Downloaded 27 times







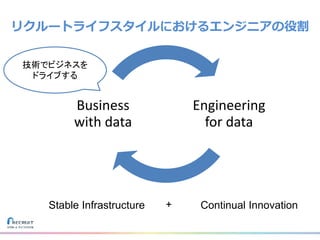

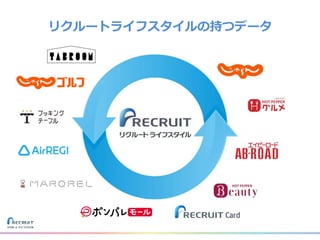
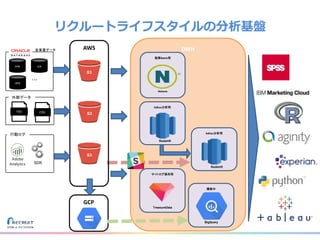
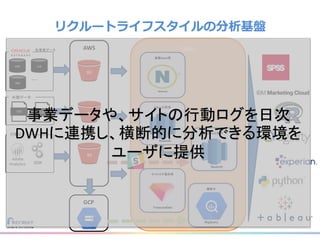
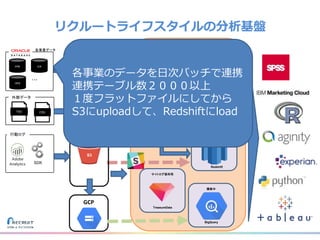
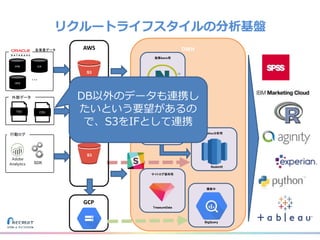
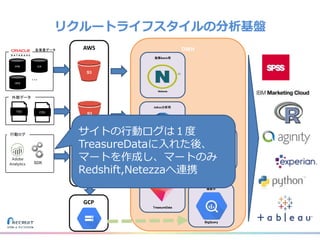
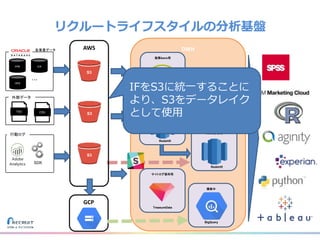
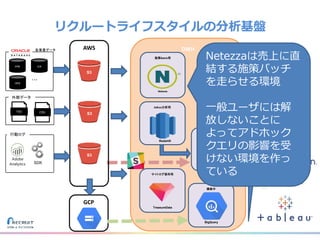
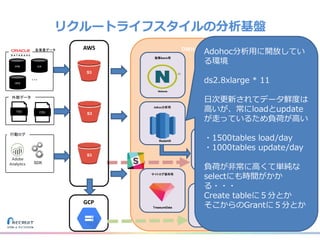
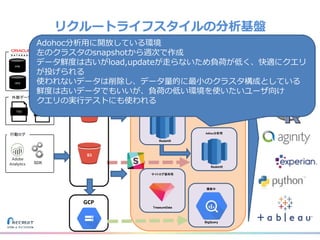
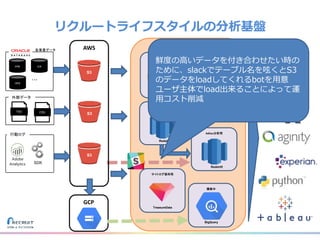
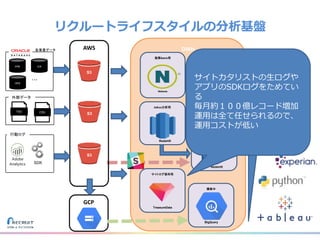
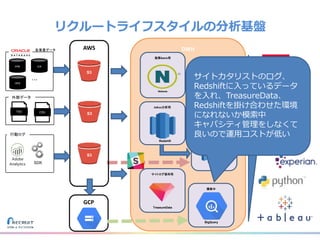
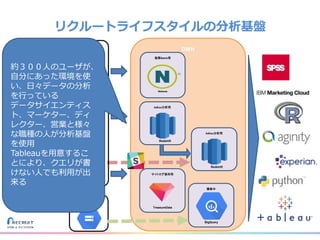
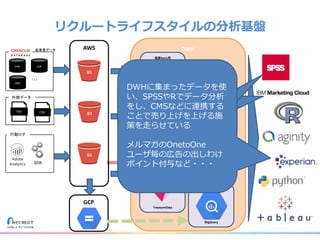
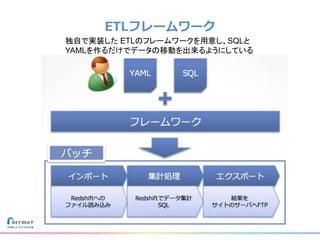
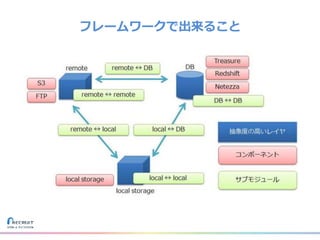
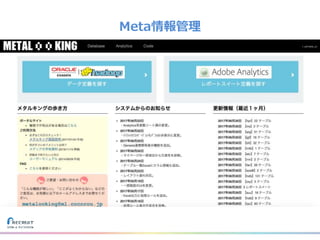
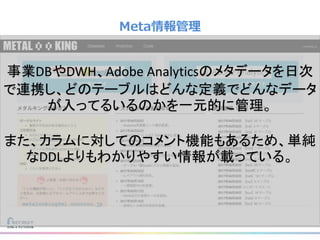
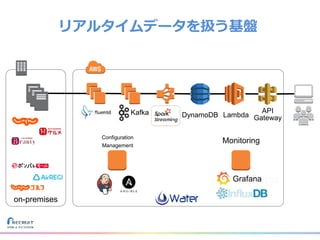
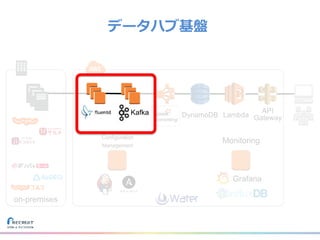
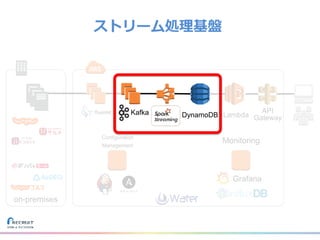
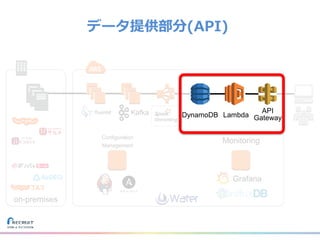




