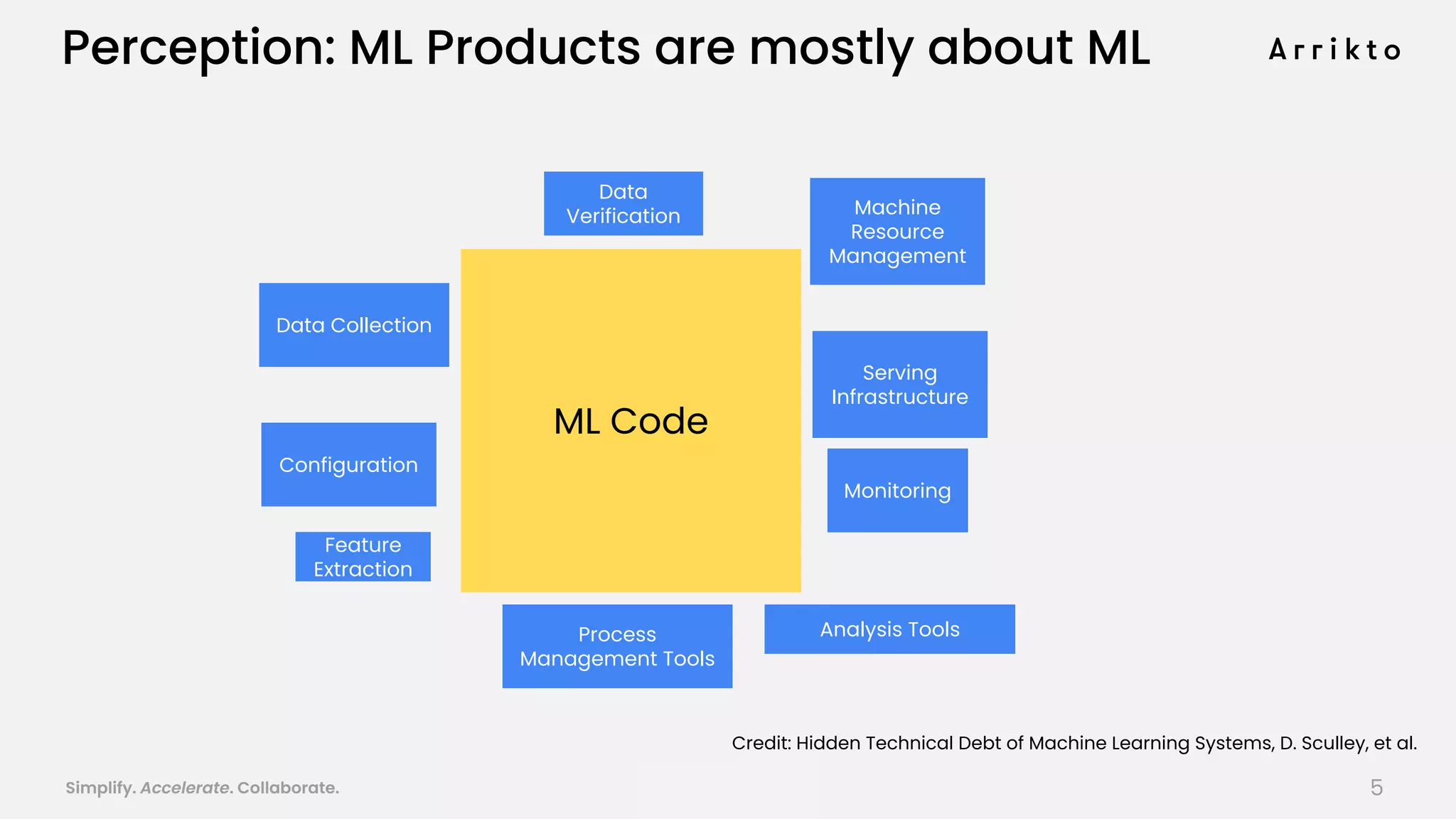
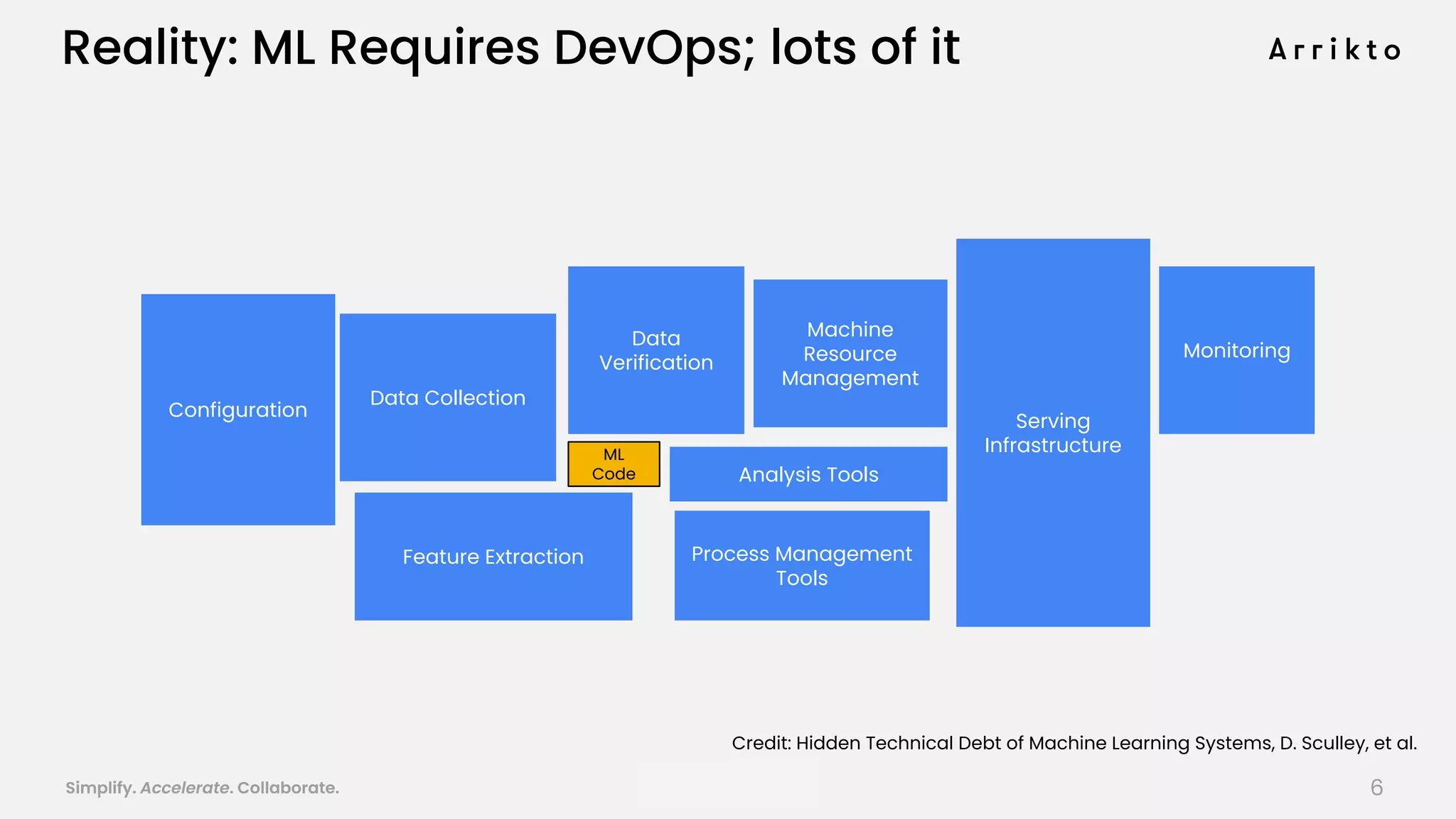
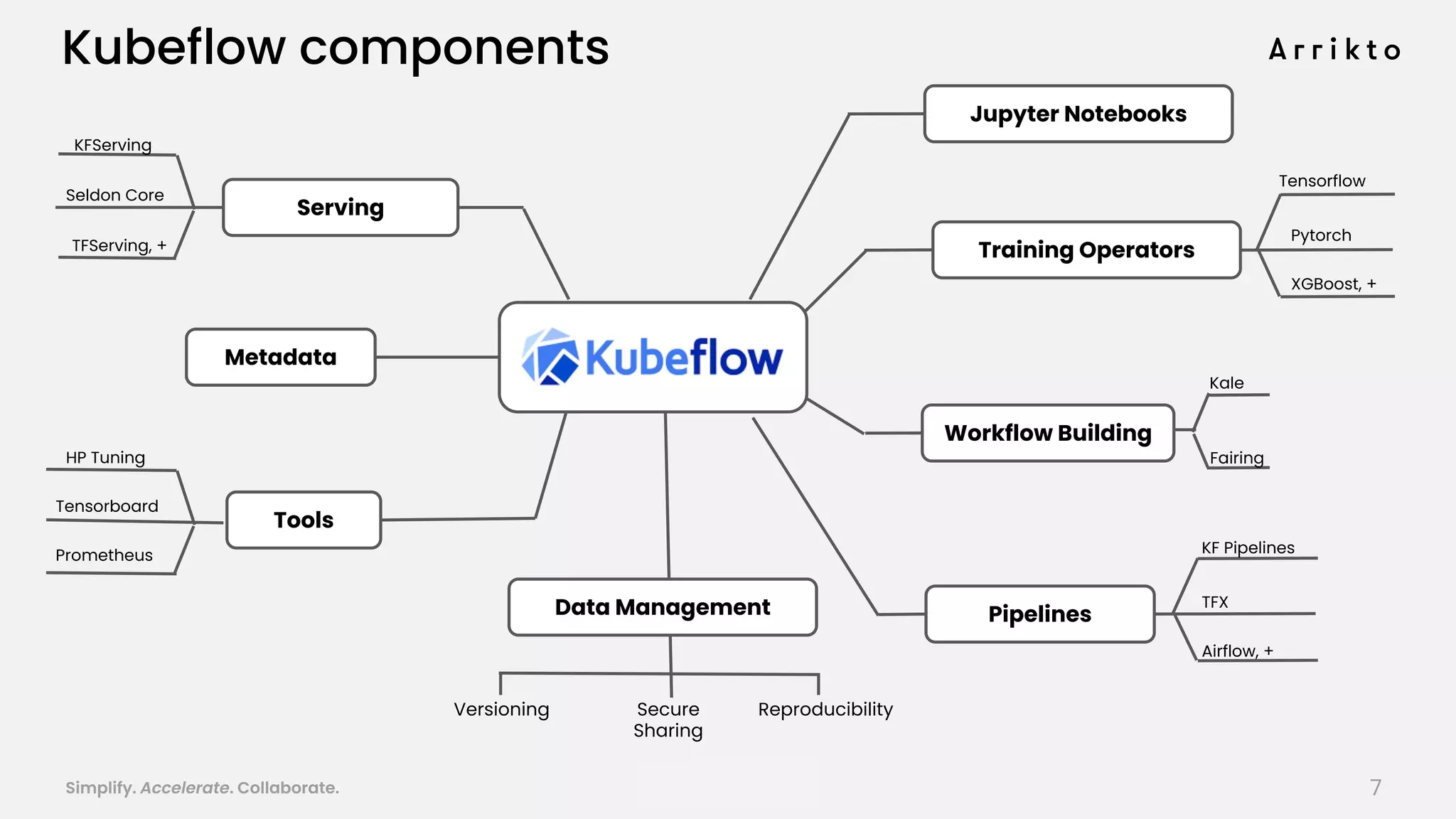
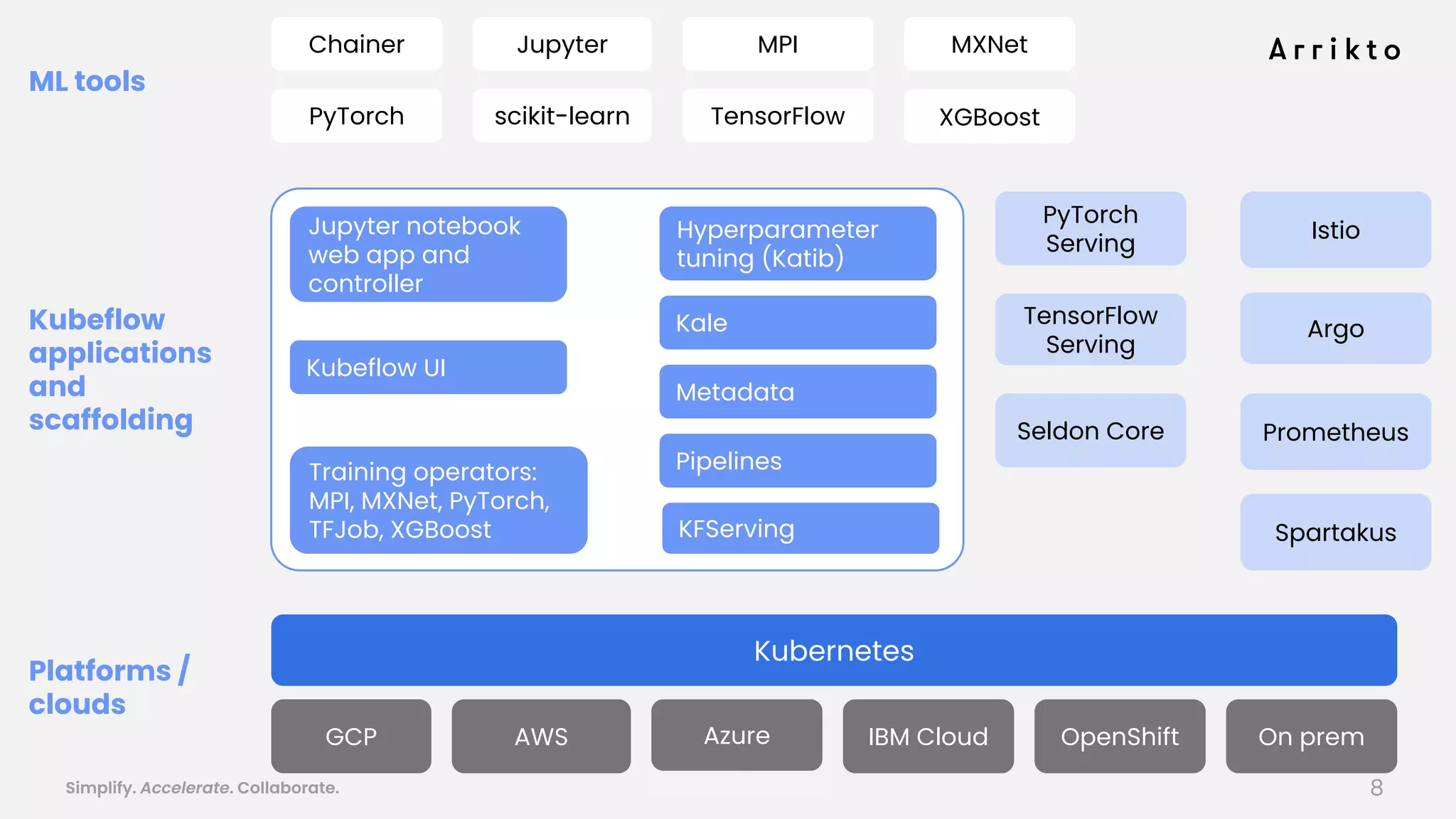
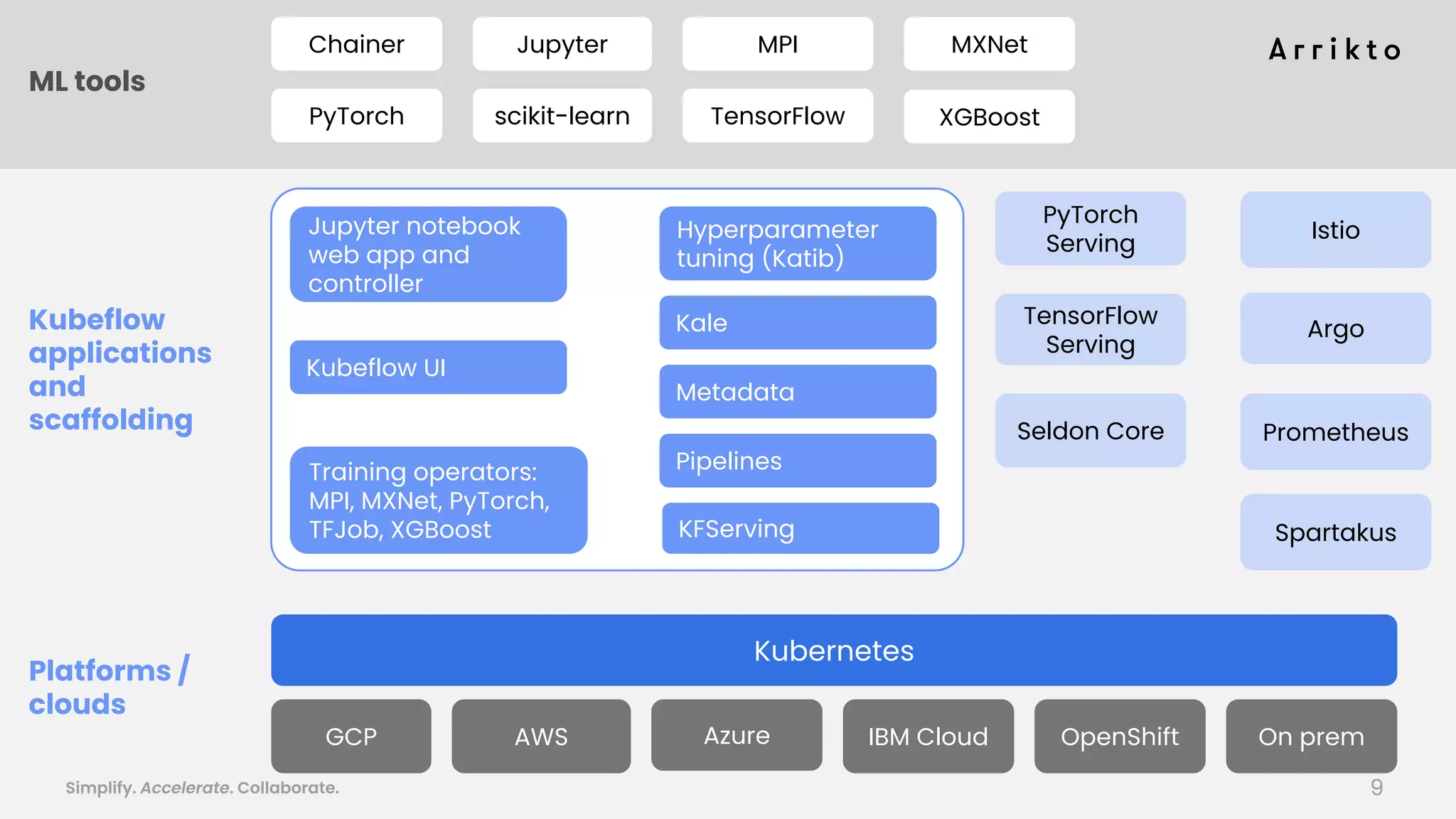
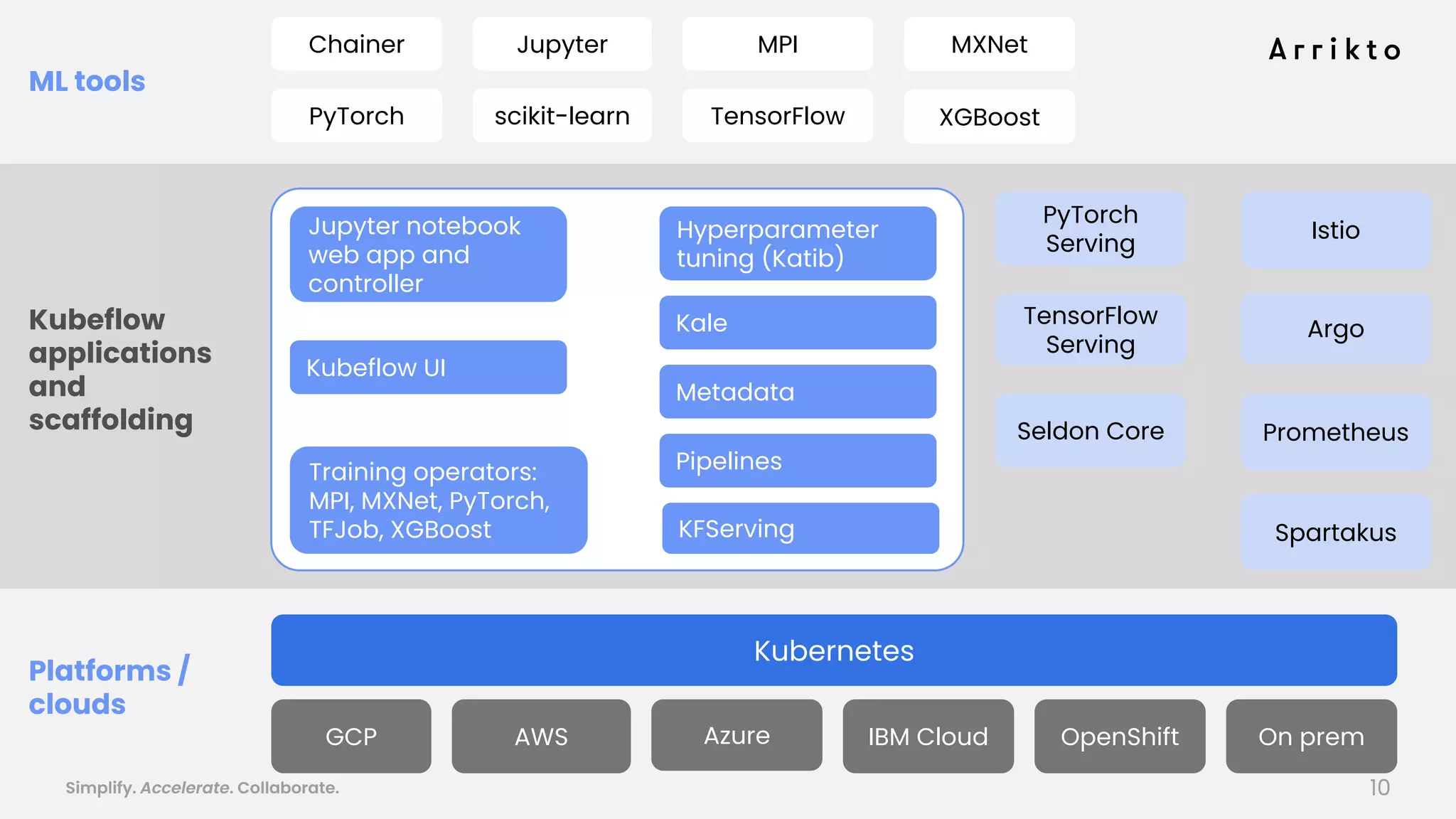
