What is Intelligence
Accordingto Websters Dictionary:
Intelligence is the capacity to learn and solve problems in particular intelligence is
related with:
• the ability to solve novel problems (new)
• the ability to act rationally (logically)
• the ability to act like humans
According to Oxford dictionary:
Intelligence is the ability to learn, understand and think
Intelligence is the ability to learn, to deal with different situations, to acquire,
understand and apply knowledge and to analyze and reason.
Intelligence relates to tasks involving higher mental
processes.
Examples: Creativity, Solving problems, Pattern recognition, Classification,
Learning, Induction, Deduction, Building analogies, Optimization, Language
processing, Knowledge and many more
4.
What’s Involved inIntelligence?
• Ability to interact with the real world
– to perceive, understand, and act
– e.g., speech recognition and understanding and synthesis
– e.g., image understanding
– e.g., ability to take actions, have an effect
• Reasoning and Planning
– Solving new problems, planning, and making decisions
– Ability to deal with unexpected problems, uncertainties
• Learning and Adaptation
– learn from changing environment and adapt them self
5.
What is IntelligentSystem
Intelligent system have the capacity to acquire
and apply knowledge in an intelligent manner
and have the capability of
- Perception (acquiring knowledge through surrounding or situation)
- Reasoning
- Learning (changing environment)
- Making Inferencing or decision from
incomplete information
6.
Cognitive Science
• Cognitiverefers to the mental action or process of acquiring
knowledge and understanding through thought, experience,
and the senses
• Cognitive Science is the interdisciplinary, scientific study of
the mind and its processes.
• Aims to develop, explore and evaluate theories of how the
mind works through the use of computational models.
• Example: Learning is an example of cognition. The way our
brain makes connection as we learn concepts in different ways
to remember what we have learned.
• Our ability to reason through logic is a prime example of
cognition. People do have different ways of reasoning if we
think about why people buy certain things when they shop.
7.
Artificial Intelligence
• Theterm Artificial Intelligence was coined by McCarthy in 1956.
• According to John McCarthy(1956), Artificial Intelligence is “The science
and engineering of making intelligent machines, especially intelligent
computer programs”.
• AI is the study of how to make computers do things at which, at the moment,
people are better. [Rich & Knight]
• AI is the art of making computers or machine do smart things.
[Waldrop]
• AI is the activity of providing such machines as computers with the ability to
display behavior that would be regarded as intelligent if it were observed in
humans. [R. McLoed]
• A field that focuses on developing techniques to enable computer systems to
perform activities that are considered intelligent (in humans and other
animals). [Dyer]
8.
Artificial Intelligence
• AIis the study of the combinations that make it possible to
perceive, reason and act. [Winston]
• Computational Intelligence is the study of the design of
intelligent agents. [Poole]
• Artificial Intelligence is the study and design of intelligent
agents, where an intelligent agent is a system that perceives its
environment and takes actions that maximize its chance of
success.
Artificial Intelligence is the branch of engineering employed for
the creation of computers that possess some form of intelligence
and can be used to solve real world problems and functions within
a domain
9.
Artificial Intelligence
• Allthe definitions of AI focus on the following :
1. Systems that think like humans
2. Systems that think rationally
3. Systems that act like humans
4. Systems that act rationally
• Traditionally, all four goals have been followed and the
approaches were:
10.
•Systems that thinklike humans
-How our mind works, most of the time it is a black box where
we
are not clear about our thought process.
- Neural network is a computing model for processing
information similar to brain.
•Systems that act like humans
-The overall behaviorof the system should be
human like. It could be achieved by observation.
•Systems that think rationally
- systems rely on logic rather than human to measure
correctness.
-For thinking rationally or logically, logic formulas and
theories are used for synthesizing outcomes.
•Systems that act rationally
-Rational behavior means doing right thing.
-Goal is to develop systems that are
rational and sufficient
11.
11
General AI Goals
•Replicate human intelligence
• Solve knowledge intensive tasks
• Make an intelligent connection between perception and action
• Enhance human-human, human-computer and computer
to computer interaction/communication
Engineering based AI Goal
• Develop concepts, theory and practice of building intelligent
machines.
• Emphasis is on system building.
Science based AI Goal
• Develop concepts, mechanisms and vocabulary to understand
biological intelligent behavior.
• Emphasis is on understanding intelligent behavior.
12.
Major Components ofan AI System
AI Program
AI Hardware
AI
Programming
languages and
tools
Knwoledge
Representation
Heuristic
Search
13.
Historical Development ofAI
i. Conception of AI (1943-1955)
ii. Birth of AI (1956)
iii. Adolescence of AI (1952-1969)
iv. Youthfulness of AI (1969-1979)
v. Maturity and Commercialization of AI (1980-
Present)
14.
Historical Development ofAI
• Conception of AI (1943-55)
- 1943: McCulloch & Pitts: build a Boolean circuit model of brain.
- 1950: Turing’s “Computing Machinery and Intelligence”.
Work done in this era:
- Turing Test
- Marvin Minsky’s first neural network in 1951
- Newell & Simon’s Logic Theorist
- Gelernter’s Geometry
- Theorem Proven.
- Robinson’s complete algorithm for logical reasoning
15.
Turing Test
• Turingproposed operational test for intelligent
behavior in 1950.
• Major contributor to the early
development of computers.
16.
Turing Test
• Toconduct Turing test, There is a need of two people and
the machine to be evaluated. One person plays the role of
the interrogator, who is in a separate room from the
computer and the other person.
• The interrogator can ask questions of either the person or
the computer by typing questions and receiving typed
responses. However, the integrator knows only as A and B
and aims to determine which is the person and which is
the machine.
