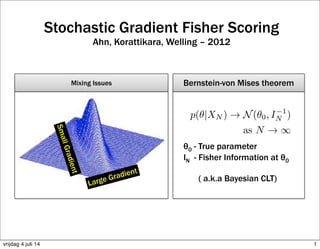
4. SGFS
Stochastic Gradient Langevin
Markov Chain for Approximate
LowBias
High
Samples from the correct posterior, , at low ϵ
Samples from approximate posterior, , at any ϵ
2
2vrijdag 4 juli 14
5. SGFS
Stochastic Gradient Langevin
Markov Chain for Approximate
LowBias
High
Samples from the correct posterior, , at low ϵ
Samples from approximate posterior, , at any ϵ
Low
HighBias
2
2vrijdag 4 juli 14
8. The SGFS Knob
Burn-in
using
Sampli
ng
Sampli
ng
Decrease ϵ over time
Exact
Sampli
4
Low
Variance
( Fast )
High
Variance
( Slow )
High Bias Low Bias
xx
x
x
x x
x xx x
x x
x
x
x
x
xx
x
x
x x
x
x
x
x
x
x
x x
x
x
x
x
4vrijdag 4 juli 14
13. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
7vrijdag 4 juli 14
14. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
7vrijdag 4 juli 14
15. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
Euclidean distance b/w
parameters is 10,
but densities p(x|θ) are
almost identical
7vrijdag 4 juli 14
16. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
Euclidean distance b/w
parameters is 10,
but densities p(x|θ) are
almost identical
where G(θ) is positive semi-definite
7vrijdag 4 juli 14
17. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
Euclidean distance b/w
parameters is 10,
but densities p(x|θ) are
almost identical
where G(θ) is positive semi-definite
7vrijdag 4 juli 14
18. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
Euclidean distance b/w
parameters is 10,
but densities p(x|θ) are
almost identical
where G(θ) is positive semi-definite
7vrijdag 4 juli 14
19. Stochastic Gradient Riemannian Langevin Dynamics
(SGRLD) - Patterson & Teh, 2013
Euclidean space
of parameters θ = (σ, µ)
of a normal distribution
Euclidean distance b/w
parameters is 1,
but densities p(x|θ) are
very different
Euclidean distance b/w
parameters is 10,
but densities p(x|θ) are
almost identical
where G(θ) is positive semi-definite
Natural Gradient change in curvaturealign noise
7vrijdag 4 juli 14
21. An (over-) simplified explanation of Hamiltonian Monte Carlo (HMC)
Stochastic Gradient Hamiltonian Monte Carlo
T. Chen, E. B. Fox, C. Guestrin (2014)
one informative gradient step of size ϵ + one random step of size ϵ
= Random walk type movement and bad mixing
Langevin Update
8vrijdag 4 juli 14
22. An (over-) simplified explanation of Hamiltonian Monte Carlo (HMC)
Stochastic Gradient Hamiltonian Monte Carlo
T. Chen, E. B. Fox, C. Guestrin (2014)
one informative gradient step of size ϵ + one random step of size ϵ
= Random walk type movement and bad mixing
Langevin Update
• HMC allows multiple gradient steps per noise step
• HMC can make distant proposals with high acceptance probability
8vrijdag 4 juli 14
23. Stochastic Gradient Hamiltonian Monte Carlo (SGHMC)
An (over-) simplified explanation of Hamiltonian Monte Carlo (HMC)
Stochastic Gradient Hamiltonian Monte Carlo
T. Chen, E. B. Fox, C. Guestrin (2014)
one informative gradient step of size ϵ + one random step of size ϵ
= Random walk type movement and bad mixing
Langevin Update
• Naively using stochastic gradients in HMC does not work well
• Authors use a correction term to cancel the effect of noise in gradients
• HMC allows multiple gradient steps per noise step
• HMC can make distant proposals with high acceptance probability
8vrijdag 4 juli 14
24. Stochastic Gradient Hamiltonian Monte Carlo (SGHMC)
An (over-) simplified explanation of Hamiltonian Monte Carlo (HMC)
Stochastic Gradient Hamiltonian Monte Carlo
T. Chen, E. B. Fox, C. Guestrin (2014)
one informative gradient step of size ϵ + one random step of size ϵ
= Random walk type movement and bad mixing
Langevin Update
• Naively using stochastic gradients in HMC does not work well
• Authors use a correction term to cancel the effect of noise in gradients
• HMC allows multiple gradient steps per noise step
• HMC can make distant proposals with high acceptance probability
Talk tomorrow afternoon
In Track C (Monte Carlo)
8vrijdag 4 juli 14
32. Distributed SGLD
Ahn, Shahbaba, Welling (2014)
N
N
N
Total N
Data points
Adaptive Load Balancing: Longer trajectories from faster machines
9vrijdag 4 juli 14
34. D-SGLD Results
Wikipedia dataset: 4.6M articles,811M tokens,vocabulary size: 7702
PubMed dataset: 8.2M articles,730M tokens,vocabulary size: 39987
Model: Latent Dirichlet Allocation
10
Talk tomorrow afternoon
In Track C (Monte Carlo)
