Download as PDF, PPTX












![Outline
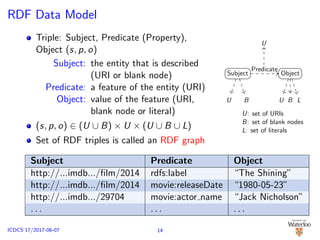
1 RDF Technology [¨Ozsu, 2016]
Data Warehousing Approach
Distributed RDF Processing
2 Federated RDF Systems
SPARQL Endpoint Federation
General RDF Federation
3 LOD – Live Querying Approach [Hartig, 2013a]
Traversal-based approaches
Index-based approaches
Hybrid approaches
4 Conclusions
11ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-17-320.jpg)
![Outline
1 RDF Technology [¨Ozsu, 2016]
Data Warehousing Approach
Distributed RDF Processing
2 Federated RDF Systems
SPARQL Endpoint Federation
General RDF Federation
3 LOD – Live Querying Approach [Hartig, 2013a]
Traversal-based approaches
Index-based approaches
Hybrid approaches
4 Conclusions
12ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-18-320.jpg)
















![Exhaustive Indexing
RDF-3X [Neumann and Weikum, 2008, 2009], Hexastore
[Weiss et al., 2008]
Strings are mapped to ids using a mapping table
Create indexes for permutations of the three columns: SPO,
SOP, PSO, POS, OPS, OSP
Subject Property Object
0 1 2
0 3 4
5 6 7
8 9 5
...
...
...
ID Value
0 mdb: film/2014
1 rdfs:label
2 “The Shining”
3 movie:initial release date
4 “1980-05-23”
5 mdb:director/8476
6 movie:director name
7 “Stanley Kubrick”
8 mdb:film/2685
9 movie:director23ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-39-320.jpg)
![Exhaustive Indexing
RDF-3X [Neumann and Weikum, 2008, 2009], Hexastore
[Weiss et al., 2008]
Strings are mapped to ids using a mapping table
Create indexes for permutations of the three columns: SPO,
SOP, PSO, POS, OPS, OSP
Each triple pattern can be answered by a range query
Joins between triple patterns computed using merge join
Subject Property Object
0 1 2
0 3 4
5 6 7
8 9 5
...
...
...
ID Value
0 mdb: film/2014
1 rdfs:label
2 “The Shining”
3 movie:initial release date
4 “1980-05-23”
5 mdb:director/8476
6 movie:director name
7 “Stanley Kubrick”
8 mdb:film/2685
9 movie:director23ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-40-320.jpg)
![Exhaustive Indexing
RDF-3X [Neumann and Weikum, 2008, 2009], Hexastore
[Weiss et al., 2008]
Strings are mapped to ids using a mapping table
Create indexes for permutations of the three columns: SPO,
SOP, PSO, POS, OPS, OSP
Each triple pattern can be answered by a range query
Joins between triple patterns computed using merge join
Subject Property Object
0 1 2
0 3 4
5 6 7
8 9 5
...
...
...
ID Value
0 mdb: film/2014
1 rdfs:label
2 “The Shining”
3 movie:initial release date
4 “1980-05-23”
5 mdb:director/8476
6 movie:director name
7 “Stanley Kubrick”
8 mdb:film/2685
9 movie:director
Advantages
Eliminates some of the joins – they become range queries
Merge join is easy and fast
23ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-41-320.jpg)
![Exhaustive Indexing
RDF-3X [Neumann and Weikum, 2008, 2009], Hexastore
[Weiss et al., 2008]
Strings are mapped to ids using a mapping table
Create indexes for permutations of the three columns: SPO,
SOP, PSO, POS, OPS, OSP
Each triple pattern can be answered by a range query
Joins between triple patterns computed using merge join
Subject Property Object
0 1 2
0 3 4
5 6 7
8 9 5
...
...
...
ID Value
0 mdb: film/2014
1 rdfs:label
2 “The Shining”
3 movie:initial release date
4 “1980-05-23”
5 mdb:director/8476
6 movie:director name
7 “Stanley Kubrick”
8 mdb:film/2685
9 movie:director
Advantages
Eliminates some of the joins – they become range queries
Merge join is easy and fast
Disadvantages
Space usage
Expensive updates
23ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-42-320.jpg)
![Property Tables
Grouping by entities; Jena [Wilkinson, 2006], DB2-RDF
[Bornea et al., 2013]
Clustered property table: group together the properties that
tend to occur in the same (or similar) subjects
Property-class table: cluster the subjects with the same type
of property into one property table
Subject Property Object
mdb:film/2014 rdfs:label “The Shining”
mdb:film/2014 movie:director mdb:director/8476
mdb:film/2685 movie:director mdb:director/8476
mdb:film/2685 rdfs:label “A Clockwork Orange”
mdb:actor/29704 movie:actor name “Jack Nicholson”
. . . . . . . . .