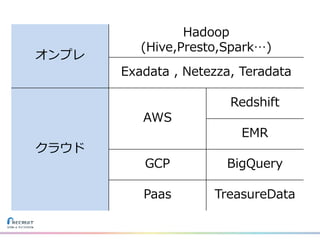

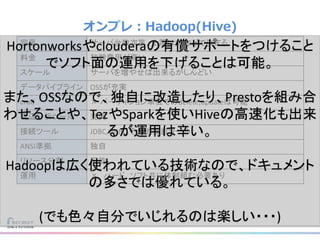

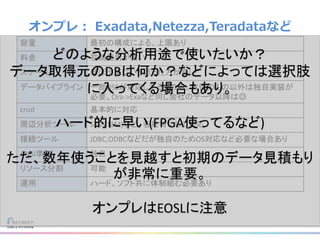




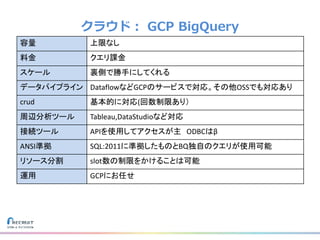



















リクルートライフスタイルではじゃらん、ホットペッパーグルメ、ホットペッパービューティーなど約30のサービスを展開しています。 それらのデータを全社共通で使えるように、オンプレ、クラウドのハイブリッドでビックデータ基盤を構築しています。 メール配信に使われるバッチやアドホック分析、レポーティングなど様々な用途で使われる中、どうバッチに影響を出さない基盤を作るのか、なぜクラウドだけではなく、オンプレなど複数のDBを使っているのか、なぜその基盤を選んだのか、データ基盤の比較とともに紹介します。 山田 雄(株式会社リクルートライフスタイル)



































![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)