10vrijdag 4 juli 14
35. A Recap
Use
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoidedUse
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoided
SGLD Langevin
Dynamics
with
stochas3c
gradients
SGFS Precondi3oning
matrix
based
on
Fisher
informa3on
at
mode
SGRLD Posi3on
specific
precondi3oning
matrix
based
on
Reimannian
geometry
SGHMC Avoids
random
walks
by
taking
mul3ple
gradient
steps
DSGLD Distributed
version
of
above
algorithms
11vrijdag 4 juli 14
36. A Recap
Use
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoidedUse
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoided
SGLD Langevin
Dynamics
with
stochas3c
gradients
SGFS Precondi3oning
matrix
based
on
Fisher
informa3on
at
mode
SGRLD Posi3on
specific
precondi3oning
matrix
based
on
Reimannian
geometry
SGHMC Avoids
random
walks
by
taking
mul3ple
gradient
steps
DSGLD Distributed
version
of
above
algorithms
Approximate
the
Metropolis-‐Has3ngs
Test
using
less
dataApproximate
the
Metropolis-‐Has3ngs
Test
using
less
data
11vrijdag 4 juli 14
37. Why approximate the MH test?
(if gradient based methods seem to work so well)
• Gradient based proposals are not always available
– Parameter spaces of different dimensionality
– Distributions on constrained manifolds
– Discrete variables
• High gradients may catapult the sampler to low density regions
12vrijdag 4 juli 14
47. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
16vrijdag 4 juli 14
48. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
16vrijdag 4 juli 14
49. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
16vrijdag 4 juli 14
50. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
16vrijdag 4 juli 14
51. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
(c is chosen as in a t-test for µ = µ0 vs µ ≠ µ0 )
16vrijdag 4 juli 14
52. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
(c is chosen as in a t-test for µ = µ0 vs µ ≠ µ0 )
Talk tomorrow afternoon
In Track C (Monte Carlo)
16vrijdag 4 juli 14
53. Approach 1: Using Confidence Intervals
Korattikara, Chen, Welling (2014)
Collect more data
(c is chosen as in a t-test for µ = µ0 vs µ ≠ µ0 )
Talk tomorrow afternoon
In Track C (Monte Carlo)
• Singh, Wick, McCallum (2012) – inference in large scale factor graphs
• DuBois, Korattikara, Welling, Smyth (2014) – approximate Slice Sampling
16vrijdag 4 juli 14
54. Independent Component Analysis
Mixture of 4 audio sources - 1.95 Million datapoints, 16 dimensions
Test function is Amari distance to true unmixing matrix
17
17vrijdag 4 juli 14
56. Approach 2: Using Concentration Inequalities
Bardenet, Doucet, Holmes (2014)
Collect more data
19vrijdag 4 juli 14
57. Approach 2: Using Concentration Inequalities
Bardenet, Doucet, Holmes (2014)
Collect more data
19vrijdag 4 juli 14
58. Approach 2: Using Concentration Inequalities
Bardenet, Doucet, Holmes (2014)
Collect more data
• Complementary to previous method
• More robust as it does not use any CLT assumptions
• Uses more data per test if CLT assumptions do hold
19vrijdag 4 juli 14
59. Approach 2: Using Concentration Inequalities
Bardenet, Doucet, Holmes (2014)
Collect more data
• Complementary to previous method
• More robust as it does not use any CLT assumptions
• Uses more data per test if CLT assumptions do hold
Talk tomorrow afternoon
In Track C (Monte Carlo)
19vrijdag 4 juli 14
60. Summary
Use
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoidedUse
an
efficient
proposal
so
that
the
Metropolis-‐Has3ngs
test
can
be
avoided
SGLD Langevin
Dynamics
with
stochas3c
gradients
SGFS Precondi3oning
matrix
based
on
Fisher
informa3on
at
mode
SGRLD Posi3on
specific
precondi3oning
based
on
Reimannian
geometry
SGHMC Avoids
random
walks
by
taking
mul3ple
gradient
steps
DSGLD Distributed
version
of
above
algorithms
Approximate
the
Metropolis-‐Has3ngs
Test
using
less
dataApproximate
the
Metropolis-‐Has3ngs
Test
using
less
data
Confidence
Intervals
Based
on
confidence
levels
using
CLT
assump3ons.
Concentra3on
Bounds
Based
on
concentra3on
bounds.