Subject refs:label movie:director
mob:film/2014 “The Shining” mob:director/8476
mob:film/2685 “The Clockwork Orange” mob:director/8476
Subject movie:actor name
mdb:actor “Jack Nicholson”
24ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-43-320.jpg)
![Property Tables
Grouping by entities; Jena [Wilkinson, 2006], DB2-RDF
[Bornea et al., 2013]
Clustered property table: group together the properties that
tend to occur in the same (or similar) subjects
Property-class table: cluster the subjects with the same type
of property into one property table
Subject Property Object
mdb:film/2014 rdfs:label “The Shining”
mdb:film/2014 movie:director mdb:director/8476
mdb:film/2685 movie:director mdb:director/8476
mdb:film/2685 rdfs:label “A Clockwork Orange”
mdb:actor/29704 movie:actor name “Jack Nicholson”
. . . . . . . . .
Subject refs:label movie:director
mob:film/2014 “The Shining” mob:director/8476
mob:film/2685 “The Clockwork Orange” mob:director/8476
Subject movie:actor name
mdb:actor “Jack Nicholson”
Advantages
Fewer joins
If the data is structured, we have a relational system – similar
to normalized relations
24ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-44-320.jpg)
![Property Tables
Grouping by entities; Jena [Wilkinson, 2006], DB2-RDF
[Bornea et al., 2013]
Clustered property table: group together the properties that
tend to occur in the same (or similar) subjects
Property-class table: cluster the subjects with the same type
of property into one property table
Subject Property Object
mdb:film/2014 rdfs:label “The Shining”
mdb:film/2014 movie:director mdb:director/8476
mdb:film/2685 movie:director mdb:director/8476
mdb:film/2685 rdfs:label “A Clockwork Orange”
mdb:actor/29704 movie:actor name “Jack Nicholson”
. . . . . . . . .
Subject refs:label movie:director
mob:film/2014 “The Shining” mob:director/8476
mob:film/2685 “The Clockwork Orange” mob:director/8476
Subject movie:actor name
mdb:actor “Jack Nicholson”
Advantages
Fewer joins
If the data is structured, we have a relational system – similar
to normalized relations
Disadvantages
Potentially a lot of NULLs
Clustering is not trivial
Multi-valued properties are complicated
24ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-45-320.jpg)
![Vertical Partitioning
Binary Tables [Abadi et al., 2007, 2009]:
Grouping by properties – for each property, build a two-column
table, containing both subject and object, ordered by subjects
n two column tables (n is the number of unique properties in
the data)
Subject Property Object
mdb:film/2014 rdfs:label “The Shining”
mdb:film/2014 movie:director mdb:director/8476
mdb:film/2685 movie:director mdb:director/8476
mdb:film/2685 rdfs:label “A Clockwork Orange”
mdb:actor/29704 movie:actor name “Jack Nicholson”
. . . . . . . . .
Subject Object
mdb:film/2014 mdb:director/8476
mdb:film/2685 mdb:director/8476
movie:director
Subject Object
mob:film/2014 “The Shining”
mob:film/2685 “The Clockwork Orange”
refs:label
Subject Object
mdb:actor/29704 “Jack Nicholson”
movie:actor name
25ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-46-320.jpg)
![Vertical Partitioning
Binary Tables [Abadi et al., 2007, 2009]:
Grouping by properties – for each property, build a two-column
table, containing both subject and object, ordered by subjects
n two column tables (n is the number of unique properties in
the data)
Advantages
Supports multi-valued properties
No NULLs
No clustering
Read only needed attributes (i.e. less I/O)
Good performance for subject-subject joins
25ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-47-320.jpg)
![Vertical Partitioning
Binary Tables [Abadi et al., 2007, 2009]:
Grouping by properties – for each property, build a two-column
table, containing both subject and object, ordered by subjects
n two column tables (n is the number of unique properties in
the data)
Advantages
Supports multi-valued properties
No NULLs
No clustering
Read only needed attributes (i.e. less I/O)
Good performance for subject-subject joins
Disadvantages
Not useful for subject-object joins
