11
What is derivativefree optimization ?
(Numerical) optimization is about finding the (argument) minimum of f.
It’s optimization without derivatives.
Maybe you have learnt Newton, BFGS, etc ? These algorithms need the gradient of f.
It’s finding (approx.) argmin f without knowing gradient(f), just with a black-box x à f(x).
It’s finding f* such that for almost all x, f(x) >= f(f*).
1
Evolutionary programming
Mathematical programming
(cobyla, sqp…)
Design of experiments
Bayesian Optimization (EGO)
DFO for games?
- Partial obs.: ok
- No gradient: ok
- Multi-agent ok
- Collaborative or not
- Two-levels ok (e.g. each agent has its
training, as in PBT)
2019
Derivative-free optimization
Transition
function
Agent 1
Agent 2
Agent 3
State
Observ. 1
Observ. 2
Observ. 3
6.
14
Advantages of DFO
•Fog of war (partial information) taken into account
• Bounded rationality taken into account
• No gradient ok.
• Noise ok.
• Simple, transparent: small code contains all the
information for justifying the decisions
è you know why power plant X is built (transparency++).
Examples:
• Power systems
• Roads
• Irrigation
• Games
4
Several agents
èno problem AskTellRecom.
No gradient
èno problem for DFO.
èCompared to Bellman-style methods
or model-predictive control: far less
assumptions. No parameter such as
operational/tactical/strategic horizon
7.
15
Serious game inpower systems:
Each power plant is maximizing its income.
Which law do we need for making this ~ equivalent to global
maximization ? No details here, but a real problem.
4
Several agents
èno problem AskTellRecom.
No gradient
èno problem for DFO.
èCompared to Bellman-style methods
or model-predictive control: far less
assumptions. No parameter such as
operational/tactical/strategic horizon
24
Problem: close tothe optimum, we might want to reduce σ.
(1+1)-ES with one-fifth rule:
x(0) = (0, 0)
σ(0) = 1
for n in {0, 1, 2, 3, …}
x’ = x(n) + σ(n) x Gaussian
if x’ better than x(n):
x(n+1) = x’
σ(n+1) = 2 σ(n)
else:
σ(n+1) = 0.84 σ(n)
σ very big è success rate goes to what ?
σ very small è success rate what ?, but slow
progress.
Equilibrium when P(success) = What ?
because 0.84^4 == 1 / 2
12.
25
Problem: close tothe optimum, we might want to reduce σ.
(1+1)-ES with one-fifth rule:
x(0) = (0, 0)
σ(0) = 1
for n in {0, 1, 2, 3, …}
x’ = x(n) + σ(n) x Gaussian
if x’ better than x(n):
x(n+1) = x’
σ(n+1) = 2 σ(n)
else:
σ(n+1) = 0.84 σ(n)
3
σ very big è success rate goes to 0.
σ very small è success rate ½, but
slow progress.
Equilibrium when P(success) = 1/5
because 0.84^4 == 1 / 2
13.
26
Problem: we mightwant to be parallel! Evaluate λ individuals
simultaneously ?
(µ/µ, λ)-ES with self-adaptation:
x(0) = (0, 0)
σ(0) = 1
for n in {0, 1, 2, 3, …}
for i in {1, 2, 3, …, λ}
σ(n,i) = σ(n) x exp(1D-Gaussian)
x’(i) = x(n) + σ(n,i) x 2D-Gaussian
pick up the µ best x’(i) and their σ(n,i)
x(n+1) = average of those µ best
σ(n+1) = exp( average of these log σ(n,i))
3
14.
27
Problem: isotropic mutations!We want to mutate some variables more
than others. E.g. f(x) = 100(x(1)-7)2 + x(2)2
(µ/µ, λ)-ES with anisotropic self-adaptation:
x(0) = (0, 0)
σ(0) = (1,1)
for n in {0, 1, 2, 3, …}
for i in {1, 2, 3, …, λ}
σ(n,i) = σ(n) *pointwise-product* exp(2D-Gaussian)
x’(i) = x(n) + σ(n,i) *pointwise-product* 2D-Gaussian
pick up the µ best x’(i) and their σ(n,i)
x(n+1) = average of those µ best
σ(n+1) = exp( average of these log σ(n,i) )
3
15.
28
Problem: what ifthere is noise!
Like, my oven is not completely deterministic.
I want oven(temperature) to be excellent on average.
Problem: classical algorithms stagnate!