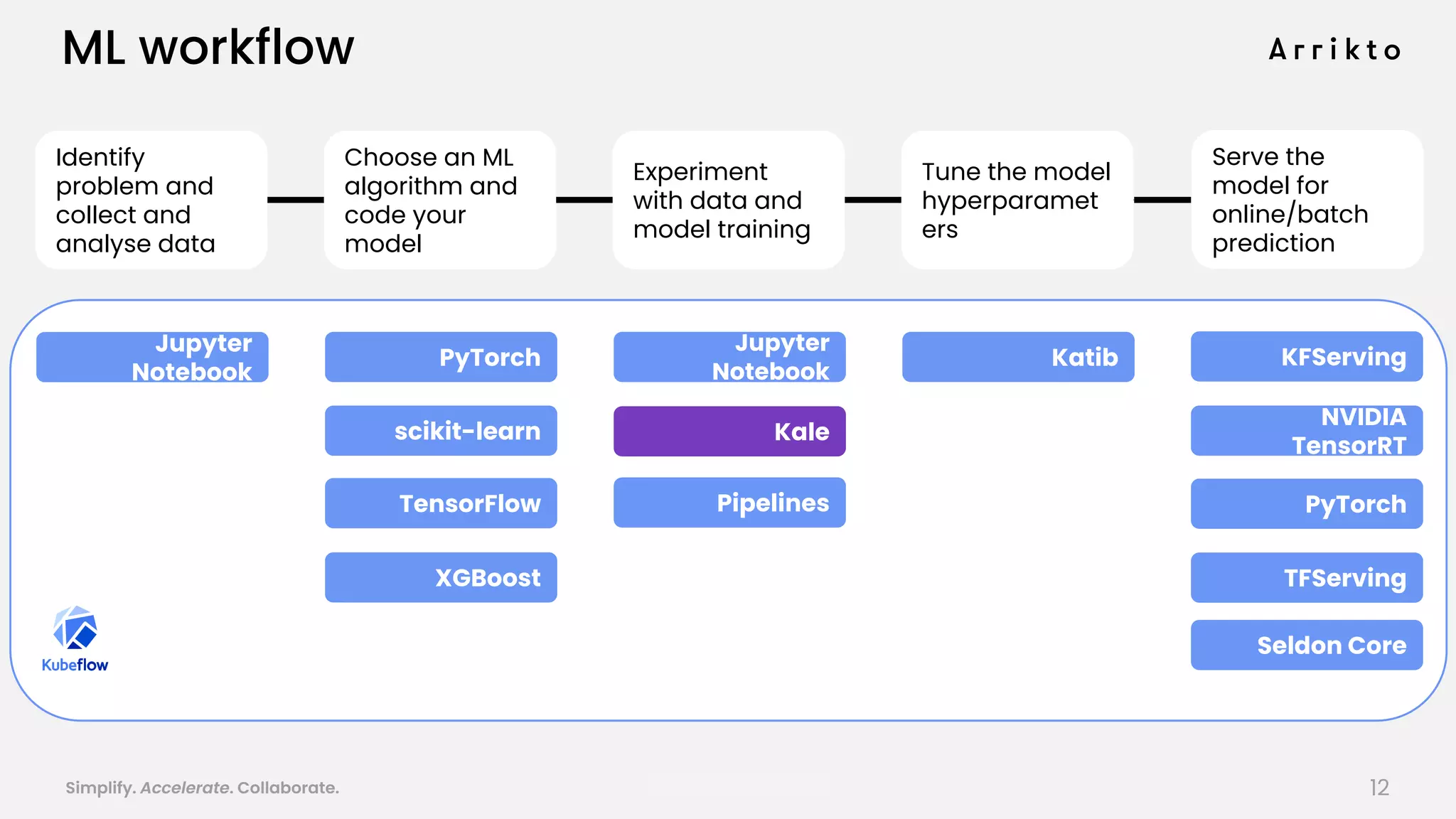
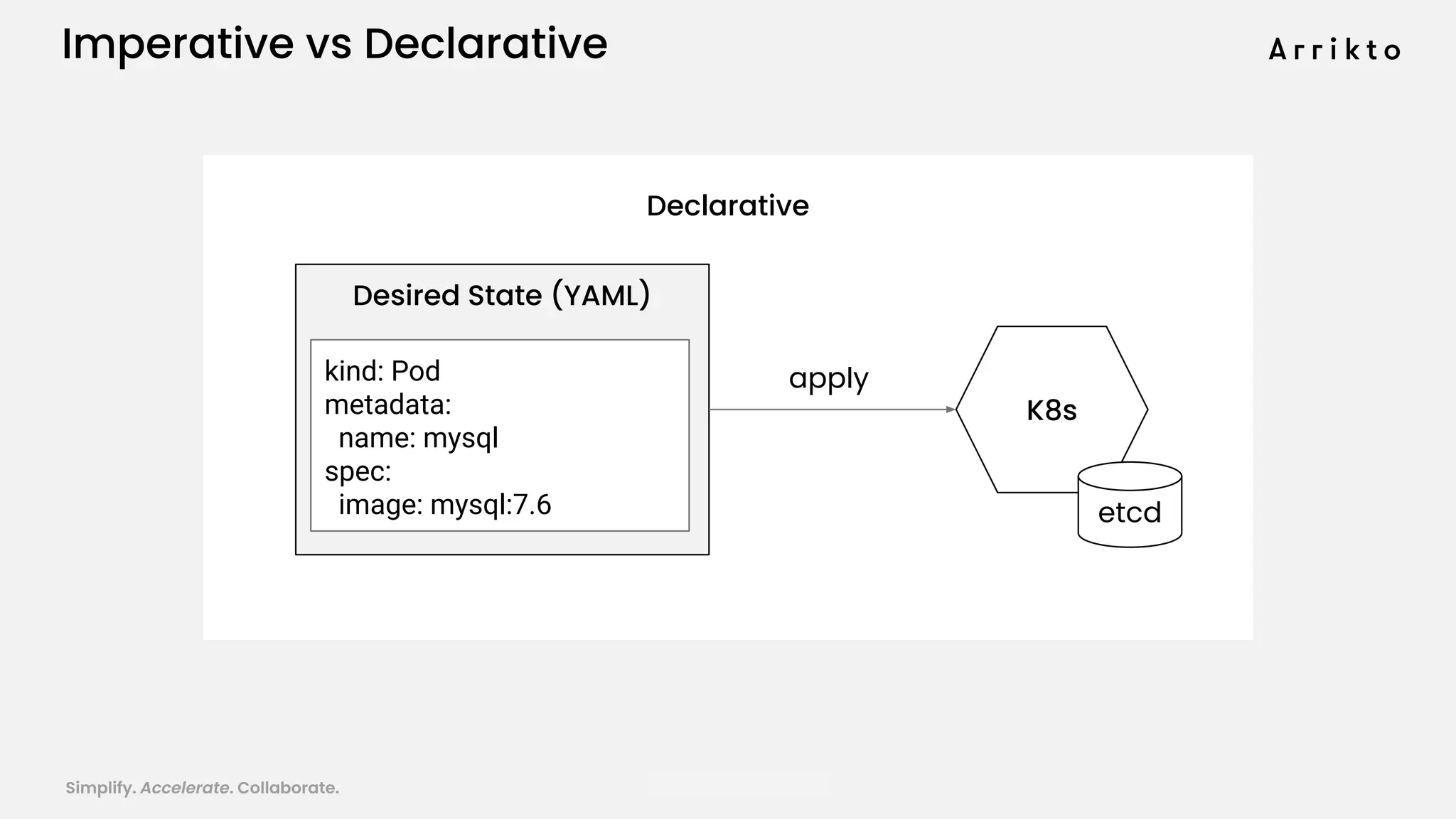
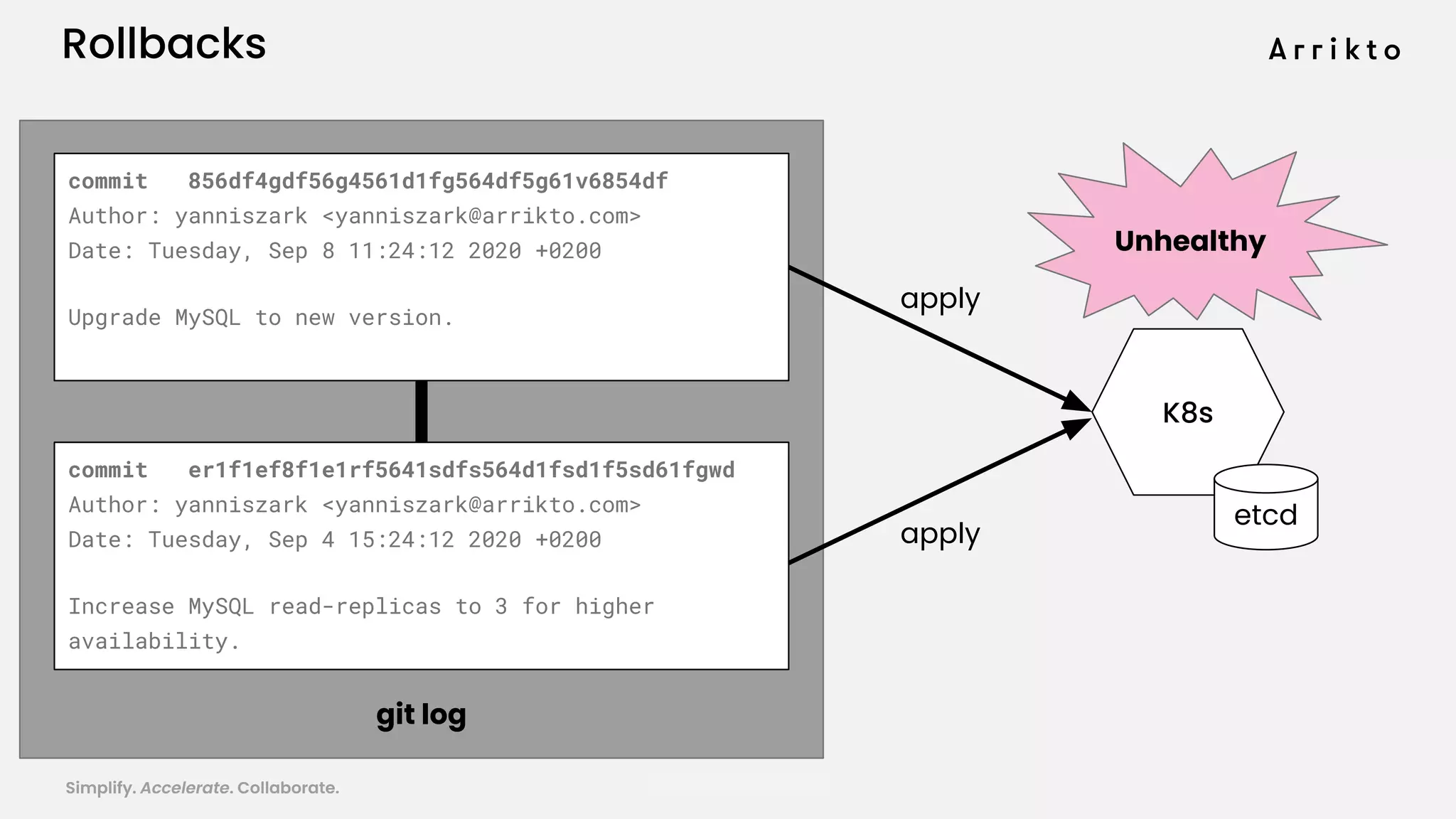
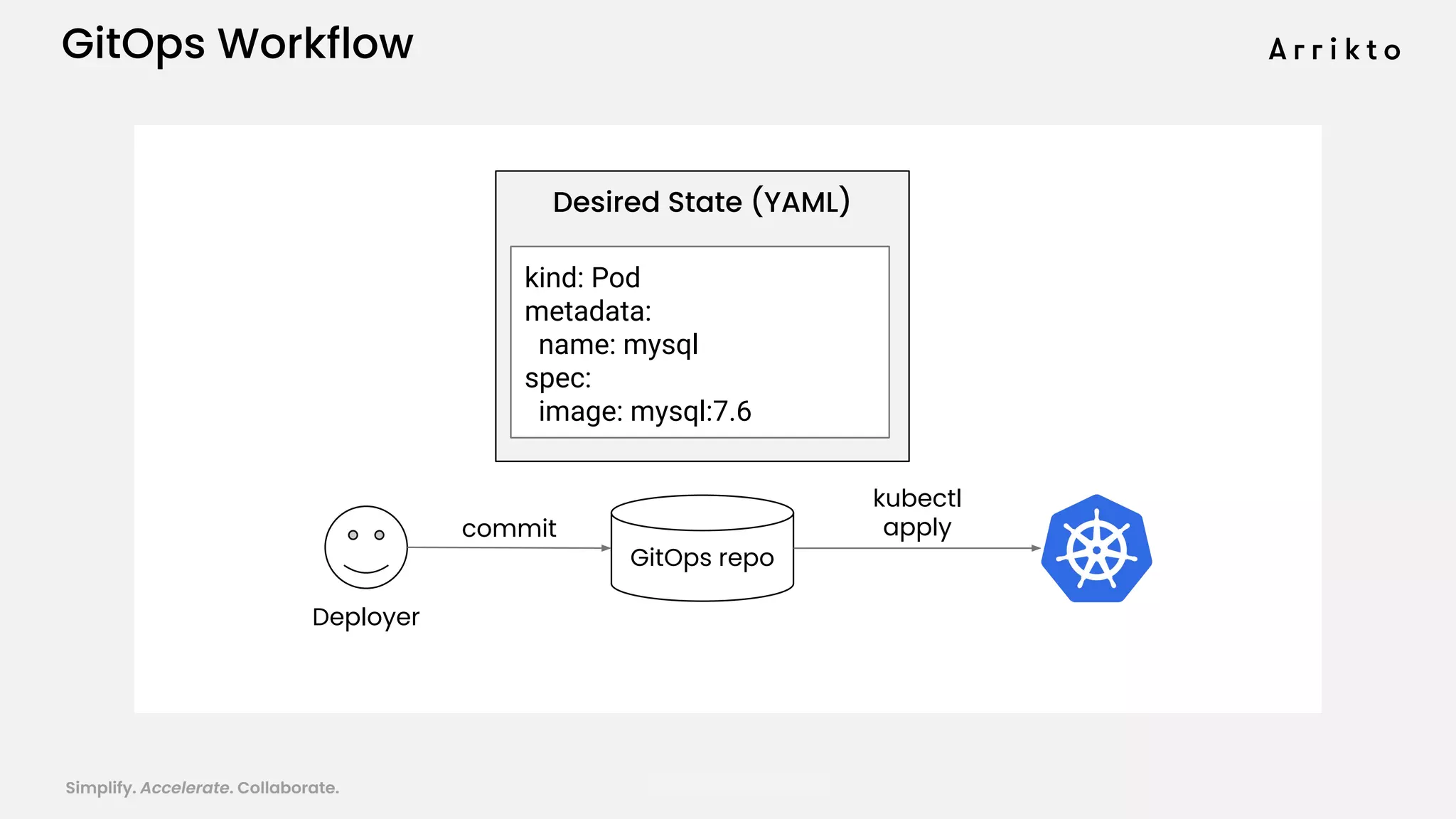
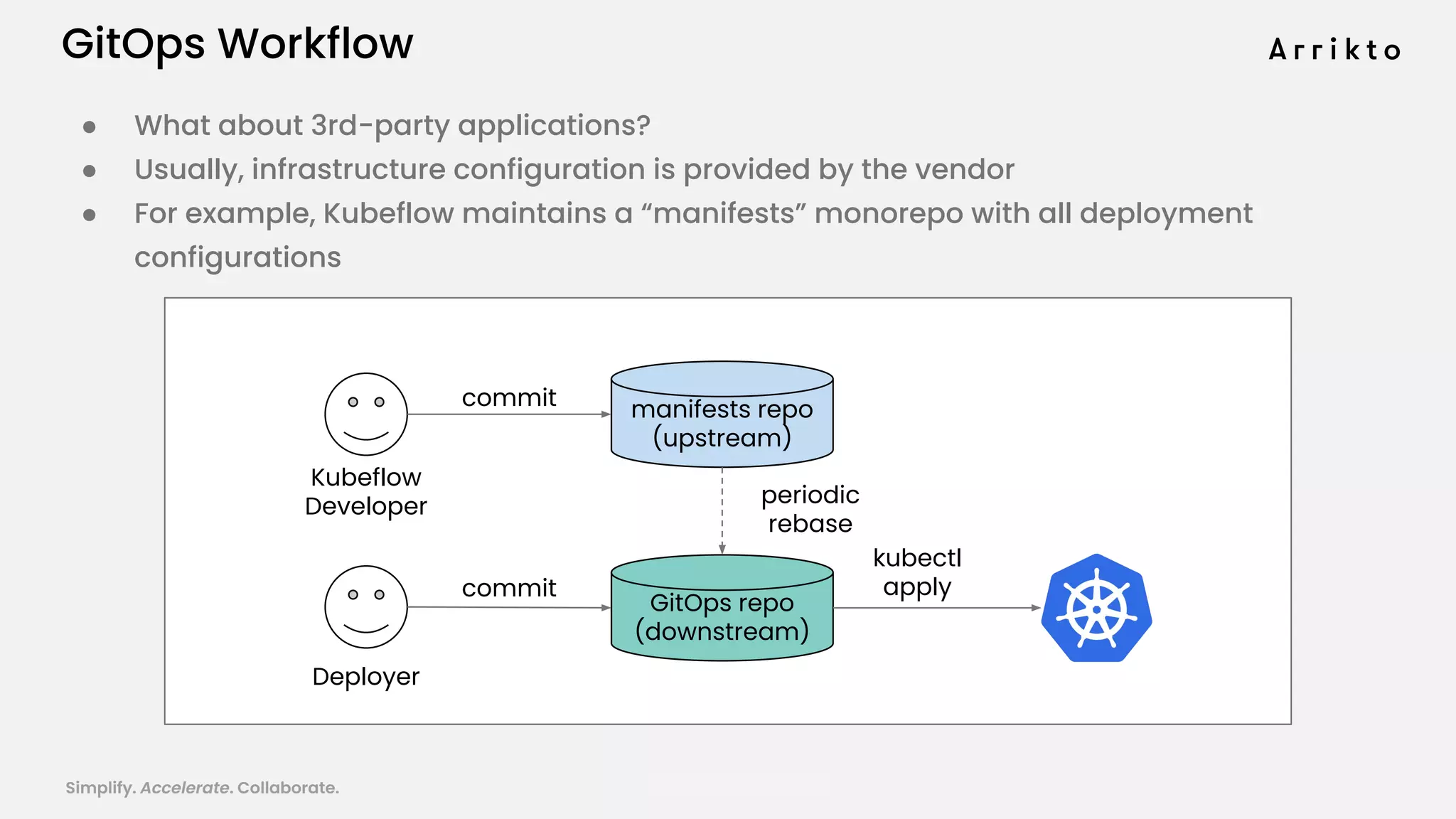
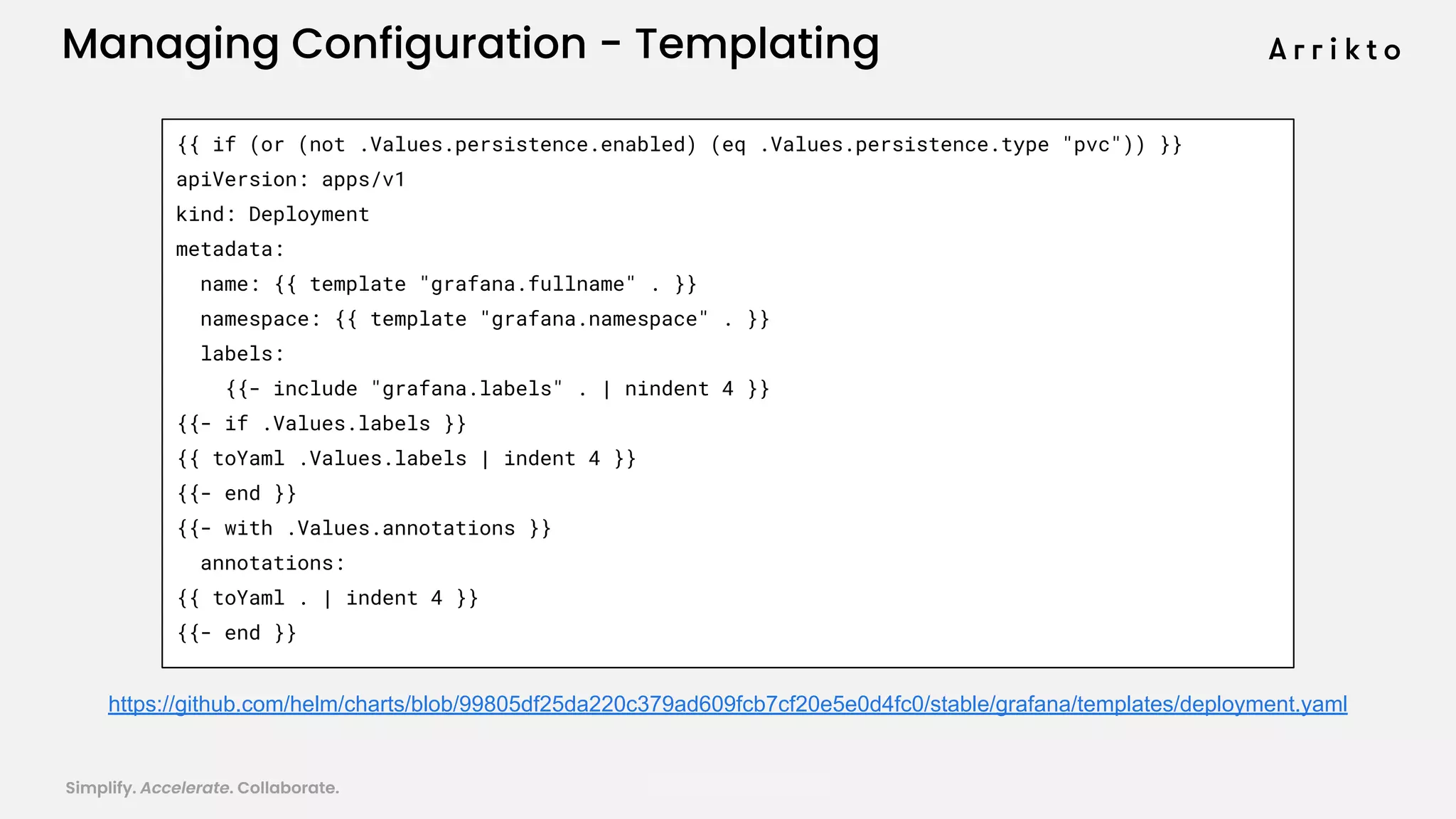