Expensive inserts
25ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-48-320.jpg)
![Vertical Partitioning
Binary Tables [Abadi et al., 2007, 2009]:
Grouping by properties – for each property, build a two-column
table, containing both subject and object, ordered by subjects
n two column tables (n is the number of unique properties in
the data)
TripleBit [Yuan et al., 2013]:
Create a table with |triple| columns, |objects| + |subjects| rows
with “1” if object/subject exists in triple; groups columns by
predicate
Compress columns (since they are sparse); partition by
predicate, then partition into chunks
(P,S,O) and (P,O,S) indexes on the chunks
25ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-49-320.jpg)
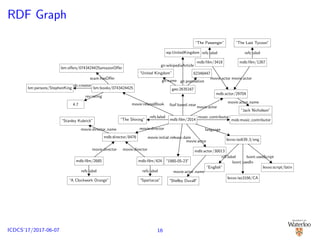
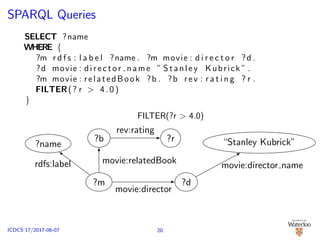
![Graph-based Approach [Zou and ¨Ozsu, 2017]
Answering SPARQL query ≡ subgraph matching using
homomorphism
gStore [Zou et al., 2011, 2014], chameleon-db [Alu¸c et al., 2013]
?m ?d
movie:director
?name
rdfs:label
?b
movie:relatedBook
“Stanley Kubrick”
movie:director name
?r
rev:rating
FILTER(?r > 4.0)
mdb:film/2014
“1980-05-23”
movie:initial release date
“The Shining”
refs:label
mob:music contributor
music contributor
lexvo:iso639 3/eng
language
bm:books/0743424425
4.7
rev:rating
bm:persons/StephenKing
dc:creator
bm:offers/0743424425amazonOffer
geo:2635167
“United Kingdom”
gn:name
62348447
gn:population
wp:UnitedKingdom
gn:wikipediaArticle
mdb:actor/29704
“Jack Nicholson”
movie:actor name
mdb:film/3418
“The Passenger”
refs:label
mdb:film/1267
“The Last Tycoon”
refs:label
mdb:director/8476
“Stanley Kubrick”
movie:director name
mdb:film/2685
“A Clockwork Orange”
refs:label
mdb:film/424
“Spartacus”
refs:label
mdb:actor/30013
“Shelley Duvall”
movie:actor name
“English”
rdf:label
lexvo:iso3166/CA
lvont:usedIn
lexvo:script/latin
lvont:usesScript
movie:relatedBook
scam:hasOffer
foaf:based near
movie:actor
movie:director
movie:actor
movie:actor movie:actor
movie:director movie:director
Subgraph
M
atching
26ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-50-320.jpg)
![Graph-based Approach [Zou and ¨Ozsu, 2017]
Answering SPARQL query ≡ subgraph matching using
homomorphism
gStore [Zou et al., 2011, 2014], chameleon-db [Alu¸c et al., 2013]
?m ?d
movie:director
?name
rdfs:label
?b
movie:relatedBook
“Stanley Kubrick”
movie:director name
?r
rev:rating
FILTER(?r > 4.0)
mdb:film/2014
“1980-05-23”
movie:initial release date
“The Shining”
refs:label
mob:music contributor
music contributor
lexvo:iso639 3/eng
language
bm:books/0743424425
4.7
rev:rating
bm:persons/StephenKing
dc:creator
bm:offers/0743424425amazonOffer
geo:2635167
“United Kingdom”
gn:name
62348447
gn:population
wp:UnitedKingdom
gn:wikipediaArticle
mdb:actor/29704
“Jack Nicholson”
movie:actor name
mdb:film/3418
“The Passenger”
refs:label
mdb:film/1267
“The Last Tycoon”
refs:label
mdb:director/8476
“Stanley Kubrick”
movie:director name
mdb:film/2685
“A Clockwork Orange”
refs:label
mdb:film/424
“Spartacus”
refs:label
mdb:actor/30013
“Shelley Duvall”
movie:actor name
“English”
rdf:label
lexvo:iso3166/CA
lvont:usedIn
lexvo:script/latin
lvont:usesScript
movie:relatedBook
scam:hasOffer
foaf:based near
movie:actor
movie:director
movie:actor
movie:actor movie:actor
movie:director movie:director
Subgraph
M
atching
Advantages
Maintains the graph structure
Full set of queries can be handled
26ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-51-320.jpg)
![Graph-based Approach [Zou and ¨Ozsu, 2017]
Answering SPARQL query ≡ subgraph matching using
homomorphism
gStore [Zou et al., 2011, 2014], chameleon-db [Alu¸c et al., 2013]
?m ?d
movie:director
?name
rdfs:label
?b
movie:relatedBook
“Stanley Kubrick”
movie:director name
?r
rev:rating
FILTER(?r > 4.0)
mdb:film/2014
“1980-05-23”
movie:initial release date
“The Shining”
refs:label
mob:music contributor
music contributor
lexvo:iso639 3/eng
language
bm:books/0743424425
4.7
rev:rating
bm:persons/StephenKing
dc:creator
bm:offers/0743424425amazonOffer
geo:2635167
“United Kingdom”
gn:name
62348447
gn:population
