
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Way to kafka connect
Similar to Way to kafka connect (20)
Recently uploaded
Recently uploaded (20)
Way to kafka connect
- 2. what is kafka 2 coolmeen, grinfeld
- 3. what is kafka 3 coolmeen, grinfeld
- 6. Async communication messaging bus 6 coolmeen, grinfeld
- 7. Async communication messaging bus 7 coolmeen, grinfeld
- 8. Async communication messaging bus 8 coolmeen, grinfeld
- 9. Near real time Data Extraction and Transformation (ETL) platform: 9 coolmeen, grinfeld
- 10. Near real time multi source event aggregation 10 coolmeen, grinfeld
- 11. My Data is in Kafka, now what? 11 coolmeen, grinfeld
- 12. Kafka eco-system: 1. Kafka Simple ProducerConsumer 2. Kafka Streams 3. KSQL What about data that is not in Kafka? 12 coolmeen, grinfeld
- 13. delete everything and use oracle hand made by © coolmeen 13 coolmeen, grinfeld
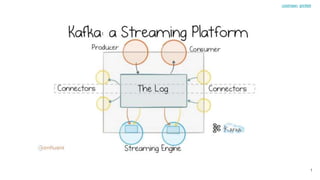
- 14. Kafka Connect to the Rescue Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka. https://www.confluent.io/hub/ 14 coolmeen, grinfeld
- 15. Let’s look for example from our system 15 coolmeen, grinfeld
- 16. What do we have now? Keeper Users Web DBROUTER W A N Kafka Getting user data from Charlie 16 coolmeen, grinfeld
- 17. What problems do we have? 1. Synchronous request from keeper to charlie over the WAN 2. Synchronous request between Web and DB services 3. Synchronous request between DB service and Oracle DB 4. and response back LATENCY 1. Multiple requests from Keeper can slow (or kill) Charlie DB (Oracle) 2. Slowness in Charlie DB could cause slowness or failures in Keeper, it will cause retries with Quartz which will go to Charlie Oracle and so onMUTUAL DEPENDENCY 17 coolmeen, grinfeld
- 18. Let’s try to solve this Keeper Users Web DBROUTER W A N Kafka Cache with TTL 18 coolmeen, grinfeld
- 19. Let’s try to solve this Keeper Users Web DBROUTER W A N Kafka Cache Scheduler 19 coolmeen, grinfeld
- 20. What did we solve? Mutual Dependency - now only “Scheduler” depends on Charlie and it runs once per X time. It could be adjusted to affect less on charlie. What problems we still have and maybe have added the new ones? Staleness - now data should be outdated for some (long) period of time (even when everything is playing well). We can shorten un-updated period by making “Scheduler” to execute more frequently, but it will take us back to “Mutual Dependency” problem. Mutual Dependency - now we should take all users and their plans from DB every time scheduler makes requests to charlie and it could take much more time, we need to manage retries and so on. We depend on our Web Services Latency - now router sends its requests inside Tlx without interacting directly with Charlie (Savis) Solved Partially Solved 20 coolmeen, grinfeld
- 21. Let’s try to solve this Keeper Users DB ROUTER W A N Kafka Cache 1 ForKeeper 2 Cache Updater 21 coolmeen, grinfeld
- 22. Let’s try to solve this Keeper Users DB ROUTER W A N Kafka Cache 1 ForKeeper 2 Cache Updater Controller Cache Cache Updater 22 coolmeen, grinfeld
- 23. Let’s try to solve this Keeper Users DB ROUTER W A N Kafka Cache 1 ForKeeper 2 Kafka 3 Cache Updater Cache Updater Controller 23 coolmeen, grinfeld
- 24. What did we solved? Mutual Dependency - now only “Scheduler” depends on Charlie and it runs once per X time. It could be adjusted to influence less on charlie. What problems we still have and maybe have added the new ones? Staleness - now data should be outdated for some (long) period of time (even when everything is playing well). We can shorten un-updated period by making “Scheduler” to execute more frequently, but it will take us back to “Mutual Dependency” problem. Inverse Dependency - Charlie knows keeper, despite of fact that keeper depends on charlie and NOT the opposite direction (and it’s bad) Latency - now router sends its requests inside Tlx without interacting directly with Charlie (Savis) Solved Partially Solved Solved Data loss if Charlie services (DB or Web) is down or adding latency to Charlie (if we wait for commit until data is sent to keeper) 24 coolmeen, grinfeld
- 25. Let’s try to solve this Keeper Users DB ROUTER W A N Kafka Cache CDC (Kafka Connect) Cache Updater Single source of truth Oracle append log DB 25 coolmeen, grinfeld
- 26. Users DB ROUTERKafka Cache Cache Updater Single source of truth Oracle append log Keeper W A N CDC (Kafka Connect) Let’s try to solve this 26 coolmeen, grinfeld DB
- 27. { "schema": { "type": "struct", "fields": [ { "type": "struct", "fields": [ { "type": "int32", "optional": false, "field": "ID" }, { "type": "string", "optional": false, "field": "FIRST_NAME" }, { "type": "string", "optional": false, "field": "LAST_NAME" }, { "type": "string", "optional": true, "field": "COMPANY" } ], "optional": true, "name": "server1.DEBEZIUM.USERS.Value", "field": "before" } Short example from Debezium 27 coolmeen, grinfeld
- 28. { "type": "struct", "fields": [ { "type": "int32", "optional": false, "field": "ID" }, { "type": "string", "optional": false, "field": "FIRST_NAME" }, { "type": "string", "optional": false, "field": "LAST_NAME" }, { "type": "string", "optional": true, "field": "COMPANY" } ], "optional": true, "name": "server1.DEBEZIUM.USERS.Value", "field": "after" } Short example from Debezium 28 coolmeen, grinfeld
- 29. { "type": "struct", "fields": [ { "type": "string", "optional": true, "field": "version" }, { "type": "string", "optional": false, "field": "name" }, { "type": "int64", "optional": true, "field": "ts_ms" }, { "type": "string", "optional": true, "field": "txId" }, { "type": "int64", "optional": true, "field": "scn" }, { "type": "boolean", "optional": true, "field": "snapshot" } ], "optional": false, "name": "io.debezium.connector.oracle.Source", "field": "source" } Short example from Debezium 29 coolmeen, grinfeld