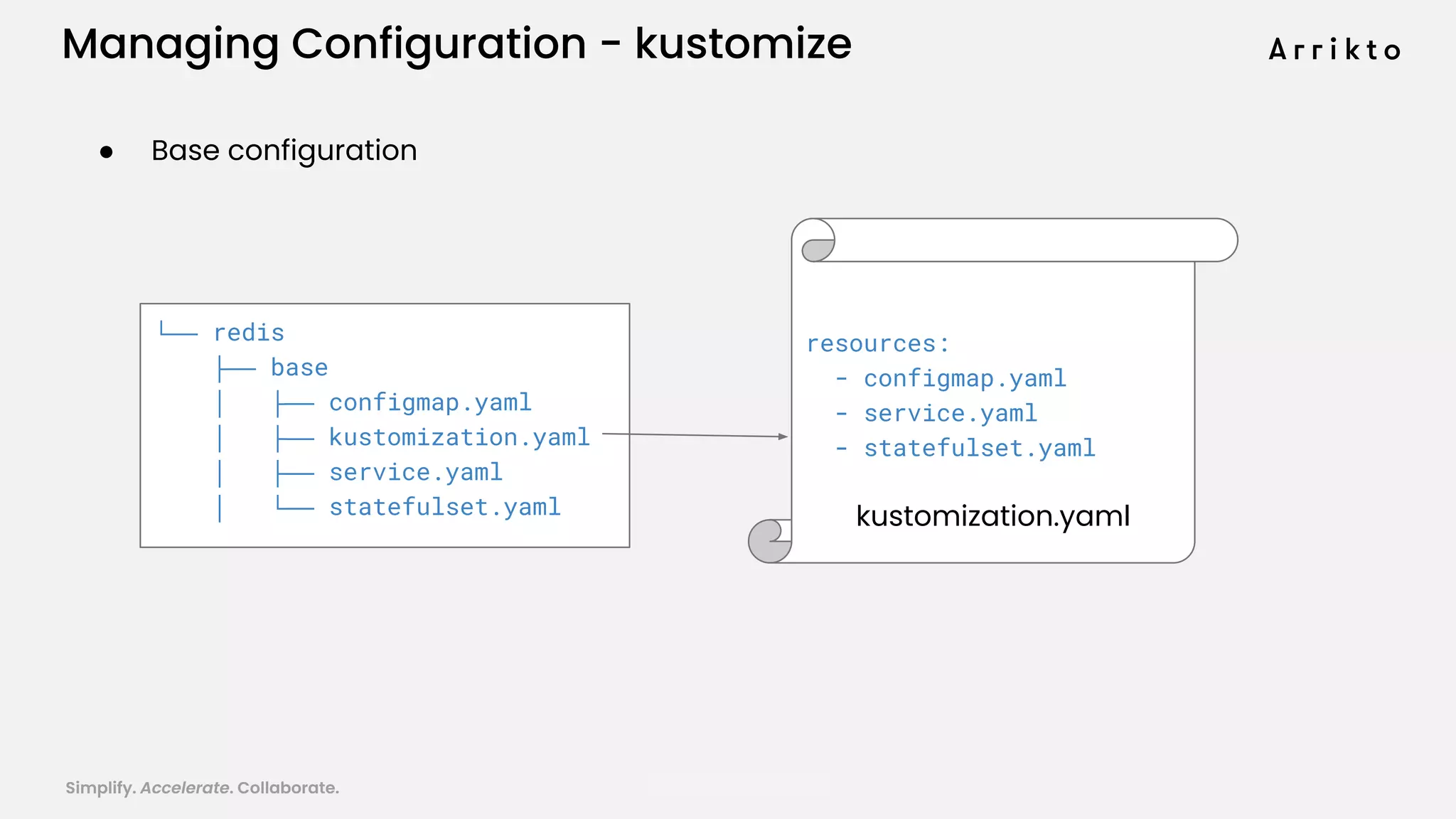
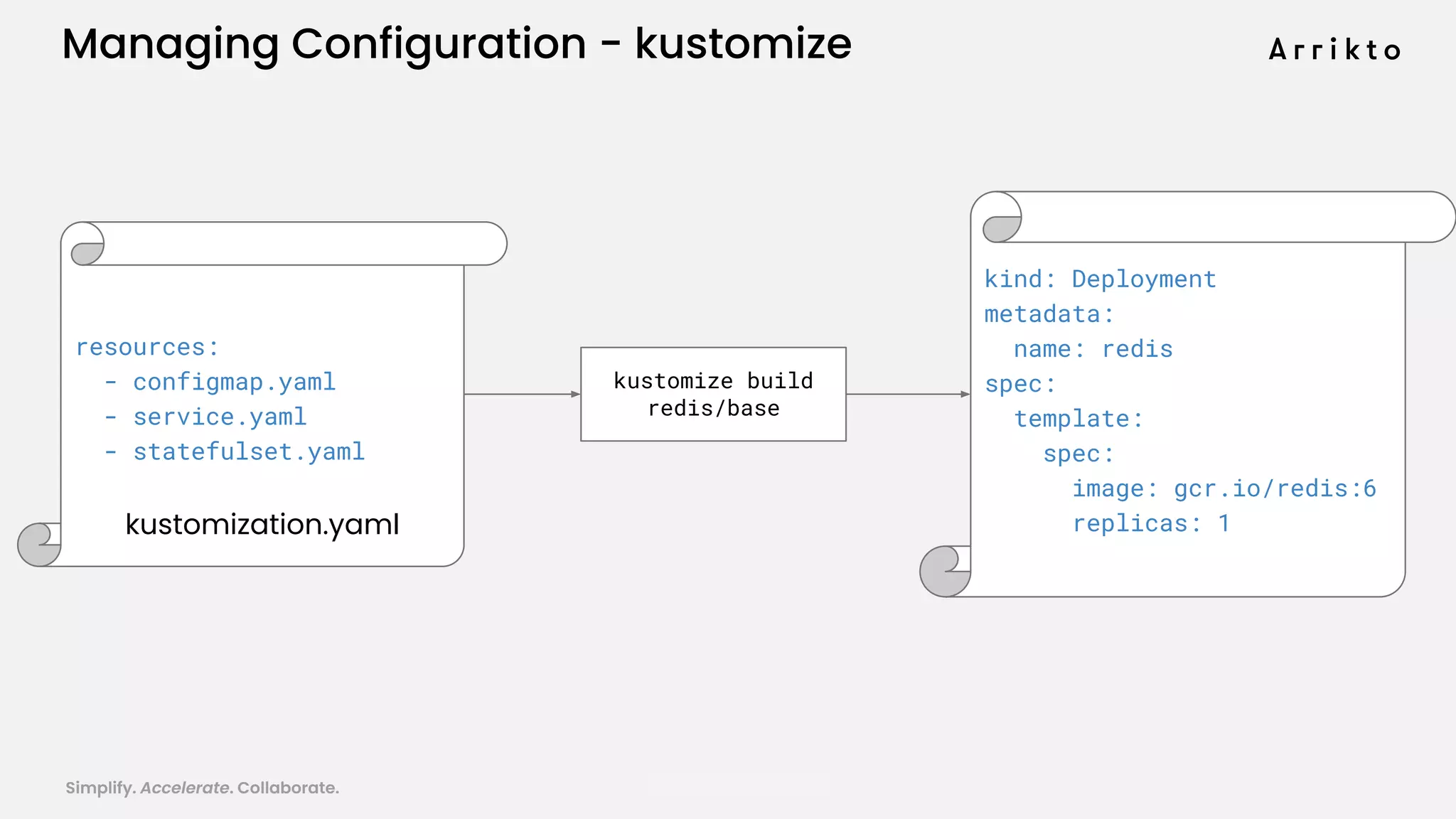
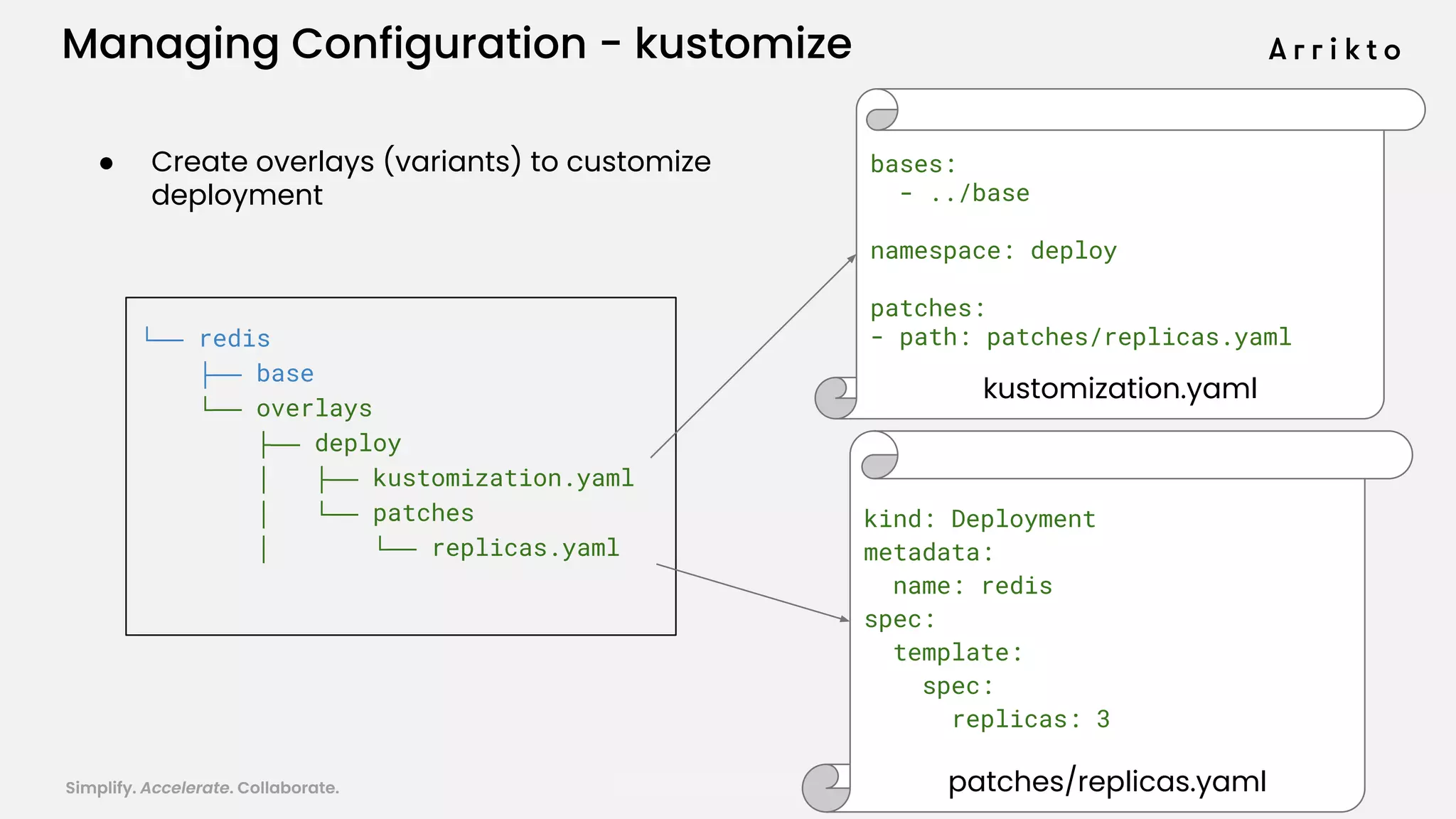
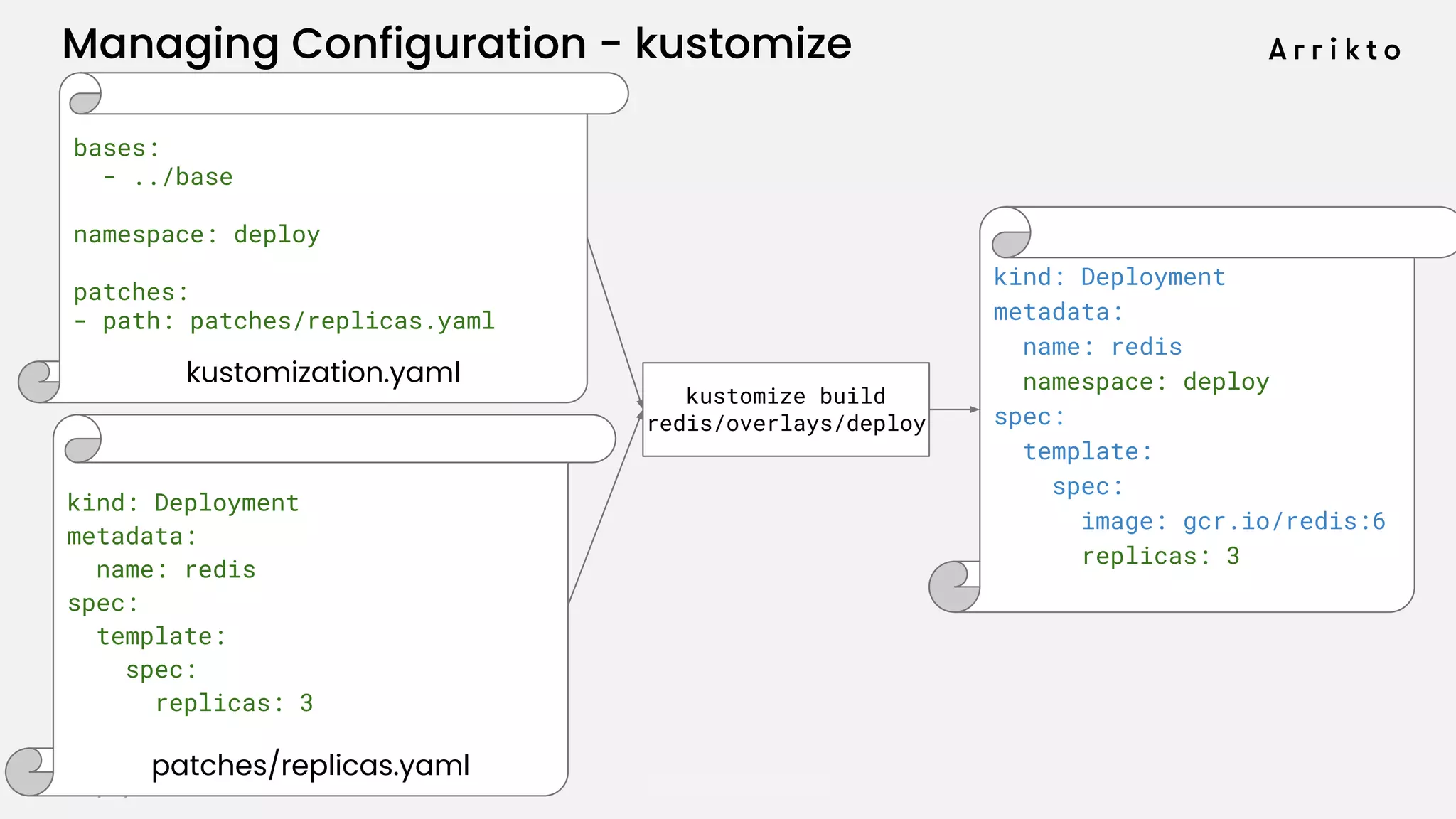
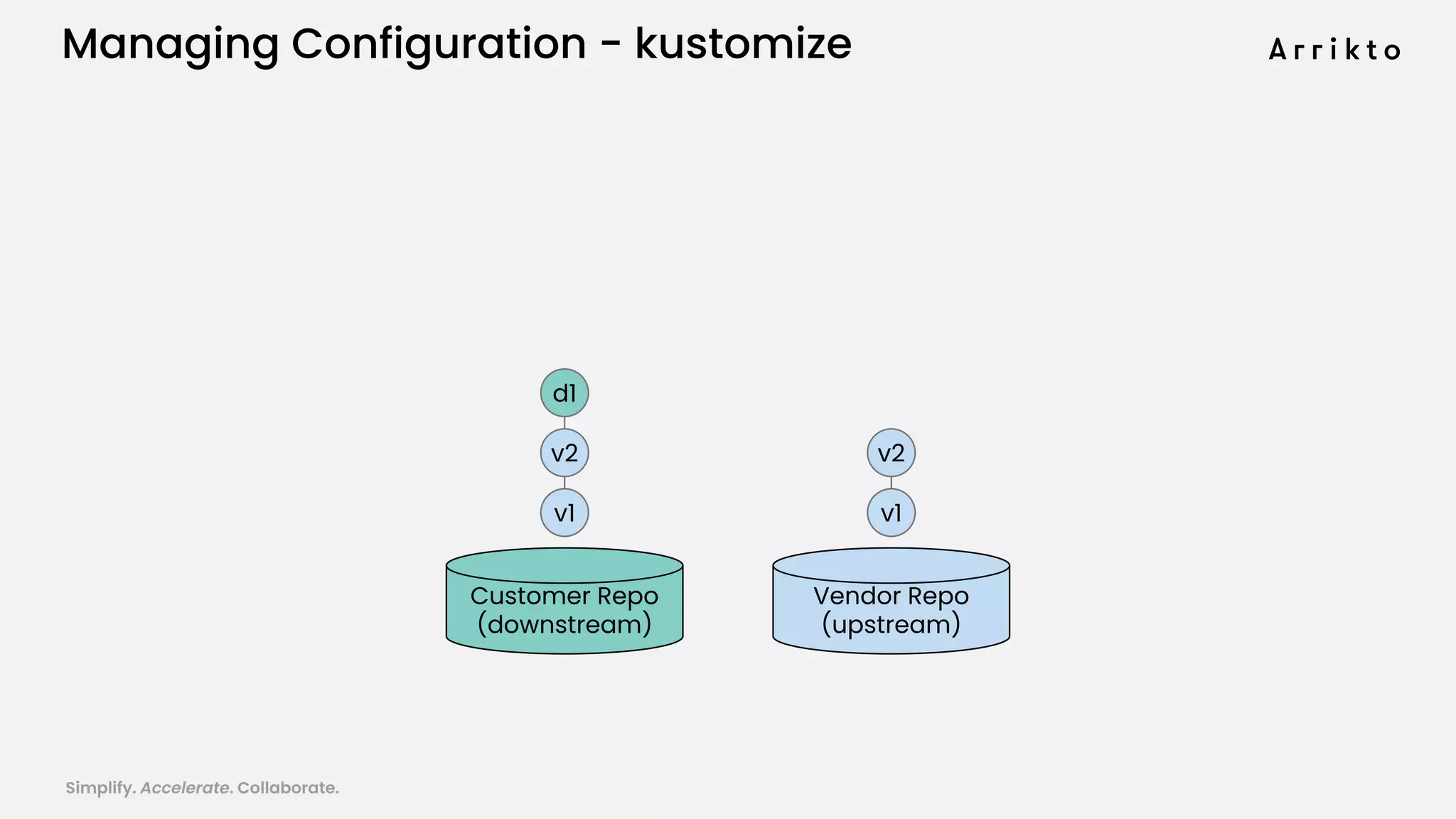
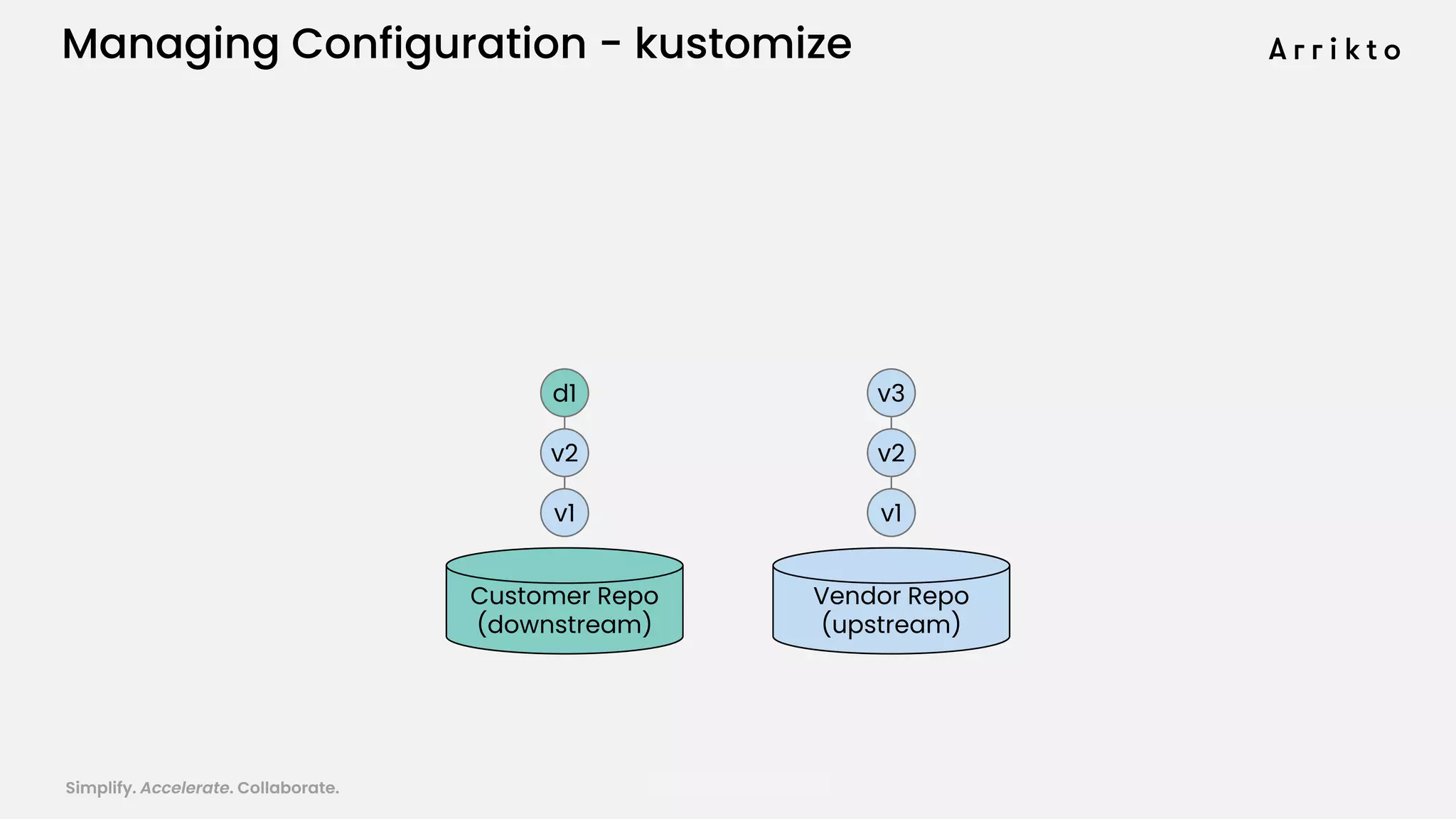
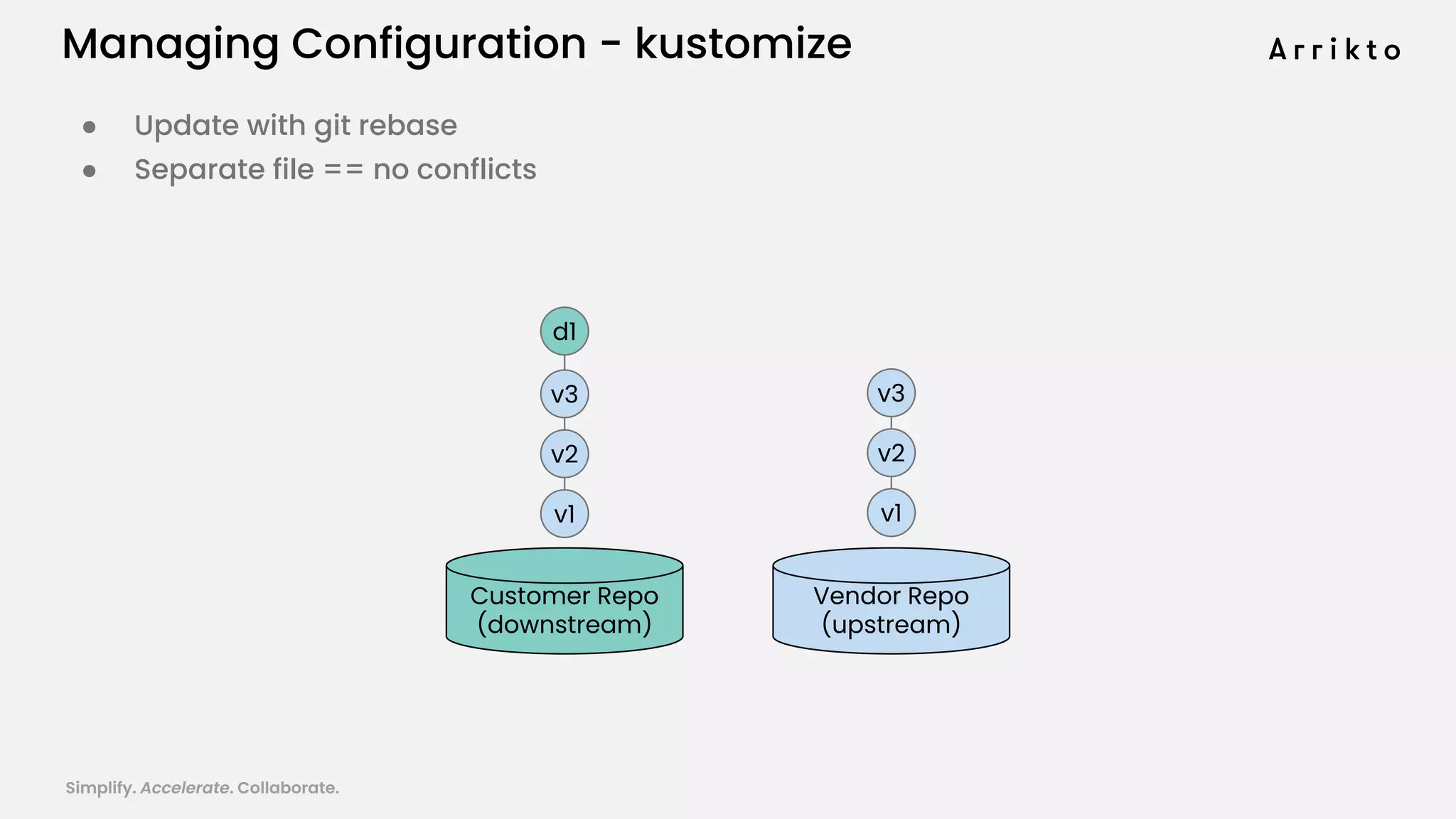