wp:UnitedKingdom
gn:wikipediaArticle
mdb:actor/29704
“Jack Nicholson”
movie:actor name
mdb:film/3418
“The Passenger”
refs:label
mdb:film/1267
“The Last Tycoon”
refs:label
mdb:director/8476
“Stanley Kubrick”
movie:director name
mdb:film/2685
“A Clockwork Orange”
refs:label
mdb:film/424
“Spartacus”
refs:label
mdb:actor/30013
“Shelley Duvall”
movie:actor name
“English”
rdf:label
lexvo:iso3166/CA
lvont:usedIn
lexvo:script/latin
lvont:usesScript
movie:relatedBook
scam:hasOffer
foaf:based near
movie:actor
movie:director
movie:actor
movie:actor movie:actor
movie:director movie:director
Subgraph
M
atching
Advantages
Maintains the graph structure
Full set of queries can be handled
Disadvantages
Graph pattern matching is expensive
26ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-52-320.jpg)
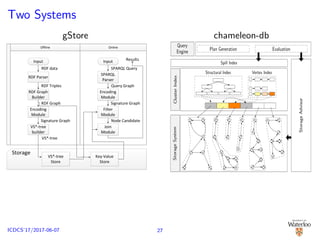
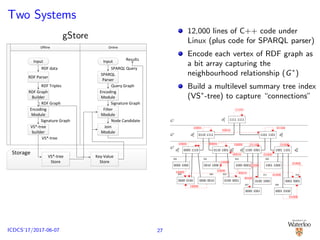
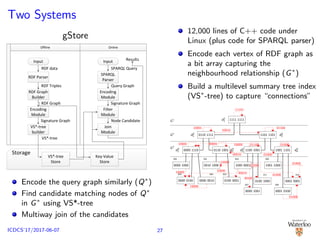
![Two Systems
35,000 lines of C++ code under Linux
(plus code for SPARQL 1.0 parser)
Adaptivity to workload due to
variability of Web workloads and the
variability of composition of SPARQL
triple patterns
An experiment [Alu¸c et al., 2014a]
No single system is a sole winner
across all queries
No single system is the sole loser
across all queries, either
2–5 orders of magnitude difference
in the performance between the
best and the worst system for a
given query
The winner in one query may
timeout in another
Performance difference widens as
dataset size increases
Group-by-query approach [Alu¸c et al.,
2014b]
chameleon-db
Structural Index
...
Vertex Index
Spill Index
ClusterIndexStorageSystem
StorageAdvisor
Query
Engine Plan Generation Evaluation
27ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-56-320.jpg)
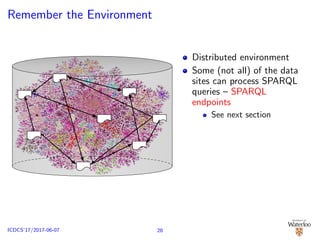
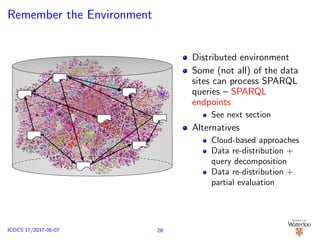
![Cloud-based Solutions [Kaoudi and Manolescu, 2015]
RDF data warehouse D is partitioned ({D1, . . . , Dn}) and
placed on cloud platforms (such as HDFS, HBase)
29ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-59-320.jpg)
![Cloud-based Solutions [Kaoudi and Manolescu, 2015]
RDF data warehouse D is partitioned ({D1, . . . , Dn}) and
placed on cloud platforms (such as HDFS, HBase)
SPARQL query is run through MapReduce jobs
Data parallel execution
29ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-60-320.jpg)
![Cloud-based Solutions [Kaoudi and Manolescu, 2015]
RDF data warehouse D is partitioned ({D1, . . . , Dn}) and
placed on cloud platforms (such as HDFS, HBase)
SPARQL query is run through MapReduce jobs
Data parallel execution
Examples: HARD [Rohloff and Schantz, 2010] , HadoopRDF
[Husain et al., 2011] , EAGRE [Zhang et al., 2013] and
JenaHBase [Khadilkar et al., 2012]
29ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-61-320.jpg)
![Cloud-based Solutions [Kaoudi and Manolescu, 2015]
RDF data warehouse D is partitioned ({D1, . . . , Dn}) and
placed on cloud platforms (such as HDFS, HBase)
SPARQL query is run through MapReduce jobs
Data parallel execution
Examples: HARD [Rohloff and Schantz, 2010] , HadoopRDF
[Husain et al., 2011] , EAGRE [Zhang et al., 2013] and
JenaHBase [Khadilkar et al., 2012]
High scalability and fault-tolerance
Possibly low performance since MapReduce is not suitable for
graph processing
29ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-62-320.jpg)

![Partition-based Approaches
(Offline) Partition an RDF data warehouse (graph) into
several fragments that are distributed to sites
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
Partitioning alternatives
Table-based (e.g., [Husain et al., 2011])
Graph-based (e.g., [Huang et al., 2011; Zhang et al., 2013])
Unit-based (e.g., [Gurajada et al., 2014; Lee and Liu, 2013])
30ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-64-320.jpg)
![Partition-based Approaches
(Offline) Partition an RDF data warehouse (graph) into
several fragments that are distributed to sites
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
Partitioning alternatives
Table-based (e.g., [Husain et al., 2011])
