Downloaded 69 times









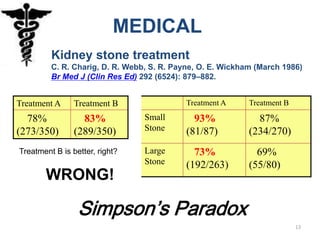





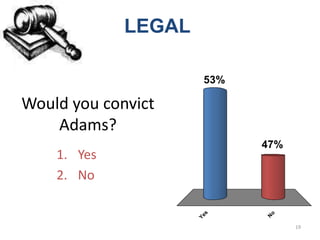


Based on the information provided, I would not convict Adams. While the DNA evidence places him in a very small group of potential suspects, there are reasonable doubts raised by the defense arguments regarding the accuracy of the victim's identification and Adams' alibi. Statistical evidence alone is not enough to determine guilt beyond a reasonable doubt in this case.


























































