
Downloaded 48 times



![Copyright © 2014 Oracle and/or its affiliates. All rights reserved. |
What is a hash-function?
– Hash function application is cheap
– Hash values are typically “evenly
distributed” in range
• Irrespective of distribution of input values
– Collisions can occur
• Two domain values map to same hash value
• Since #domain >> #range
Domain Range
Hash
function
Digital data
Byte strings of any length
“Hash values”
Offset between
[0..some-power-of-2 minus 1]](https://image.slidesharecdn.com/hashjoinsandbloomfiltersatamis25-160608083350/75/Hash-joins-and-bloom-filters-at-AMIS25-5-2048.jpg)





![Copyright © 2014 Oracle and/or its affiliates. All rights reserved. |
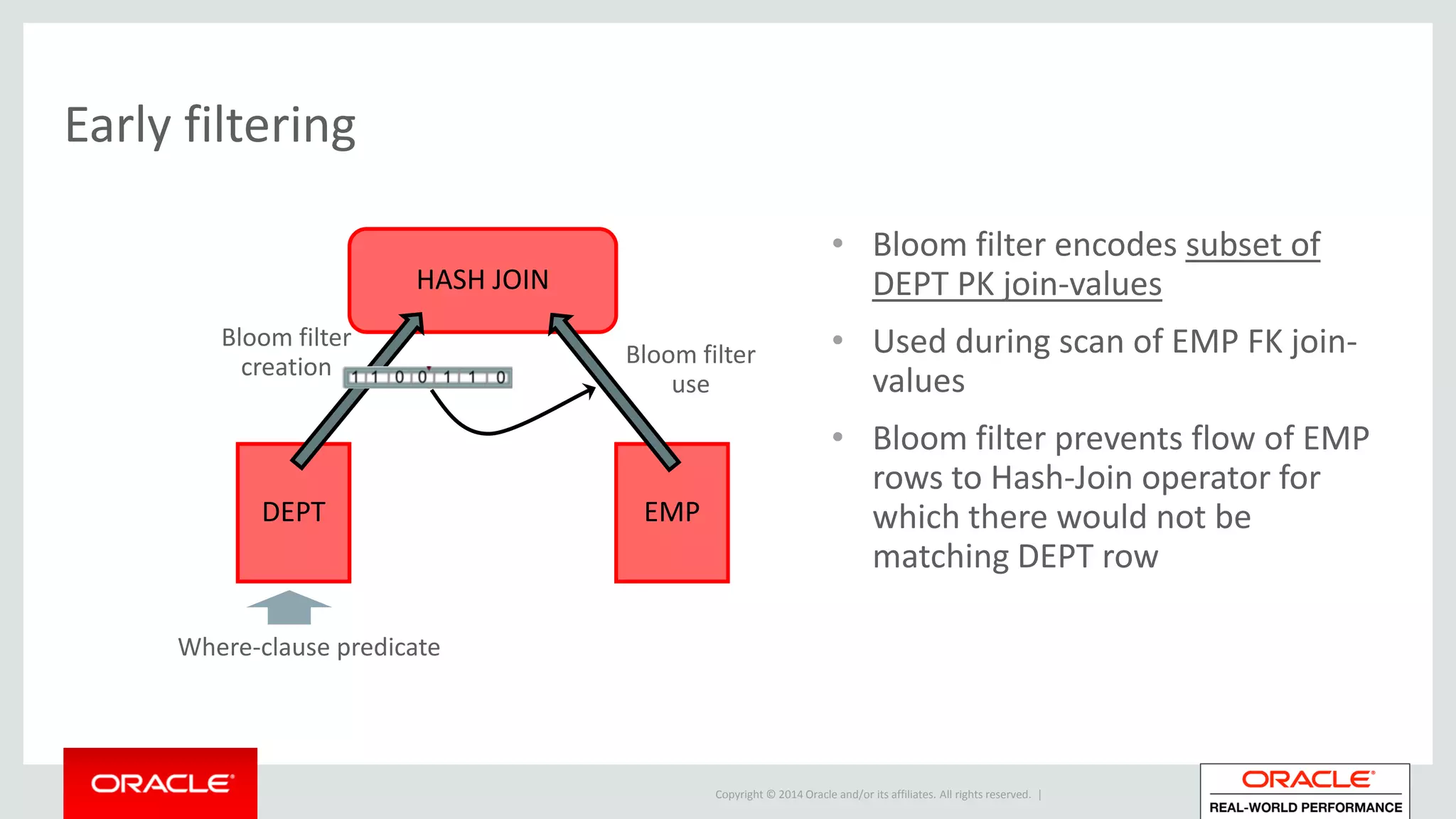
Bloom filter concept
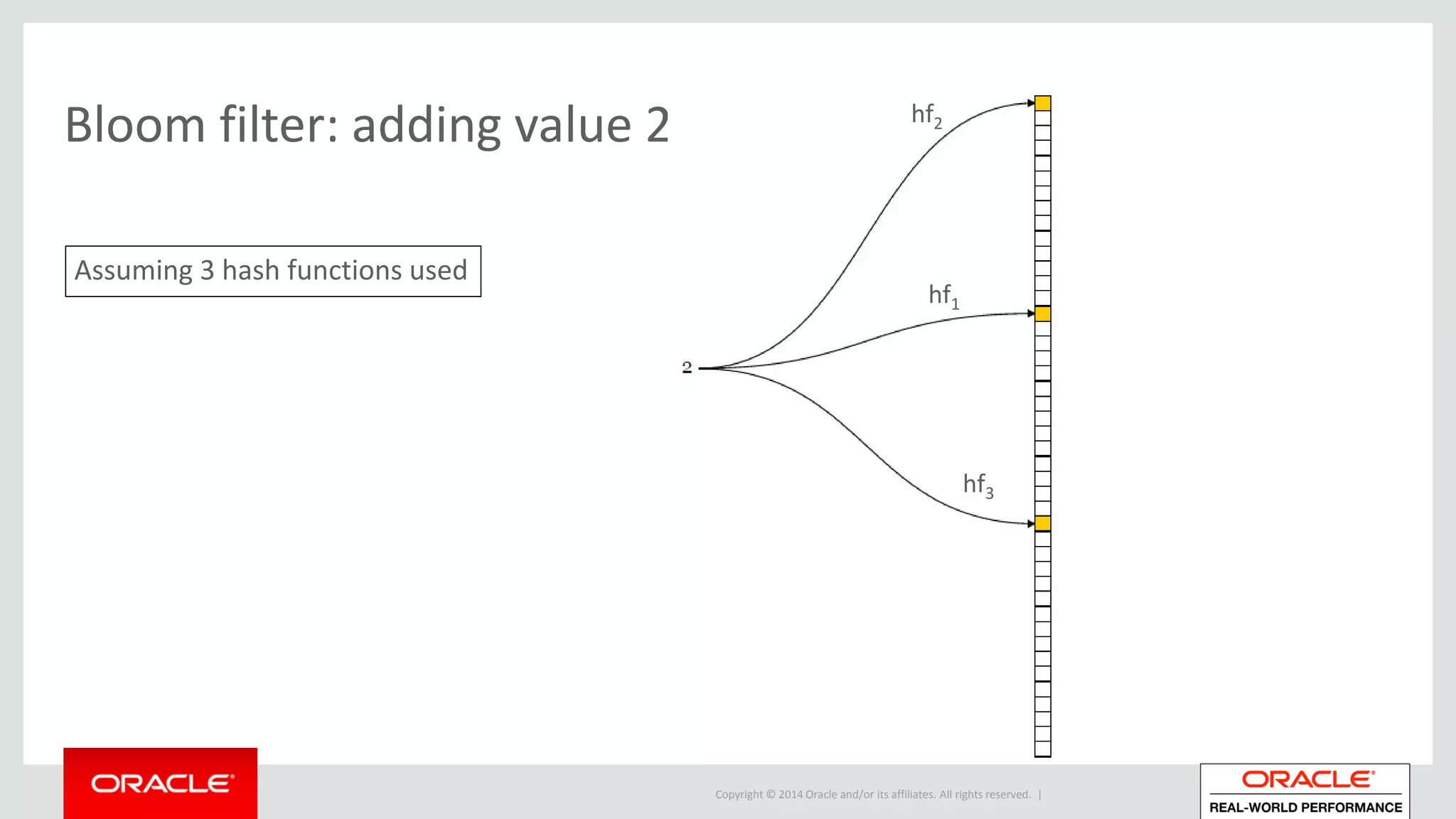
• BF(m,k)
– m = size of memory structure in bits array of m bits
– k = number of hash functions used to encode value (hf1,…,hfk)
• Range of hash functions is: [0..m]
Bit array initially filled with 0’s
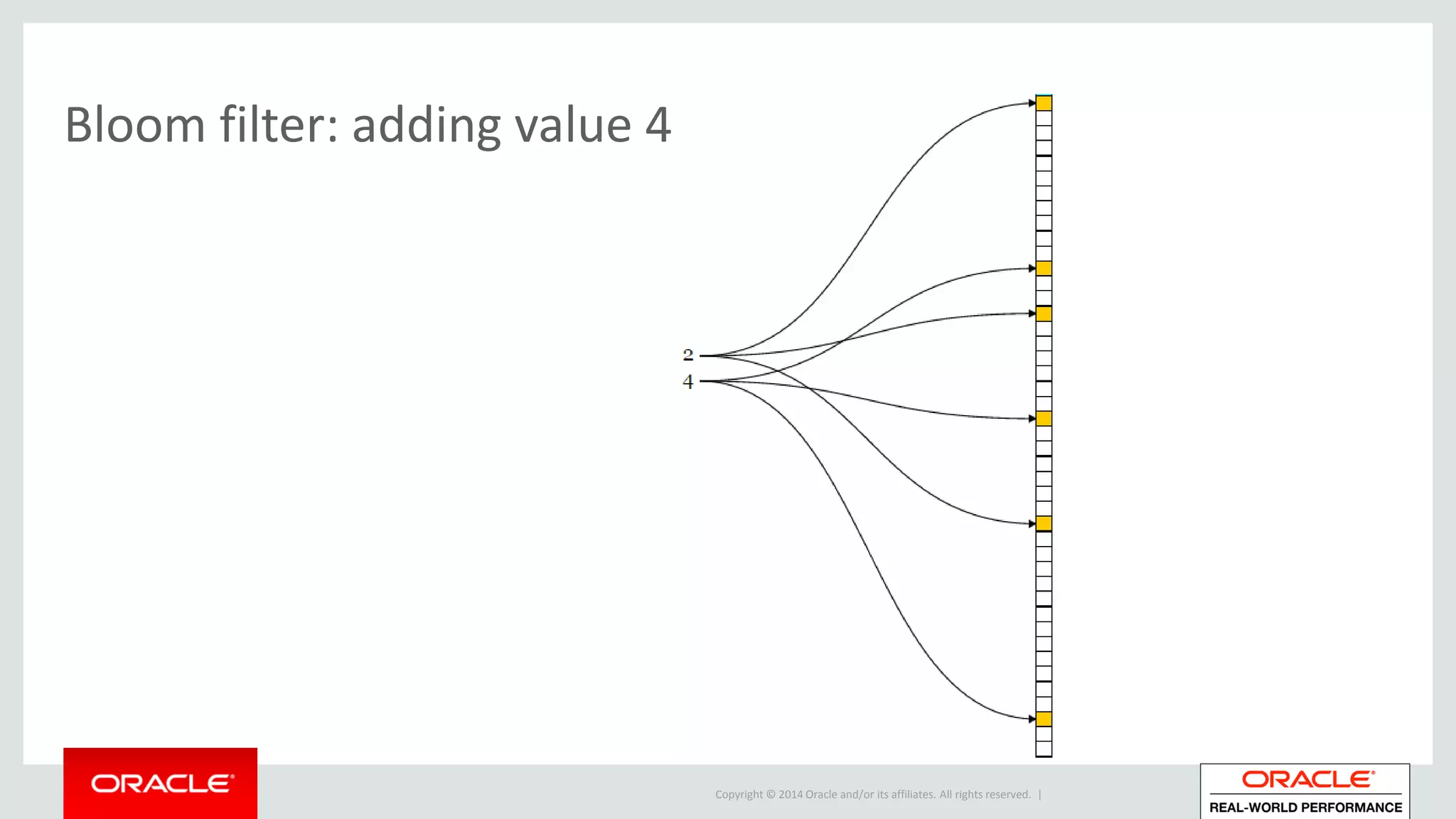
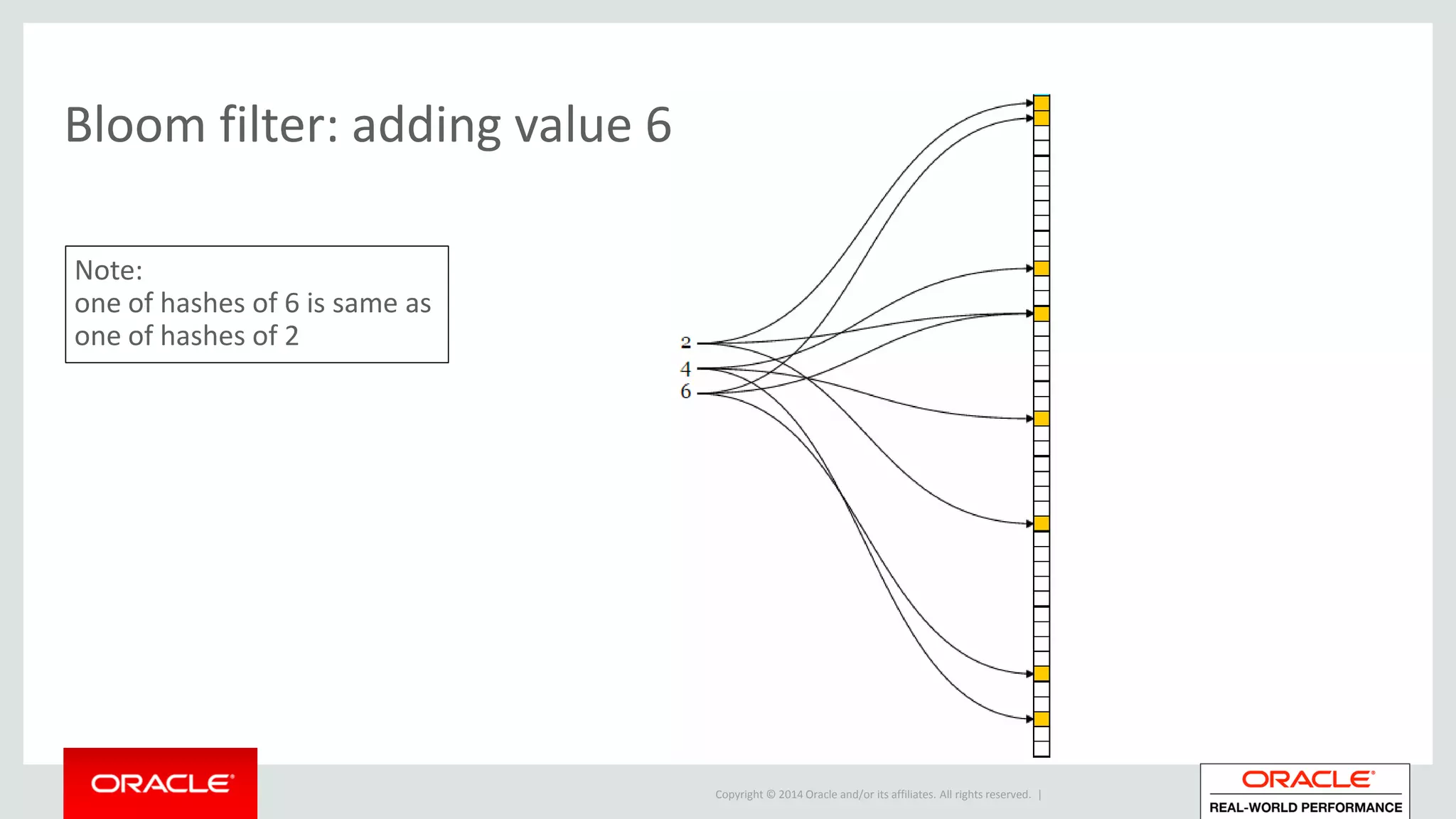
• Adding (encoding) a value x:
– Apply each hash-function to value x this produces k hash-values
– Set bit in array at each hash-value’s position](https://image.slidesharecdn.com/hashjoinsandbloomfiltersatamis25-160608083350/75/Hash-joins-and-bloom-filters-at-AMIS25-21-2048.jpg)












![Copyright © 2014 Oracle and/or its affiliates. All rights reserved. |
Final remarks
• Bloom filter are pushed down to storage cells and DBIM scans
• SQL Monitor report has details on Bloom filter
– V$sql_join_filter
• Hints px_join_filter() / no_px_join_filter()
• alter session set events 'trace[RDBMS.Bloom_filter] …'
• Event 10128 Bloom pruning filter](https://image.slidesharecdn.com/hashjoinsandbloomfiltersatamis25-160608083350/75/Hash-joins-and-bloom-filters-at-AMIS25-40-2048.jpg)


This document discusses Bloom filters and how they are used to optimize hash joins in Oracle databases. It provides examples of how hash joins work in serial and parallel execution plans. Bloom filters allow the cost-based optimizer to "filter early" in hash joins by preventing unnecessary row transportation between parallel query slave sets. The document explains the build and probe phases of hash joins and how Bloom filters can filter rows before they flow through parent execution stages, improving performance.
