Download to read offline


![• ヒアラブルデバイス
• 音楽再生,音声アシスタント,通話などの多くの機能
• 操作
• スマートフォンによる操作
• 画面注視の必要性
• 音声アシスタント
• 社会的受容性の問題
2
[1]Sony, WF-10000XM5 https://www.sony.jp/headphone/products/WF-1000XM5/
[2]Apple, AirPodsPro(第2世代) https://www.apple.com/jp/shop/product/MTJV3J/A/airpods-pro
背景
市販のヒアラブルデバイス
[1] [2]](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-2-320.jpg)
![• デバイス本体による操作
• 感圧センサ,物理ボタン
• センサ部分,ボタン部分が小さく,押下が困難
• 静電容量センサ
• 手袋着用時の使用が不可能
• 押下による耳への負担
• 操作数
• 押下時間や回数の変化による定義
• AirPods[3]では5種類の操作
• 1~3回のタップ,長押し,スワイプ
• 操作数の限界
3
[3]Apple, AirPods(第3世代) https://www.apple.com/airpods-3rd-generation/
背景
デバイス本体による操作[1]](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-3-320.jpg)
![• EarBuddy
• 顔や耳近くのタップやスライディングジェスチャ
• EarTouch
• 反射型光センサで耳の変形をセンシング
• 手が汚れている,手を清潔に保ちたい場合は
システムの利用が困難
4
[4] Xuhai Xu et al., EarBuddy: Enabling On-Face Interaction via Wireless Earbuds. CHI '20. https://doi.org/10.1145/3313831.3376836
[5] Takashi Kikuchi et al., EarTouch: turning the ear into an input surface. MobileHCI '17. https://doi.org/10.1145/3098279.3098538
関連研究:ハンドジェスチャ入力
EarBuddy[4]
EarTouch[5]](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-4-320.jpg)
![• 赤外線センサ
• センサ付近を指でジェスチャ
• カメラ
• 手の輪郭,爪の位置,指関節の角度をセンシング
• 実装コスト,デザイン制約の課題
5
[6] C. Metzger et al., FreeDigiter: a contact-free device for gesture control, Eighth International Symposium on Wearable Computers, doi: 10.1109/ISWC.2004.23.
[7] Emi Tamaki et al., Brainy hand: an ear-worn hand gesture interaction device. CHI EA '09. https://doi.org/10.1145/1520340.1520649
関連研究:空中ジェスチャハンズフリー入力
赤外線センサを使用したジェスチャ検出[6]
カメラを使用したジェスチャ検出[7]](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-5-320.jpg)

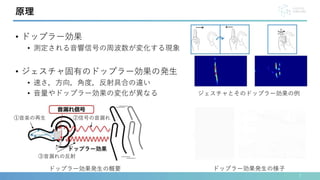
![• ヒアラブルデバイスの種類
8
原理
[8]Apple,EarPods(3.5mmヘッドフォンプラグ)https://www.apple.com/jp/shop/product/MNHF2FE/A/earpods-with-35-mm-headphone-plug
[9]Victor, HA-NP35T https://www.victor.jp/headphones/lineup/ha-np35t/
[10]SHOKZ,OPENFIT https://jp.shokz.com/products/openfit
Sony WF-1000XM5[1] Apple AirPods Pro[2] Apple AirPods[3] Apple EarPods[8]
SHOKZ OPENFIT[10]
Victor HA-NP35T[9]
①カナル型 ②インイヤー型
③オープンイヤー型](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-8-320.jpg)
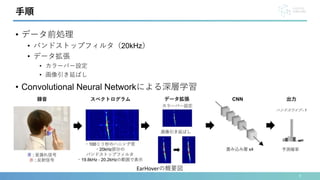
![11
実装
• ハードウェア
• インイヤー型デバイス
• Apple EarPods
• オープンイヤー型デバイス
• Victor HA-NP35T
• ソフトウェア
• Python 3.10
• サンプリングレート:44.1kHz
• 量子化ビットレート:16bit
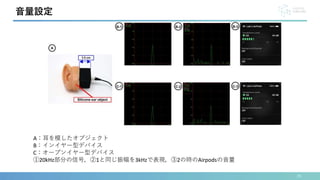
• 音量
• 40-45dBの範囲で実験
• 実験時は20kHz部分の振幅を統一
• 推奨音量は週40時間80dB(世界保健機関[11])
[11] WHO: Safe listening devices and systems: a WHO-ITU standard, https://www.who.int/publications/i/item/9789241515276/ (2019).
2つのプロトタイプデバイス
接続の様子
赤:ヒアラブルデバイス
青:外部マイク](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-11-320.jpg)
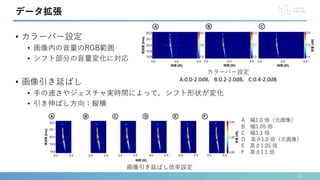
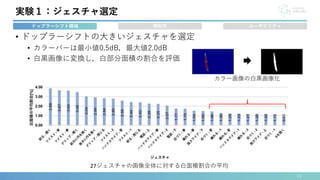
![• 27種類の空中ジェスチャ(Yu-chunら[12]+自作)
12
実験1:ジェスチャ選定
[12] Yu-Chun Chen et al. Exploring User Defined Gestures for Ear-Based Interactions. ISS, Article 186(2020), 20 pages. https://doi.org/10.1145/3427314](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-12-320.jpg)
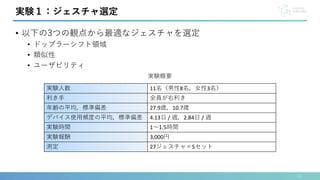