(µ/µ, λ)-ES with anisotropic self-adaptation and population control:
x(0) = (0, 0)
σ(0) = (1,1)
for n in {0, 1, 2, 3, …}
for i in {1, 2, 3, …, λ}
σ(n,i) = σ(n) *pointwise-product* exp(2D-Gaussian)
x’(i) = x(n) + σ(n,i) *pointwise-product* 2D-Gaussian
pick up the µ best x’(i) and their σ(n,i)
x(n+1) = average of those µ best
σ(n+1) = exp( average of these log σ(n,i) )
if average of population is signif. better than
average of the population 5 iterations earlier,
then decrease λ; otherwise increase λ.
3
16.
29
Problem: what ifit’s discrete ? Like, we optimize in
{0,1}10.
Discrete-(1+1)ES
x(0) = (0,0,0,…..,0,0,0,0)
for n in {0, 1, 2, 3, …}
x’ = mutation(x(n))
if x’ better than x(n):
x(n+1) = x’
3
Mutation:
RLS: randomly mutate one of the variables.
(1+1)classical: each variable is mutated with
probability 1/10 (if no mutation, then discard/redraw)
17.
30
Problem: what ifmutating a small number of variables does
not work ? E.g. f(x) = bad value as long as we do not have at
least half bits equal to 1.
Discrete-(1+1)ES
x(0) = (0,0,0,…..,0,0,0,0)
for n in {0, 1, 2, 3, …}
x’ = mutation(x(n))
if x’ better than x(n):
x(n+1) = x’
3
Mutation:
RLS: randomly mutate one of the variables.
(1+1)classical: each variable is mutated with
probability 1/10
(1+1)Mixing of mutation rates: randomly draw
the probability p of mutation in (0,1), then each
variable is mutated with probability p.
Duc-Cuong Dang
& Per Christian Lehre:
Uniform mixing of mutation rates
Carola Doerr and Benjamin Doerr:
Parameter control
18.
31
Convergence rates ?
Self-adaptivealgorithms, case f(x) = ||x||:
• (x(n)/sigma(n)) is an homogeneous Markov chain
• It has a stationary distribution (non trivial)
• E log ||x(n+1)|| - log ||x(n) || converges to a constant
• log||x(n)||/n converges to a constant
3
log||x(n)||
n
Auger, TCS
19.
32
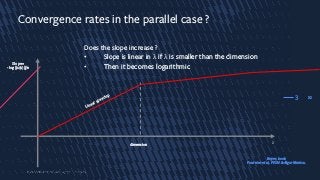
Convergence rates inthe parallel case ?
Does the slope increase ?
• Slope is linear in λ if λ is smaller than the dimension
• Then it becomes logarithmic
3
Slope=
- log||x(n)||/n
λ
Linear speedup
dimension
Beyer, book
Fournier et al, PPSN & Algorithmica.
20.
33
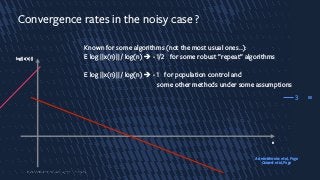
Convergence rates inthe noisy case ?
Known for some algorithms (not the most usual ones…):
E log ||x(n)|| / log(n) è -1/2 for some robust ”repeat” algorithms
E log ||x(n)|| / log(n) è -1 for population control and
some other methods under some assumptions
3
log||x(n)||
n
Astete-Morales et al, Foga
Cauwet et al, Foga
21.
344
Derivative-free methods
1.Random search:randomly draw 1 000 000 points, and pick up the best.
2.Estimation of Distribution Algorithm: while (budget not elapsed) randomly draw 1000 points,
select the 250 best, define a Gaussian matching those 250 points, repeat until budget elapsed.
3.Particle swarm optimization: define 50 particles in the domain, with random velocities.
Particles are attracted by their best visited point, and by the best point for the entire
population, and receive random noise.
4. Quasi-Random Search: similar to random search, but try to have a better positioning of
points, using low-discrepancy sequences.
… and so many others!
22.
354
Derivative-free methods
1.CMA: extendinganisotropic mutations to rotated ellipsoids
2.Differential Evolution: also rotated anisotropic mutations, with cheap computational cost
3. Lamarckism, i.e. inheritance of acquired characteristics:
a) Part of the state if evolution-optimized
b) The rest evolves during the evaluation (e.g. neural networks training)
èAs if your child could inherit your post-workout muscles or your trained neural net
è remember the inheritance of the immune system ?
38
Let us savethe world.
What is the API of our optimization algorithms ?
• Dear optimizer, I’m asking you which point I should evaluate è
ASK.