Introduction to Bloom filters, hash functions, and hash joins as part of the performance optimization agenda.
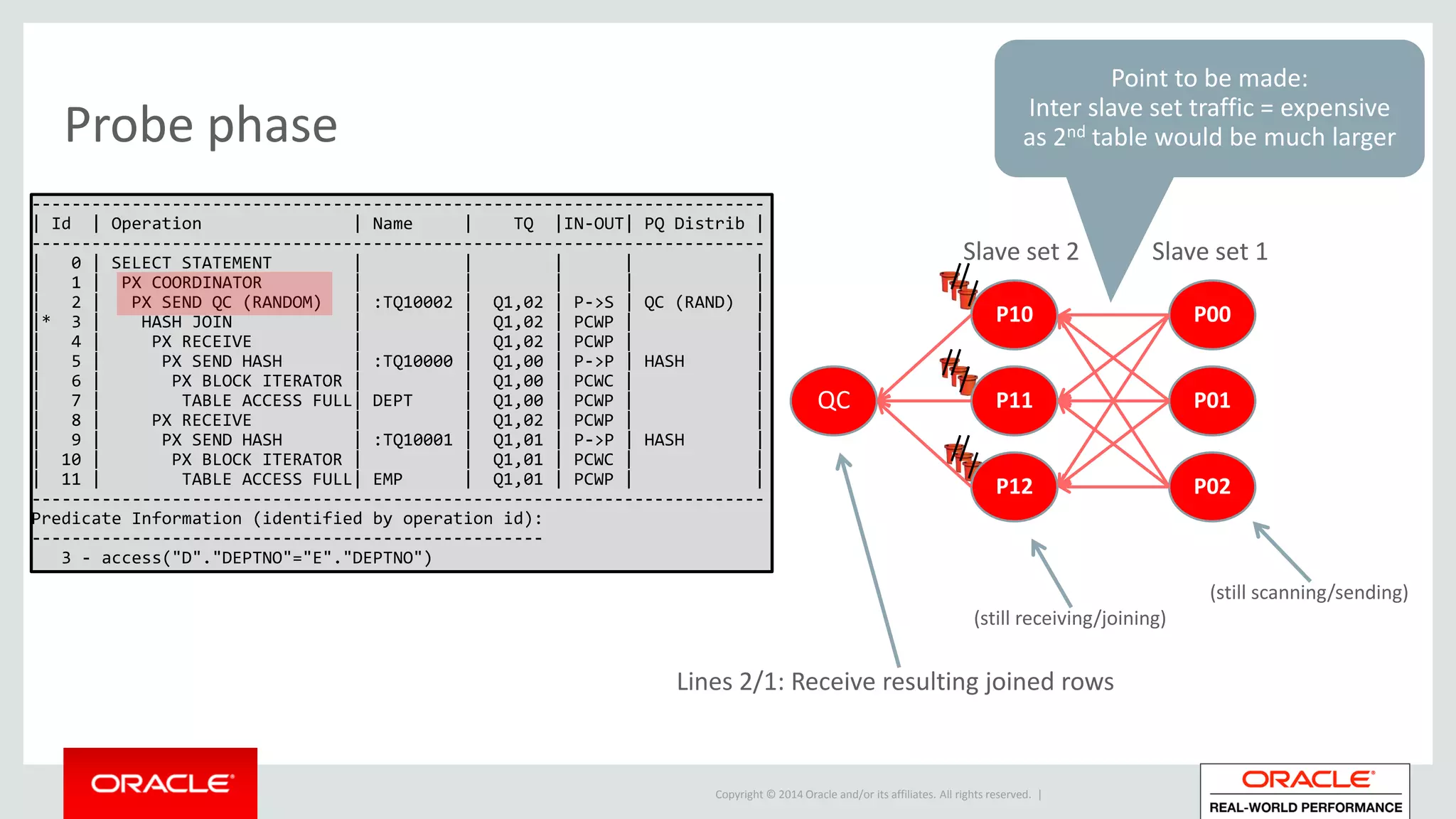
Explanation of how Bloom filters