Graph-based (e.g., [Huang et al., 2011; Zhang et al., 2013])
Unit-based (e.g., [Gurajada et al., 2014; Lee and Liu, 2013])
(Online) SPARQL query decomposed Q = {Q1, . . . , Qk} ⇒
query graph is decomposed
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
30ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-65-320.jpg)
![Partition-based Approaches
(Offline) Partition an RDF data warehouse (graph) into
several fragments that are distributed to sites
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
Partitioning alternatives
Table-based (e.g., [Husain et al., 2011])
Graph-based (e.g., [Huang et al., 2011; Zhang et al., 2013])
Unit-based (e.g., [Gurajada et al., 2014; Lee and Liu, 2013])
(Online) SPARQL query decomposed Q = {Q1, . . . , Qk} ⇒
query graph is decomposed
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
Examples: GraphPartition [Huang et al., 2011], WARP [Hose
and Schenkel, 2013] , Partout [Galarraga et al., 2014] ,
Vertex-block [Lee and Liu, 2013]
30ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-66-320.jpg)
![Partition-based Approaches
(Offline) Partition an RDF data warehouse (graph) into
several fragments that are distributed to sites
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
Partitioning alternatives
Table-based (e.g., [Husain et al., 2011])
Graph-based (e.g., [Huang et al., 2011; Zhang et al., 2013])
Unit-based (e.g., [Gurajada et al., 2014; Lee and Liu, 2013])
(Online) SPARQL query decomposed Q = {Q1, . . . , Qk} ⇒
query graph is decomposed
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
Examples: GraphPartition [Huang et al., 2011], WARP [Hose
and Schenkel, 2013] , Partout [Galarraga et al., 2014] ,
Vertex-block [Lee and Liu, 2013]
High performance
Great for parallelizing centralized RDF data
May not be possible to re-partition and re-allocate Web data
(i.e., LOD)
Each approach requires a specific partitioning strategy – no
generic partitioning
Query decomposition may not be easy
30ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-67-320.jpg)
![Partial Query Evaluation (PQE)
RDF data warehouse is partitioned and distributed as before
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
SPARQL query is not decomposed
Partial query evaluation – Distributed gStore [Peng et al., 2016]
31ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-68-320.jpg)
![Partial Query Evaluation (PQE)
RDF data warehouse is partitioned and distributed as before
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
SPARQL query is not decomposed
Partial query evaluation – Distributed gStore [Peng et al., 2016]
f (x) ⇒ f (s, d) ⇒ f (f (s), d)) ⇒ Final Answerf (s, d)
known inputs unknown inputs
31ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-69-320.jpg)
![Partial Query Evaluation (PQE)
RDF data warehouse is partitioned and distributed as before
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
SPARQL query is not decomposed
Partial query evaluation – Distributed gStore [Peng et al., 2016]
f (x) ⇒ f (s, d) ⇒ f (f (s), d)) ⇒ Final Answerf (s, d)
known inputs unknown inputs
f (f (s), d))
partial results
31ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-70-320.jpg)
![Partial Query Evaluation (PQE)
RDF data warehouse is partitioned and distributed as before
RDF data D = {D1, . . . , Dn}
Allocate each Di to a site
SPARQL query is not decomposed
Partial query evaluation – Distributed gStore [Peng et al., 2016]
f (x) ⇒ f (s, d) ⇒ f (f (s), d)) ⇒ Final Answerf (s, d)
known inputs unknown inputs
f (f (s), d))
partial results
Query is the function and each Di is the known input
31ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-71-320.jpg)
![Distributed SPARQL Using PQE [Peng et al., 2016]
Two steps:
1. Evaluate a query at each site to find local matches
These are local partial matches
D1
D2
D3
D4
32ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-72-320.jpg)
![Distributed SPARQL Using PQE [Peng et al., 2016]
Two steps:
1. Evaluate a query at each site to find local matches
These are local partial matches
