Luigi is a Python framework developed by Spotify for defining and executing data workflows, enabling users to process large volumes of data efficiently. It emphasizes simple dependency management, integration with Hadoop, and a user-friendly command line interface, which facilitates tasks such as data aggregation and reporting. The framework is open source and has been in use since September 2012, with contributions from companies like Foursquare and Bitly.
Background
Why did webuild Luigi?
We have a lot of data
Billions of log messages (several TBs) every day
Usage and backend stats, debug information
What we want to do
AB-testing
Music recommendations
Monthly/daily/hourly reporting
Business metric dashboards
We experiment a lot – need quick development cycles
3.
How to doit?
Hadoop
Data storage
Clean, filter, join and aggregate data
Postgres
Semi-aggregated data for dashboards
Cassandra
Time series data
4.
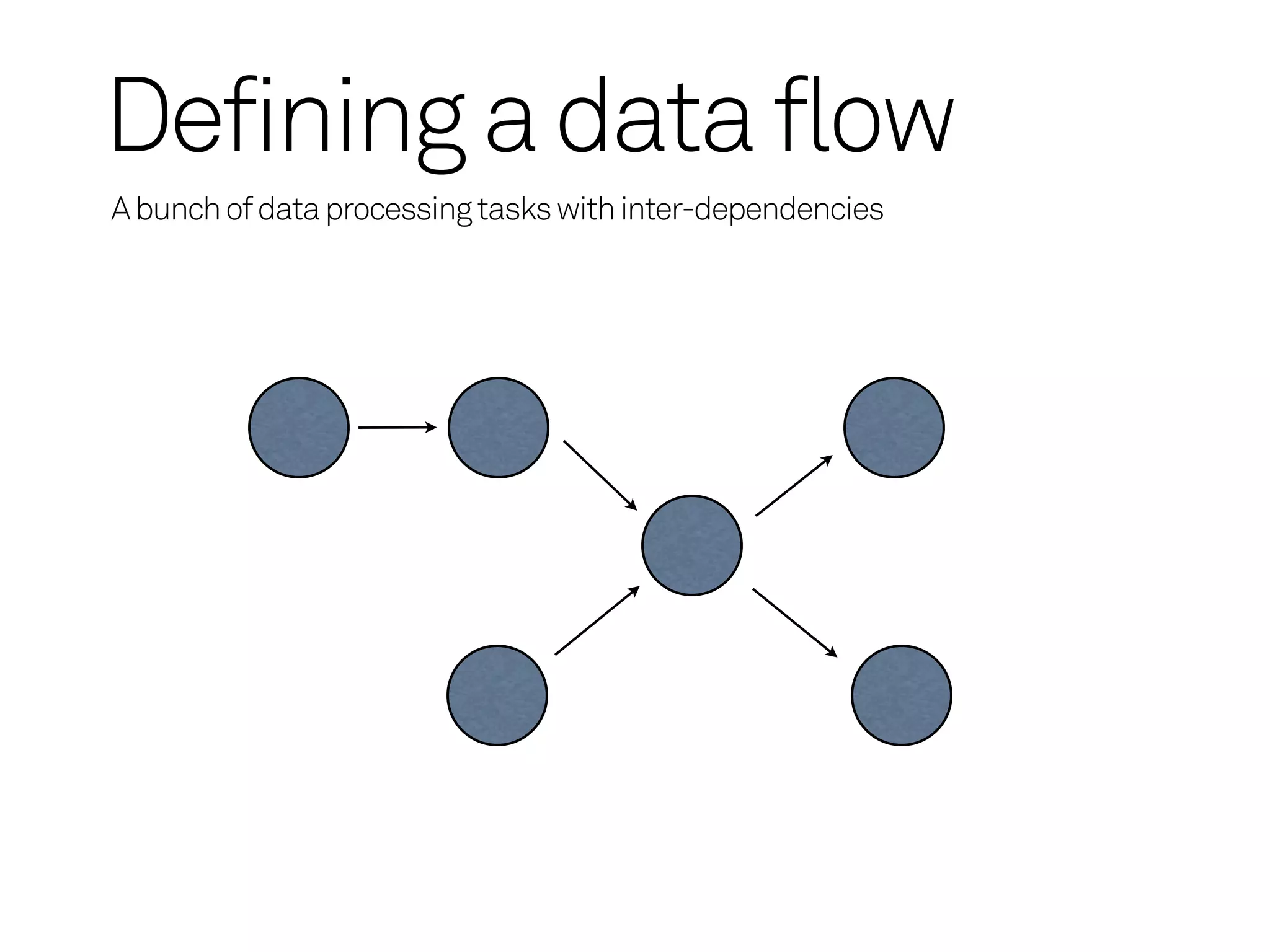
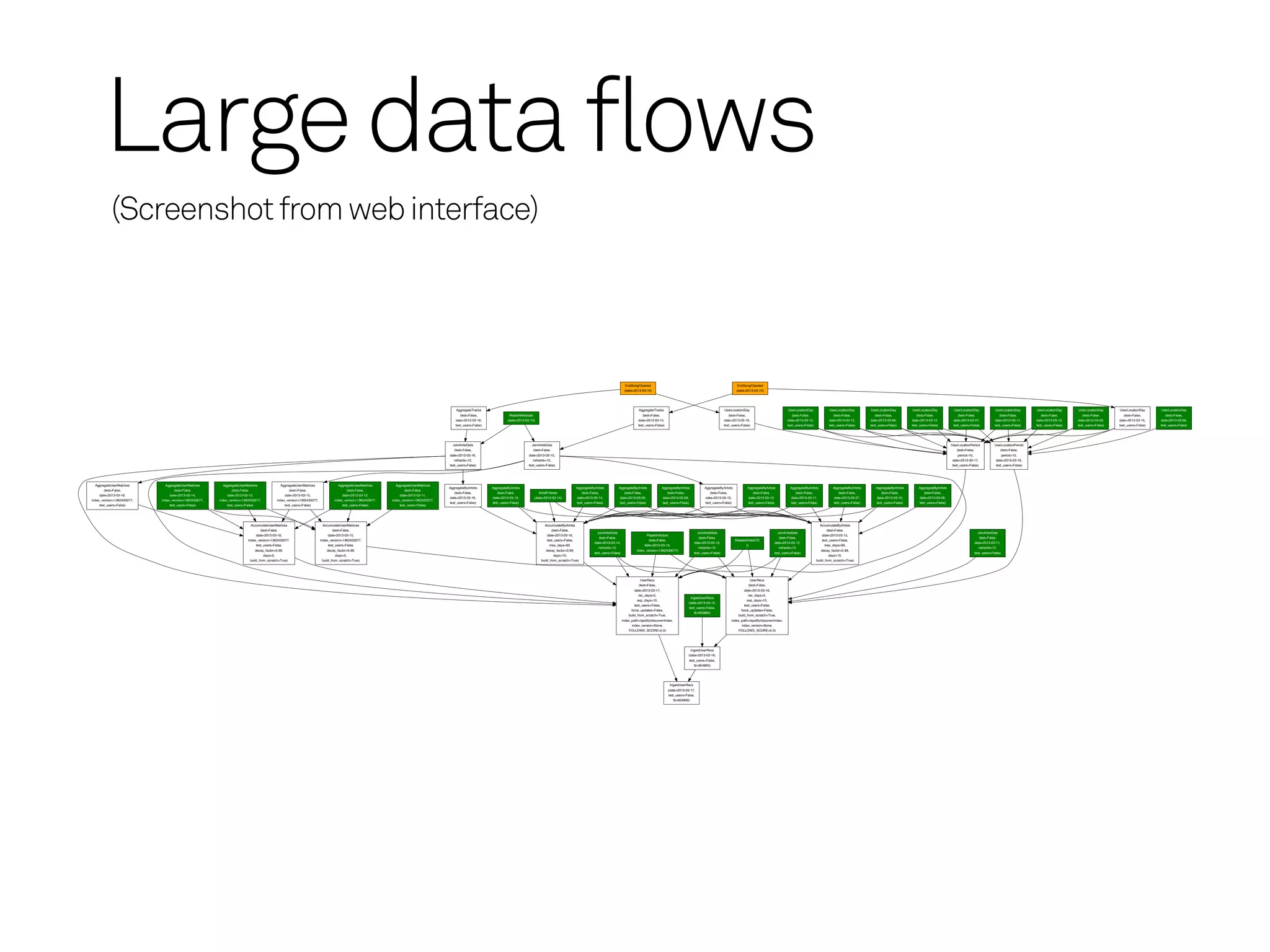
Defining a dataflow
A bunch of data processing tasks with inter-dependencies
5.
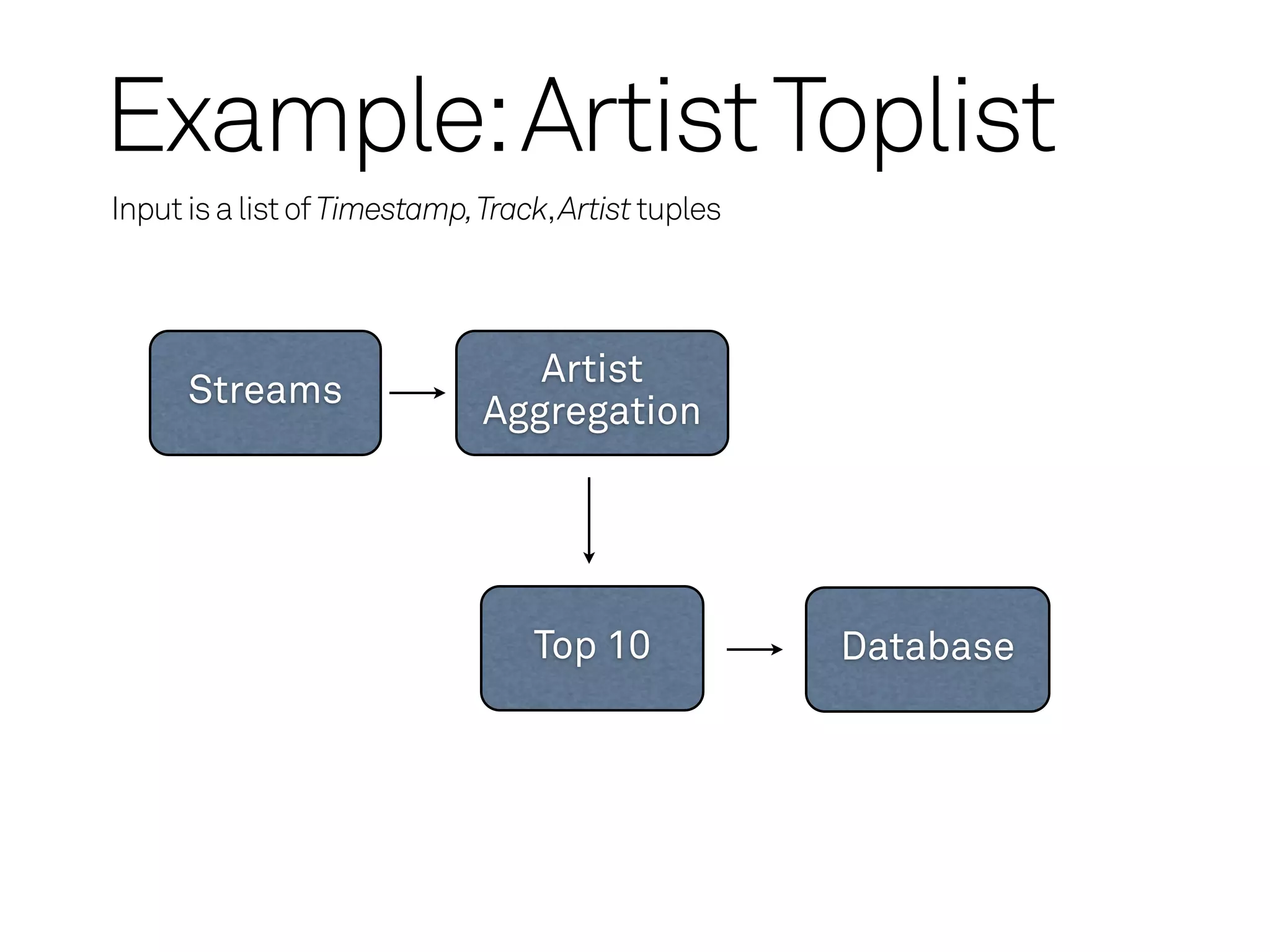
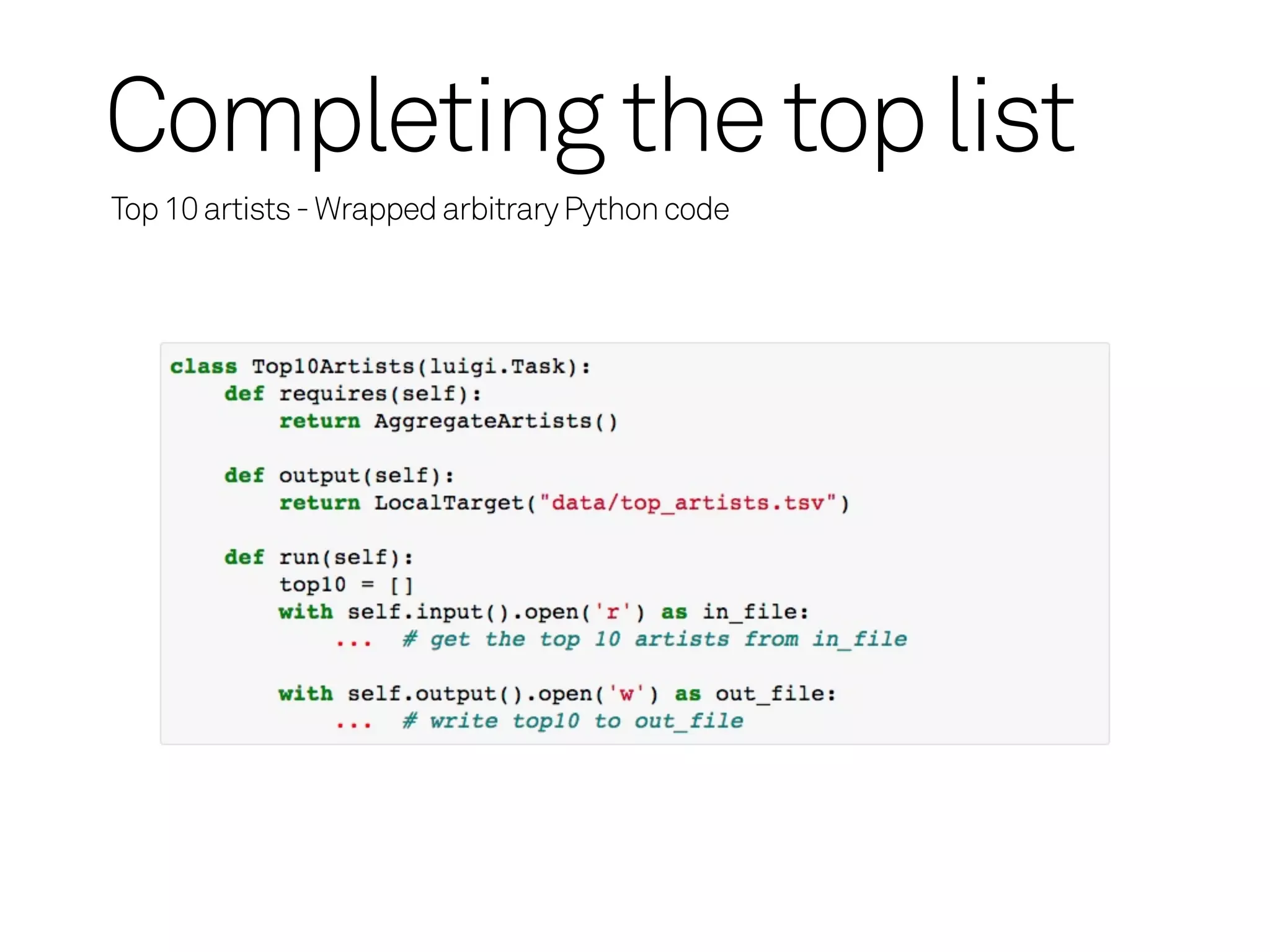
Example: Artist Toplist
Inputis a list of Timestamp, Track, Artist tuples
Artist
Streams
Aggregation
Top 10 Database
Introducing Luigi
A Pythonframework for data flow definition and execution
Main features
Dead-simple dependency definitions (think GNU make)
Emphasis on Hadoop/HDFS integration
Atomic file operations
Powerful task templating using OOP