improve performance in hash joins by early filtering in execution plans.
Description of hash functions: their cheap implementation, collision possibilities, and characteristics.
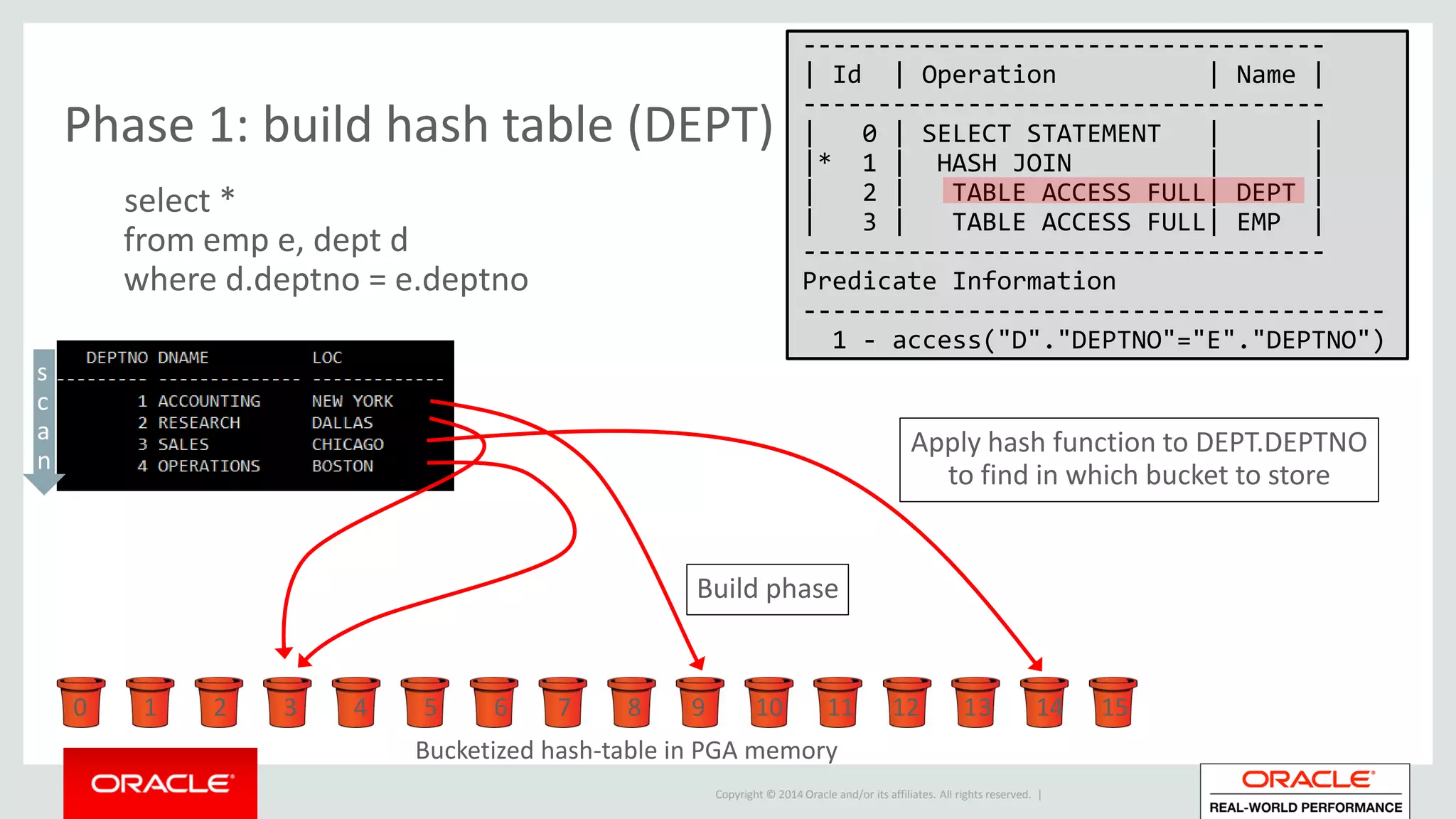
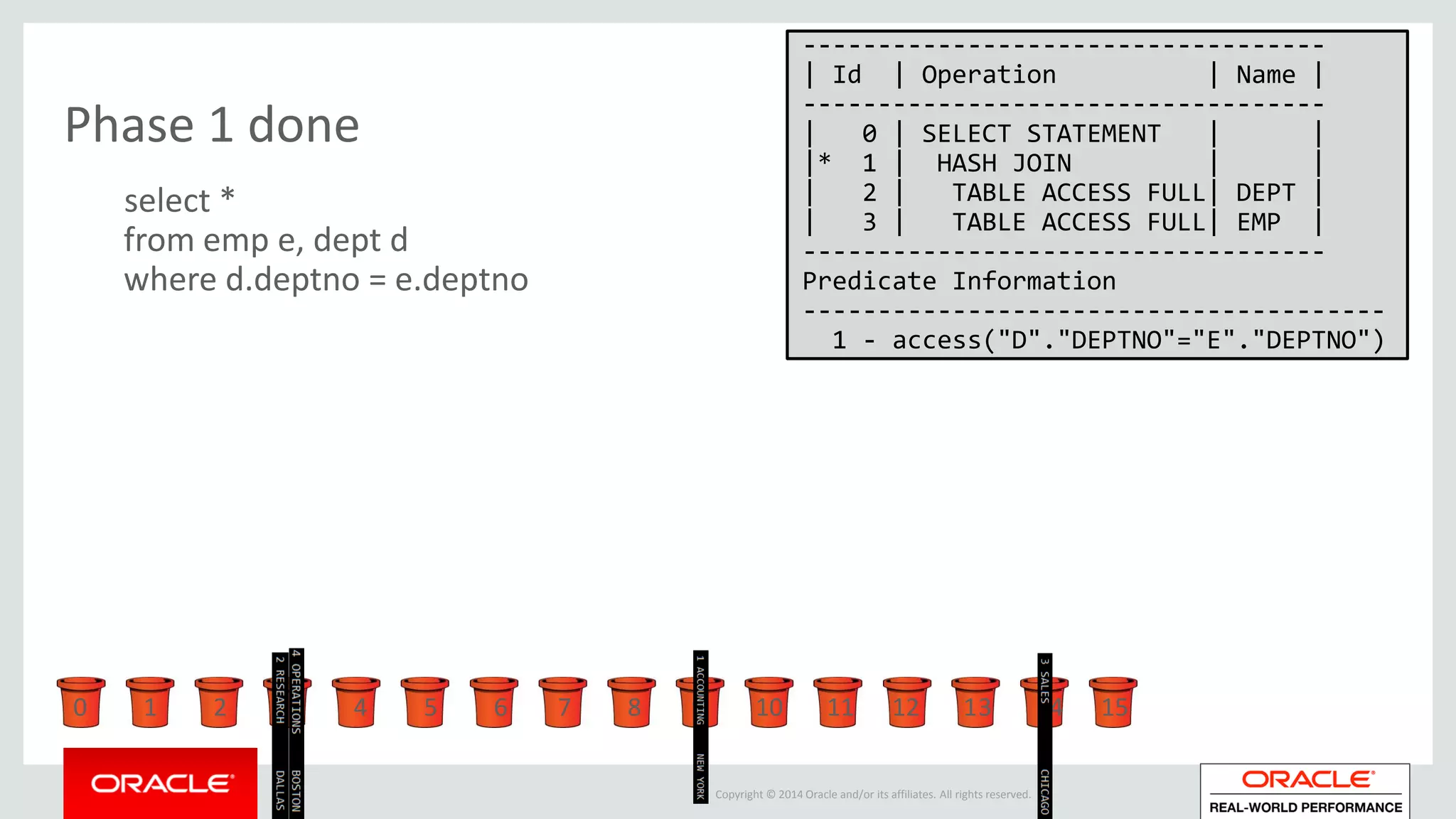
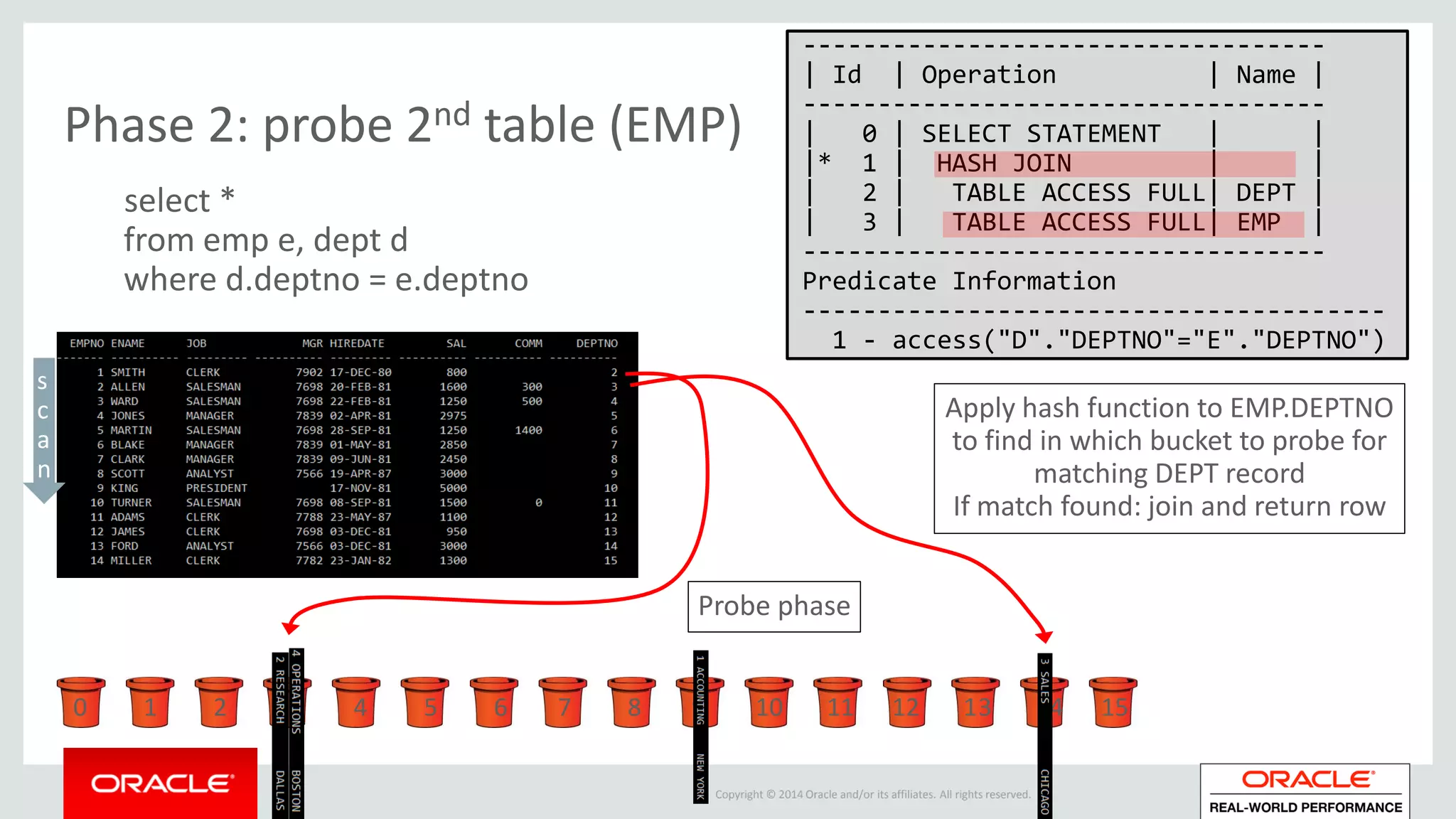
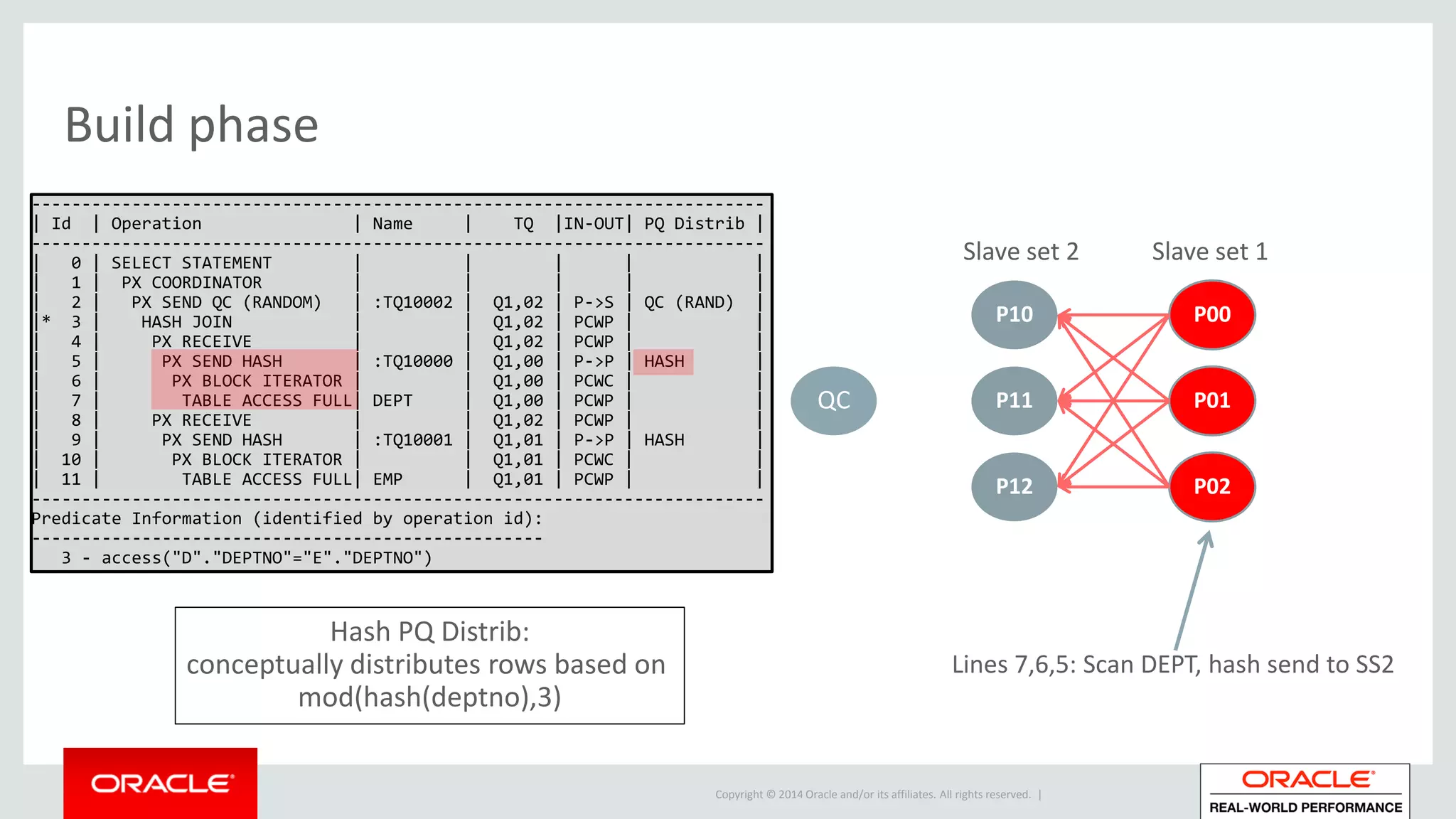
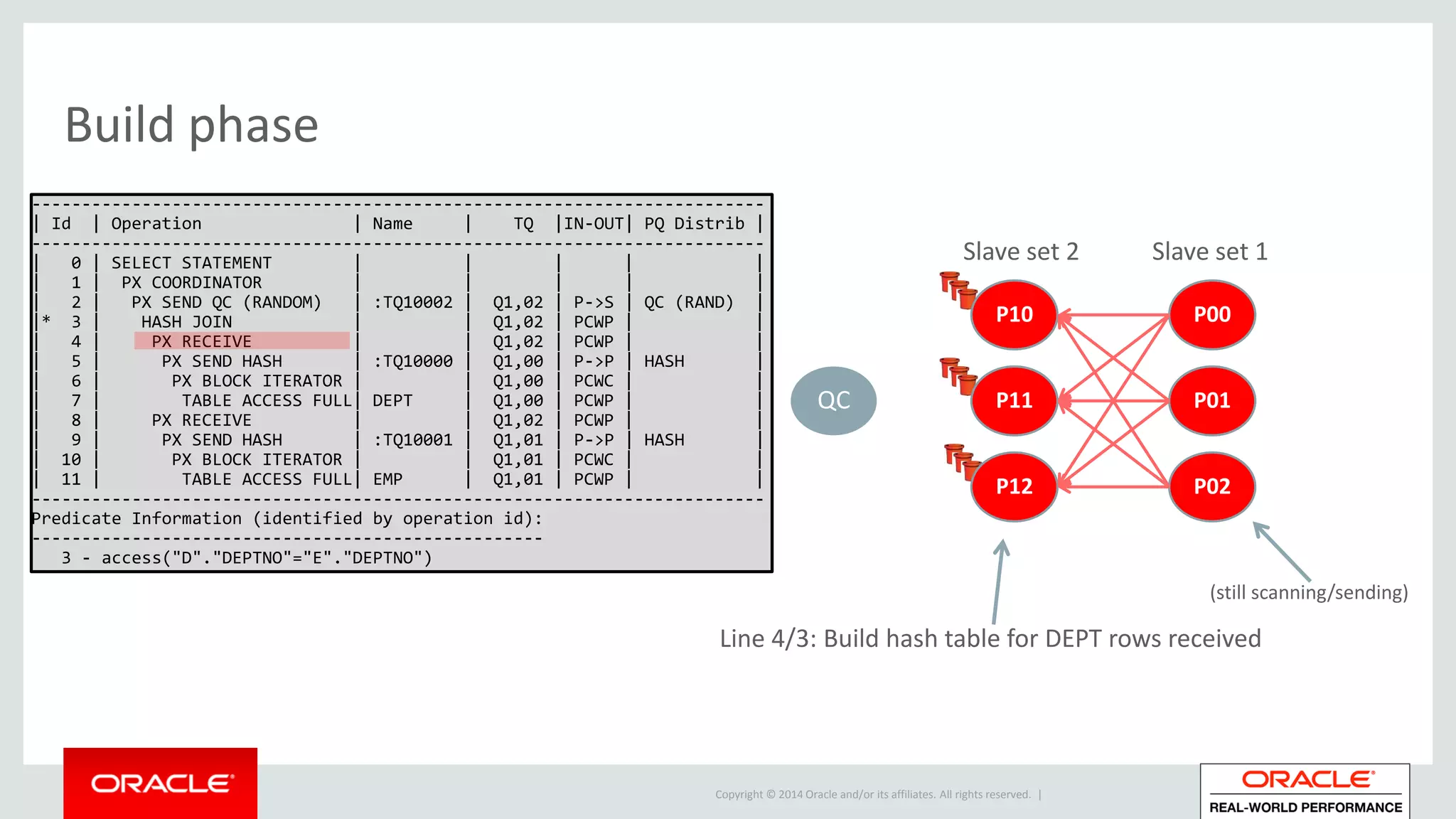
