Download as PDF, PPTX
![why is a[1] fast than a.get
(1)
果凍](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-1-320.jpg)
![why is a[1] fast than a.get
(1)
果凍](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/75/Why-is-a-1-fast-than-a-get-1-1-2048.jpg)
![why is a[1] fast than a.get(1)
import timeit
print timeit.timeit('a={1:1};a.get(1)',
number=10000)
print timeit.timeit('a={1:1};a[1]', number=10000)](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-2-320.jpg)
![Let we see opcode
def func():
a = {1:1}
a[1]
a.get(1)
import dis
dis.dis(func)](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-3-320.jpg)
![a[1]
3 13 LOAD_FAST 0 (a)
16 LOAD_CONST 1 (1)
19 BINARY_SUBSCR
20 POP_TOP
use
BINARY_SUBSCR](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-4-320.jpg)

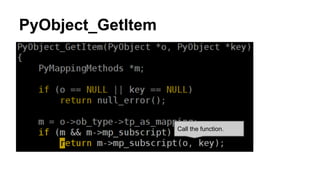
![Let we see python implementation, a
[1]
Call the function.](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-6-320.jpg)



![Summary
● This is why a[1] is fast than a.get(1)
○ a.get(1) do more thing than a[1]
● what about a.__getitem__ ?
○ The opcode is CALL_FUNCTION. slower.
○ But it call dict_subscript instead of dict_get. fast.
○ a[1] is fast than a.__getitem__(1). And a.
__getitem__(1) is fast than a.get(1)](https://image.slidesharecdn.com/whyisa1fastthana-150329085113-conversion-gate01/85/Why-is-a-1-fast-than-a-get-1-14-320.jpg)

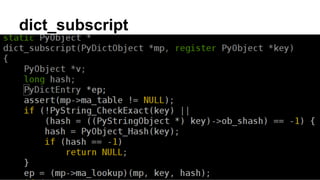
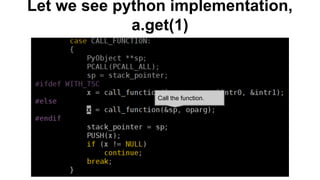
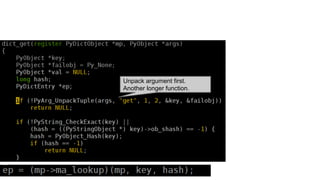
a[1] is faster than a.get(1) because: 1) a[1] uses direct element access via BINARY_SUBSCR which is faster than a function call. 2) a.get(1) must unpack arguments, call multiple functions, and ultimately call dict_get() which introduces overhead compared to direct element access. 3) a.__getitem__(1) also uses a function call but calls the faster dict_subscript instead of dict_get(), so it is faster than a.get(1) but slower than direct element access with a[1].





























