More
robust
as
it
does
not
use
CLT
assump3ons,
but
uses
more
data
than
above
if
CLT
assump3ons
hold
20vrijdag 4 juli 14
61. Langevin Dynamics
• The Langevin update is a discrete
time approximation of a stochastic differential equation(SDE)
• The stationary distribution of this SDE is S0(θ)
• Discretization introduces O(ϵ) errors that are corrected using a MH test
Analysis: SGLD
I. Sato and H. Nakagawa (2014)
Stochastic Gradient Langevin Dynamics
• The stationary distribution of the SDE that SGLD represents can also be
shown to be S0(θ) I. Sato and H. Nakagawa (2014)
• Time Discretized SGLD converges weakly to the SGLD SDE
i.e. For any continuous differentiable and polynomial growth function f:
21vrijdag 4 juli 14
62. Langevin Dynamics
• The Langevin update is a discrete
time approximation of a stochastic differential equation(SDE)
• The stationary distribution of this SDE is S0(θ)
• Discretization introduces O(ϵ) errors that are corrected using a MH test
Analysis: SGLD
I. Sato and H. Nakagawa (2014)
Stochastic Gradient Langevin Dynamics
• The stationary distribution of the SDE that SGLD represents can also be
shown to be S0(θ) I. Sato and H. Nakagawa (2014)
• Time Discretized SGLD converges weakly to the SGLD SDE
i.e. For any continuous differentiable and polynomial growth function f:
Talk Monday afternoon
In Track C (Monte Carlo &
Approximate Inference)
21vrijdag 4 juli 14
63. Assume Uniform Ergodicity
Control error in Transition Kernel
Analysis: Approximate MH
Control probability of making a wrong decision:
_ Error in acceptance probability is bounded:
_ Error in transition probability is bounded:
where Total Variation
22vrijdag 4 juli 14
64. Error in Stationary Distribution
If the error in transition probability is bounded:
And uniform ergodicity holds:
Then, the error in the stationary distribution is bounded as:
Analysis: Approximate MH
For more details:
1. P. Alquier, N. Friel, R. Everitt, A. Boland (2014)
2. R. Bardenet, A. Doucet, C. Holmes (2014)
3. A. Korattikara, Y. Chen, M. Welling (2014)
4. N. S. Pillai, A. Smith (2014)
23vrijdag 4 juli 14
65. References - MCMC
Approximate MCMC algorithms using mini-batch gradients
• Stochastic Gradient Langevin Dynamics – M. Welling and Y. W. Teh (ICML 2011)
• Stochastic Gradient Fisher Scoring – S. Ahn, A. Korattikara, M. Welling (ICML 2012)
• Stochastic Gradient Riemannian Langevin Dynamics on the Probability Simplex – S. Patterson and Y.W. Teh (NIPS 2013)
• Stochastic Gradient Hamiltonian Monte Carlo - T. Chen, E. B. Fox, C. Guestrin (ICML 2014)
• Distributed Stochastic Gradient MCMC – S. Ahn, B. Shahbaba, M. Welling (ICML 2014)
Approximate MCMC algorithms using mini-batch Metropolis-Hastings
• Austerity in MCMC Land: Cutting the Metropolis-Hastings Budget - A. Korattikara, Y. Chen, M. Welling (ICML 2014)
• Towards scaling up Markov chain Monte Carlo: an adaptive subsampling approach – R. Bardenet, A. Doucet, C. Holmes (ICML 2014)
• Approximate Slice Sampling for Bayesian Posterior Inference – C. DuBois, A. Korattikara, M. Welling, P. Smyth (AISTATS 2014)
Theory
• Approximation Analysis of Stochastic Gradient Langevin Dynamics using Fokker-Planck Equation and Ito Process –I. Sato and H.
Nakagawa (ICML 2014)
• Noisy Monte Carlo: Convergence of Markov chains with approximate transition kernels - P. Alquier, N. Friel, R. Everitt, A. Boland (arXiv
2014)
• Ergodicity of Approximate MCMC Chains with Applications to Large Data Sets - N. S. Pillai, A. Smith (arXiv 2014)
Asymptotically unbiased MCMC algorithms using mini-batches
• Asymptotically Exact, Embarrassingly Parallel MCMC – W. Neiswanger, C. Wang, R. Xing (arXiv 2013)
• Firefly Monte Carlo: Exact MCMC with Subsets of Data – D. Maclaurin, R. P. Adams (arXiv 2014)
• Accelerating MCMC via Parallel Predictive Prefetching – E. Angelino, E. Kohler, A. Waterland, M. Seltzer, R. P. Adams (arXiv 2014)
24vrijdag 4 juli 14
66. Conclusions & Future Directions
• Bayesian
Inference
is
not
superfluous
in
the
context
of
big
data.
• Two
requirements:
• Stochas3c
/
mini-‐batch
based
updates
• Distributed
implementa3on
• Two
fruiRul
approaches:
• Stochas3c
Varia3onal
Bayes
• Mini-‐batch
MCMC
• Future
VB:
• Very
flexible
varia3onal
posteriors,
very
small
remaining
bias
• Black-‐box
inference
engine,
a
la
Infer.net,
BUGS
• Future
MCMC
• BeTer
theory
• BeTer
use
of
powerful
(stochas3c)
op3miza3on
methods.
25vrijdag 4 juli 14
67. Stochas3c
Fully
Structured
Distributed
Varia3onal
Bayes
Stochas3c
Approxima3on
MCMC
(driving
bias
to
0)
(driving
variance
to
0)
26vrijdag 4 juli 14
68. Acknowledgements & Collaborators
• Yee Whye Teh
• Sungjin Ahn
• Babak Shahbaba
• Yutian Chen
• Durk Kingma
• Taco Cohen
• Alex Ihler
• Chris DuBois
• Padhraic Smyth
• Dan Gillen
27vrijdag 4 juli 14