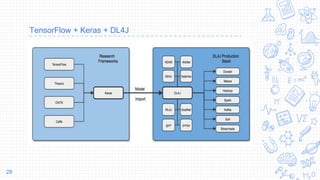
This document discusses why Scala is a good programming language for data science. It begins by providing background on Scala as a functional programming language that runs on the Java Virtual Machine. The main reasons given for using Scala in data science are its robustness for large datasets, integration with common big data tools that run on JVM, and available libraries like Spark MLlib, DeepLearning4J, and ND4J. Code examples are provided showing how to perform tasks with these libraries in Scala. The document also discusses how Scala, Python, and Keras can be used together via TensorFlow for prototyping models in Python and deploying them in Scala applications using DeepLearning4J.


















![object Nd4JScalaSample {
def main (args: Array[String]) {
// Create arrays using the numpy syntax
var arr1 = Nd4j.create(4)
val arr2 = Nd4j.linspace(1, 10, 10)
// Fill an array with the value 5 (equivalent to fill method in numpy)
println(arr1.assign(5) + "Assigned value of 5 to the array")
// Basic stats methods
println(Nd4j.mean(arr1) + "Calculate mean of array")
println(Nd4j.std(arr2) + "Calculate standard deviation of array")
println(Nd4j.`var`(arr2), "Calculate variance")
...
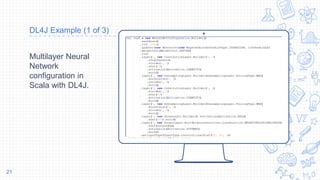
ND4J Example
ND4J tries to fill the
gap between JVM
languages and
Python
programmers in
terms of availability
of powerful data
analysis tools.
20](https://image.slidesharecdn.com/whyscalafordatascience-180916123104/85/Why-scala-for-data-science-20-320.jpg)