로그가 데이터가 되려면
•
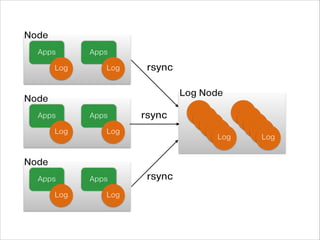
흩어져있는 로그 파일들 - 수집
•
서로 다른 파일 들 - 하나의 타임라인으로 통합
•
정규화 되지 않은 로그 메시지들 - 선별 및 정규화
24.
바람직한 로그
•
로그 파일생성시 파일(경로)명에 필요한 정보
•
•
로그를 생성한 서버의 종류
•
•
로그가 발생한 일시
로그를 생성한 서버의 번호
로그 파일 내용에 필요한 할 정보
•
•
•
로그 메시지를 출력한 일시 (년:월:일 - 시:분:초)
로그 메시지의 레벨 (크리티컬, 에러, 워닝, 정보, 디버그)
로그가 수집될 때 파일(경로)에 필요한 할 정보
•
로그를 생성한 노드(머신) 이름 - 지역 정보 포함 권장
WzDat 셀렉터
뒤에 ~s가붙은 복수형 단어, 각괄호 [ ] 로 조건 기술
•
files - 파일 선택
•
nodes - 노드(머신) 선택
•
servers - 서버(앱) 선택
•
dates - 일시(Date Time) 선택
34.
files
•
모든 파일을 선택
files
•
첫번째, 마지막 파일
files[0], files[-1]
•
100번째 에서 10개 파일
files[100:110]
•
앞에서 10개, 뒤에서 10개
files[:10], files[-10:]
35.
dates
•
파일이 있는 모든일시를 선택
dates
•
파일이 있는 첫 번째, 마지막 일시
dates[0], dates[-1]
•
같은 식으로
dates[100:110], dates[:10], date[-10:]
36.
nodes
•
파일을 만든 모든노드(머신)를 선택
nodes
•
파일을 만든 첫 번째, 마지막 노드
nodes[0], nodes[-1]
•
같은 식으로
nodes[100:110], nodes[:10], nodes[-10:]
37.
servers
•
파일을 만든 모든서버(앱)을 선택
servers
•
파일을 만든 첫 번째, 마지막 서버
servers[0], servers[-1]
•
같은 식으로
servers[100:110], servers[:10], servers[-10:]
38.
WzDat 상수
•
‘카테고리 .이름’의 형식
•
파일 분석과정에서 자동으로 정의
•
상수의 카테고리는 공통, 이름은 프로젝트 별로 다양하다. (아
래는 C9의 예)
•
node.ASIA_1 # 아시아 1번 서버 머신
•
server.GameServer # 게임서버
•
date.D2013_07_11 # 2013년 7월 11일
39.
상수로 필터링
•
2013년 7월11일 파일만
files[date.D2013_07_11]
•
게임 서버 파일만
files[server.GameServer]
•
ASIA-1 노드에서 파일이 발생한 일시만
dates[node.ASIA_1]
40.
상수 매칭
•
상수의 앞문자열만 맞으면 모두 매칭
# node.ASIA_1, node.ASIA_2, … 식으로 여럿 있을 때
files[node.ASIA] # 모든 아시아 노드의 파일이 매칭
41.
셀렉터의 결과로 필터링
•
마지막날의 파일만 선택
files[dates[-1]]
•
마지막 날 파일을 만든 노드만 선택
nodes[dates[-1]]
•
아시아 지역의 마지막 날 파일만 선택
files[dates[node.ASIA][-1]]
42.
복합 조건 필터링
•
마지막날의 게임서버 파일만
files[dates[-1], server.GameServer]
•
7월 12일의 게임/인증 서버 파일중 마지막 10개만
files[date.D2013_07_12, server.GameServer,
server.AuthServer][-10:]
43.
파일 병합, 단어검색
•
조건에 맞는 파일들을 합쳐 하나의 임시파일에 저장
files[…].merge()
•
파일들에서 ‘ERR’단어를 포함한 줄만 찾아 임시파일에 저장
files[…].find(‘ERR’)
•
검색 결과 내 재검색
files[…].find(‘ERR’).find(‘OnClose’)
44.
결과 보기
•
선택 결과파일 앞, 뒤 보기
files[…].head(), files(…).tail()
files[…][:-10], files[…].[-10:]
•
파일 내용 앞, 뒤 보기
files[…].merge().head(), files(…).find(‘ERR”).tail()
files[…].merge()[0:10], files(…).find(‘ERR”).[-10:]
45.
DataFrame으로 변환
!
•
병합,찾은 결과를Pandas의 DataFrame으로 변환
files[…].find(…).to_frame()
•
find, merge는 여러 파일을 합쳐주지만, 아직 타
임 라인 소팅은 되지 않은 상태
•
DataFrame으로 만들어 질 때 비로소 시간 순서대로
정렬된다.
46.
WzDat 어댑터와 파일타입
•
프로젝트별로 다르다
•
•
파일 경로명, 파일 종류, 내용 기록 방식등
공용 인터페이스를 위한 프로젝트 어댑터 작성 필요
•
하나 이상의 파일 타입 모듈을 작성
•
c9.log - C9의 로그 파일 모듈 (*.txt)
•
c9.dump - C9 덤프 파일 모듈 (*.dmp)

