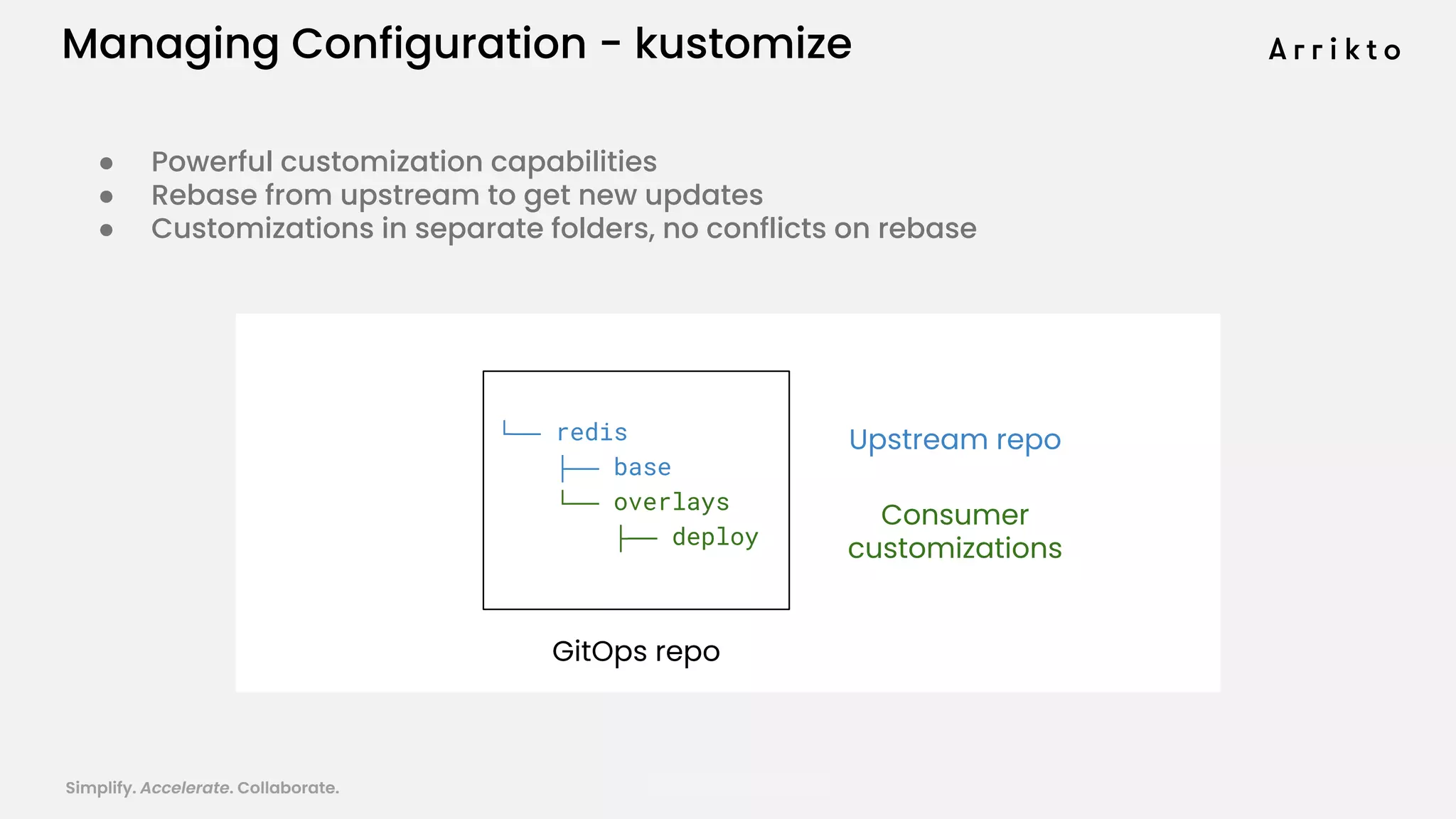
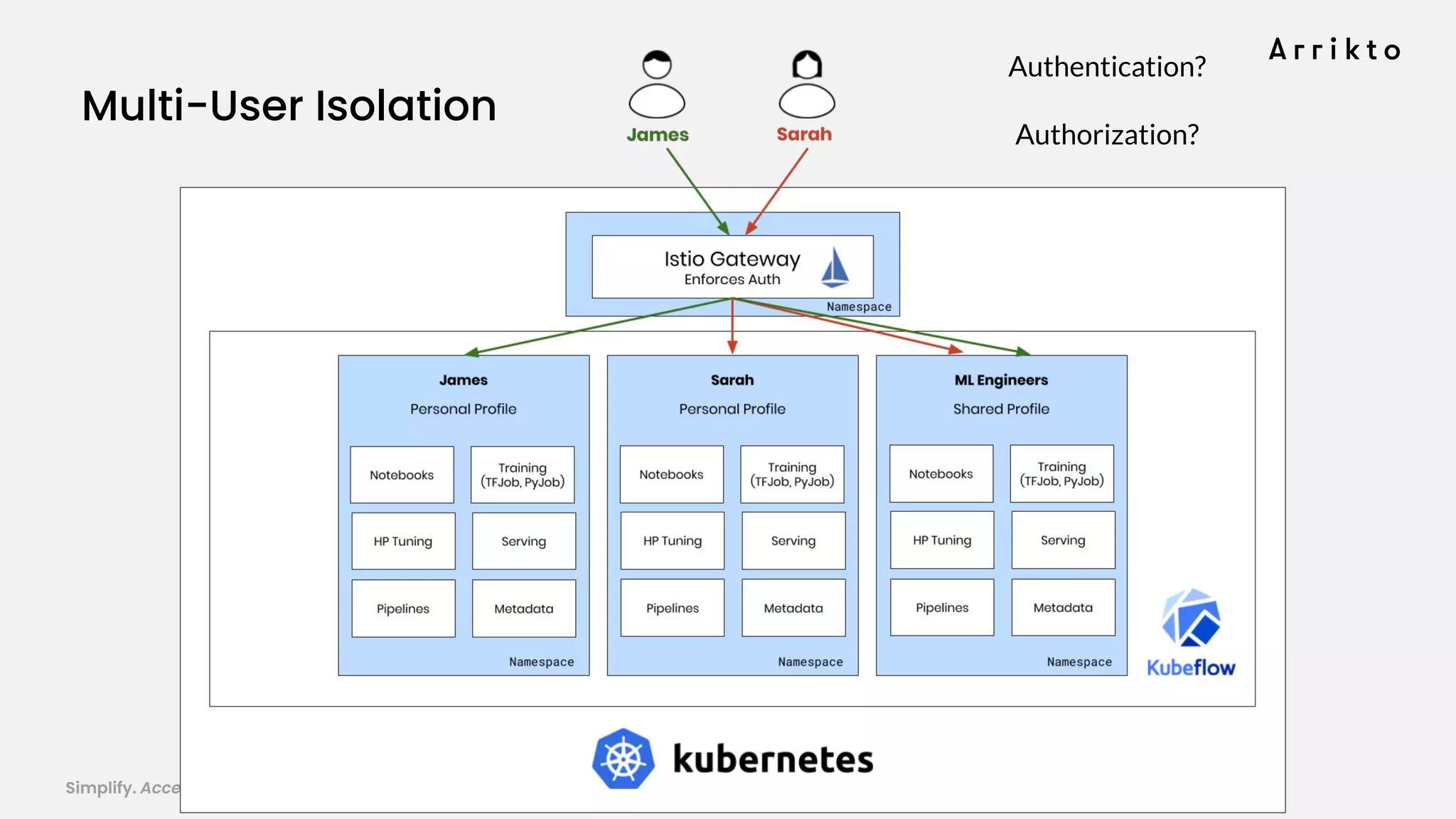
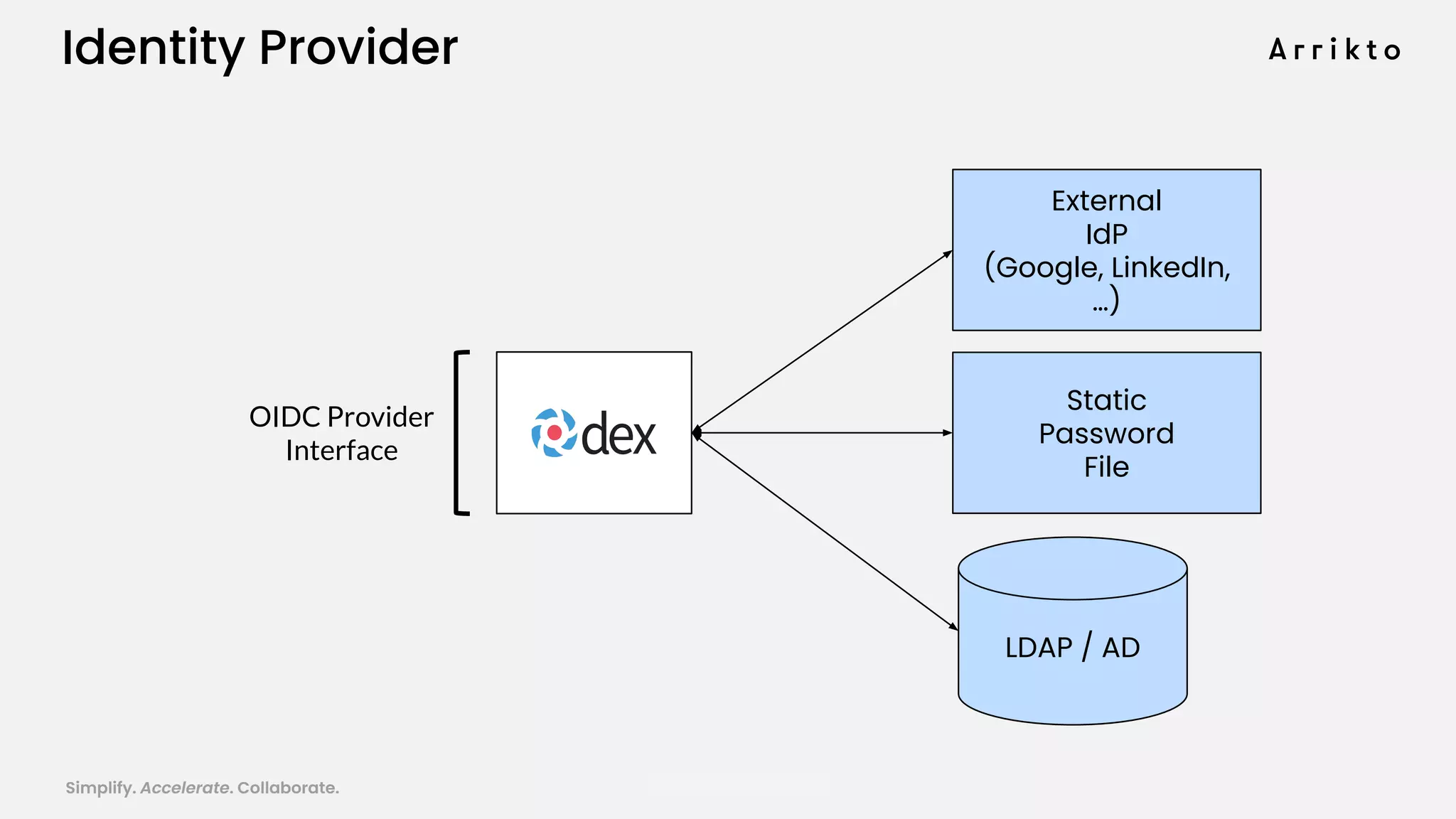
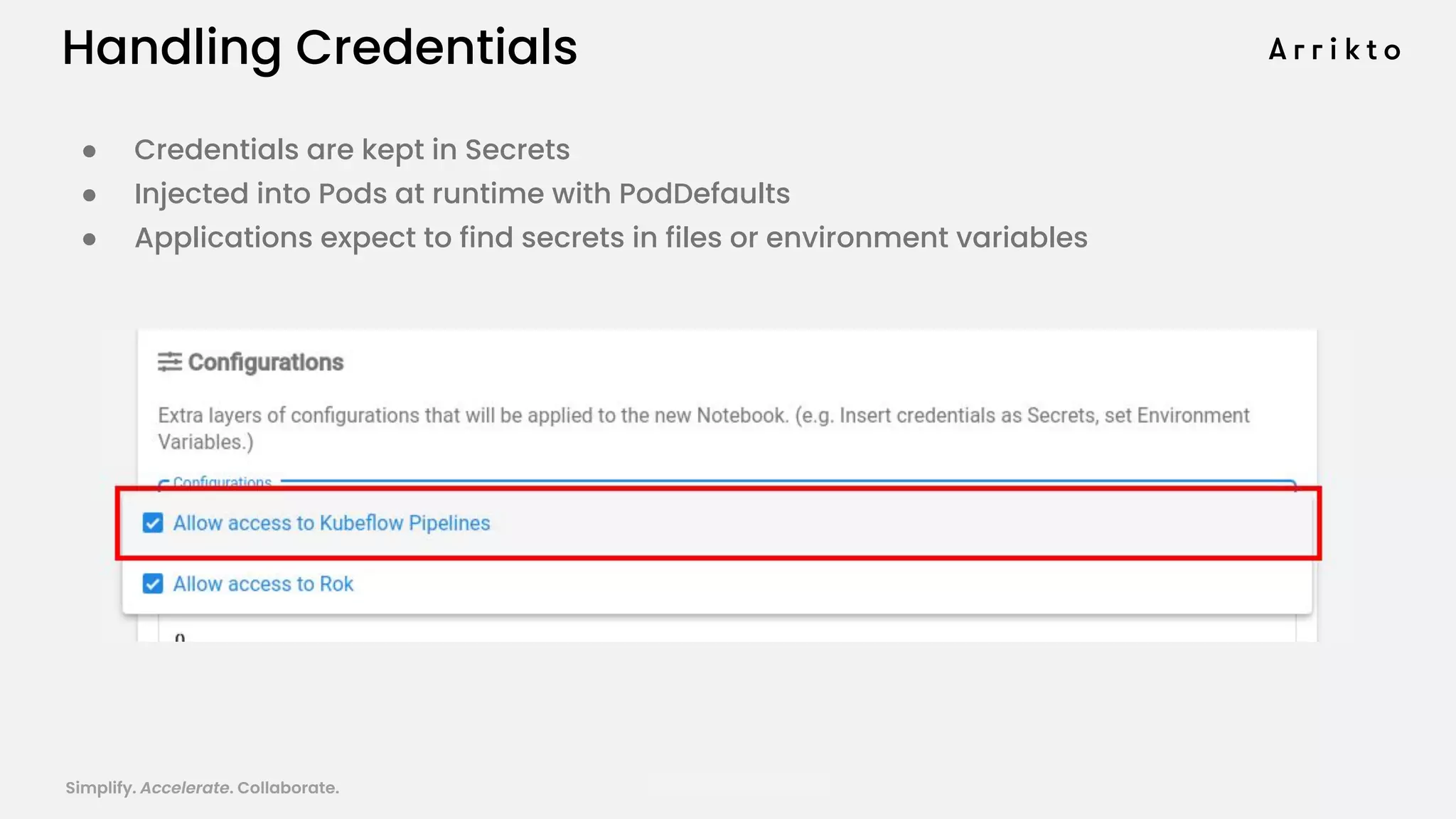
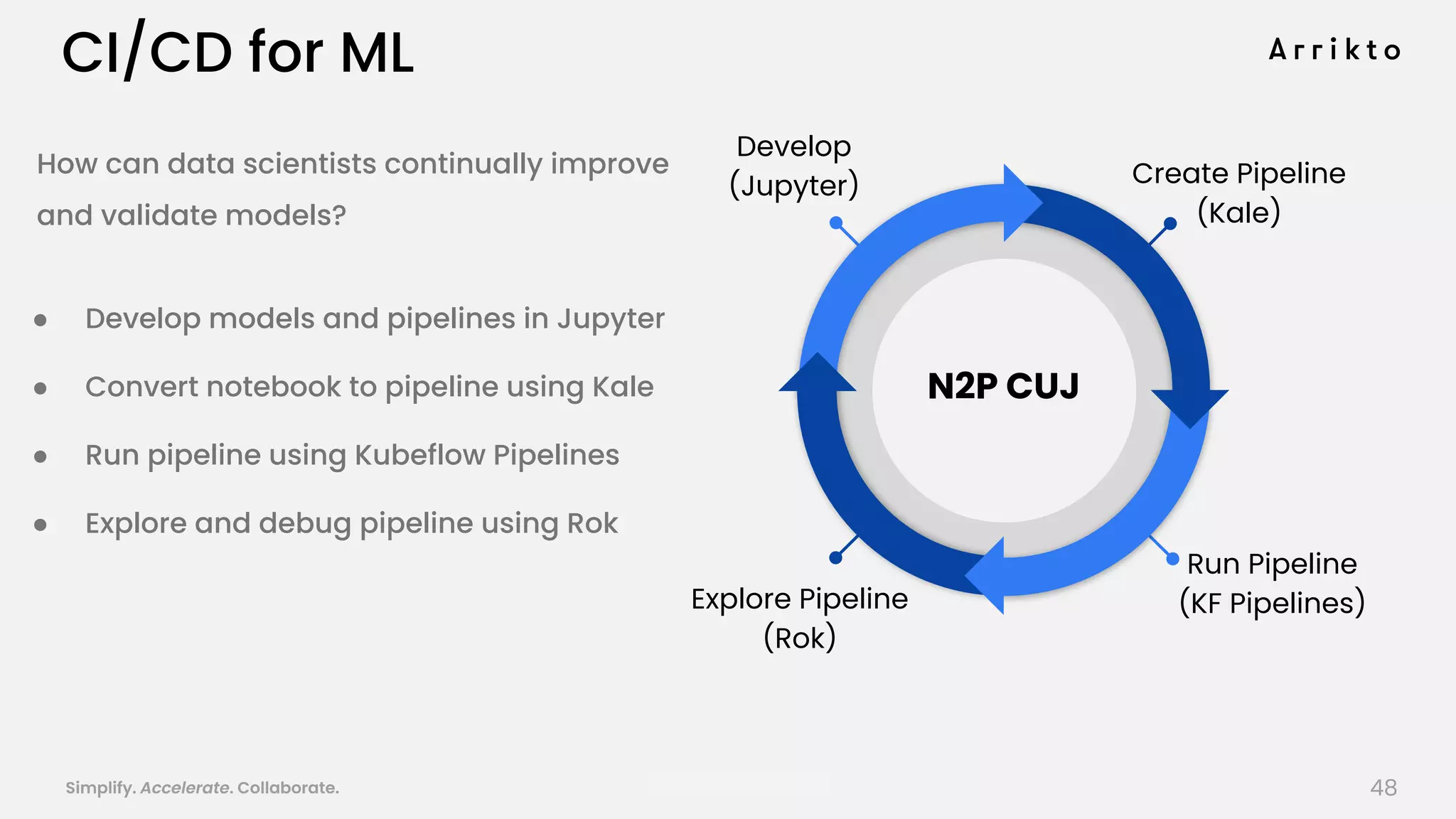
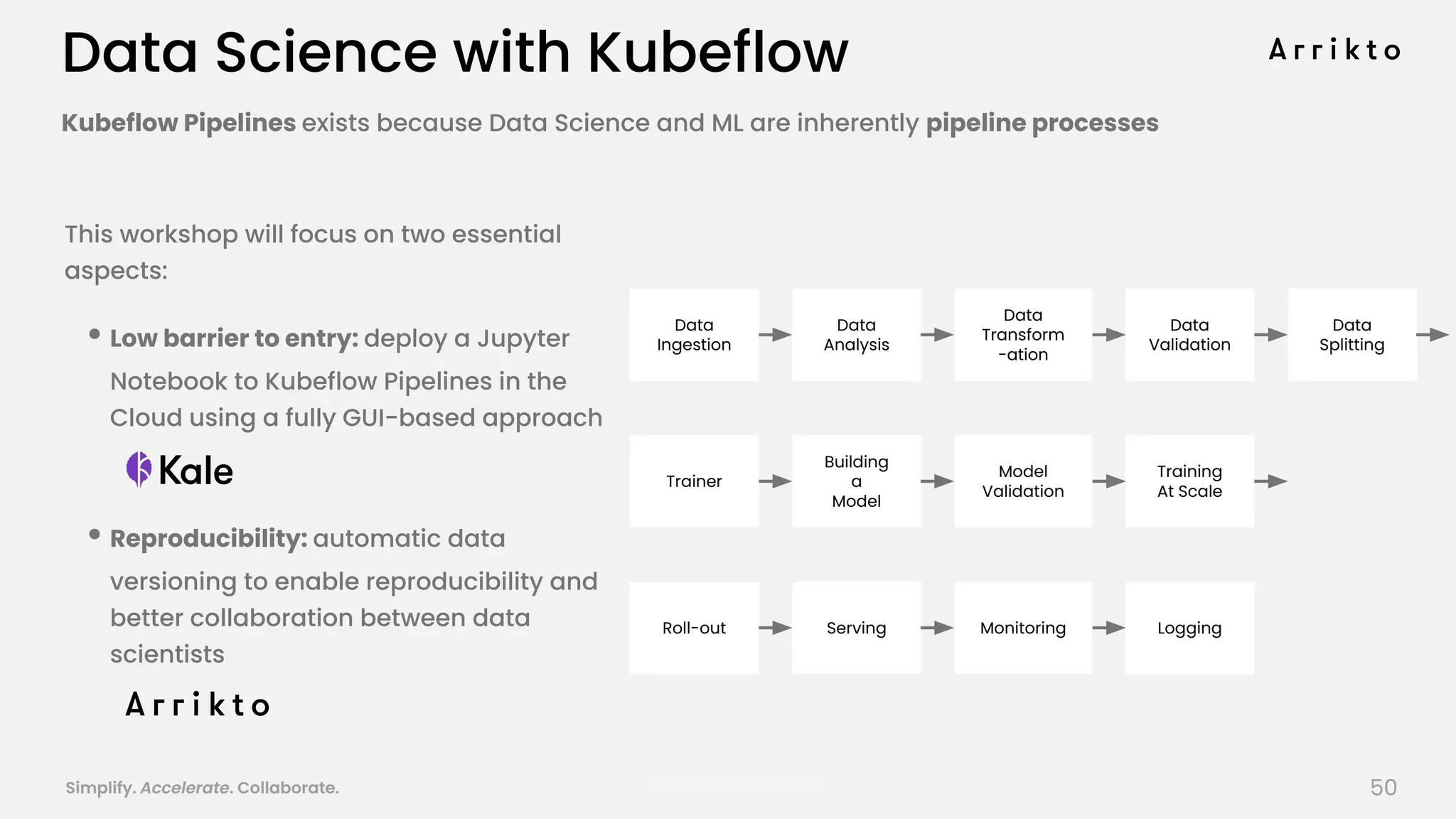