2. Assemble the partial matches to get final result
Crossing match
Centralized assembly
Distributed assembly
D1
D2
D3
D4
Crossing match
32ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-73-320.jpg)
![Distributed SPARQL Using PQE [Peng et al., 2016]
Two steps:
1. Evaluate a query at each site to find local matches
These are local partial matches
2. Assemble the partial matches to get final result
Crossing match
Centralized assembly
Distributed assembly
D1
D2
D3
D4
Crossing match
High performance due to parallelization
Do not have to deal with query decomposition
May not be possible to re-partition and re-allocate Web data
(i.e., LOD)
RDF storage sites need to be modified to handle partial query
processing
32ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-74-320.jpg)
![Outline
1 RDF Technology [¨Ozsu, 2016]
Data Warehousing Approach
Distributed RDF Processing
2 Federated RDF Systems
SPARQL Endpoint Federation
General RDF Federation
3 LOD – Live Querying Approach [Hartig, 2013a]
Traversal-based approaches
Index-based approaches
Hybrid approaches
4 Conclusions
33ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-75-320.jpg)
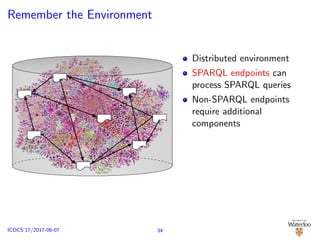
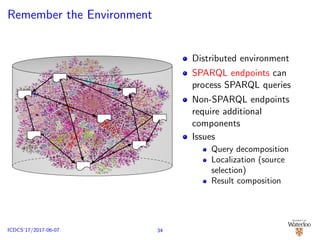
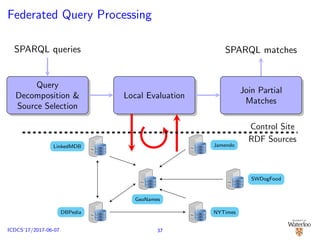
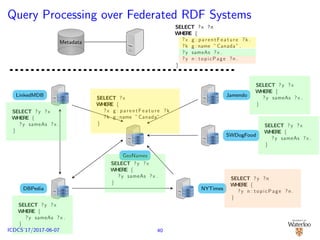
![SPARQL Endpoint Federation
No data re-partitioning/re-distribution
Consider D = D1 ∪ D2 ∪ . . . ∪ Dn; Di : SPARQL endpoint
SPARQL query decomposed Q = {Q1, . . . , Qk}
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
E.g.: SPLENDID [G¨orlitz and Staab, 2011], ANAPSID
[Acosta et al., 2011]
Jamendo
SWDogFood
GeoNames
LinkedMDB
DBPedia NYTimes
RDF Sources
35ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-78-320.jpg)
![SPARQL Endpoint Federation
No data re-partitioning/re-distribution
Consider D = D1 ∪ D2 ∪ . . . ∪ Dn; Di : SPARQL endpoint
SPARQL query decomposed Q = {Q1, . . . , Qk}
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
E.g.: SPLENDID [G¨orlitz and Staab, 2011], ANAPSID
[Acosta et al., 2011]
Jamendo
SWDogFood
GeoNames
LinkedMDB
DBPedia NYTimes
RDF Sources
Control Site
Metadata
35ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-79-320.jpg)
![SPARQL Endpoint Federation
No data re-partitioning/re-distribution
Consider D = D1 ∪ D2 ∪ . . . ∪ Dn; Di : SPARQL endpoint
SPARQL query decomposed Q = {Q1, . . . , Qk}
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
E.g.: SPLENDID [G¨orlitz and Staab, 2011], ANAPSID
[Acosta et al., 2011]
Jamendo
SWDogFood
GeoNames
LinkedMDB
DBPedia NYTimes
RDF Sources
Control Site
Metadata
Data included at the source
Supported access patterns
Statistical information
· · ·
35ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-80-320.jpg)
![SPARQL Endpoint Federation
No data re-partitioning/re-distribution
Consider D = D1 ∪ D2 ∪ . . . ∪ Dn; Di : SPARQL endpoint
SPARQL query decomposed Q = {Q1, . . . , Qk}
Distributed execution of {Q1, . . . , Qk} over {D1, . . . , Dn}
E.g.: SPLENDID [G¨orlitz and Staab, 2011], ANAPSID
[Acosta et al., 2011]
Jamendo
SWDogFood
GeoNames
LinkedMDB
DBPedia NYTimes
RDF Sources
Control Site
Metadata
Data integration approach
May be the only way to proceed if RDF data is already
distributed with autonomous owners
Not all RDF data storage points are SPARQL endpoints
35ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-81-320.jpg)
![Not All RDF Storage Sites are SPARQL Endpoints
Use the mediator-wrapper paradigm
Wrappers provide SPARQL endpoint functionality
Mediators may be introduced if wrappers are thin
E.g.: DARQ [Quilitz and Leser, 2008], FedX [Schwarte et al.,
2011b]
Jamendo
SWDogFood
GeoNames
LinkedMDB
DBPedia NYTimes
RDF Storage
A
Wrapper
Wrapper
Mediator
RDF Storage
B
RDF Sources
Control Site
Metadata
36ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-82-320.jpg)



![Data Localization
Metadata-based approaches
Use the information in the metadata repository to determine
which sources are relevant
DARQ [Quilitz and Leser, 2008]
QTree [Harth et al., 2010; Prasser et al., 2012]
HiBISCus [Saleem and Ngomo, 2014]
. . .
