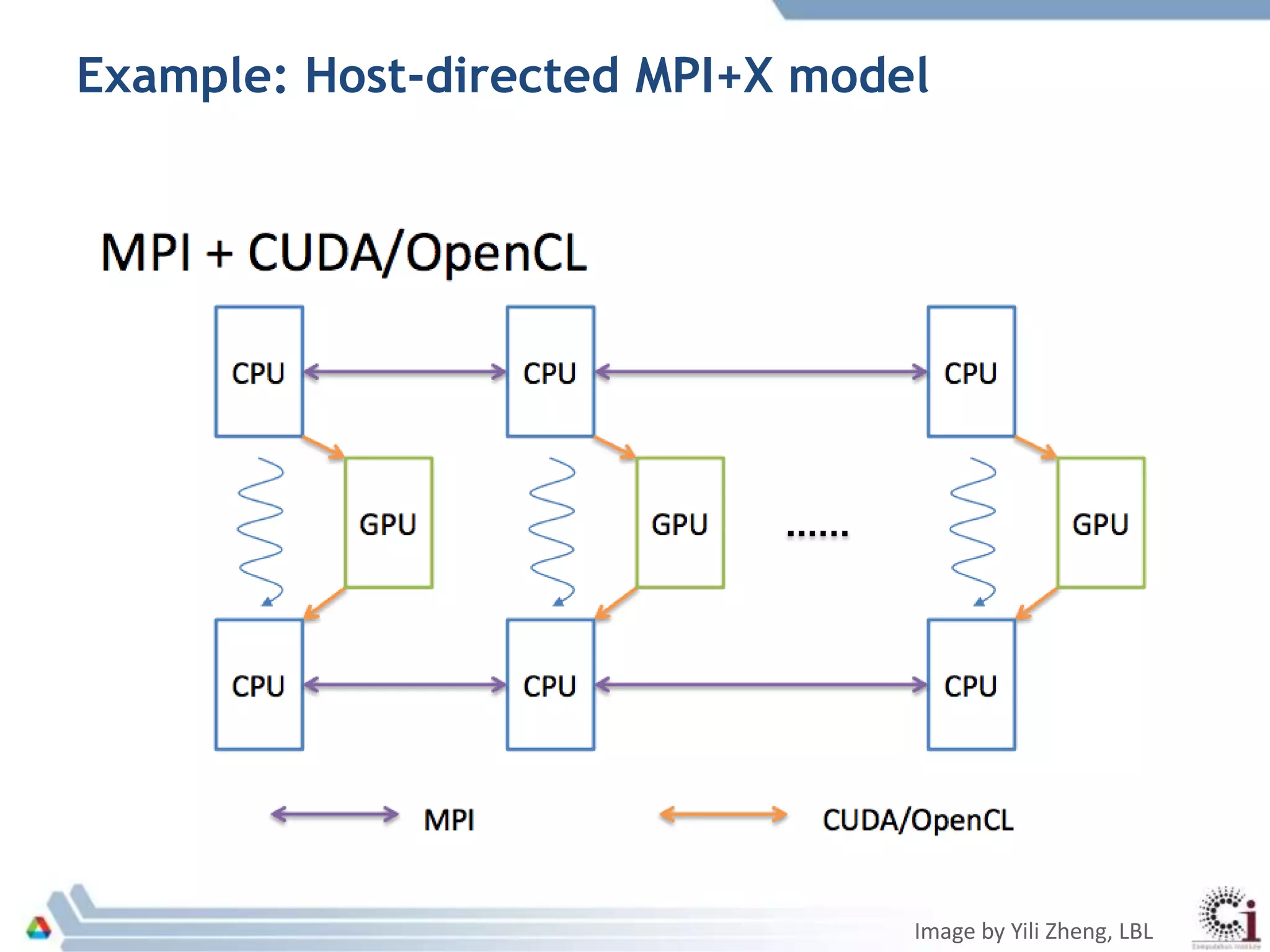
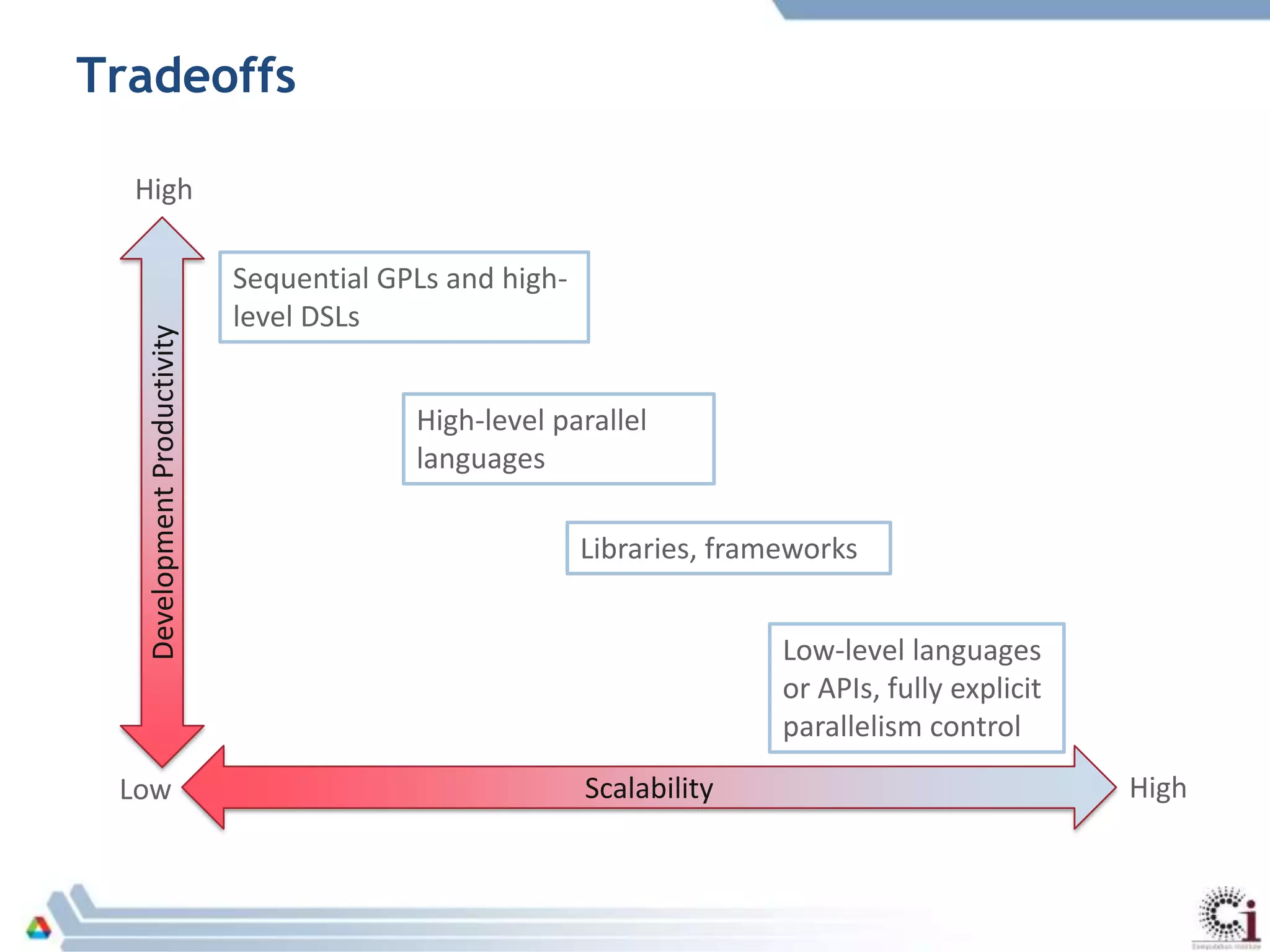
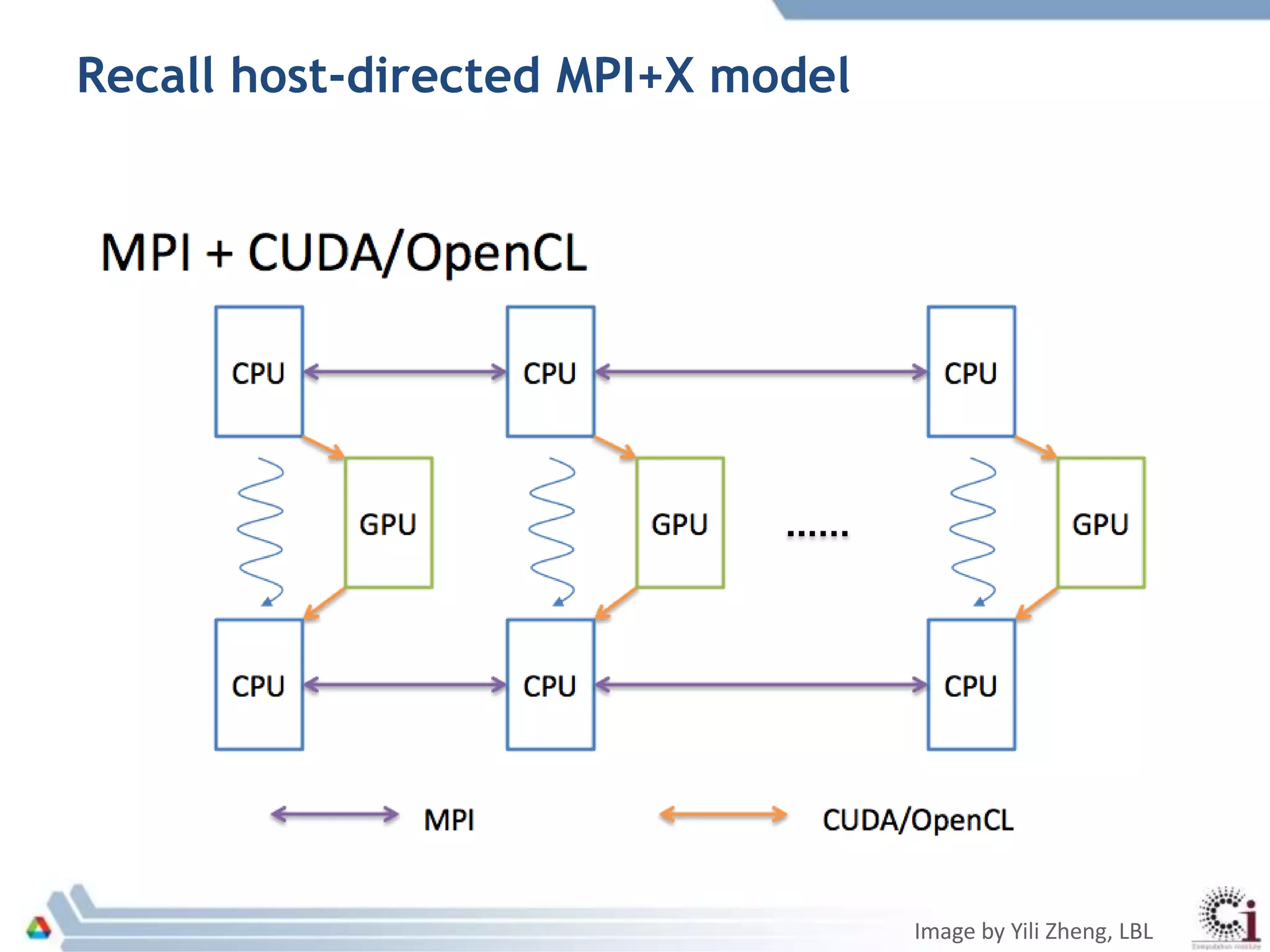
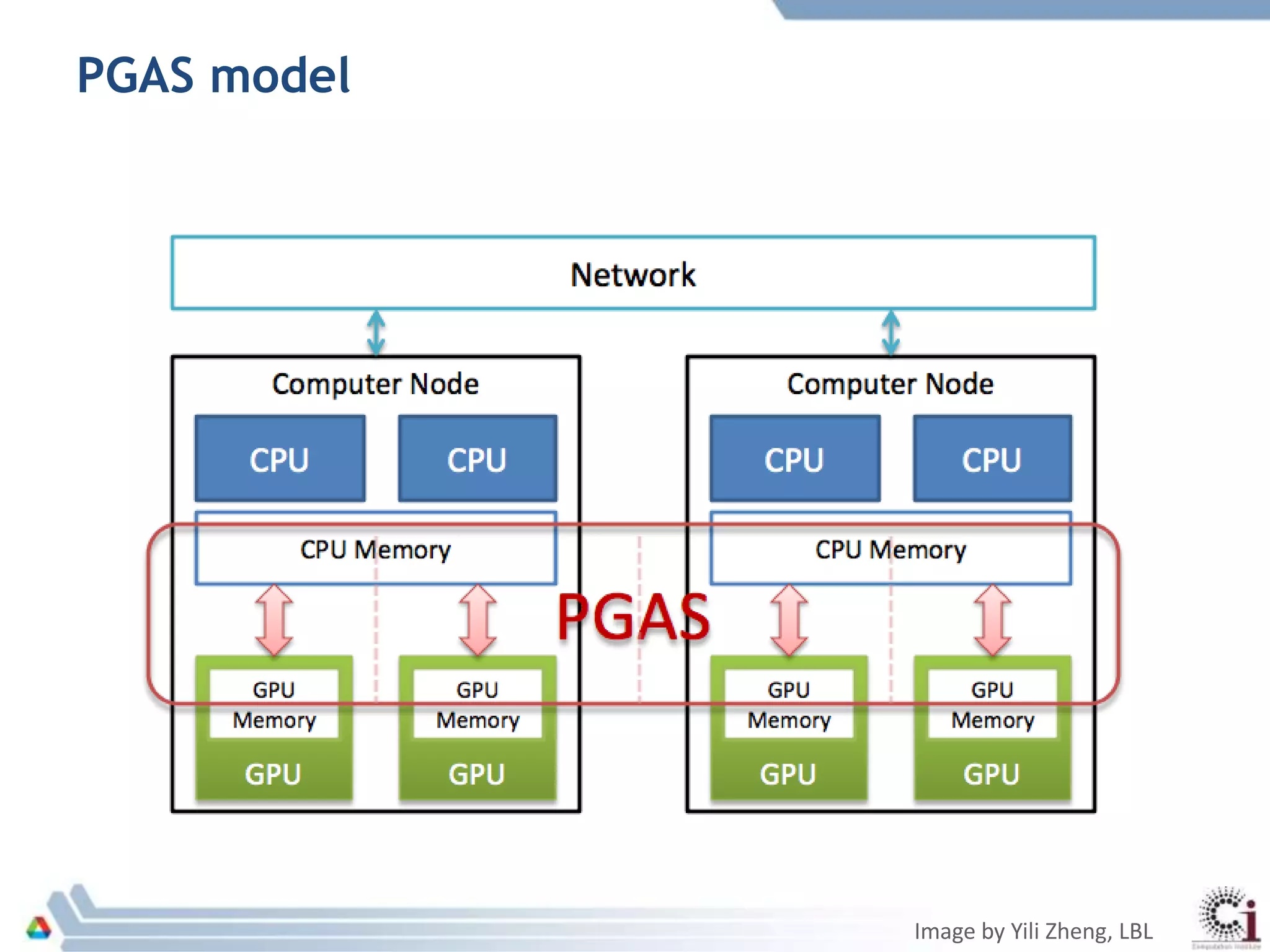
The document discusses programming models and challenges related to heterogeneous architectures, highlighting both hardware and software diversity. It examines various parallel programming models and the limitations faced by developers in managing data and performance across different platforms. Ongoing efforts aim to enhance programming tools and frameworks to better support applications on exascale systems while balancing scalability and productivity.