- 30. { "type": "string", "optional": false, "field": "op" }, { "type": "int64", "optional": true, "field": "ts_ms" } ], "optional": false, "name": "server1.DEBEZIUM.USERS.Envelope" }, "payload": { "before": null, "after": { "ID": 1004, "FIRST_NAME": "Ilya", "LAST_NAME": "Morgenshtern", "COMPANY": "TeleMessage" }, "source": { "version": "0.9.0.Alpha1", "name": "server1", "ts_ms": 1520085154000, "txId": "6.28.807", "scn": 2122185, "snapshot": false }, "op": "c", "ts_ms": 1532592105975 } } Short example from Debezium 30 coolmeen, grinfeld
- 31. Users Devices Products Cache What next? 31 coolmeen, grinfeld
- 33. Resources Apache Kafka use cases from Apache Kafka site Kafka Connect Confluent Hub Kafka Connect Confluent Docs Blog: The Simplest Useful Kafka Connect Data Pipeline In The World Tutorial for Debezium Devoxx: Data Streaming for Microservices using Debezium ETL Is Dead, Long Live Streams: real-time streams w/ Apache Kafka #ApacheKafkaTLV hosting Gwen Shapira 33 coolmeen, grinfeld
Editor's Notes
- From sync REST Communication to async communication messaging bus (scalable, fault tolerant, persistent). Kafka is scalable, fault tolerant, persistent
- From sync REST Communication to async communication messaging bus (scalable, fault tolerant, persistent). Kafka is scalable, fault tolerant, persistent
- From sync REST Communication to async communication messaging bus (scalable, fault tolerant, persistent). Kafka is scalable, fault tolerant, persistent
- From batch schedulers jobs to real time event processing
- This is our current system overview. We have Keeper which depends on Charlie. They are located in 2 different zones (cities, states) and networking between them goes through the WAN (Internet). Actually, we have Web on Tlx, but it calls DB service on Savis in any case, so it’s quite same situation
- long RTT between to geo zones (aka, latency) Increase number of possible failures (we should manage retries, recovery and so on) tight coupling 2 systems and this is error prone (affect each other - pauses, down time and so on) What is correct term for “mutual influence” when we 2 system can hurt each other (Mutual dependency or something similar)?
- So let’s add cache So let’s add cache with TTL (redis for example) and when no data in cache - let’s go to charlie
- But now we need to update this cache, so we need some service to maintain the cache: according to some pre-defined frequency, it requests users and their plans and update cache We can try to implement some type of receiving only changes by time or some data, but we can’t recognize deletes
- Let’s assume we solved latency Mutual influence (dependency) - solved partially, since we can continue to work if charlie is down, but data could be not updated (by the way - seems it’s ok for our use cases) we added staleness and if we want to decrease the staleness effect by increasing pulling frequency - trade off with going back to “mutual influence” when both systems affect each other
- Every time we update user or/and his plan, we can add async (or sync) action to, for example, Partner service and it will send some update directly to Kafka Let’s say it’s type of pub/sub managed by our code Another problem is our services: they are not persistent, so if DB or Partner is down - we lose data If DB synchronous sends requests to keeper before commit, we increase latency on Charlie’s transactions - meaning keeper affect charlie Another Problem: Charlie knows inner keeper structure, adding Kafka dependencies to trunk and so on
- By adding end-point on keeper - we remove charlie knowledge about keeper inner structure, but still Charlie knows about keeper, despite of fact it shouldn’t
- Still, we need to wait for commit in DB until we put data in Kafka (or we’ll lost data when DB restarted/crashed)
- We flipped dependency between 2 systems. Actually, keeper depends on charlie, but implementation is in opposite way. We prefer not to do it, since it means that Charlie knows keeper (even if we reduced coupling by introducing, hopefully, well defined endpoint to get data into keeper We need to add (in any case and for any solution) some integration tests to verify that changes in charlie doesn’t affect keeper
- CDC - capture data changes (e.g. Kafka Connect) (we currently using CDC for replicating main Oracle DB to our DR by using Oracle GoldenGate replication solution) Data log - first it was used for recovering from crash without losing data Now, let’s look into our system more precisely. Actually, we have 3 different system: the 1st is charlie, the 2nd is keeper and 3rd (actually the 1st one) is Oracle DB. Oracle DB is our “single source of truth”. It knows nothing about other system elements and depends on nothing. Other elements of TeleMessage depend on it. For example, Oracle doesn’t know what Charlie does, and Charlie accesses Oracle to get data from it. Keeper, actually, doesn’t depend on Charlie - it depends on Oracle DB, so nor charlie neither keeper should know each other and interact with each other
- Despite of being part of Keeper system, Kafka connect is “invisible” element, so without extra attention we could “hurt” keeper. A lot of people like to call this “transparency” (Ilya calls this “magic”). When your system has “transparency” it’s very easy to forget about this element and could be difficult to maintain. This situation is bug-prone, so it should be documented good and find the way to test it to avoid bugs.