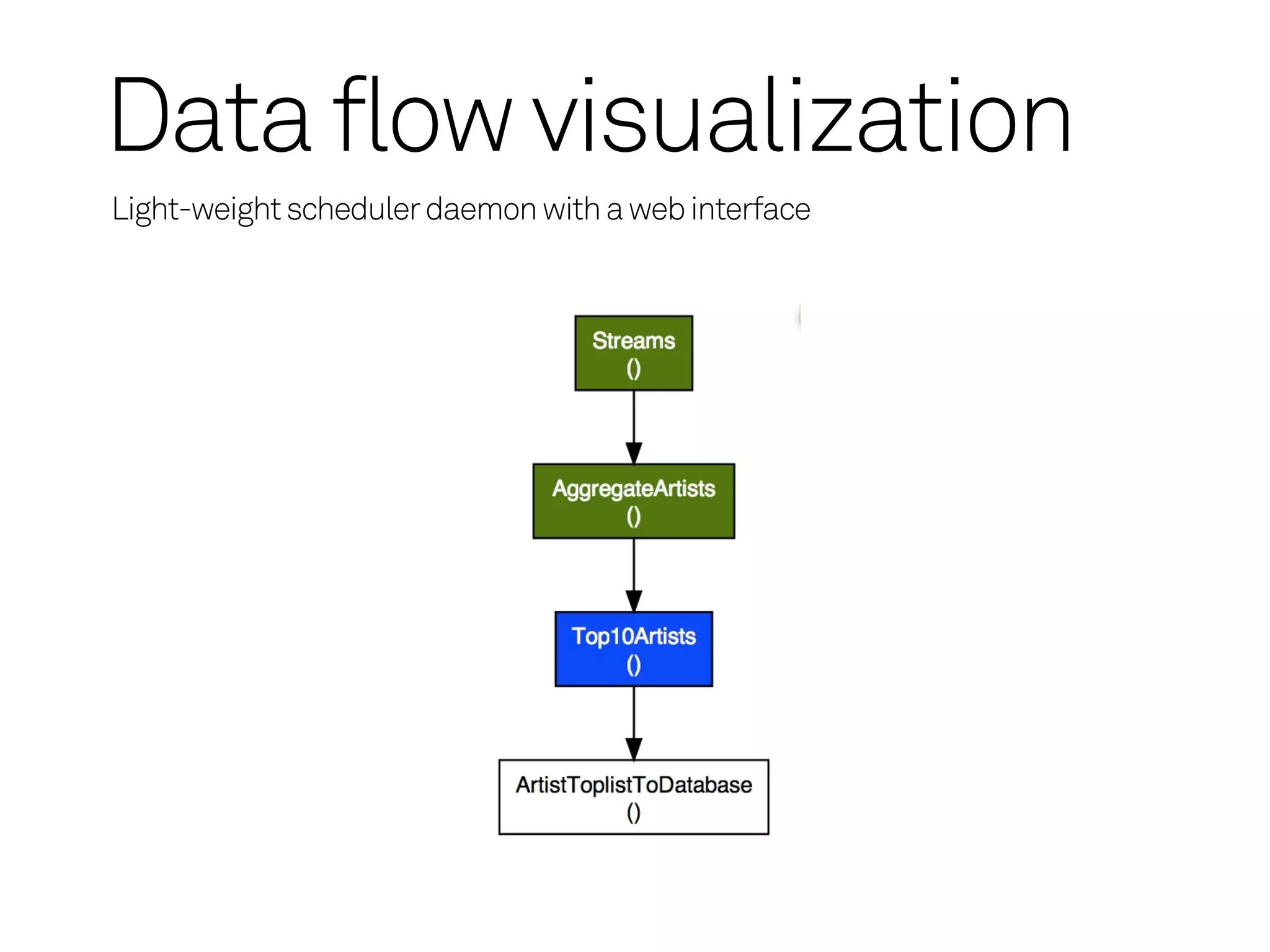
Data flow visualization
Command line integration
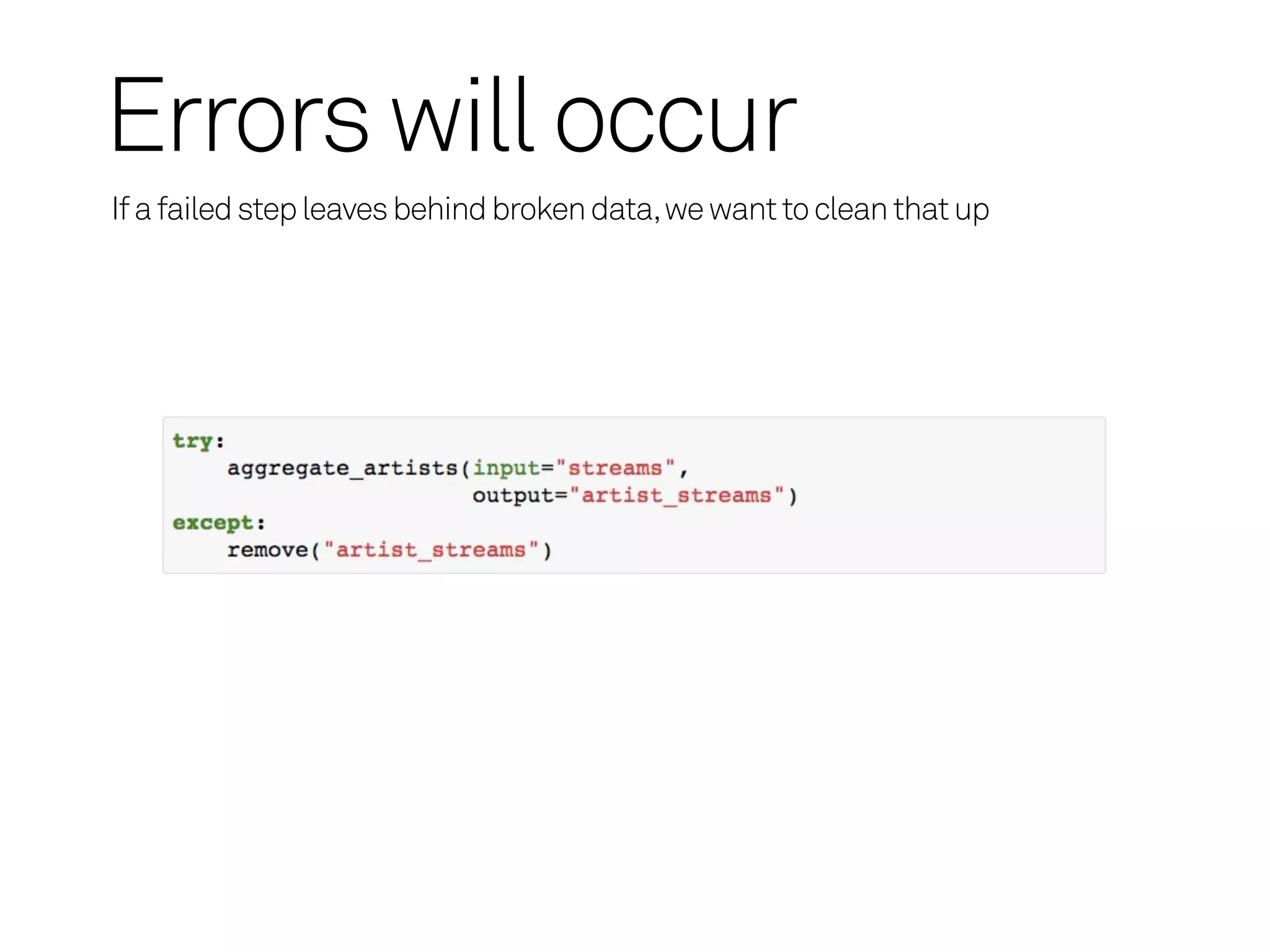
Luigi - AggregateArtists
Run on the command line:
$ python dataflow.py AggregateArtists
DEBUG: Checking if AggregateArtists() is complete
INFO: Scheduled AggregateArtists()
DEBUG: Checking if Streams() is complete
INFO: Done scheduling tasks
DEBUG: Asking scheduler for work...
DEBUG: Pending tasks: 1
INFO: [pid 74375] Running AggregateArtists()
INFO: [pid 74375] Done AggregateArtists()
DEBUG: Asking scheduler for work...
INFO: Done
INFO: There are no more tasks to run at this time
14.
Task templates andtargets
Reduces code-repetition by utilizing Luigi’s object oriented data model
