Download as ODP, PPTX
![Get involved with the Apache Software Foundation Shalin Shekhar Mangar shalin [at] apache [dot] org](https://image.slidesharecdn.com/apacheopensource21-oct-2009-091026142333-phpapp01/75/Get-involved-with-the-Apache-Software-Foundation-1-2048.jpg)
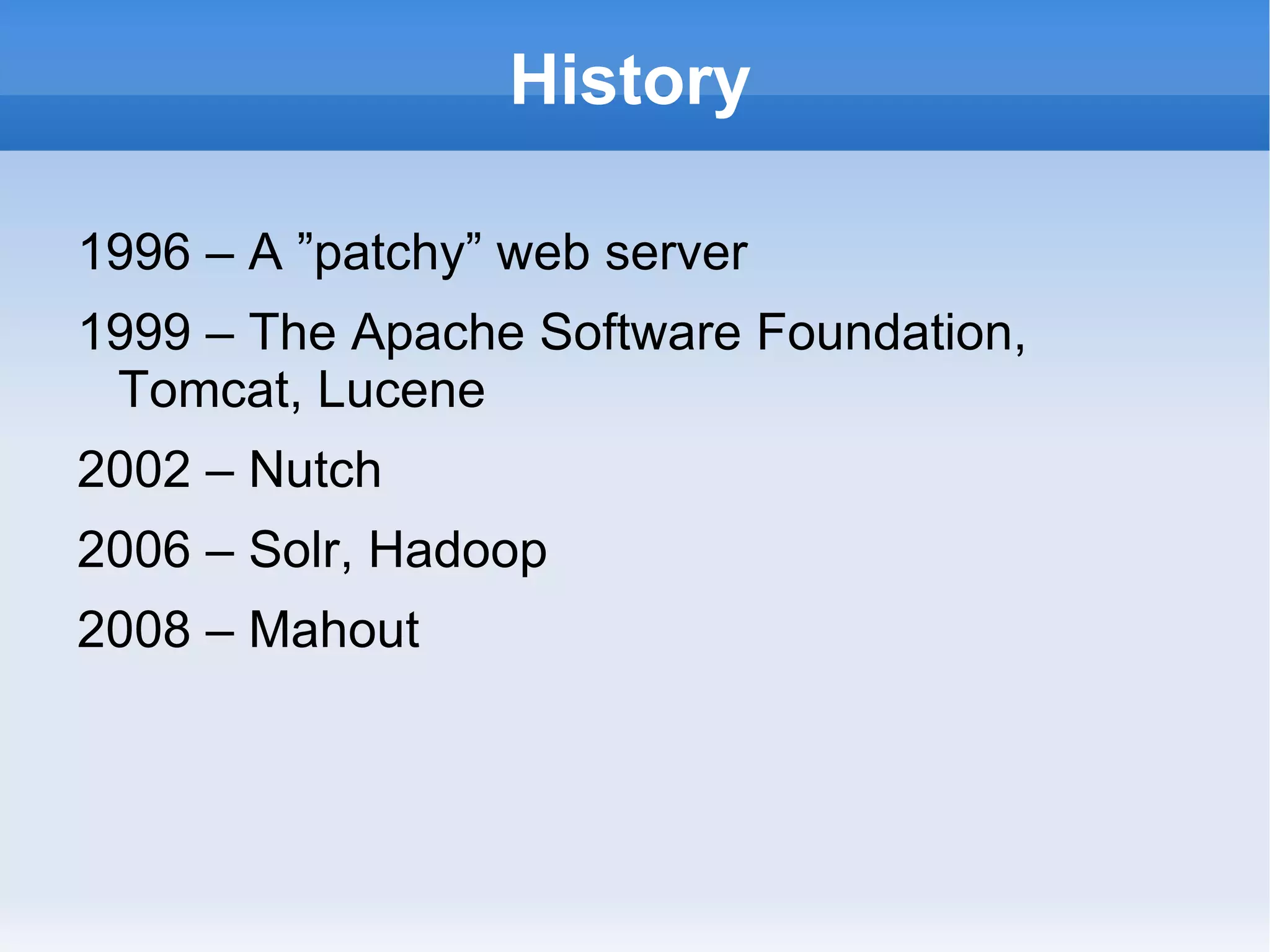