ASK query-based approach
Asking whether or not a triple pattern has an answer at a
source
FedX [Schwarte et al., 2011a,b]
39ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-87-320.jpg)

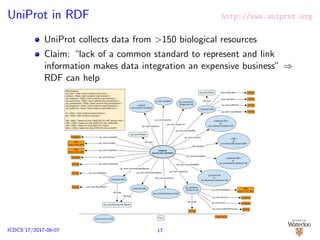
![Federated Access to UniProt Collection
Get the Reactome pathways where Q16850 is associated, then get all the
other proteins in that pathway and pull out their expression from the atlas,
along with the GO annotations from UniProt
PREFIX r d f : <http ://www. w3 . org /1999/02/22− rdf −syntax−ns#>
PREFIX r d f s : <http ://www. w3 . org /2000/01/ rdf −schema#>
PREFIX biopax3 : <http ://www. biopax . org / r e l e a s e / biopax−l e v e l 3 . owl#>
PREFIX a t l a s t e r m s : <http :// r d f . ebi . ac . uk/ terms / a t l a s />
PREFIX upc:< http :// p u r l . u n i p r o t . org / core/>
SELECT DISTINCT ?pathwayname ? e x p r e s s i o n V a l u e ? g o l a b e l
WHERE {
# Get the pathways that r e f e r e n c e Q16850
? pathway r d f : type biopax3 : Pathway .
? pathway biopax3 : displayName ?pathwayname .
? pathway biopax3 : pathwayComponent
[? r e l [ biopax3 : e n t i t y R e f e r e n c e ? dbXref ] ] .
? pathway biopax3 : pathwayComponent
[? r e l [ biopax3 : e n t i t y R e f e r e n c e <http :// p u r l . u n i p r o t . org / u n i p r o t /Q16850 >]] .
# Get the e x p r e s s i o n f o r those p r o t e i n s
SERVICE <http ://www. e bi . ac . uk/ r d f / s e r v i c e s / a t l a s / sparql > {
? value r d f s : l a b e l ? e x p r e s s i o n V a l u e .
? value a t l a s t e r m s : pValue ? pvalue .
? value a t l a s t e r m s : isMeasurementOf ? probe .
? probe a t l a s t e r m s : dbXref ? dbXref .
}
# get the GO f u n c t i o n s from Uniprot
SERVICE <http :// u n i p r o t . org / sparql > {
? dbXref a upc : Protein ;
upc : c l a s s i f i e d W i t h ? keyword .
? keyword r d f s : seeAlso ? goid .
? goid r d f s : l a b e l ? g o l a b e l .
}
}
42ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-90-320.jpg)
![Outline
1 RDF Technology [¨Ozsu, 2016]
Data Warehousing Approach
Distributed RDF Processing
2 Federated RDF Systems
SPARQL Endpoint Federation
General RDF Federation
3 LOD – Live Querying Approach [Hartig, 2013a]
Traversal-based approaches
Index-based approaches
Hybrid approaches
4 Conclusions
43ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-91-320.jpg)
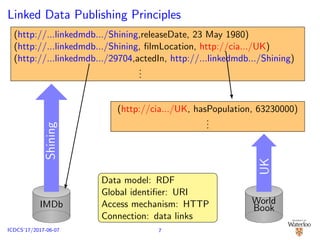
![Linked Data Model [Hartig, 2012]
Web of Linked Data
Given a finite or countably infinite set D of Linked Documents, a
Web of Linked Data is a tuple W = (D, adoc, data) where:
D ⊆ D,
adoc is a partial mapping from URIs to D, and
data is a total mapping from D to finite sets of RDF triples.
45ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-93-320.jpg)
![Linked Data Model [Hartig, 2012]
Web of Linked Data
Given a finite or countably infinite set D of Linked Documents, a
Web of Linked Data is a tuple W = (D, adoc, data) where:
D ⊆ D,
adoc is a partial mapping from URIs to D, and
data is a total mapping from D to finite sets of RDF triples.
