Downloaded 13 times










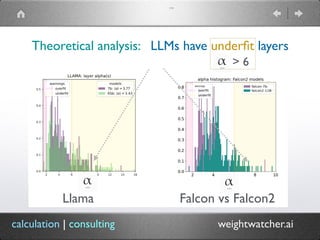





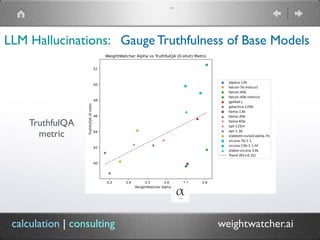











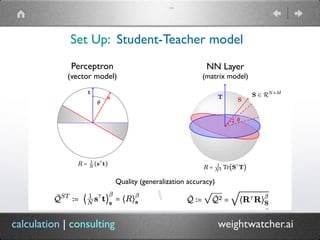























The document introduces WeightWatcher, a tool developed by Dr. Charles H. Martin for analyzing the performance metrics of deep neural network layers, focusing on self-regularization and under/overfitting in machine learning models. It discusses various research findings, including the application of random matrix theory and the importance of layer quality metrics in model training. The tool is open-source, aimed at fostering collaboration, and currently has over 115,000 downloads.


























































![Human Reproduction [ Reproductive System ] Notes @irfanullah_mehar Irfanullah...](https://cdn.slidesharecdn.com/ss_thumbnails/humanreproductionreproductivesystemnotesirfanullahmeharirfanullahmeharjanantantra-260111172350-56e85778-thumbnail.jpg?width=640&height=640&fit=bounds)