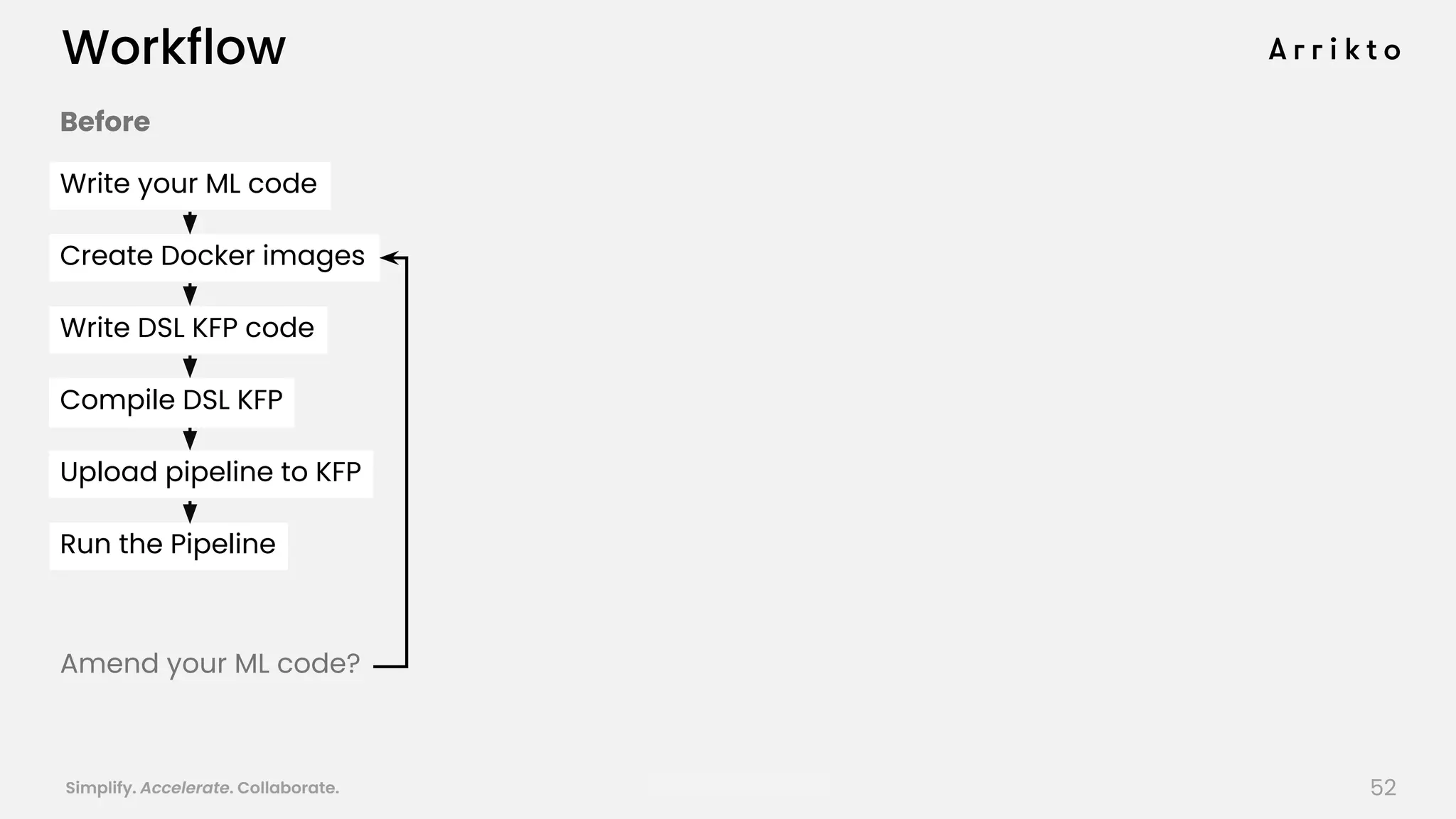
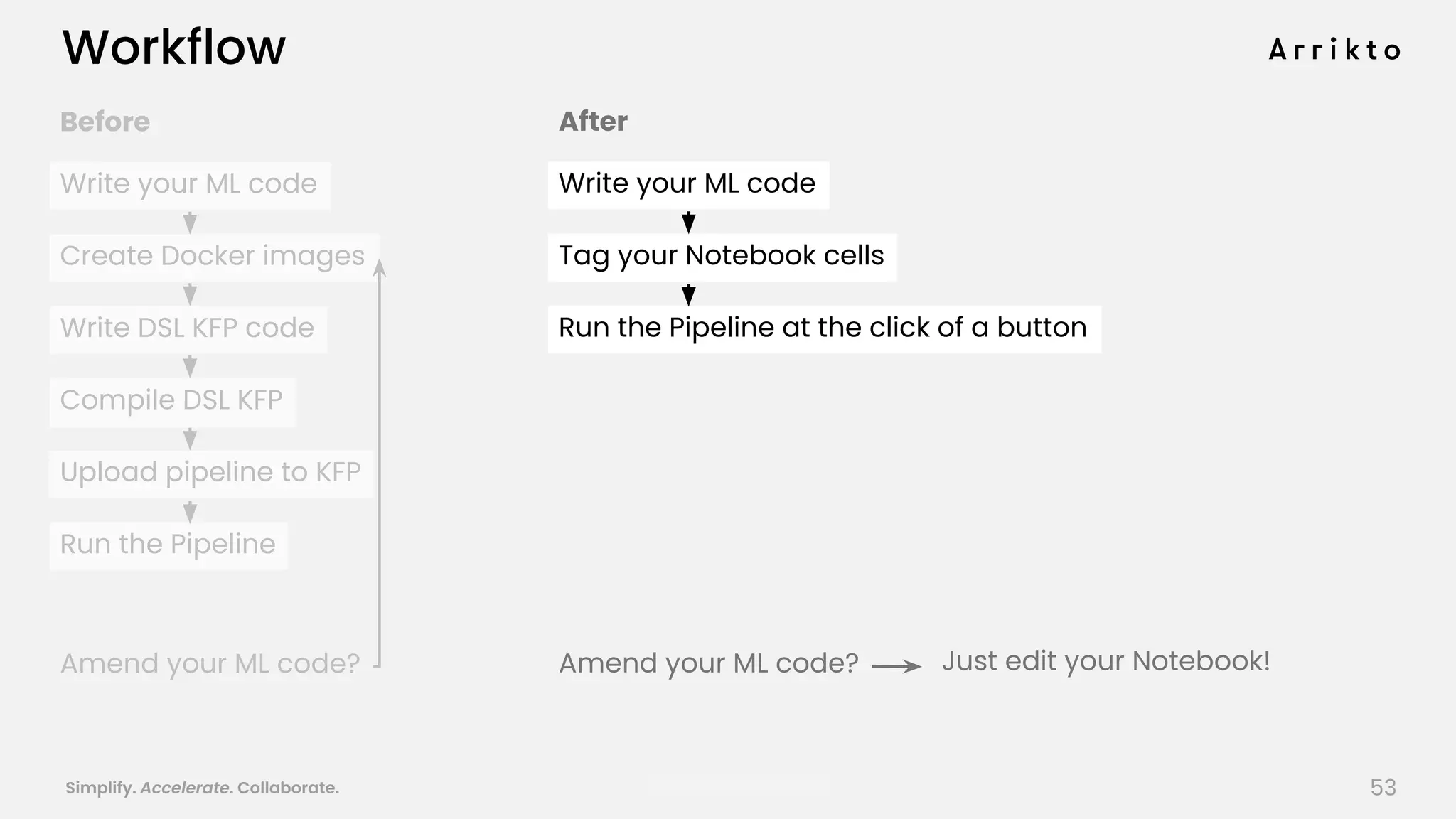
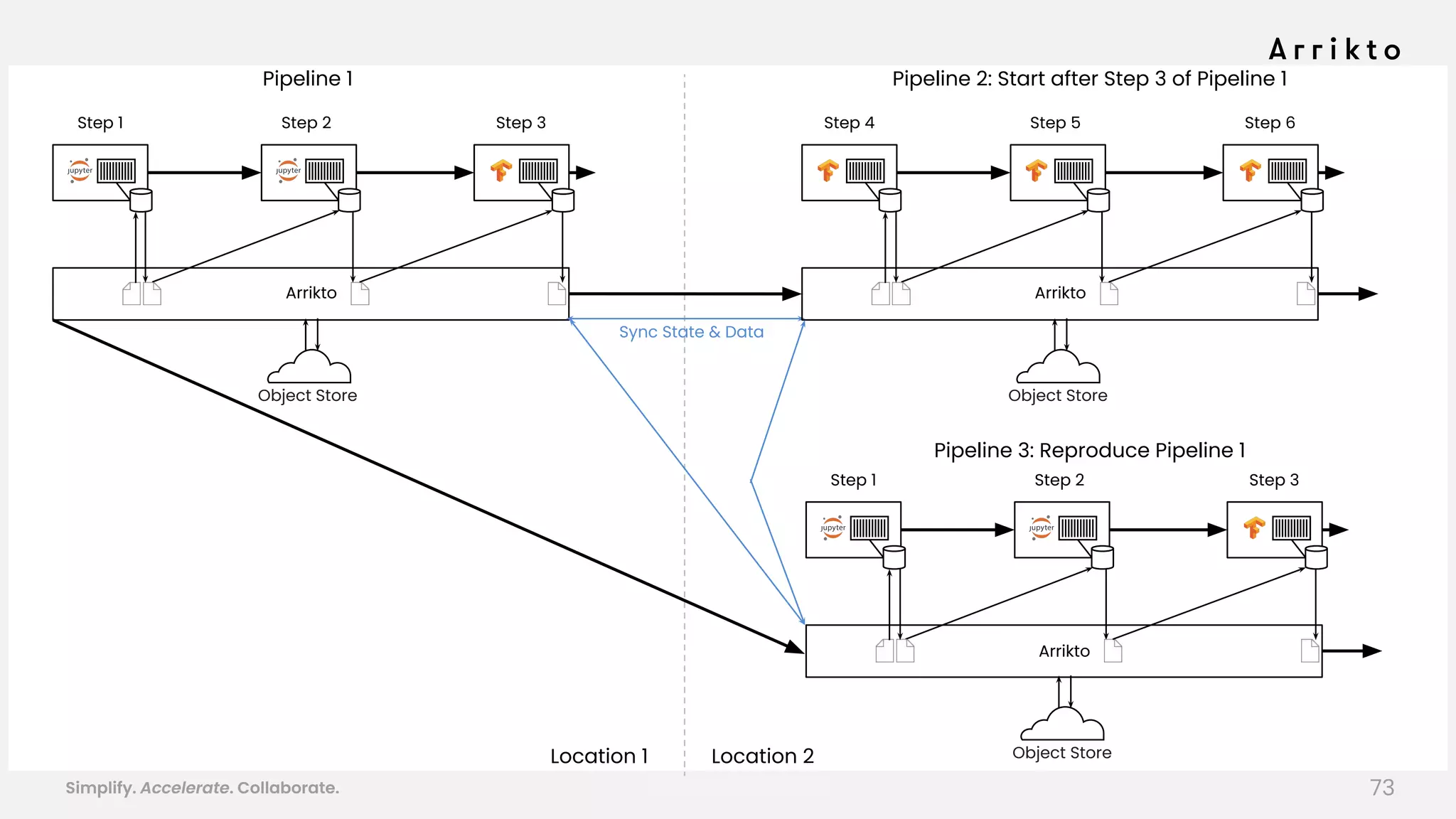
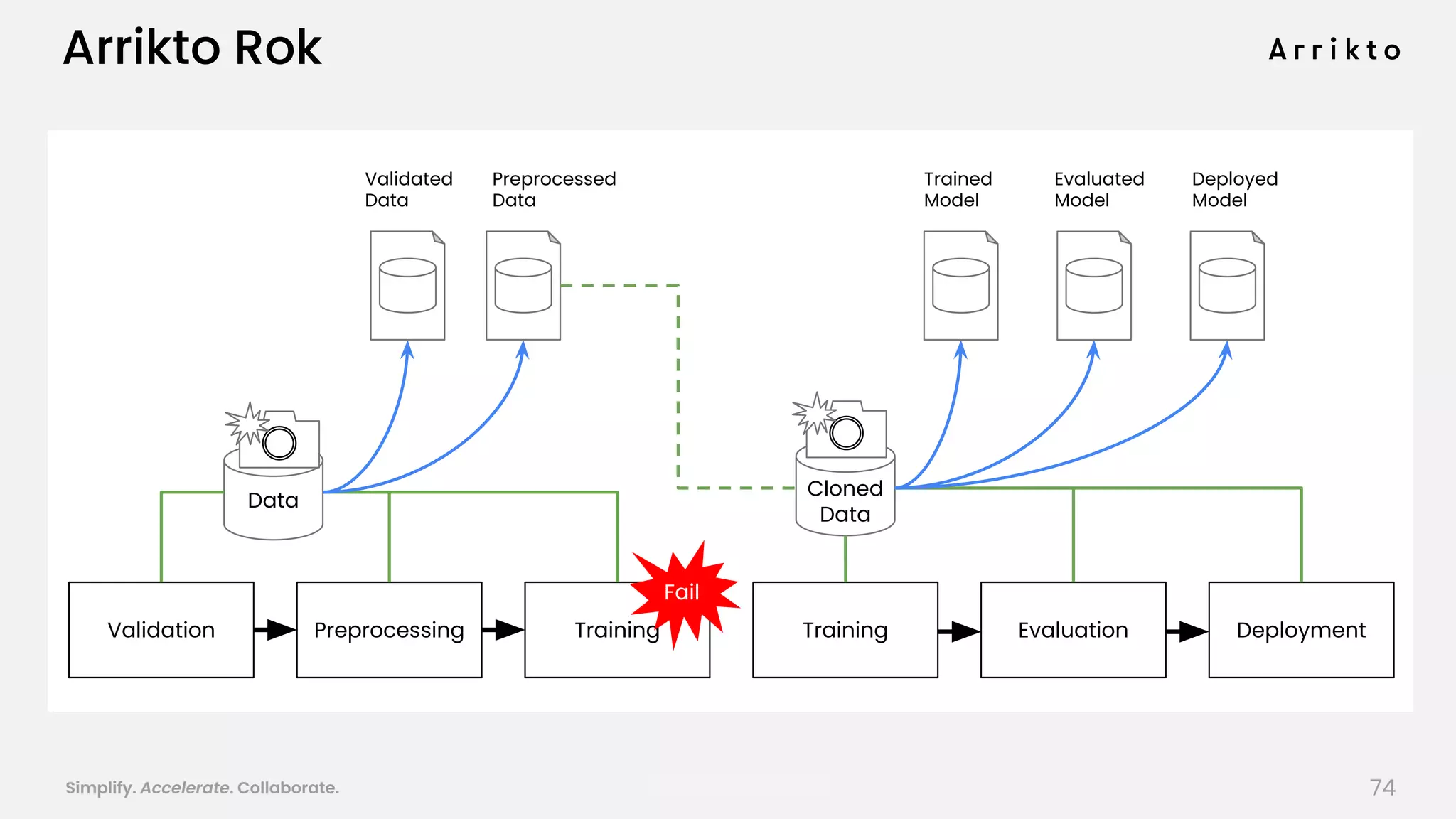
This document discusses using GitOps and multi-tenancy to provide an enterprise data science experience on Kubeflow. It describes how to deploy and manage Kubeflow using GitOps to simplify operations and accelerate time to production. GitOps allows storing all configuration in Git for versioning, rollbacks, and collaboration. Kustomize is used to manage configurations and integrate changes from upstream Kubeflow repositories while allowing customizations. This provides reproducibility, isolation of tenants, and easy upgrades in a production-ready Kubeflow cluster.





















































![Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]](https://cdn.slidesharecdn.com/ss_thumbnails/tfx-kfp-191031073013-thumbnail.jpg?width=640&height=640&fit=bounds)



















































