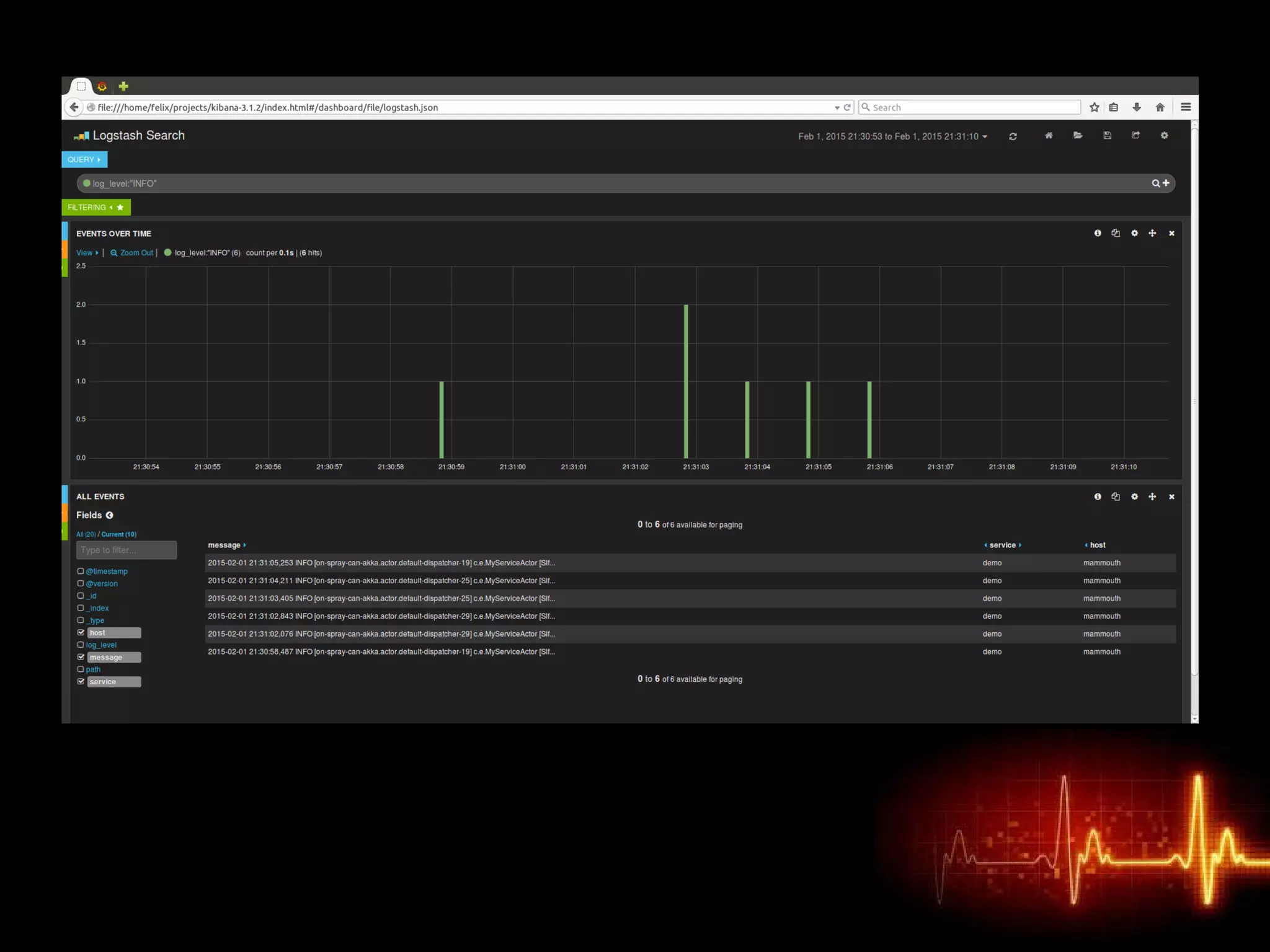
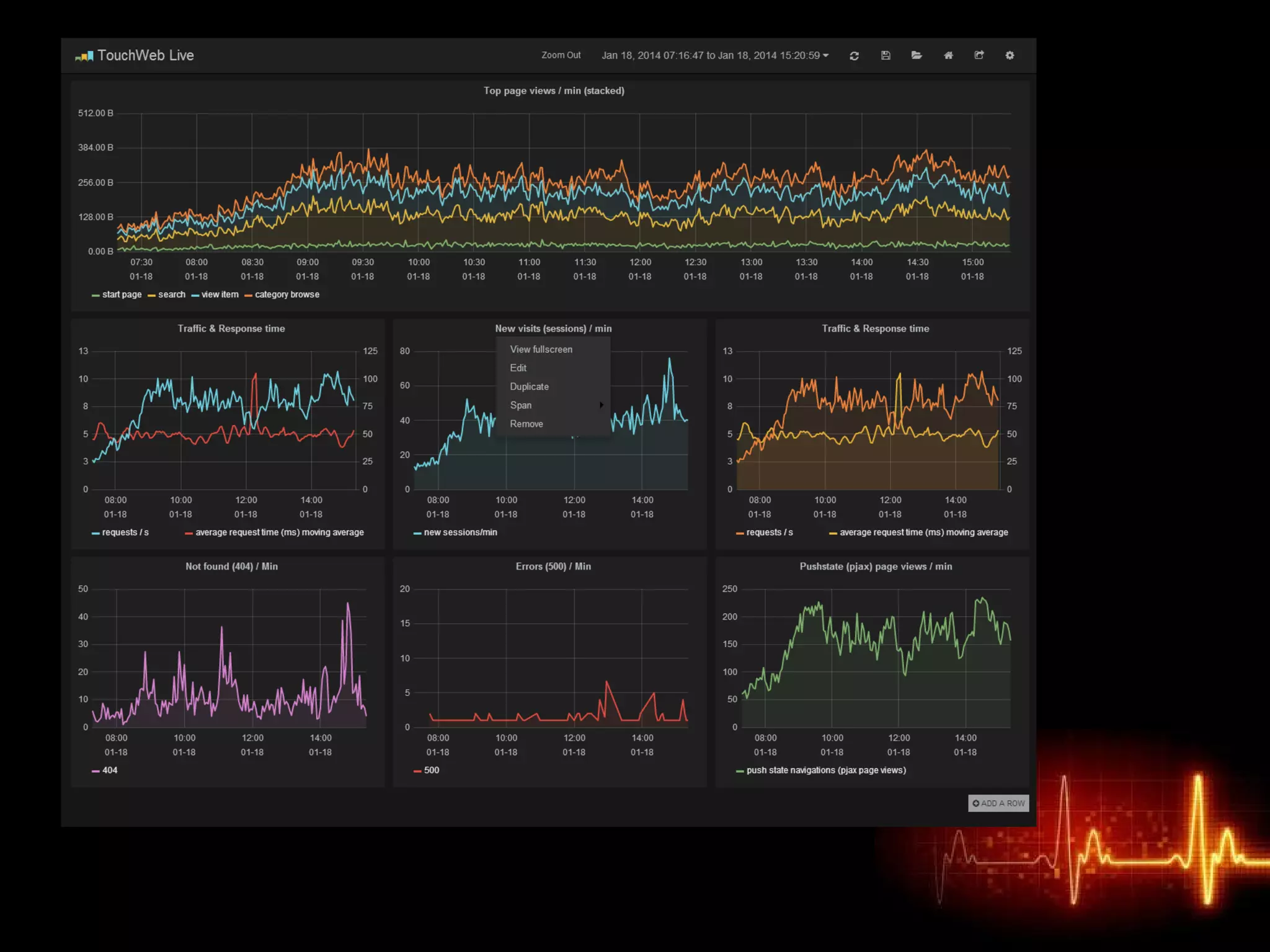
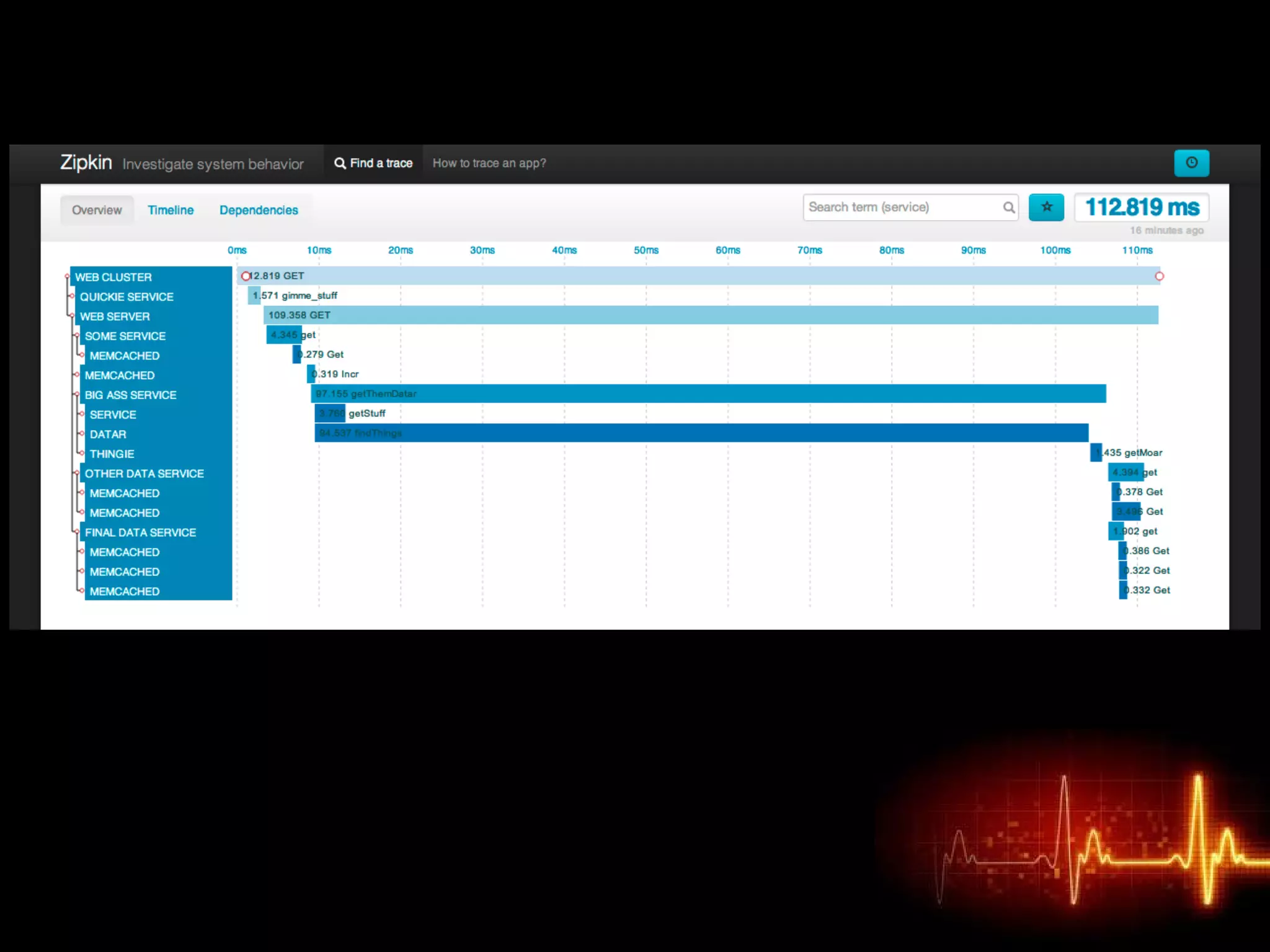
Monitor All the Things! provides tips for effectively monitoring distributed systems. It recommends centralizing logs for ease of access and insights. Metrics such as gauges, counters, and timers should be stored and graphs created for visualization. Services should publish health statuses to enable simple checks that raise alerts on failures. Traces can help identify the paths requests take through systems and pinpoint where slowdowns occur. The document stresses the importance of monitoring all facets of systems for visibility into performance and failures.













![Example
input {
file {
path => "/var/log/demo/demo.log"
}
}
filter {
grok {
match => [ "message", "%{DATESTAMP} %{LOGLEVEL:log_level} %{GREEDYDATA}" ]
}
mutate {
add_field => {
"service" => "demo"
}
}
}
output {
elasticsearch {
host => mysearchserver
}
}](https://image.slidesharecdn.com/monitorallthethings1-150219133111-conversion-gate01/75/Monitor-all-the-things-Confoo-14-2048.jpg)
![Example
{
"message":"2015-02-01 21:31:02,076 INFO [dispatcher-29] awesome log",
"@version":"1",
"@timestamp":"2015-02-02T02:31:02.860Z",
"host":"mammouth",
"path":"/var/log/demo/demo.log",
"log_level":"INFO",
"service":"demo"
}](https://image.slidesharecdn.com/monitorallthethings1-150219133111-conversion-gate01/75/Monitor-all-the-things-Confoo-15-2048.jpg)