Luigi comes with pre-implemented Tasks for...
Running Hadoop MapReduce utilizing Hadoop Streaming or custom jar-files
Running Hive and (soon) Pig queries
Inserting data sets into Postgres
Writing new ones are as easy as defining an interface and
implementing run()
15.
Hadoop MapReduce
Built-in HadoopStreaming Python framework
Features
Very slim interface
Fetches error logs from Hadoop cluster and displays them to the user
Class instance variables can be referenced in MapReduce code, which makes it
easy to supply extra data in dictionaries etc. for map side joins
Easy to send along Python modules that might not be installed on the cluster
Basic support for secondary sort
Runs on CPython so you can use your favorite libs (numpy, pandas etc.)
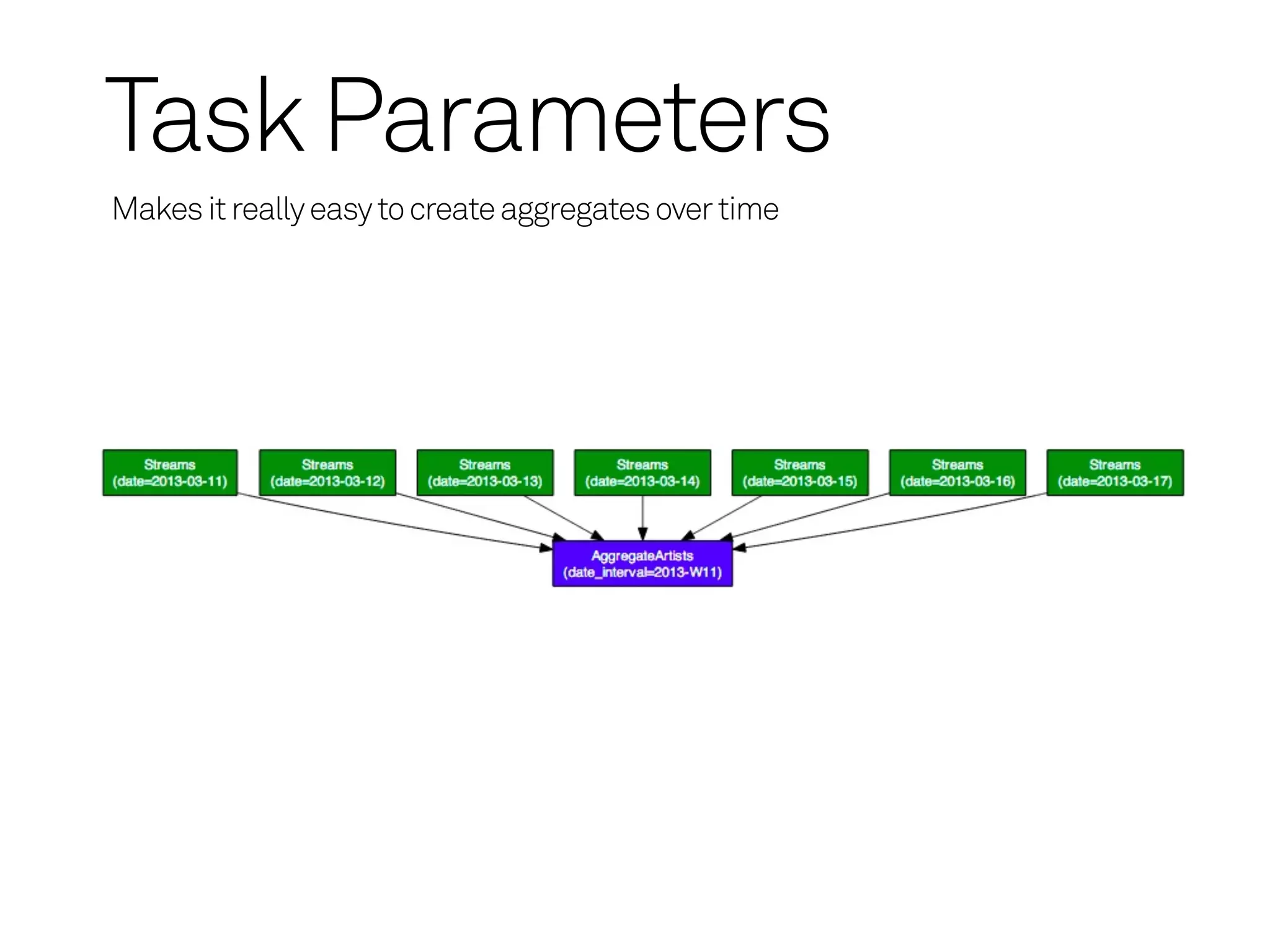
Task Parameters
Class variableswith some magic
Tasks have implicit __init__
Generates command line interface with typing and documentation
$ python dataflow.py AggregateArtists --date 2013-03-05
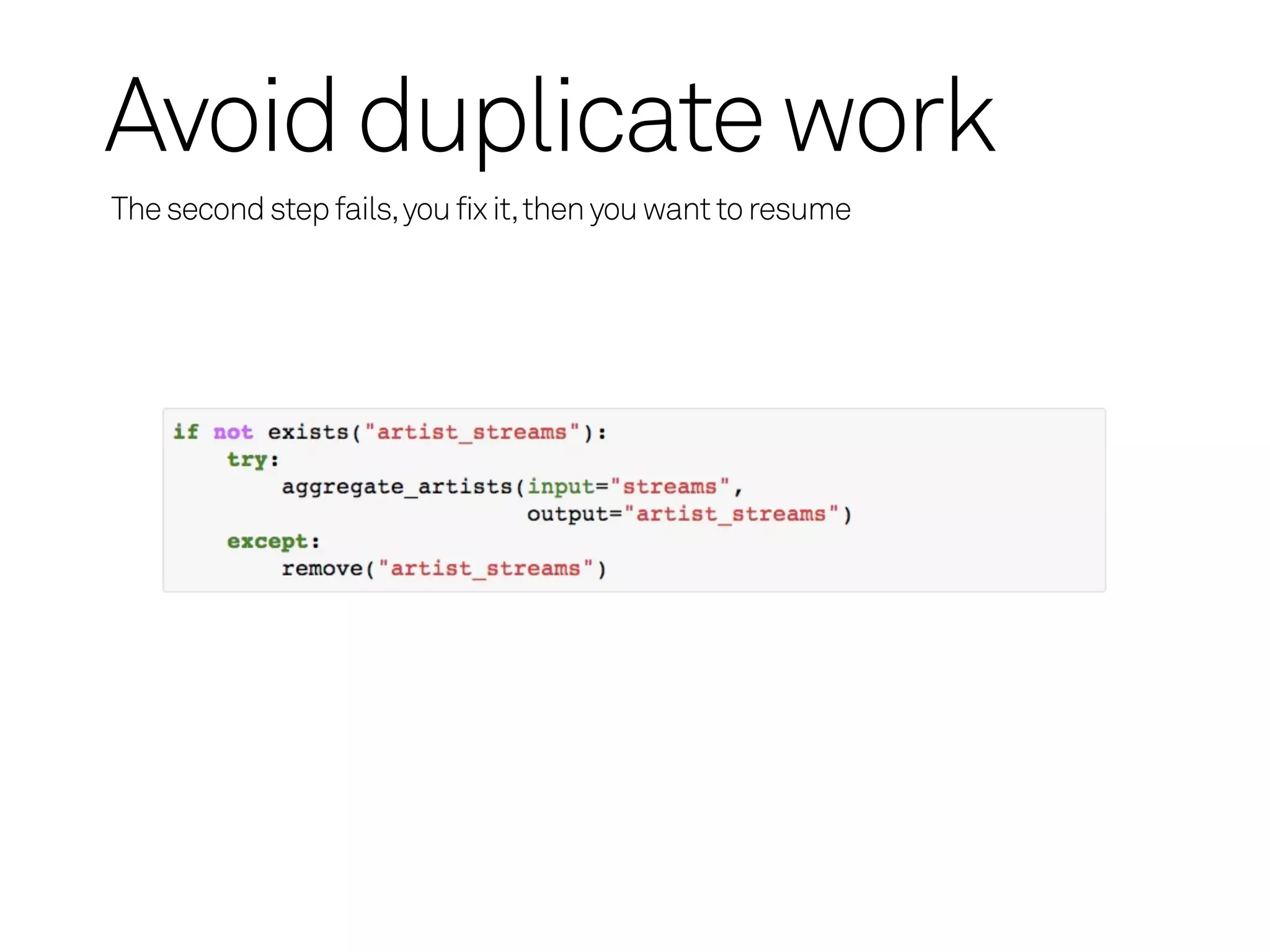
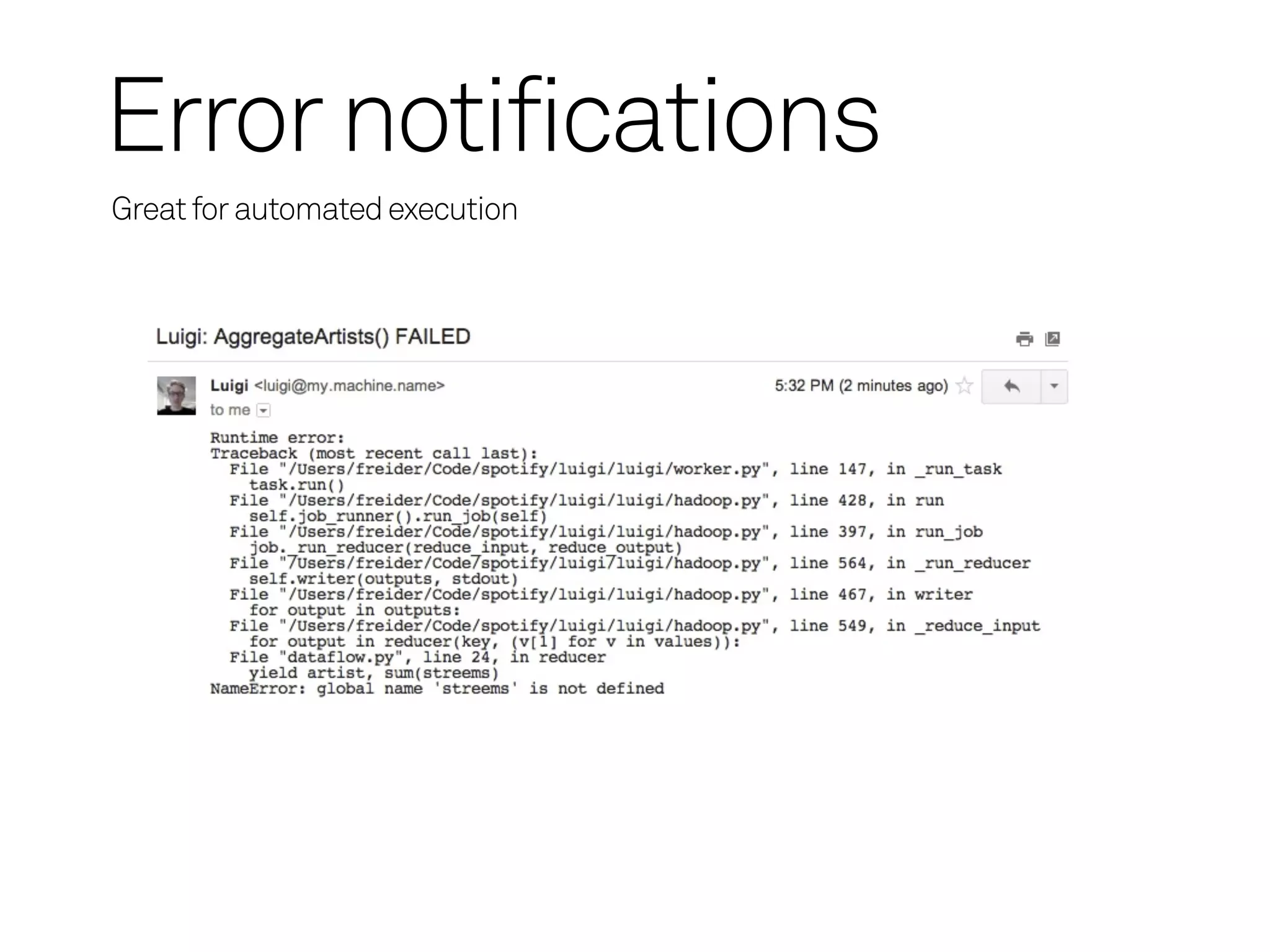
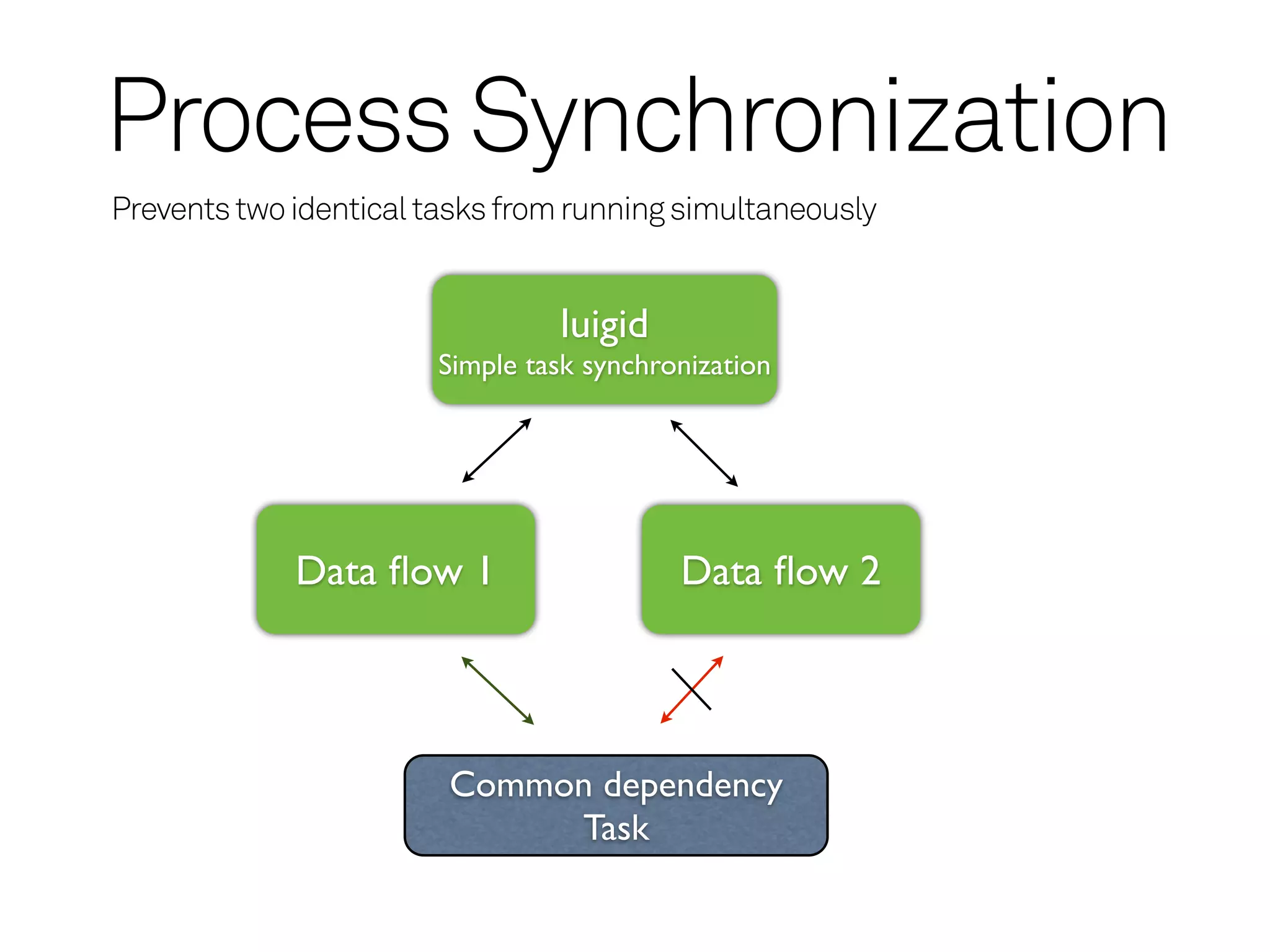
Process Synchronization
Prevents twoidentical tasks from running simultaneously
luigid
Simple task synchronization
Data flow 1 Data flow 2
Common dependency
Task
32.
What we useLuigi for
Not just another Hadoop streaming framework!
Hadoop Streaming
Java Hadoop MapReduce
Hive
Pig
Local (non-hadoop) data processing
Import/Export data to/from Postgres
Insert data into Cassandra
scp/rsync/ftp data files and reports