Data Links
A Web of Linked Data W = (D, adoc, data)
contains a data link from document d ∈ D to
document d ∈ D if there exists a URI u such
that:
u is mentioned in an RDF triple
t ∈ data(d), and
d = adoc(u).
45ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-94-320.jpg)

![Traversal Approaches
Discover relevant URIs recursively
by traversing (specific) data links
at query execution runtime [Hartig,
2013b; Ladwig and Tran, 2011]
Implements reachability-based
query semantics
Start from a set of seed URIs
Recursively follow and discover
new URIs
Important issue is selection of seed
URIs
Retrieved data serves to discover
new URIs and to construct result
47ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-97-320.jpg)
![Traversal Approaches
Discover relevant URIs recursively
by traversing (specific) data links
at query execution runtime [Hartig,
2013b; Ladwig and Tran, 2011]
Implements reachability-based
query semantics
Start from a set of seed URIs
Recursively follow and discover
new URIs
Important issue is selection of seed
URIs
Retrieved data serves to discover
new URIs and to construct result
Advantages
Easy to implement.
No data structure to maintain.
47ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-98-320.jpg)
![Traversal Approaches
Discover relevant URIs recursively
by traversing (specific) data links
at query execution runtime [Hartig,
2013b; Ladwig and Tran, 2011]
Implements reachability-based
query semantics
Start from a set of seed URIs
Recursively follow and discover
new URIs
Important issue is selection of seed
URIs
Retrieved data serves to discover
new URIs and to construct result
Advantages
Easy to implement.
No data structure to maintain.
Disadvantages
Possibilities for parallelized data retrieval are limited
Repeated data retrieval introduces significant query latency.
47ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-99-320.jpg)
![Index Approaches
Use pre-populated index to determine relevant URIs (and to
avoid as many irrelevant ones as possible)
Different index keys possible; e.g., triple patterns [Umbrich
et al., 2011]
Index entries a set of URIs
Indexed URIs may appear multiple times (i.e., associated with
multiple index keys)
Each URI in such an entry may be paired with a cardinality
(utilized for source ranking)
Key: tp Entry: {uri1, uri2, , urin}
GET urii
48ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-100-320.jpg)
![Index Approaches
Use pre-populated index to determine relevant URIs (and to
avoid as many irrelevant ones as possible)
Different index keys possible; e.g., triple patterns [Umbrich
et al., 2011]
Index entries a set of URIs
Indexed URIs may appear multiple times (i.e., associated with
multiple index keys)
Each URI in such an entry may be paired with a cardinality
(utilized for source ranking)
Key: tp Entry: {uri1, uri2, , urin}
GET urii
Advantages
Data retrieval can be fully parallelized
Reduces the impact of data retrieval on query execution time
48ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-101-320.jpg)
![Index Approaches
Use pre-populated index to determine relevant URIs (and to
avoid as many irrelevant ones as possible)
Different index keys possible; e.g., triple patterns [Umbrich
et al., 2011]
Index entries a set of URIs
Indexed URIs may appear multiple times (i.e., associated with
multiple index keys)
Each URI in such an entry may be paired with a cardinality
(utilized for source ranking)
Key: tp Entry: {uri1, uri2, , urin}
GET urii
Advantages
Data retrieval can be fully parallelized
Reduces the impact of data retrieval on query execution time
Disadvantages
Querying can only start after index construction
Depends on what has been selected for the index
Freshness may be an issue
Index maintenance
48ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-102-320.jpg)
![Hybrid Approach
Perform a traversal-based execution using a prioritized list of
URIs to look up [Ladwig and Tran, 2010]
Initial seed from the pre-populated index
Non-seed URIs are ranked by a function based on information
in the index
New discovered URIs that are not in the index are ranked
according to number of referring documents
49ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-103-320.jpg)
![Outline
1 RDF Technology [¨Ozsu, 2016]
Data Warehousing Approach
Distributed RDF Processing
2 Federated RDF Systems
SPARQL Endpoint Federation
General RDF Federation
3 LOD – Live Querying Approach [Hartig, 2013a]
Traversal-based approaches
Index-based approaches
Hybrid approaches
4 Conclusions
50ICDCS’17/2017-06-07](https://image.slidesharecdn.com/web-new-shortest-170605113810/85/Web-Data-Management-in-the-RDF-Age-104-320.jpg)












This document summarizes recent approaches to web data management including Fusion Tables, XML, and Linked Open Data (LOD). It discusses properties of web data like lack of schema, volatility, and scale. LOD uses RDF, global identifiers (URIs), and data links to query and integrate data from multiple sources while maintaining source autonomy. The LOD cloud has grown rapidly, currently consisting of over 3000 datasets with more than 84 billion triples.




















