![•
좋은 로그 메시지
2013/06/28-13:07:59 [ERR] - File Open Error
2013/06/28-13:08:00 [WRN] - Player Log Out
!
•
부족한 로그 메시지
6/28 File Open Error
Player Log Out](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-26-320.jpg)






![WzDat 셀렉터
뒤에 ~s가 붙은 복수형 단어, 각괄호 [ ] 로 조건 기술
•
files - 파일 선택
•
nodes - 노드(머신) 선택
•
servers - 서버(앱) 선택
•
dates - 일시(Date Time) 선택](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-33-320.jpg)
![files
•
모든 파일을 선택
files
•
첫 번째, 마지막 파일
files[0], files[-1]
•
100번째 에서 10개 파일
files[100:110]
•
앞에서 10개, 뒤에서 10개
files[:10], files[-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-34-320.jpg)
![dates
•
파일이 있는 모든 일시를 선택
dates
•
파일이 있는 첫 번째, 마지막 일시
dates[0], dates[-1]
•
같은 식으로
dates[100:110], dates[:10], date[-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-35-320.jpg)
![nodes
•
파일을 만든 모든 노드(머신)를 선택
nodes
•
파일을 만든 첫 번째, 마지막 노드
nodes[0], nodes[-1]
•
같은 식으로
nodes[100:110], nodes[:10], nodes[-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-36-320.jpg)
![servers
•
파일을 만든 모든 서버(앱)을 선택
servers
•
파일을 만든 첫 번째, 마지막 서버
servers[0], servers[-1]
•
같은 식으로
servers[100:110], servers[:10], servers[-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-37-320.jpg)

![상수로 필터링
•
2013년 7월 11일 파일만
files[date.D2013_07_11]
•
게임 서버 파일만
files[server.GameServer]
•
ASIA-1 노드에서 파일이 발생한 일시만
dates[node.ASIA_1]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-39-320.jpg)
![상수 매칭
•
상수의 앞 문자열만 맞으면 모두 매칭
# node.ASIA_1, node.ASIA_2, … 식으로 여럿 있을 때
files[node.ASIA] # 모든 아시아 노드의 파일이 매칭](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-40-320.jpg)
![셀렉터의 결과로 필터링
•
마지막 날의 파일만 선택
files[dates[-1]]
•
마지막 날 파일을 만든 노드만 선택
nodes[dates[-1]]
•
아시아 지역의 마지막 날 파일만 선택
files[dates[node.ASIA][-1]]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-41-320.jpg)
![복합 조건 필터링
•
마지막 날의 게임서버 파일만
files[dates[-1], server.GameServer]
•
7월 12일의 게임/인증 서버 파일중 마지막 10개만
files[date.D2013_07_12, server.GameServer,
server.AuthServer][-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-42-320.jpg)
![파일 병합, 단어 검색
•
조건에 맞는 파일들을 합쳐 하나의 임시파일에 저장
files[…].merge()
•
파일들에서 ‘ERR’단어를 포함한 줄만 찾아 임시파일에 저장
files[…].find(‘ERR’)
•
검색 결과 내 재검색
files[…].find(‘ERR’).find(‘OnClose’)](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-43-320.jpg)
![결과 보기
•
선택 결과 파일 앞, 뒤 보기
files[…].head(), files(…).tail()
files[…][:-10], files[…].[-10:]
•
파일 내용 앞, 뒤 보기
files[…].merge().head(), files(…).find(‘ERR”).tail()
files[…].merge()[0:10], files(…).find(‘ERR”).[-10:]](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-44-320.jpg)
![DataFrame으로 변환
!
•
병합,찾은 결과를 Pandas의 DataFrame으로 변환
files[…].find(…).to_frame()
•
find, merge는 여러 파일을 합쳐주지만, 아직 타
임 라인 소팅은 되지 않은 상태
•
DataFrame으로 만들어 질 때 비로소 시간 순서대로
정렬된다.](https://image.slidesharecdn.com/wzdatpandas-131205093438-phpapp01/85/WzDat-Pandas-45-320.jpg)



































![[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=640&height=640&fit=bounds)


![NDC 2016, [슈판워] 맨땅에서 데이터 분석 시스템 만들어나가기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=640&height=640&fit=bounds)


![[H3 2012] 로그속 사용자 발자국 들여다보기](https://cdn.slidesharecdn.com/ss_thumbnails/b3-1030-121105213433-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