• Dear optimizer, at point (3.1, 2.0), I tell you that the quality is 47
è TELL.
• Dear optimizer, I am tired now, please recommend a good point
è RECOMMEND.
è Asynchronous ok
è Multiagent ok.
è Noisy ok.
4
26.
39
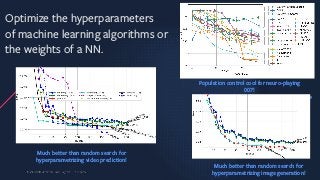
Optimize the hyperparameters
ofmachine learning algorithms or
the weights of a NN.
4
Much better than random search for
hyperparametrizing video prediction!
Much better than random search for
hyperparametrizing image generation!
Population control cool for neuro-playing
007!
27.
40
Example (simplified): powersystems.
• Time steps 1, 2, 3, …, 365 x 10 è 10 years.
• For i in {1,2,3,…,12}:
• One stock Si of water for hydroelectricity.
• A random process Ri adding water in Si.
• A random process C “electricity consumption” for each time step.
• A market converting the productions and C into cost per MWh.
• An agent Ai converting water from Si into electricity Ei.
Agent Ai = mapping (X, C, S1, S2, S3, S4, …, S12) to a real number.
This mapping has parameters. For example a neural network.
Simulator(parameters of agents):
- For each time step
- For each stock Si, update it with Ri, and Ai(params) converts some water to elect.
- Quality for society = ecological / economical penalty associated to the production (includes
some agents).
- Quality for independent agents = money earned.
- è one optimizer per independent agent and one optimizer for others + society.
4
Several agents
èno problem AskTellRecom.
No gradient
èno problem for DFO.
èCompared to Bellman-style methods:
far less assumptions. No parameter
such as operationa/tactical/strategic
horizon
28.
41
Nevergrad: super easyto use! Needs Python >= 3.6.
Installtion = pip install nevergrad
Or (developer):
• “git clone” the repository
• Run “ pip install -e .[all] ”
4
Evolutionary programming
Mathematical programming
(cobyla, sqp…)
Design of experiments
Bayesian Optimization (EGO)
434
No time forinstalling, for coding, for experimenting, or I don’t want
to take care of distributing my experiments on many machines.
No problem !!!
Just hack the code directly on the github interface:
- Duplicate the code of one of the optimizers in
optimizerlib.py
- Give it another name, modify it using your knowledge.
- Add your optimizer name in one of the experiments in
experiments.py
èCreate a pull request and our servers will run your
experiments a couple of days after it’s merged and the
result will be visible on
https://dl.fbaipublicfiles.com/nevergrad/allxps/list.html
31.
444
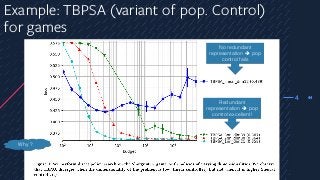
Example: TBPSA (variantof pop. Control)
for games
No redundant
representation è pop
control fails
Redundant
representation è pop
control excellent!
Why ?
32.
454
Example: random seeds!
Considera stochastic player
Action: f(random, situation)
Now:
- Situation à hash à hash % 5000
- Parameter = vector of 5000 seeds
- Seed 0 means “time” seed (i.e. no seed)
à Looks weird, but works!
à Optimizes the opening book in partially observable games e.g. phantom-Go
World Computer-Bridge Championship in September 2016: Wbridge5.
Fast and easy
experiments
33.
464
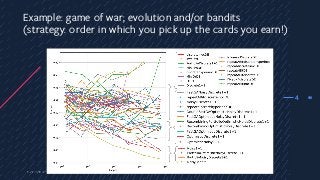
Example: game ofwar; evolution and/or bandits
(strategy: order in which you pick up the cards you earn!)
























![41
Nevergrad: super easy to use! Needs Python >= 3.6.
Installtion = pip install nevergrad
Or (developer):
• “git clone” the repository
• Run “ pip install -e .[all] ”
4
Evolutionary programming
Mathematical programming
(cobyla, sqp…)
Design of experiments
Bayesian Optimization (EGO)](https://image.slidesharecdn.com/slidesharenevergrad-200324142045/85/Nevergrad-our-platform-for-evolutionary-and-derivative-free-optimization-28-320.jpg?cb=1585066093)
































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)




















