論文紹介
BlinkDB: Queries withBounded Errors and
Bounded Response Times on Very Large Data
Sameer Agarwal, BarzanMozafari, Aurojit Panda,HenryMilner,
Samuel Madden, Ion Stoica (UCB, MIT, Conviva)
Masafumi Oyamada / @stillpedant
Some figures and examples are gratefully copied from original paper/slides
第5回 システム系論文輪読会
本日ご紹介するもの - BlinkDB
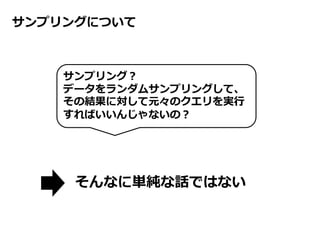
BlinkDB とは
UCB AMPLab で研究されている SQL 処理系
「精度を犠牲にし高速に処理結果を返す」というコンセプトがウケて、
一世を風靡
BlinkDB に関する論文
[Agarwal, NSDI’12 (Extended Abstract)] BlinkDB: Queries with
Bounded Errors and Bounded Response Times on Very Large Data
[Agarwal, VLDB’12 (Demo)] Blink and It’s Done: Interactive
Queries on Very Large Data
[Agarwal, EuroSys’13] BlinkDB: Queries with Bounded Errors
and Bounded Response Times on Very Large Data
[Agarwal, SIGMOD’14] Knowing When You’re Wrong: Building Fast
and Reliable Approximate Query Processing Systems
[Kleiner , KDD’14] A General Bootstrap Performance Diagnostic
本日は EuroSys’13 の論文をベースにご紹介
まとめ
最適化問題を解くことで“よい” Stratifiedsample 群を作成す
る方式を提案した
※ これまでのサンプリングベースのシステムはテーブルごとに“ひとつ
の”サンプルしかつくらなかった (AQUA [6], STRAT [10])
BlinkDB は以下を考慮して最適な stratified sample を算出
(i) the frequency of rare subgroups in the data
(ii) the column sets in the past queries
(iii) the storage overhead of each sample
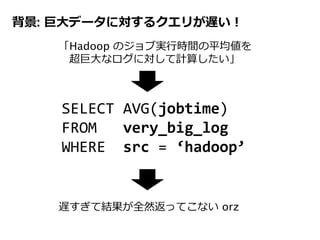
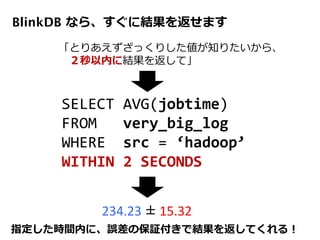
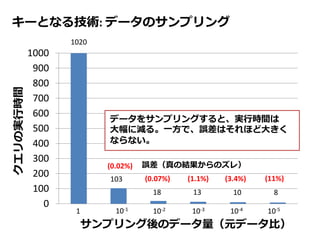
エラーとレイテンシの関係をプロファイルする方法を提案
各サンプル(異なる stratified sample されたもの)毎に、クエリを実
行した際の誤差 or レイテンシを見積もるためのプロファイルを作成
ユーザの指定した誤差 / レイテンシ制約を満たすため、最も適したサ
ンプルを選ぶためにつかわれる
Hive などの既存のシステムを少ない拡張で BlinkDB 化できる
ことをきちんと示した


![本日ご紹介するもの - BlinkDB
BlinkDB とは
UCB AMPLab で研究されている SQL 処理系
「精度を犠牲にし高速に処理結果を返す」というコンセプトがウケて、
一世を風靡
BlinkDB に関する論文
[Agarwal, NSDI’12 (Extended Abstract)] BlinkDB: Queries with
Bounded Errors and Bounded Response Times on Very Large Data
[Agarwal, VLDB’12 (Demo)] Blink and It’s Done: Interactive
Queries on Very Large Data
[Agarwal, EuroSys’13] BlinkDB: Queries with Bounded Errors
and Bounded Response Times on Very Large Data
[Agarwal, SIGMOD’14] Knowing When You’re Wrong: Building Fast
and Reliable Approximate Query Processing Systems
[Kleiner , KDD’14] A General Bootstrap Performance Diagnostic
本日は EuroSys’13 の論文をベースにご紹介](https://image.slidesharecdn.com/system5thblinkdb-150520155956-lva1-app6892/85/BlinkDB-4-320.jpg)







![まとめ
最適化問題を解くことで“よい” Stratified sample 群を作成す
る方式を提案した
※ これまでのサンプリングベースのシステムはテーブルごとに“ひとつ
の”サンプルしかつくらなかった (AQUA [6], STRAT [10])
BlinkDB は以下を考慮して最適な stratified sample を算出
(i) the frequency of rare subgroups in the data
(ii) the column sets in the past queries
(iii) the storage overhead of each sample
エラーとレイテンシの関係をプロファイルする方法を提案
各サンプル(異なる stratified sample されたもの)毎に、クエリを実
行した際の誤差 or レイテンシを見積もるためのプロファイルを作成
ユーザの指定した誤差 / レイテンシ制約を満たすため、最も適したサ
ンプルを選ぶためにつかわれる
Hive などの既存のシステムを少ない拡張で BlinkDB 化できる
ことをきちんと示した](https://image.slidesharecdn.com/system5thblinkdb-150520155956-lva1-app6892/85/BlinkDB-19-320.jpg)
![参考: サンプリングベースの DB のカテゴライズ
完全に将来のクエリがわかってる場合
そのクエリに特化したデータを保持しておける
Lossless synopsis [12], Lossy sketch [14]
過去の Predicate の頻度を確認し、その確率で将来にも同じクエリが
来ると予測。Predicate にマッチする tuple 群がわかるので、そこから
サンプリングして保持しておく
START [10], SciBORQ [21]
Group-by/Where に登場するカラム群
は仮定するが、その値までは仮定しない
BlinkDB, AQUA [4], OLAP 高速化[20]
クエリを全く仮定しない
賢いサンプリングはできず、ランダムサンプリングをすることになる
Hellerstein の Online Aggregation [15]
(この場合、事前にサンプリングをしておく必要もない)](https://image.slidesharecdn.com/system5thblinkdb-150520155956-lva1-app6892/85/BlinkDB-20-320.jpg)












![[D14] MySQL 5.6時代のパフォーマンスチューニング *db tech showcase 2013 Tokyo](https://cdn.slidesharecdn.com/ss_thumbnails/20131110tuningonmysql5-131117180858-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