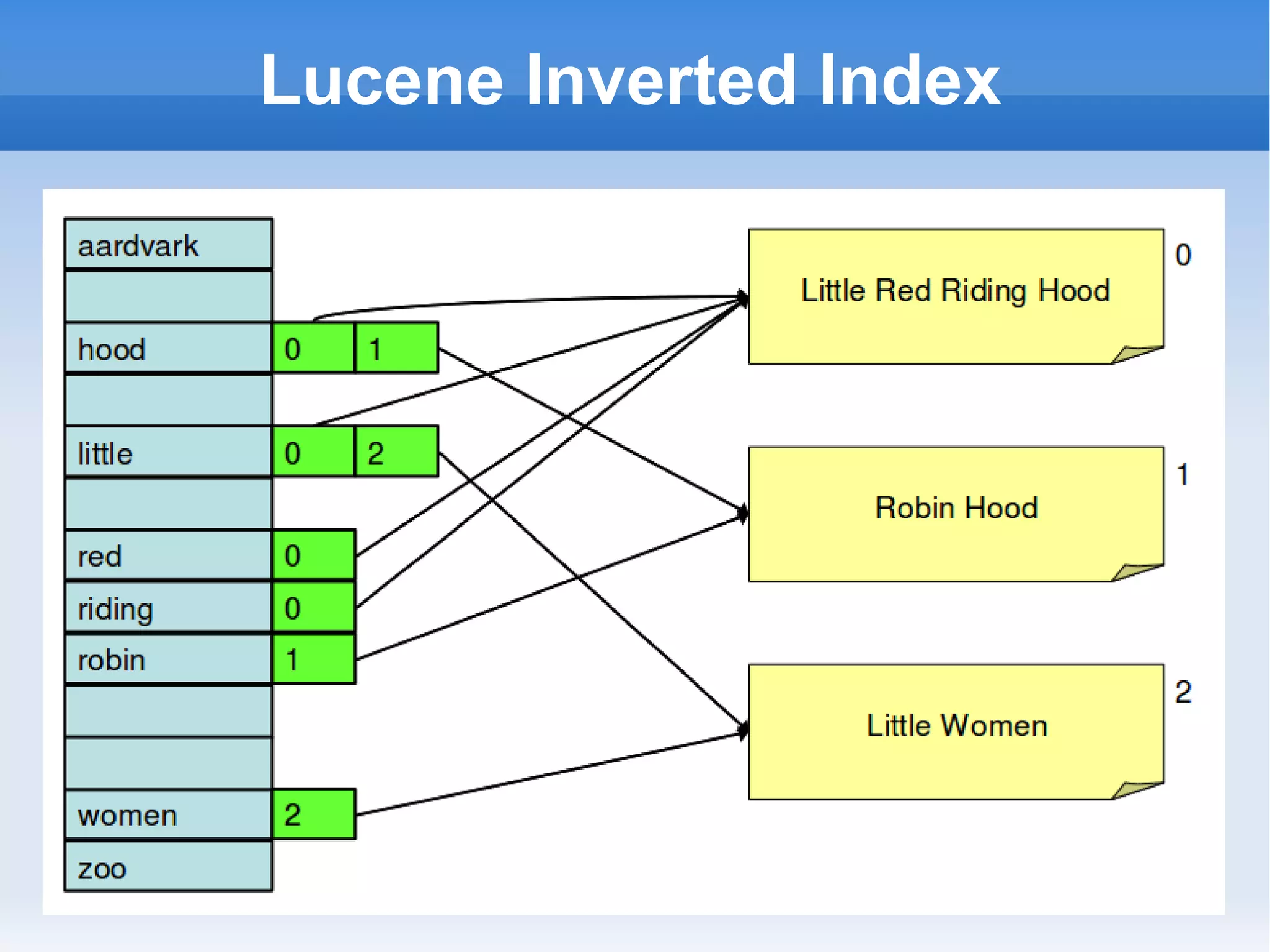






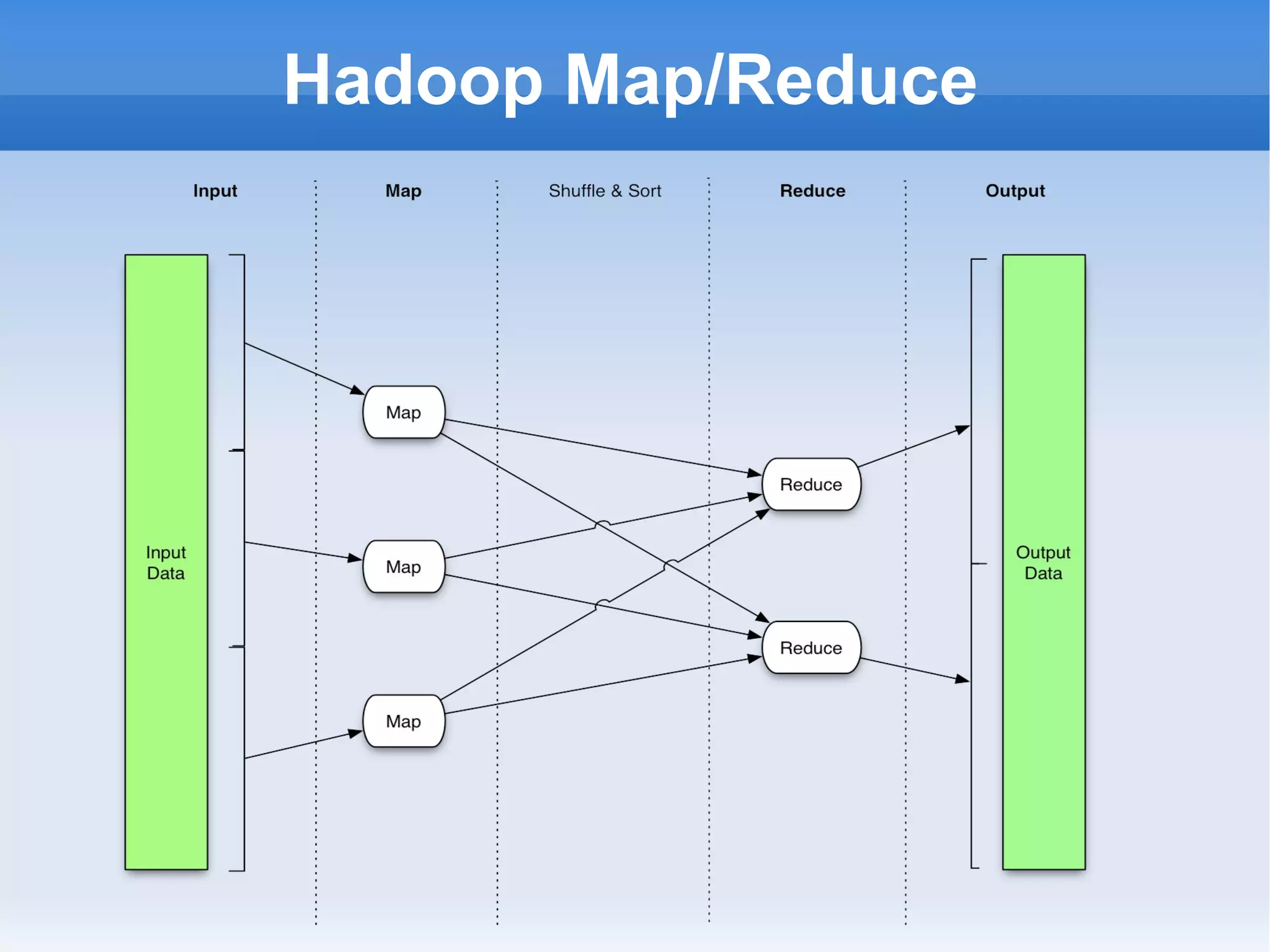






The document outlines the history and contributions of the Apache Software Foundation, highlighting key projects like HTTPD, Lucene, Hadoop, and Solr. It discusses the benefits of participating in open-source software development, such as working on preferred projects, learning from experts, and enhancing career opportunities. Additionally, the document provides insight into future developments and considerations for contributors looking to get involved.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















