` LIKE 'wp_options'G
# SHOW CREATE TABLE `wp_blog_one `.`wp_options`G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT option_name, option_value FROM wp_options WHERE autoload = 'yes'G](https://image.slidesharecdn.com/beyondphp-130515171515-phpapp01/75/Beyond-PHP-it-s-not-just-about-the-code-12-2048.jpg)









![Client X : the code
foreach ($jobs as $job) {
$db->query("
insert into shown_today(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_week(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_month(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_user(
jobId,
userId,
when
) values (
" . $job['id'] . ",
" . $user['id'] . ",
now()
)
");
}](https://image.slidesharecdn.com/beyondphp-130515171515-phpapp01/75/Beyond-PHP-it-s-not-just-about-the-code-24-2048.jpg)



![Client X : fix ?
foreach ($jobs as $job) {
$db->query("
insert into shown_today(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_week(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_month(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_user(
jobId,
userId,
when
) values (
" . $job['id'] . ",
" . $user['id'] . ",
now()
)
");
}](https://image.slidesharecdn.com/beyondphp-130515171515-phpapp01/75/Beyond-PHP-it-s-not-just-about-the-code-33-2048.jpg)
![Client X : the code change
$todayQuery = "
insert into shown_today(
jobId,
number
) values ";
foreach ($jobs as $job) {
$todayQuery .= "(" . $job['id'] . ", 1),";
}
$todayQuery = substr($todayQuery, -1);
$todayQuery .= "
)
on duplicate key
update
number = number + 1
";
$db->query($todayQuery);