Dump and load databases
Others using it with Scala MapReduce and MRJob as well
33.
Luigi is opensource
http://github.com/spotify/luigi
Originated at Spotify
Based on many years of experience with data processing
Recent contributions by Foursquare and Bitly
Open source since September 2012
34.
Thank you!
For moreinformation feel free to reach out at
http://github.com/spotify/luigi
Oh, and we’re hiring – http://spotify.com/jobs
Elias Freider
freider@spotify.com








![Luigi - Aggregate Artists
Run on the command line:
$ python dataflow.py AggregateArtists
DEBUG: Checking if AggregateArtists() is complete
INFO: Scheduled AggregateArtists()
DEBUG: Checking if Streams() is complete
INFO: Done scheduling tasks
DEBUG: Asking scheduler for work...
DEBUG: Pending tasks: 1
INFO: [pid 74375] Running AggregateArtists()
INFO: [pid 74375] Done AggregateArtists()
DEBUG: Asking scheduler for work...
INFO: Done
INFO: There are no more tasks to run at this time](https://image.slidesharecdn.com/luigi-presentation-130320190739-phpapp01/75/Luigi-PyData-presentation-13-2048.jpg)






![Running it all...
DEBUG: Checking if ArtistToplistToDatabase() is complete
INFO: Scheduled ArtistToplistToDatabase()
DEBUG: Checking if Top10Artists() is complete
INFO: Scheduled Top10Artists()
DEBUG: Checking if AggregateArtists() is complete
INFO: Scheduled AggregateArtists()
DEBUG: Checking if Streams() is complete
INFO: Done scheduling tasks
DEBUG: Asking scheduler for work...
DEBUG: Pending tasks: 3
INFO: [pid 74811] Running AggregateArtists()
INFO: [pid 74811] Done AggregateArtists()
DEBUG: Asking scheduler for work...
DEBUG: Pending tasks: 2
INFO: [pid 74811] Running Top10Artists()
INFO: [pid 74811] Done Top10Artists()
DEBUG: Asking scheduler for work...
DEBUG: Pending tasks: 1
INFO: [pid 74811] Running ArtistToplistToDatabase()
INFO: Done writing, importing at 2013-03-13 15:41:09.407138
INFO: [pid 74811] Done ArtistToplistToDatabase()
DEBUG: Asking scheduler for work...
INFO: Done
INFO: There are no more tasks to run at this time](https://image.slidesharecdn.com/luigi-presentation-130320190739-phpapp01/75/Luigi-PyData-presentation-21-2048.jpg)






































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



