Downloaded 26 times













![LLM initial request
"functions":[
{
"name":"getBookingDetails",
"description":"Get booking details for {bookingNumber} and customer {firstName} {lastName}",
"parameters":{
"type":"object",
"properties":{
"firstName":{
"type":"string"
},
"lastName":{
"type":"string"
},
"bookingNumber":{
"type":"string"
}
},
"required":[
"bookingNumber",
"firstName",
"lastName"
]
}
}, …]](https://image.slidesharecdn.com/jchateaugenai-240320093421-68f3f089/85/When-GenAI-meets-with-Java-with-Quarkus-and-langchain4j-23-320.jpg)
![LLM intermediate response
"choices":[
{
"finish_reason":"function_call",
"index":0,
"message":{
"role":"assistant",
"function_call":{
"name":"getBookingDetails",
"arguments":"{"firstName":"James","lastName":"Bond","bookingNumber":"456-789"}"
}
},
…
}
]](https://image.slidesharecdn.com/jchateaugenai-240320093421-68f3f089/85/When-GenAI-meets-with-Java-with-Quarkus-and-langchain4j-24-320.jpg)

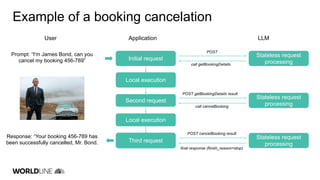





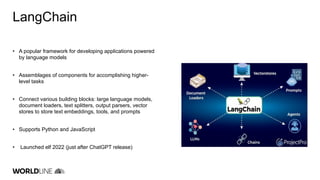
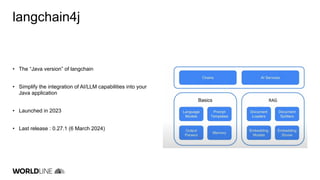
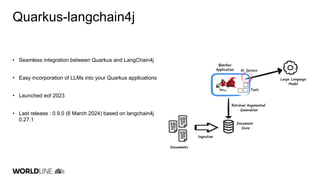
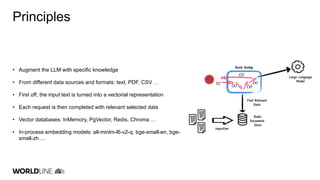
The document discusses the integration of large language models (LLMs) into Java applications using the LangChain4J framework, focusing on a car booking app. It outlines the setup and configuration steps for utilizing Azure's GPT models, along with principles of retrieving augmented data and implementing function calls. The author shares insights on the implementation process, highlighting lessons learned, the potential pitfalls of LLM usage, and suggestions for further development and application beyond initial coding experiments.

































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