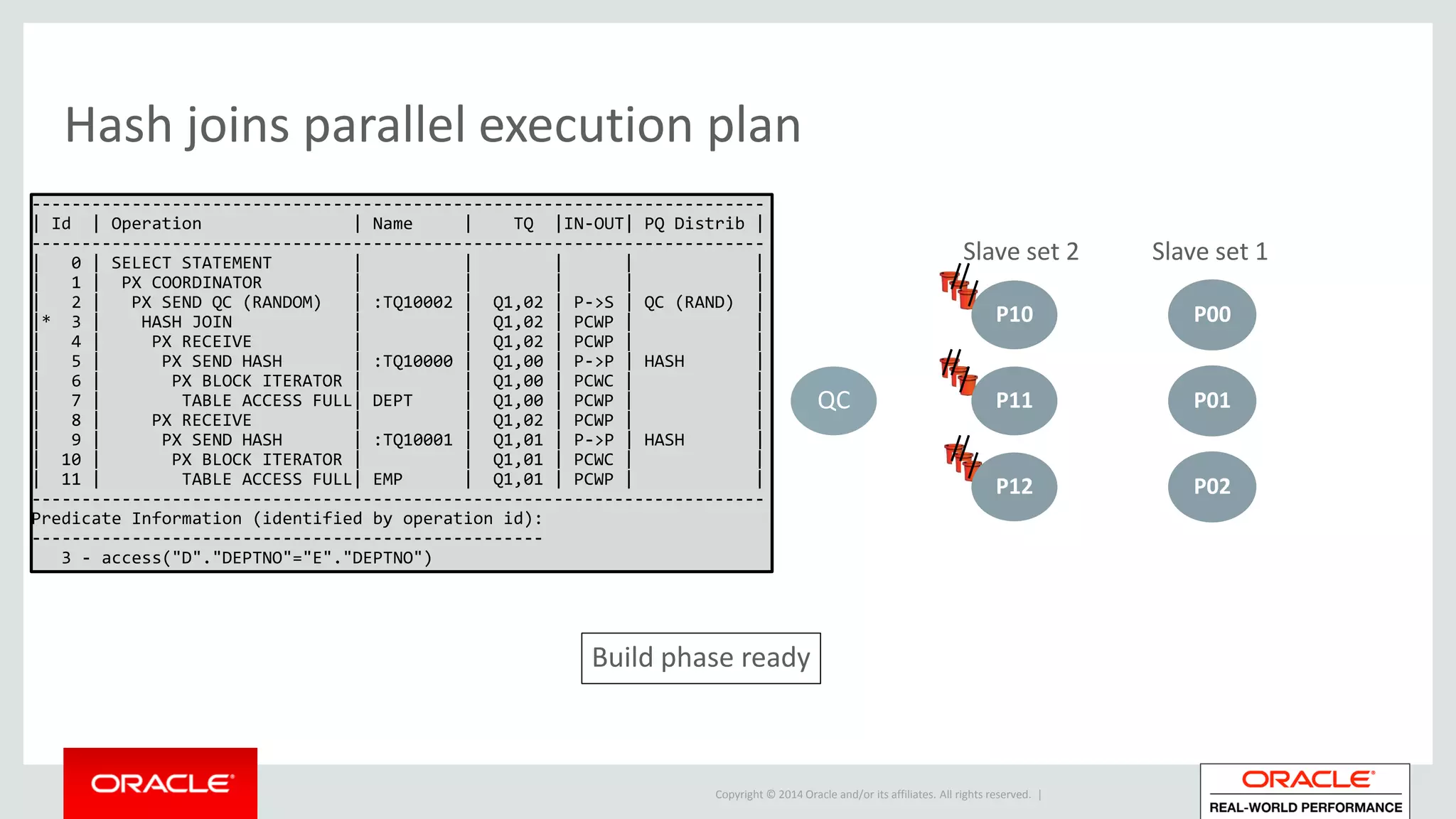
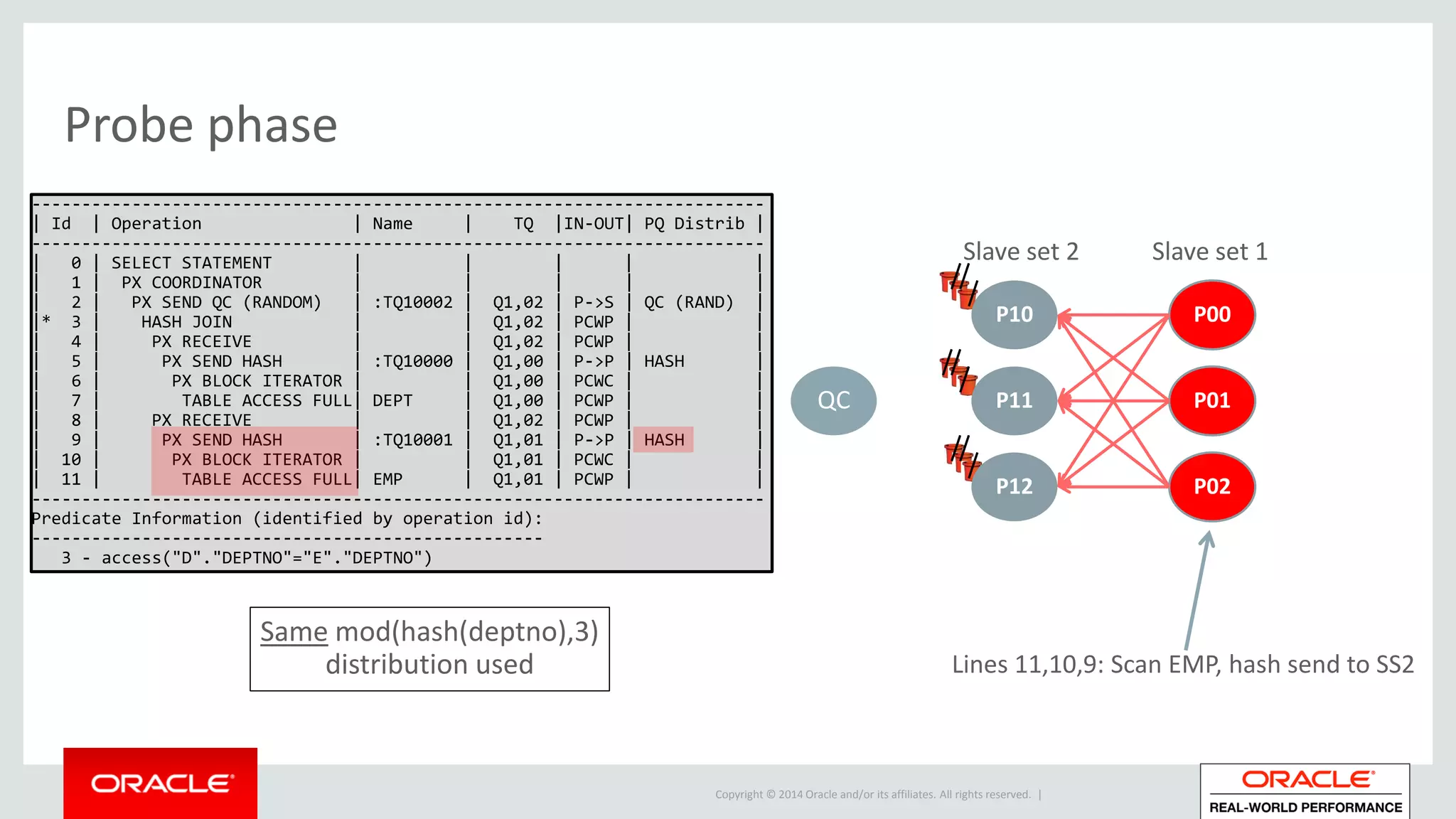
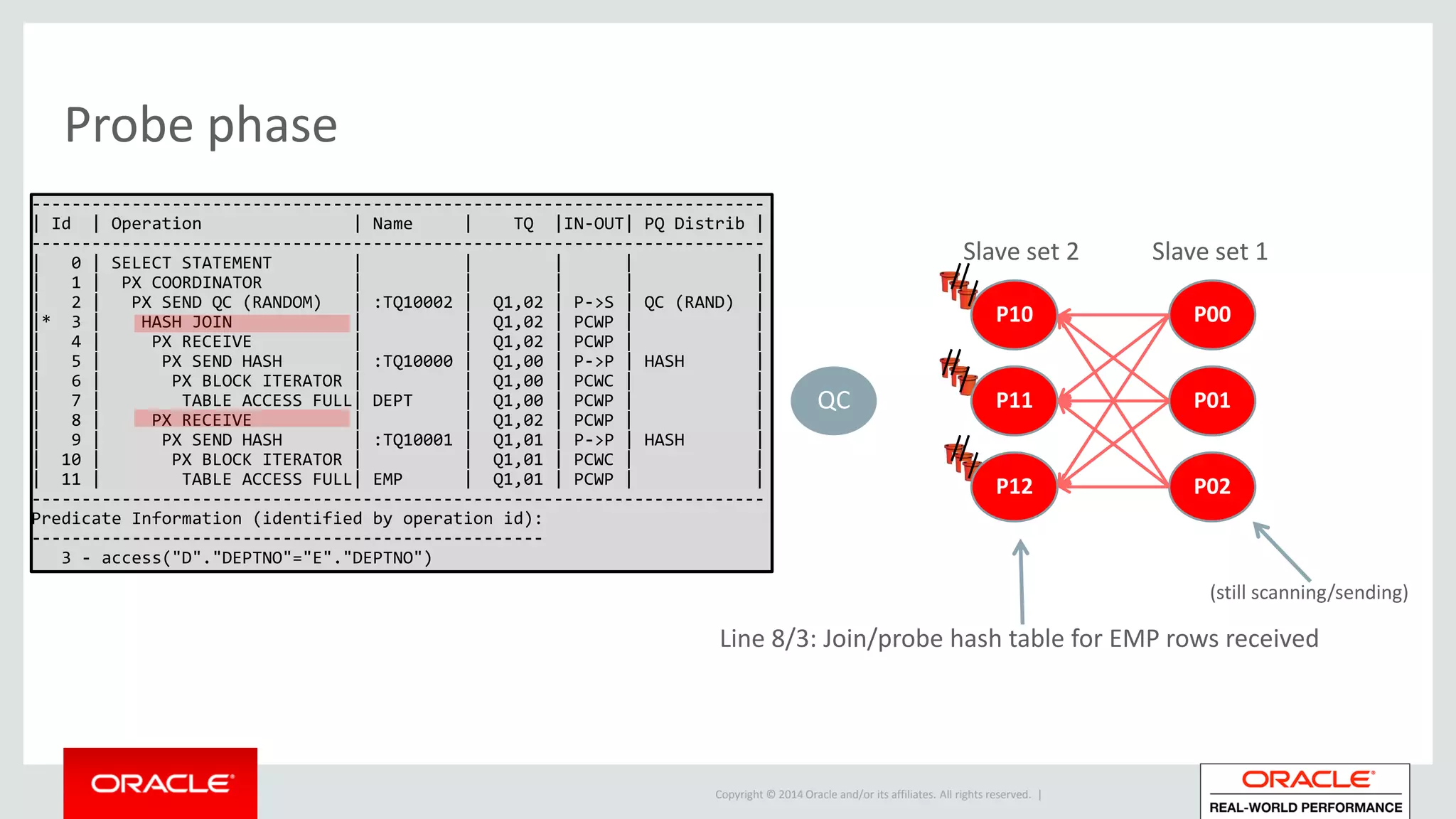
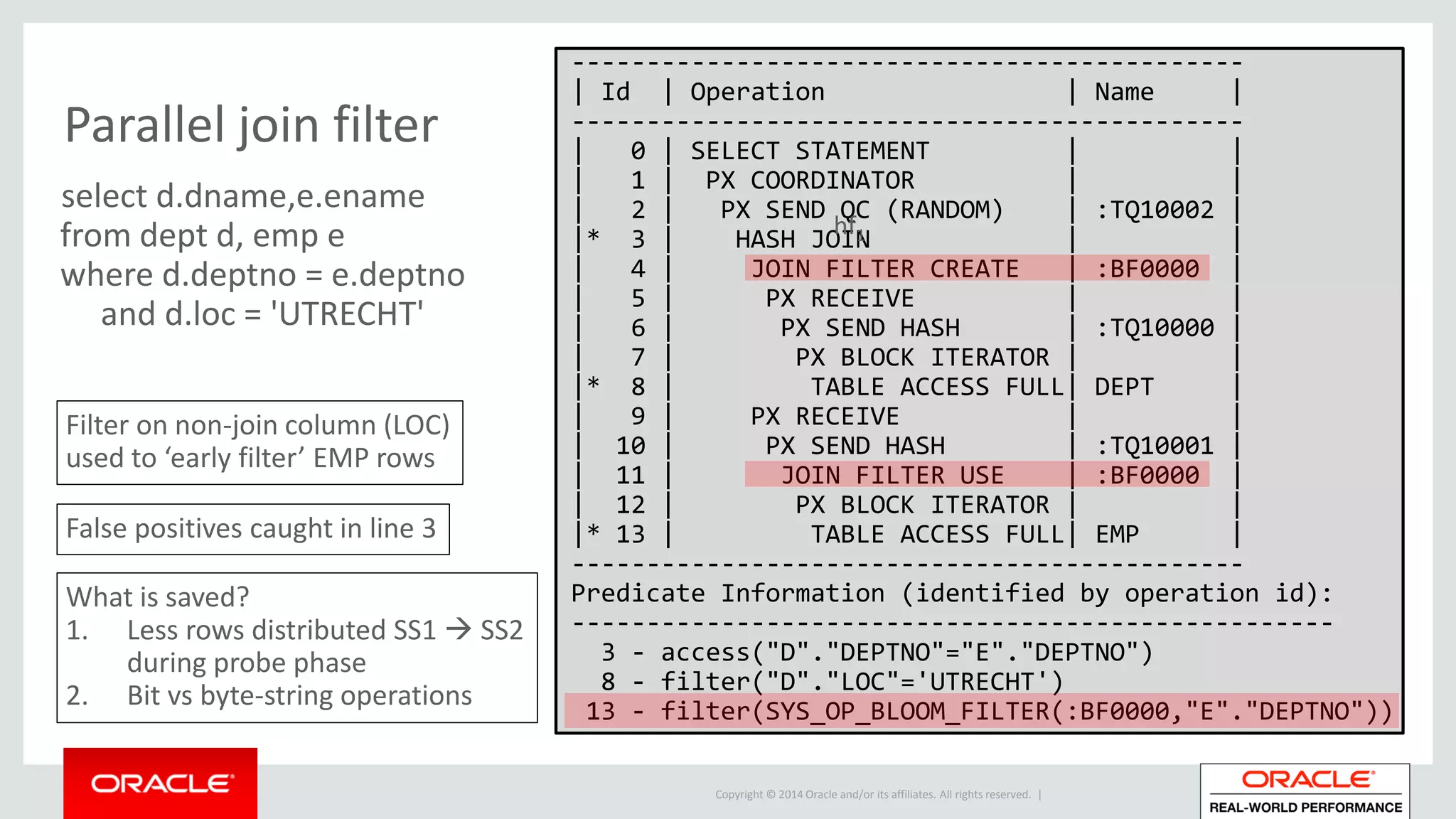
Detailed phases of hash join execution, including building hash tables and probing for matching records. Illustration of parallel hash join execution plans and their operation information.
