Download to read offline



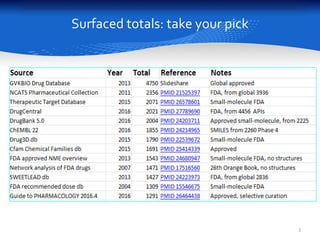
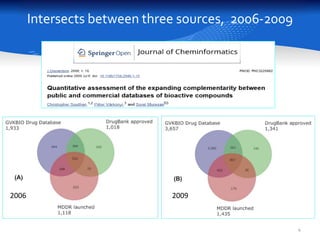


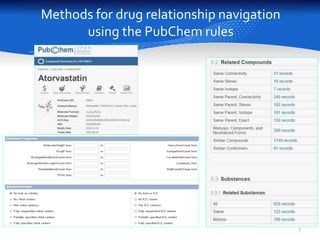
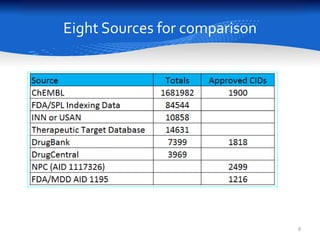
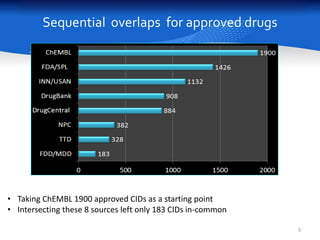

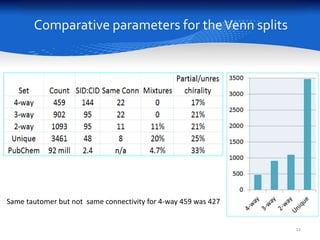
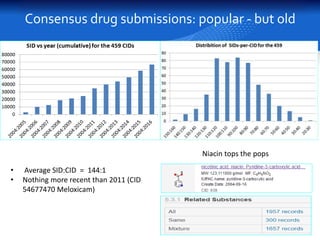
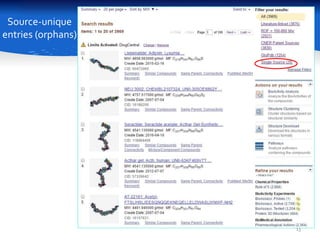



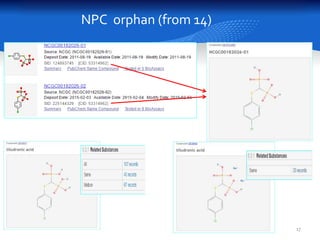
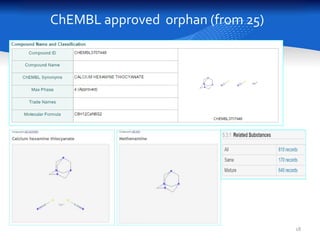
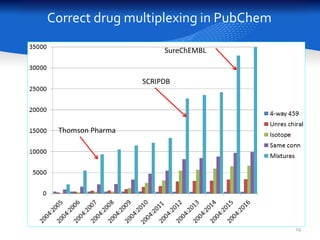





This document summarizes a study comparing different databases of approved drug structures mapped to PubChem identifiers (CIDs). The study found significant discordances between sources, with little consensus on total numbers of approved drugs or their structures. Only 183 structures were common to all 8 sources compared. The sources exhibited extensive structural multiplexing, with the same structure represented by multiple CIDs. This multiplexing extends beyond approved drugs and poses challenges for tasks like QSAR. Improved curation and direct submission of structures from drug developers could help resolve inconsistencies.






































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)














