Downloaded 32 times








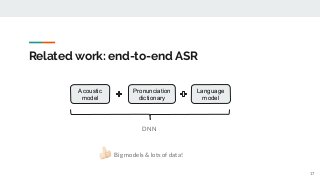
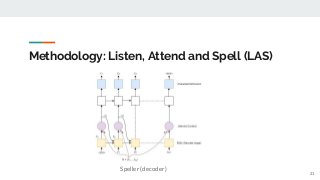




![Experiments: [1] NABU
Encoder
- Layers 2 + 1 non-pyramidal while training
- Units/layer 128 per direction
Decoder
- Layers 1
- Units/layer 128
PER = 31,94%
29
Steps
Steps
Validation loss
Training loss](https://image.slidesharecdn.com/tfgjannaescurexploringautomaticspeechrecognitionwithtensorflow-180205105225/85/Exploring-Automatic-Speech-Recognition-with-Rensorflow-29-320.jpg?cb=1517827993)
![Experiments: [2] LAS
Encoder
- Layers 3
- Units/layer 256 per direction
Decoder
- Layers 2
- Units/layer 512
PER = 27.29%
30
Validation loss
Training loss
Steps
Steps](https://image.slidesharecdn.com/tfgjannaescurexploringautomaticspeechrecognitionwithtensorflow-180205105225/85/Exploring-Automatic-Speech-Recognition-with-Rensorflow-30-320.jpg?cb=1517827993)

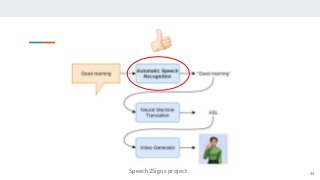

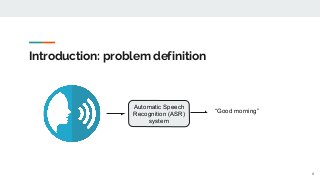
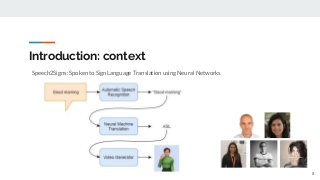
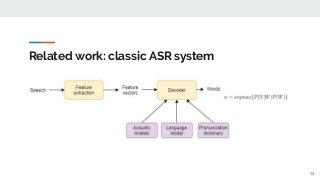
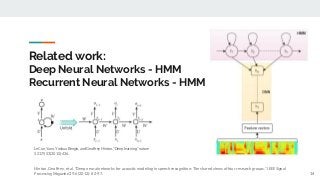
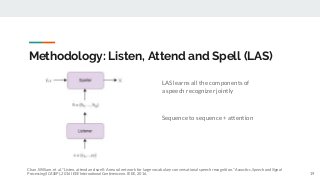
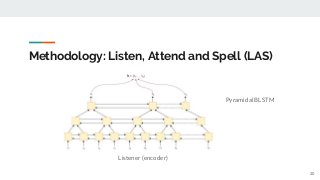
https://imatge.upc.edu/web/publications/exploring-automatic-speech-recognition-tensorflow Speech recognition is the task aiming to identify words in spoken language and convert them into text. This bachelor's thesis focuses on using deep learning techniques to build an end-to-end Speech Recognition system. As a preliminary step, we overview the most relevant methods carried out over the last several years. Then, we study one of the latest proposals for this end-to-end approach that uses a sequence to sequence model with attention-based mechanisms. Next, we successfully reproduce the model and test it over the TIMIT database. We analyze the similarities and differences between the current implementation proposal and the original theoretical work. And finally, we experiment and contrast using different parameters (e.g. number of layer units, learning rates and batch sizes) and reduce the Phoneme Error Rate in almost 12% relative.






























![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)