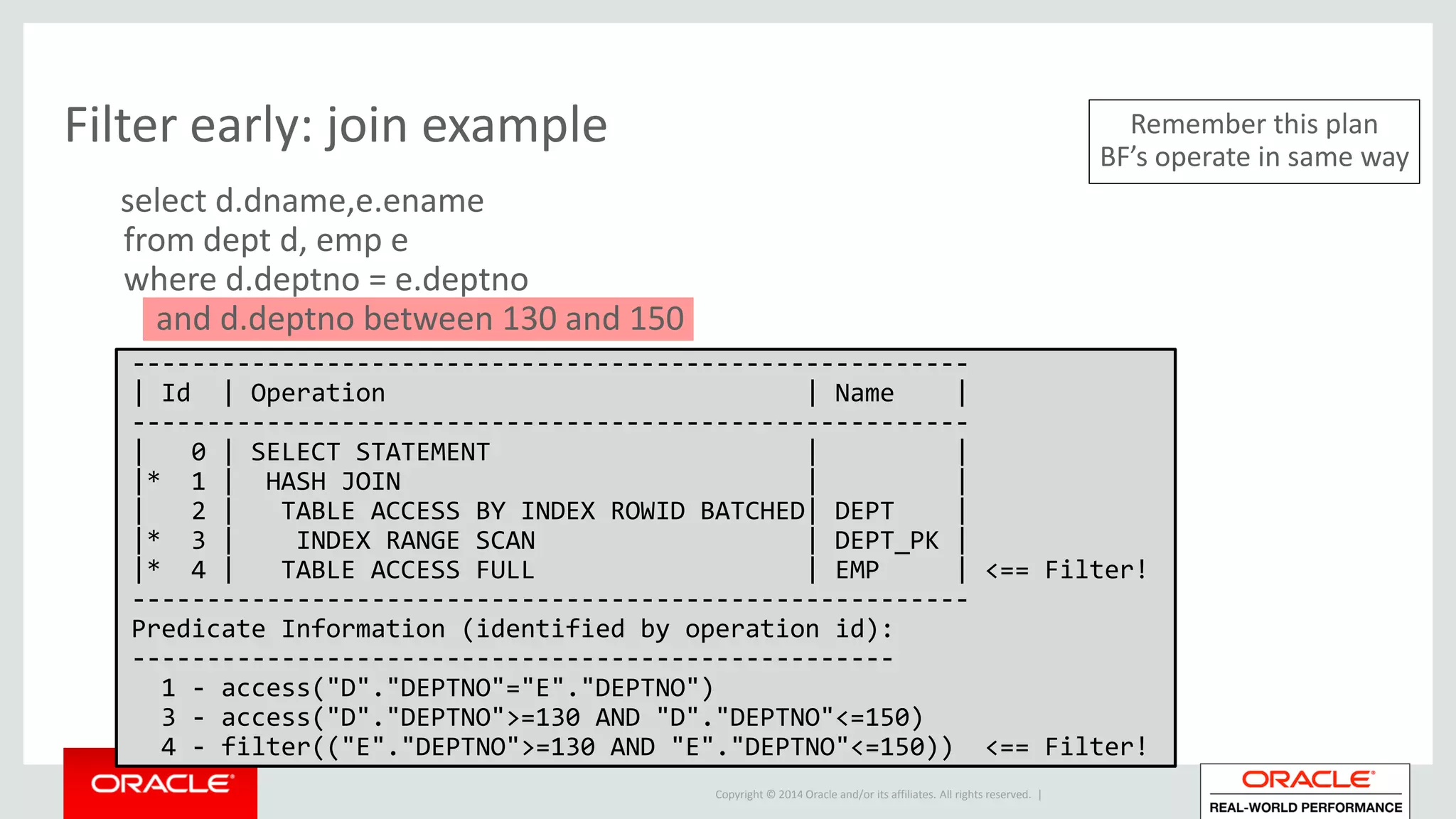
Explanation of the concept of filtering early in execution plans and the basic workings of Bloom filters.
Specifics of Bloom filter construction, membership tests, expected false positives, and their efficiency.Applications of Bloom filters in hash join operations to enhance efficiency and reduce unnecessary data flow.
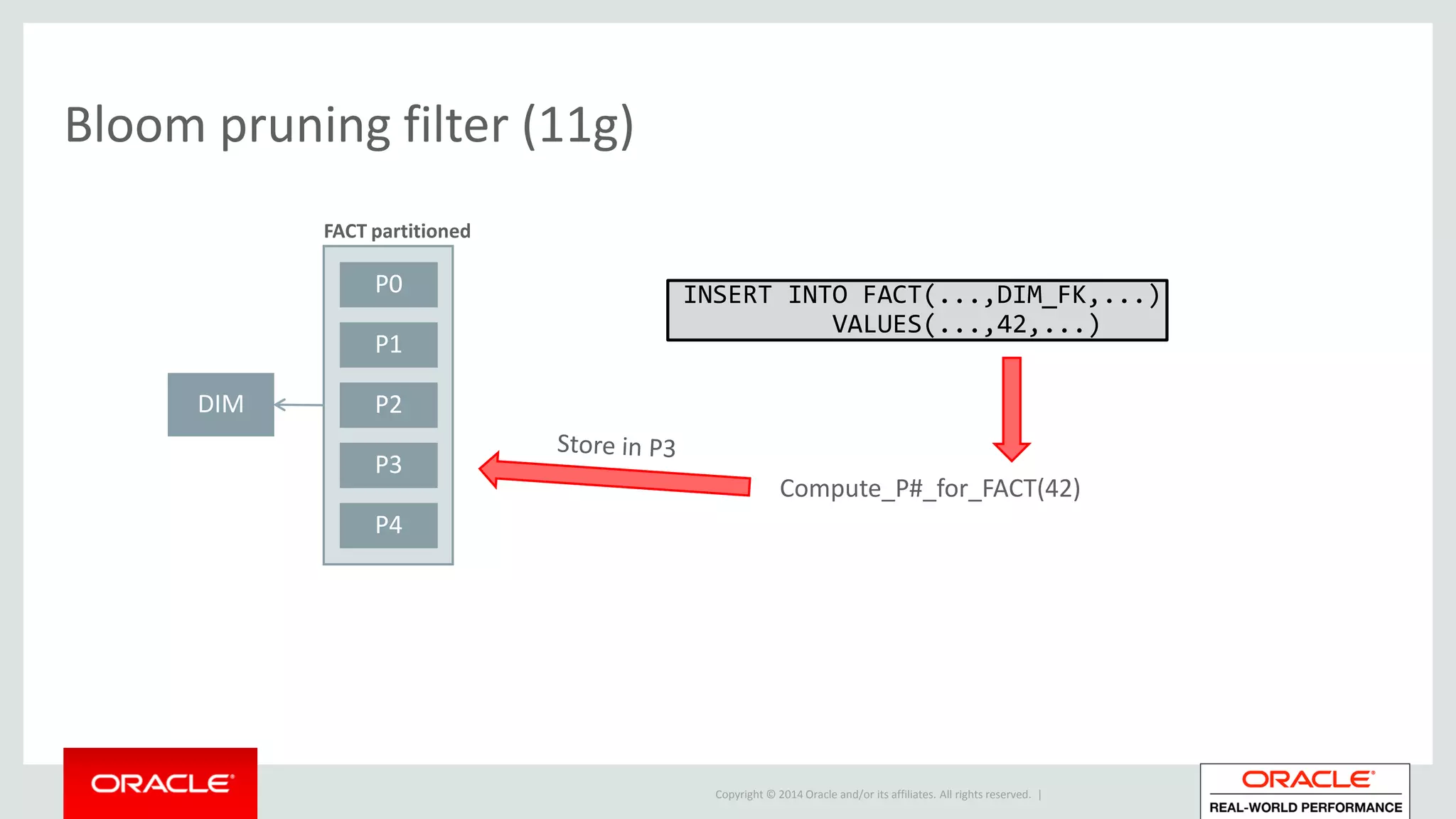
Utilization of additional Bloom filters for efficient data handling and partitioned joins within database systems.
Final comments on the utility of Bloom filters, SQL monitoring, and suggestions for community engagement.

















![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)





































































