Download as PDF, PPTX


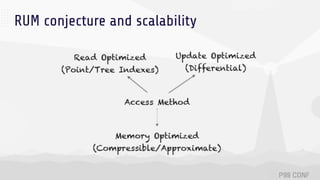



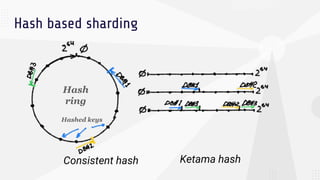
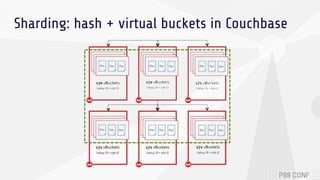
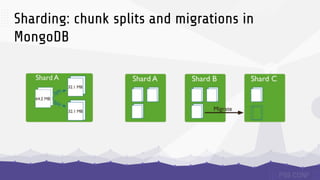
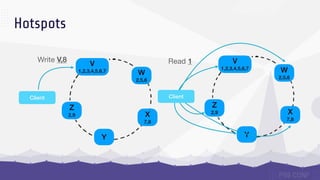
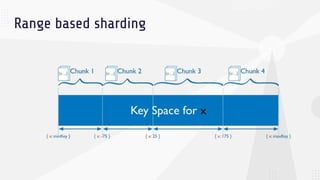




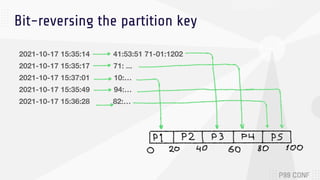

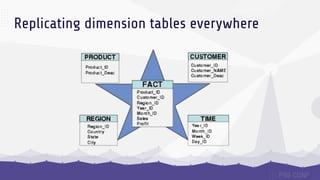



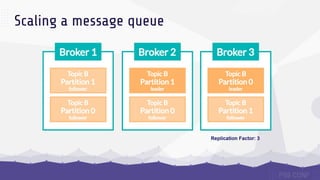


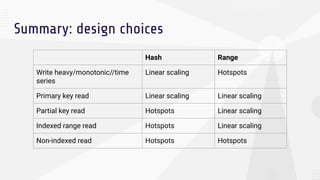


The document discusses data sharding, focusing on the principles of horizontal partitioning to avoid hotspots in distributed databases. Key challenges include data splitting, re-balancing, and query routing, with specific strategies like hash-based and range-based sharding highlighted. It emphasizes the importance of choosing effective shard keys to optimize performance and scalability while mentioning appropriate techniques to mitigate hotspot issues.























































