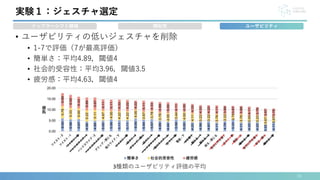

![• ヒアラブルデバイスでは一般に5つのコマンドで操作可能(AirPods Pro[2])
• 再生/停止,音量を上げる,音量を下げる,次の曲に進む,前の曲に戻る
• 現状の操作に追加する形での実装を想定
• 7ジェスチャのうち混同の多いペアの中から2ジェスチャを削除
• ツイスト-1とツイスト-2,グリップ-閉じると絞る-閉じる
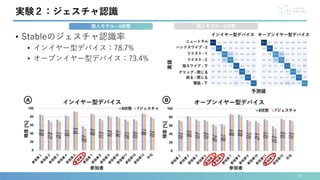
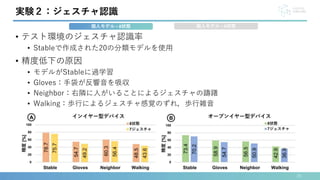
• 6状態のStable認識率
• インイヤー型デバイス:86.2%,オープンイヤー型デバイス:82.5%
21
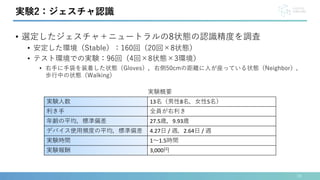
実験2:ジェスチャ認識
個人モデル – 6状態
個人モデル – 8状態](https://image.slidesharecdn.com/interaction2024-240404142739-f97be1e4/85/EarHover-21-320.jpg)




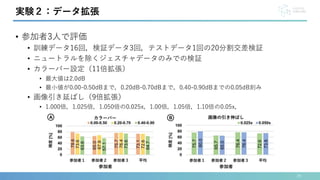

本研究では,ヒアラブルデバイスへの空中ジェスチャ入力を可能にする新しいジェスチャ認識手法“EarHover” を提案します.本手法は,ヒアラブルデバイス特有の音漏れ現象に着目します.本研究では,有効な27 種類のジェスチャの中から,信号の識別性とユーザの受容性の観点から,7 種類のジェスチャを選択しました.その後,これらの7 種類のジェスチャとニュートラル状態の計8 状態のデータをインイヤー型/オーバーイヤー型の2 つのプロトタイプデバイスを用いて収集し,深層学習による認識性能の評価を行いました.実験の結果,インイヤー型/オーバーイヤー型デバイスのそれぞれのF-score は78.7%/73.4%でした.さらに,5 種類のジェスチャに絞ることで,F-score は6 状態で86.2%/82.5% でした.







![[FIT2025 トップコンファレンスセッション]EarHover: ヒアラブルデバイスにおける音漏れ信号を用いた空中ジェスチャ認識](https://cdn.slidesharecdn.com/ss_thumbnails/fit2025-presentationv2-251006033725-c7651715-thumbnail.jpg?width=640&height=640&fit=bounds)



















