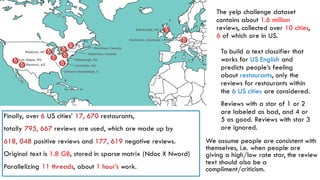
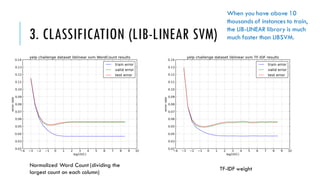
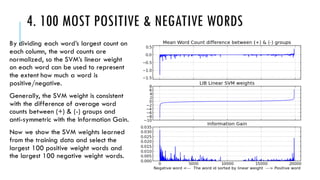
The document discusses the development of a sentiment classification model using the Yelp challenge dataset, consisting of 795,667 reviews from restaurants in six US cities. Various preprocessing techniques are employed to clean and prepare the text for analysis, followed by classification using a support vector machine (SVM) algorithm, demonstrating that the TF-IDF weighting method outperforms simple normalized word counting. Ultimately, the model identifies and ranks the top 100 most positive and negative words through analysis of their SVM weights.

![1. DATA PREPROCESSING
Using NLTK package for language
processing, the ENCHANTED dictionary
package for spelling checking and
suggestions, and some codes are provided
by Python Text Processing with NLTK 3.0
Cookbook.
1. Face emotion symbols
:-) I love it, I enjoy it !
:-( I hate it, I am unhappy !
2. Lowercase every word
3. Contraction restoring (don’t do not)
4. Tokenizing sentences into words ( punctuations
removed at this step , . : ! ? _ ‘ “ ` ~ + - * / ^
= > < @ # $ % & ( ) [ ] { } | )
5. Repeating words processing
looove love, aaammmzzzing amazing
6. Stemming
heated heat, enjoying enjoy, …
7. Removing Stop Words (the, you, I, am, …)](https://image.slidesharecdn.com/yelpchallengereviewssentimentclassification-160416191746/85/Yelp-challenge-reviews_sentiment_classification-4-320.jpg)








































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)



