Download to read offline












![Wolfgang Wiese Web-Technologies I 17
Robots and SpidersRobots and Spiders 22
Simple example in Perl:
#!/local/bin/perl
use LWP::UserAgent; use HTML::LinkExtor; use URI::URL;
$ua = LWP::UserAgent->new;
$p = HTML::LinkExtor->new(&callback);
$url = $ARGV[0];
if (not $url) { die("Usage: $0 [URL]n"); }
push(@linkliste,"usert$url");
while(($thiscount < 10) && (@linkliste)) {
$thiscount++;
($origin,$url) = split(/t/,pop(@linkliste),2);
@links = ();
$res = $ua->request(HTTP::Request->new(GET => $url),
sub {$p->parse($_[0])});
my $base = $res->base;
@links = map { $_ = url($_, $base)->abs; } @links;
$title = $res->title;
for ($i=0; $i<=$#links; $i++) { push(@linkliste,"$titlet$links[$i]");}
}
print join("n", @linkliste), "n"; exit;
sub callback { my($tag, %attr) = @_; return if $tag ne 'a'; push(@links, values %attr); }](https://image.slidesharecdn.com/webtechnologies-03-160702155342/85/Vorlesung-Web-Technologies-17-320.jpg)


















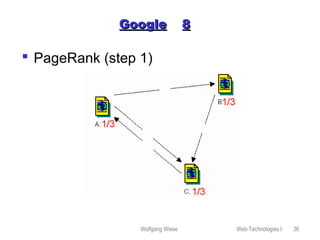
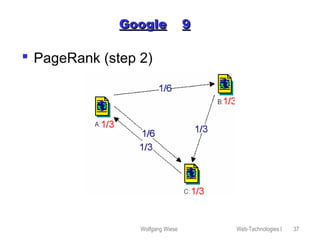
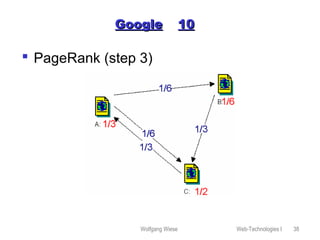









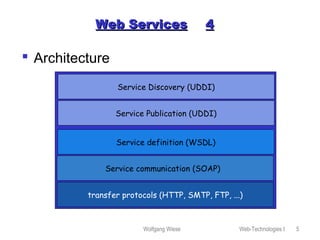
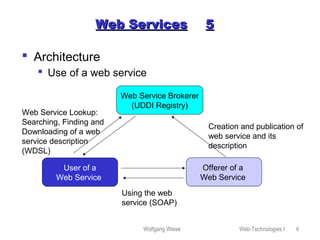
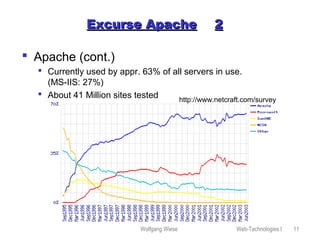
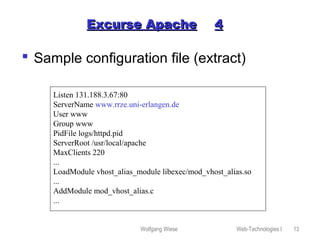
This document provides an overview of web technologies and related topics, including: - Chapters on client-side programming, server-side programming, web content management, web services, the Apache web server, robots, spiders, and search engines. - A definition of web services as software components that communicate via XML messages over defined interfaces. Key technologies involved are UDDI, WSDL, and SOAP. - An explanation of how the Apache web server works, including its configuration, virtual hosting, and security measures. - Descriptions of how robots and spiders crawl and index web pages by following links, and how the robots exclusion standard works. - An overview of different types of search

















































































