Data security and privacy techniques for on-premises, public, and private clouds

A common question is how to choose data protection techniques for different deployment models. Unfortunately, such a simple question is rather difficult to answer. An information security professional might respond with “it depends,” which is quite reasonable but sadly unhelpful. Many data protection techniques share similarities and have differences. This article compares data protection techniques and deployment models to help answer the conundrum: how to protect data when using the different deployment models. Things to consider include whether the data is being protected from unauthorized ac¬cess when stored, when being transmitted, or when being processed and the operational need from different business use cases. A Risk Adjusted Computation model can provide separation of duties and balance requirements between security and operational needs on-premises, in public or private cloud.

Recommended
More Related Content
Similar to Data security and privacy techniques for on-premises, public, and private clouds
Similar to Data security and privacy techniques for on-premises, public, and private clouds (20)
More from Ulf Mattsson
More from Ulf Mattsson (20)
Recently uploaded
Recently uploaded (20)
Data security and privacy techniques for on-premises, public, and private clouds
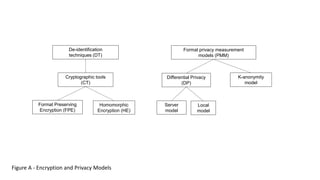
- 1. Server model Local model Differential Privacy (DP) Formal privacy measurement models (PMM) De-identification techniques (DT) Cryptographic tools (CT) Format Preserving Encryption (FPE) Homomorphic Encryption (HE) K-anonymity model Figure A - Encryption and Privacy Models
- 2. Clear text data 123123 FPE Encryption FPE Decryption Encryption Key FPE encrypted data 897645 Figure B - Format Preserving Encryption (FPE) Clear text data 123123
- 3. Operation on encrypted data HE Decryption HE Encryption HE Encryption Clear text data 12 Encryption Key Clear text data D2 Encrypted data Encrypted data “Untrusted Party” Clear text data D1 Figure C - Homomorphic Encryption (HE) Encrypted result
- 4. Protected Curator (Filter) Output Cleanser (Filter) Input Protected Database Figure D - Differential Privacy (DP)
- 5. Clear text data Cleanser Filter Database Figure E - k-Anonymity Model Clear text data
- 6. Shared responsibili ties across cloud service models Data Protection for Multi- cloud Figure F - Shared responsibilities across cloud service models (Microsoft) Responsibility On-prem IaaS PaaS SaaS Data classification & accountability User User User User Client & end-point protection User User User Shared Identity & access management User User Shared Shared Application level controls User User Shared Provider Network controls User Shared Provider Provider Host infrastructure User Shared Provider Provider Physical security User Provider Provider Provider
- 7. Risk Elasticity Out-sourcedIn-house On-premises system On-premises Private Cloud Hosted Private Cloud Public Cloud Low - High - Compute Cost - High - Low Figure G -Risk Adjusted Computation
- 8. 1970 2000 2005 2010 High Low Pain / TCO Strong Encryption Output: AES, 3DES Format Preserving Encryption DTP, FPE Vault-based Tokenization Vaultless Tokenization Input Value: 3872 3789 1620 3675 !@#$%a^.,mhu7///&*B()_+!@ 8278 2789 2990 2789 8278 2789 2990 2789 8278 2789 2990 2789 Year Figure H - Pain using Different Data Protection Techniques Output Value
- 9. Figure I –Tokenization Classification Tokenization Reversible De-Tokenization Cryptographic Non-Cryptographic Irreversible Authenticable Non-Authenticable
- 10. Type of Data Use Case I Structured I Un-structured Simple – Complex – PCI PHI PII Encryption of Files Card Holder Data Tokenization of Fields Protected Health Information Personally Identifiable Information Figure J –How to Protect Different Types of Data
- 11. User Cloud Access Security Broker (CASB) Data Tokenization / encryption Private Cloud Security Separation Figure K –Data Protection for Salesforce with CASB Salesforce (SaaS)
- 12. User Payment Application Data Tokenization / encryption Private Cloud Payment Network Data Tokens Figure L – Tokenization used in a Payment System
- 13. Figure M – mapping Data Security and Privacy techniques for On-premises, Public, and Private Clouds Vault-based Tokenization (VBT) Tokenization based on randomized token generation with a vault for storage of tokens, suitable for cloud deployment and centralized token generation Vault-less Tokenization (VLT) Tokenization based on randomized token generation without a vault, suitable for on-premises deployment and distributed token generation Format Preserving Encryption (FPE) Format-preserving encryption is designed for data that is not necessarily binary. In particular, given any finite set of symbols, like the decimal numerals, a method for format-preserving encryption transforms data that is formatted as a sequence of the symbols in such a way that the encrypted form of the data has the same format, including the length, as the original data. Homomorphic Encryption (HE) Homomorphic encryption is suitable for public cloud based computation with operations on encrypted data values is required Server Model Mechanisms that follow the “server model” for differential privacy typically preserve data in unmodified form in a secure database. In order to preserve privacy, responses to queries are only able to be obtained through a software component or “middleware”, known as the “curator”. The curator takes queries from system users, or from reporting software, and obtains the correct, noise-free answer from the database. Local Model The local model is useful when the entity receiving the data is not necessarily trusted by the data principals, or if the entity receiving the data is looking to reduce risk and practice data minimization. L-diversity L-diversity is an enhancement to K-anonymity for datasets with poor attribute variability. It is designed to protect against deterministic inference attempts by ensuring that each equivalence class has at least L well-represented values for each sensitive attribute. L-diversity is not a single model but a group of models (E.7). Each model has diversity defined slightly differently, e.g. by counting distinct values or by entropy. T-closeness T-closeness is an enhancement to L-diversity for datasets with attributes that are unevenly distributed, belong to a small range of values, or are categorical. It is designed to protect against statistical inference attempts, as it ensures that the distance between the distribution of a sensitive attribute in any equivalence class and the distribution of the attribute in the overall dataset is less than a threshold T. This technique is useful when it is important for the resulting dataset to remain as close as possible to the original one. Tokenization (T) Privacy enhancing data de-identification terminology and classification of techniques Cryptographic tools (CT) Formal privacy measurement models (PMM) Differential Privacy (DP) K-anonymity model De-identification techniques (DT)
Editor's Notes
- Cloud is only one of the platforms in an Enterprise. The flow of Sensitive data need to be secured across all platforms, including Cloud. Important Goals: GWs & Agents enforce Enterprise Policy across Cloud & On-premises Data & Applications Goals: Automated Protection of the entire Data flow, including legacy systems, Cloud and Big Data. Single point of control for policy and audit. You security posture depends on the policy and the enforcement. The security policy is the foundation for protecting data. It is usually managed by the Security Officer. Think of it as the glue that binds distributed data protection throughout the enterprise. This is policy based data security, protecting the entire data flow against threats and minimizing audit and compliance requirements. This is also an illustration of the Protegrity Software. You can find more information in the attached material.
- Reduction of Pain with New Protection Techniques. Some security approach products might restricting functionality, or compromise essential big data characteristics, like search and analytics. A good solution should address a security threat to big data environments or data stored within the cluster