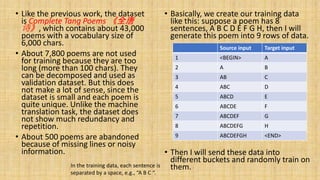
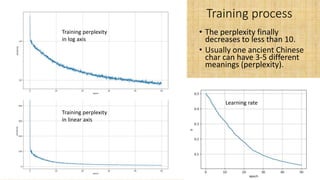
This document discusses the significance of the Tang dynasty in Chinese history and its impact on poetry, highlighting influential poets and the cultural atmosphere of inclusivity. It covers the development of a sequence-to-sequence (seq2seq) model with an attention mechanism to improve poem generation quality compared to character-level recurrent neural networks (RNNs). Challenges such as generating impactful first lines and ensuring rhyme and thematic focus in the generated poems are also addressed, along with proposed methods and variations to enhance the model's outputs.