Careful : max_allowed_packet !
Result : insert into shown_today values (5, 1), (8, 1), (12, 1), (18, 1), ...](https://image.slidesharecdn.com/beyondphp-130515171515-phpapp01/75/Beyond-PHP-it-s-not-just-about-the-code-34-2048.jpg)
![Client X : the chosen solution
$db->autocommit(false);
foreach ($jobs as $job) {
$db->query("
insert into shown_today(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_week(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_month(
jobId,
number
) values(
" . $job['id'] . ",
1
)
on duplicate key
update
number = number + 1
");
$db->query("
insert into shown_user(
jobId,
userId,
when
) values (
" . $job['id'] . ",
" . $user['id'] . ",
now()
)
");
}
$db->commit();](https://image.slidesharecdn.com/beyondphp-130515171515-phpapp01/75/Beyond-PHP-it-s-not-just-about-the-code-35-2048.jpg)


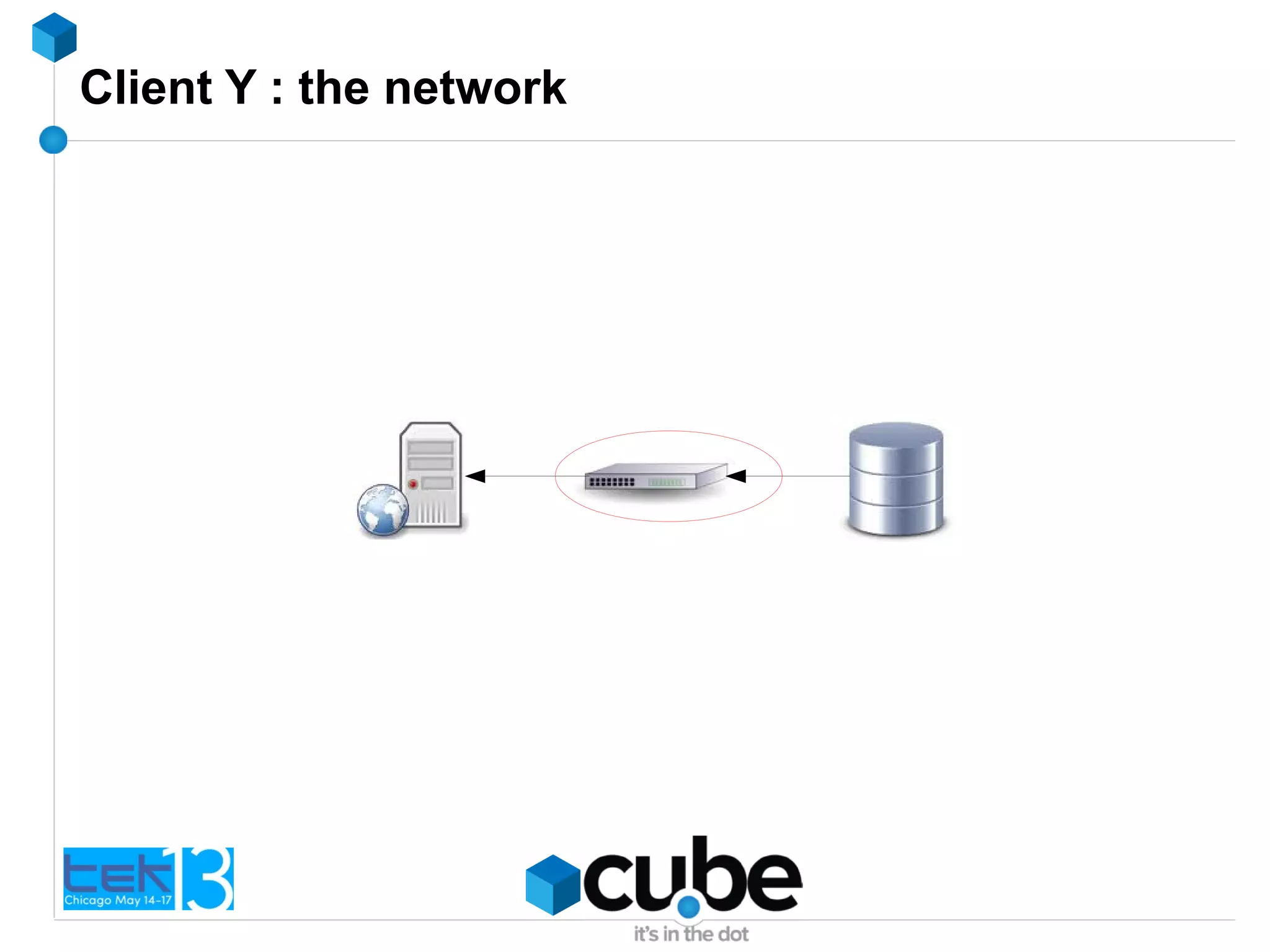
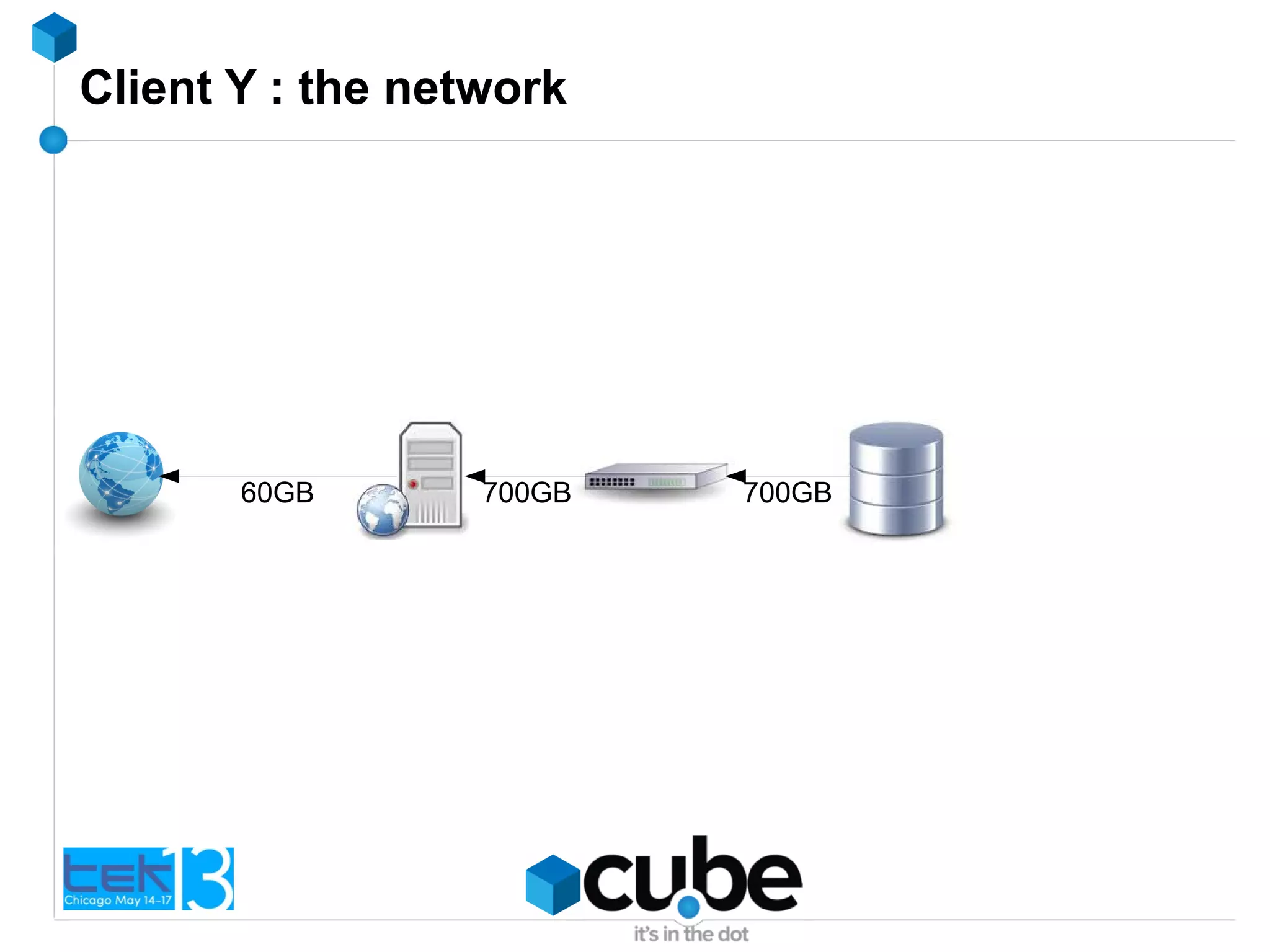



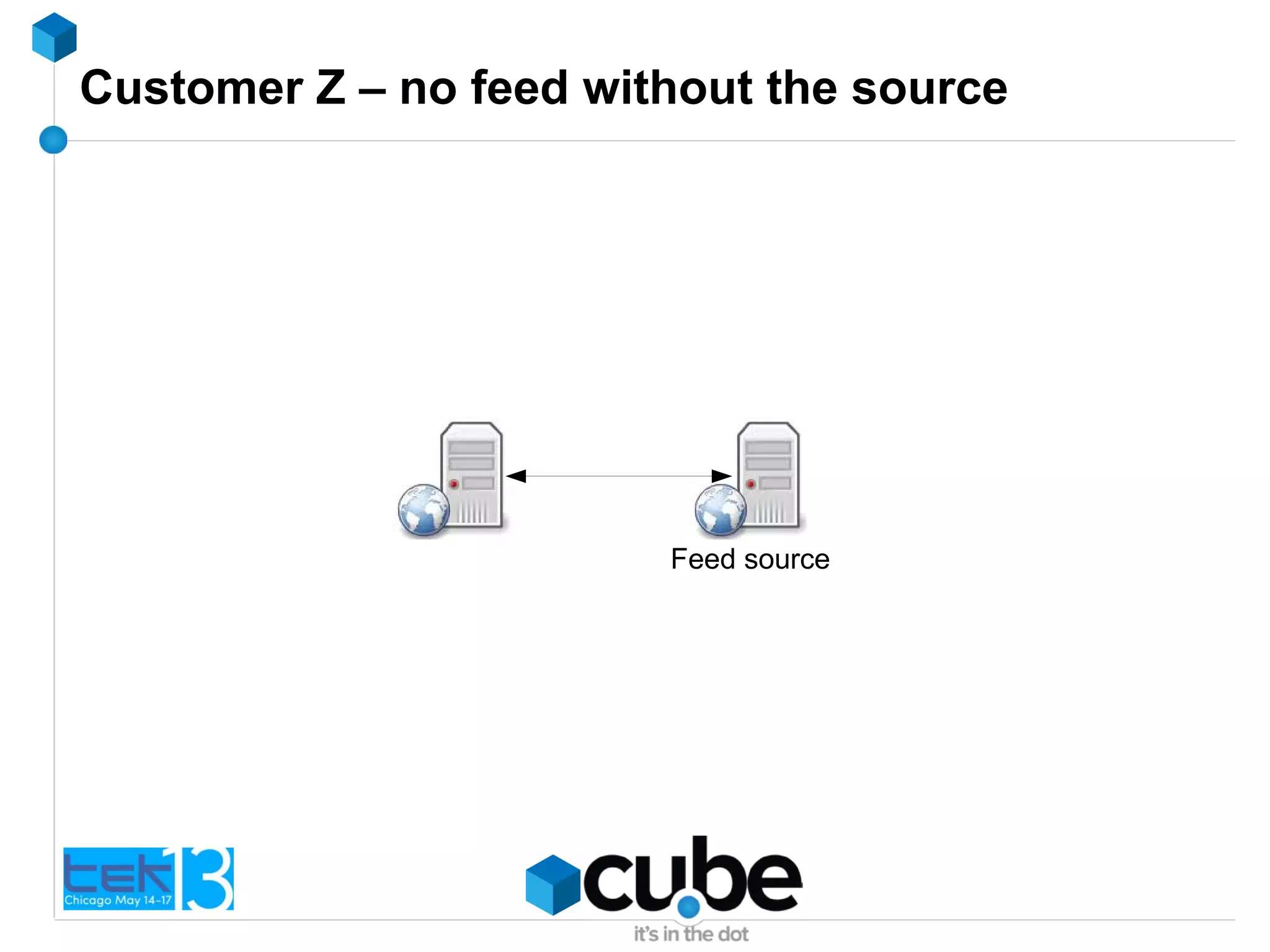
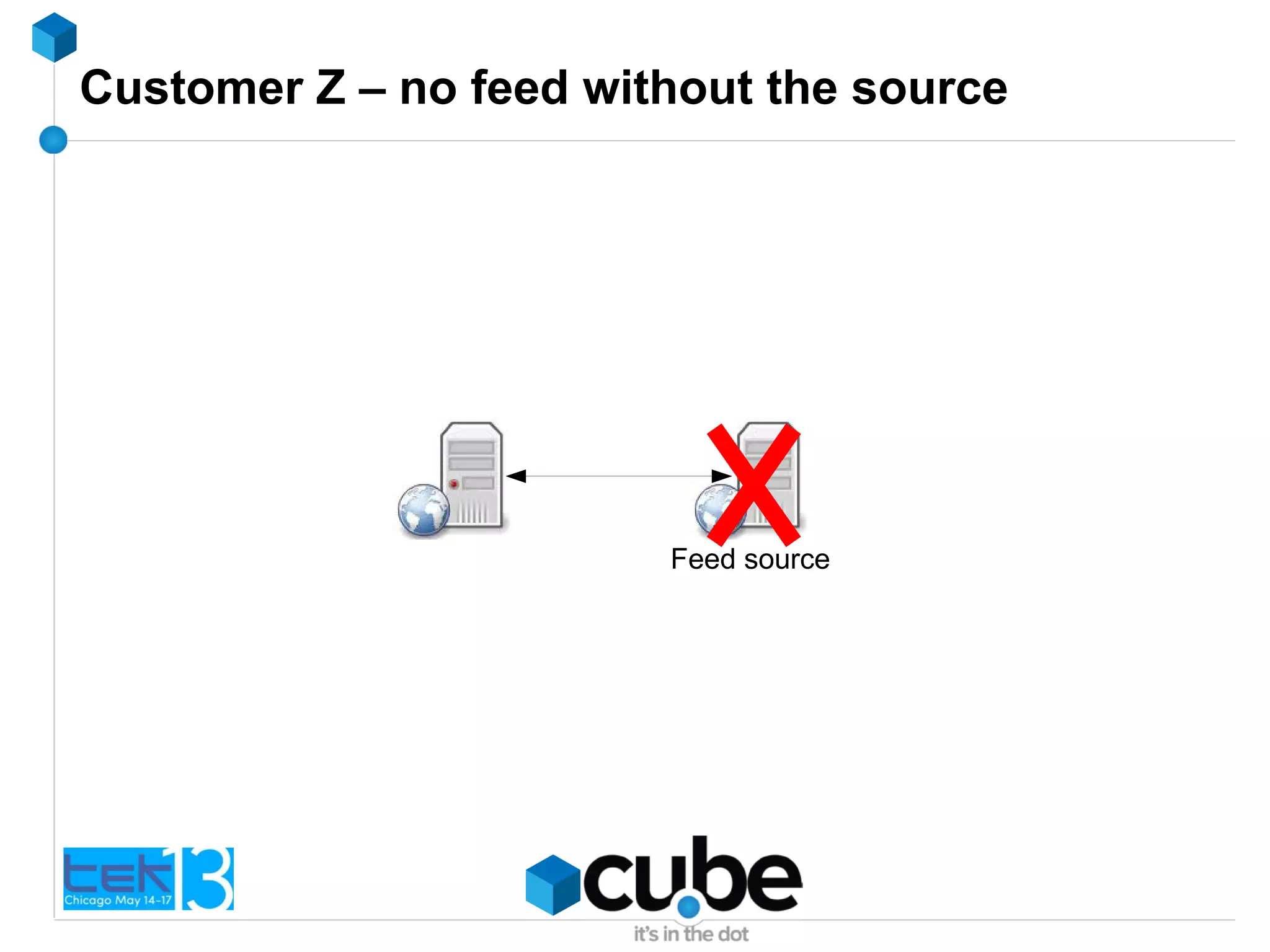







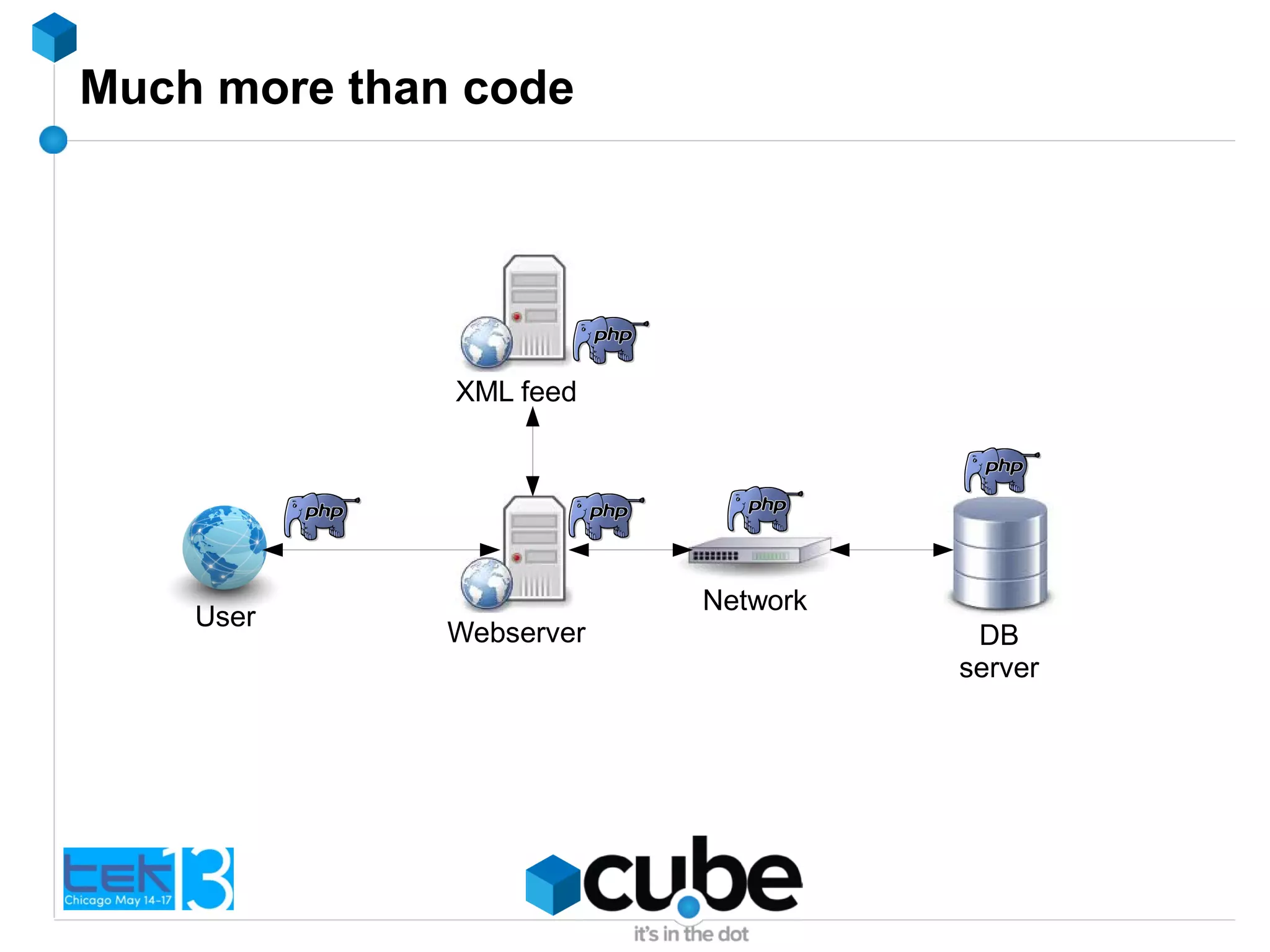





