Download to read offline



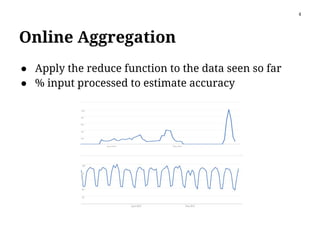













The paper discusses block sampling as a method for efficient online aggregation in MapReduce, enabling quicker access to useful results even before job completion. It highlights challenges such as slow random disk access and the need for effective sampling strategies given unstructured data. The authors propose a technique that uses in-memory shuffling to improve sampling rates and accuracy while reducing the communication costs among mapper tasks.























