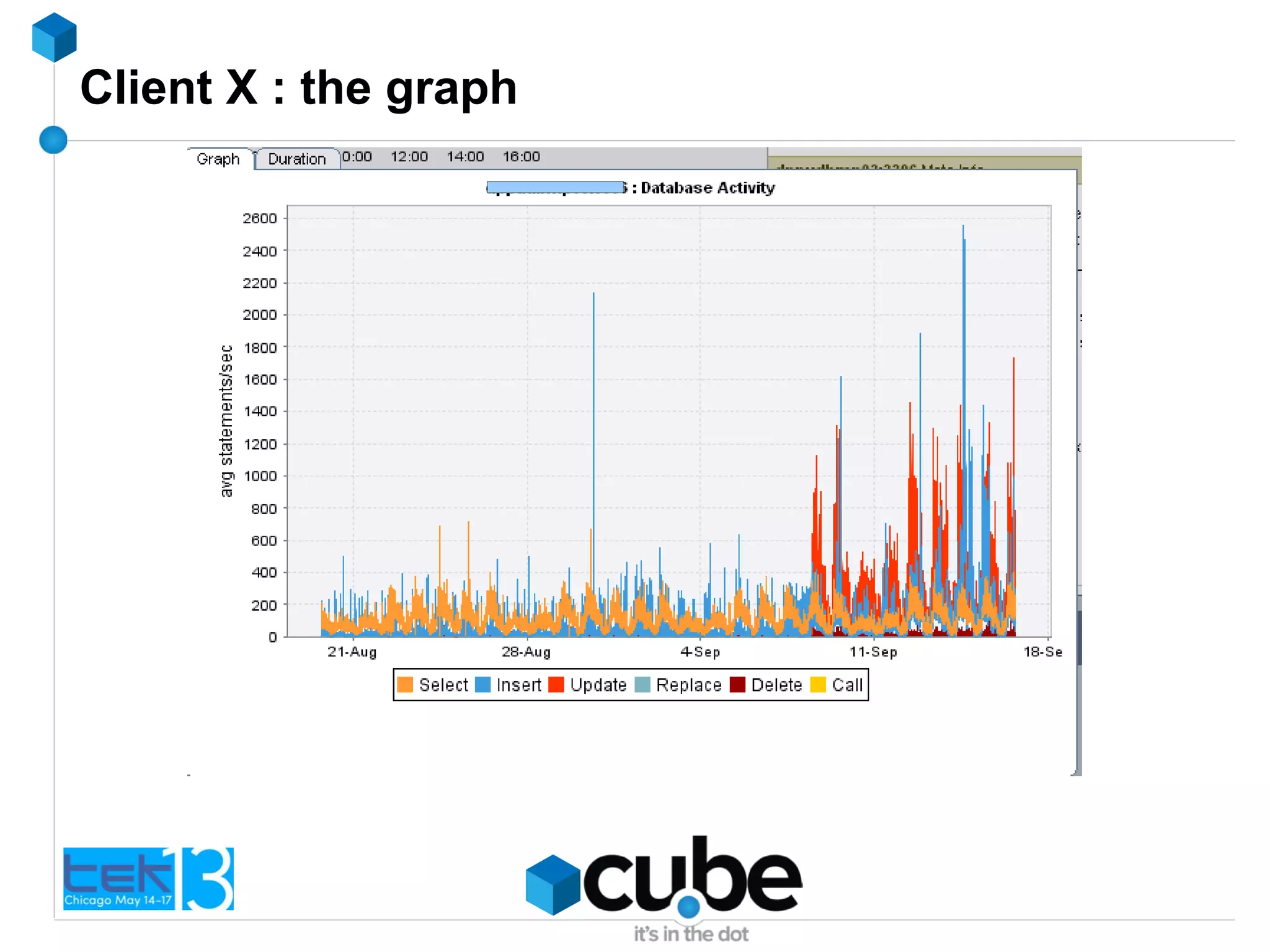
The document discusses the importance of optimizing PHP and MySQL code for efficiency and scalability, highlighting common mistakes and best practices. It emphasizes the significance of database indexing, query optimization, and the implications of poor coding on performance. The author shares real-world examples of issues encountered and solutions implemented in client projects to enhance application performance.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