• The goal of the machine is to fool the interrogator into
believing that it is the person. If the machine succeeds at
this, then we will conclude that the machine can think.
The Machine is allowed to do whatever it can to fool the
interrogator.
17.
History of AI
•Birth of AI (1956)
1956: McCarthy’s name “Artificial Intelligence” adopted.
Work done in this era:
Logic Theorist
Problem Solving
• Adolescence of AI (1952 - 1969)
Work done in this era:
Logic theorist for reasoning
General Problem Solver
Development of LISP by McCarthy in 1958
Hypothetical programs
18.
History of AI
•Youthfulness of AI (1969- 1979):
Work done in this era:
Weak AI
Strong AI
Expert System development(Knowledge based program)
Natural Language Understanding
Reasoning language PROLOG development
• Maturity and Commercialization AI (1980 - present):
Work done in this era:
Theory of Probability
Back-propagation learning algorithm
Expert systems industry busts.
Resurgence of probability.
Novel AI (Soft Computing, …).
Agents everywhere.
Human-level AI back on the agenda.
Types of AI
WeakAI or Narrow AI:
• Narrow AI is a type of AI which is able to perform a dedicated task with
intelligence. The most common and currently available AI is Narrow AI in the
world of Artificial Intelligence.
• Narrow AI cannot perform beyond its field or limitations, as it is only trained
for one specific task. Hence it is also termed as weak AI. Narrow AI can fail
in unpredictable ways if it goes beyond its limits.
• Apple Siri is a good example of Narrow AI, but it operates with a limited pre-
defined range of functions.
• IBM's Watson supercomputer also comes under Narrow AI, as it uses an
Expert system approach combined with Machine learning and natural
language processing.
• Some Examples of Narrow AI are playing chess, purchasing suggestions on
e-commerce site, self-driving cars, speech recognition, and image
recognition.
21.
Types of AI
GeneralAI
• General AI is a type of intelligence which could perform
any intellectual task with efficiency like a human.
• The idea behind the general AI to make such a system
which could be smarter and think like a human by its own.
• Currently, there is no such system exist which could come
under general AI and can perform any task as perfect as a
human.
• The worldwide researchers are now focused on developing
machines with General AI.
• As systems with general AI are still under research, and it
will take lots of efforts and time to develop such systems.
22.
Types of AI
STRONGAI or SUPER AI:
• Super AI is a level of Intelligence of Systems at which
machines could surpass human intelligence, and can perform
any task better than human with cognitive properties. It is an
outcome of general AI.
• Some key characteristics of strong AI include capability
include the ability to think, to reason, solve the puzzle, make
judgments, plan, learn, and communicate by its own.
• Super AI is a hypothetical concept of Artificial Intelligence.
Development of such systems in real is still world changing
task.
23.
Difference between Human
Intelligenceand AI
Human intelligence Artificial intelligence
Human intelligence revolves around adapting to the
environment using a combination of several cognitive
processes
The field of Artificial intelligence focuses on designing
machines that can mimic (copy) human behavior
Human Intelligence biologically based Artificial Intelligence is silicon based.
The ability to demonstrate their intelligence by
communicating effectively
Capture and preserve human intelligence
Human intelligence is separated through the five
senses.
Computer intelligence is separated into binary code
The human mind on the other hand works by
association, which is not always logical in a technical
sense.
Artificially Intelligence works along pre- set formulas
and ways, it is rather straight forward.
Human memory...Five access points Artificial intelligence...Just one access
point....
25.
Applications area ofAI
• Perception
– Machine vision
– Speech understanding
– Touch sensation
• Robotics
• Natural Language Processing
– Natural Language Understanding
– Speech Understanding
– Language Generation
– Machine Translation
• Expert Systems
• Machine Learning
• Theorem Proving
• Symbolic Mathematics
• Game Playing
What is anAgent?
• An agent can be anything that perceive its environment through sensors
and act upon that environment through actuators. An Agent runs in the
cycle of perceiving, thinking, and acting.
An agent can be:
• Human-Agent: A human agent has eyes, ears, and other organs which
work for sensors and hand, legs, vocal tract work for actuators.
• Robotic Agent: A robotic agent can have cameras, infrared range finder,
NLP for sensors and various motors for actuators.
• Software Agent: Software agent can have keystrokes, file contents as
sensory input and act on those inputs and display output on the screen.
28.
What is anAgent?
• Sensor: Sensor is a device which
detects the change in the environment
and sends the information to other
electronic devices. An agent observes
its environment through sensors.
• Actuators: Actuators are the
component of machines that converts
energy into motion. The actuators are
only responsible for moving and
controlling a system. An actuator can
be an electric motor, gears, rails, etc.
• Effectors: Effectors are the devices
which affect the environment. Effectors
can be legs, wheels, arms, fingers,
wings, fins, and display screen.
29.
Agent Terminology:
• PerformanceMeasure of Agent − It is the criteria, which
determines how successful an agent is.
• Behavior of Agent − It is the action that agent performs
after any given sequence of percepts.
• Percept − It is agent’s perceptual inputs at a given instance.
• Percept Sequence − It is the history of all that an agent has
perceived till date.
• Agent Function − It is a map from the precept sequence to
an action.
30.
Rational Agent:
Rationality
• Rationalityis nothing but status of being reasonable, sensible, and having good sense of
judgment.
• Rationality is concerned with expected actions and results depending upon what the agent has
perceived. Performing actions with the aim of obtaining useful information is an important part
of rationality.
What is Ideal Rational Agent?
• An ideal rational agent is the one, which is capable of doing expected actions to maximize its
performance measure, on the basis of −
Its percept sequence
Its built-in knowledge base
Rationality of an agent depends on the following :
The performance measures, which determine the degree of success.
Agent’s Percept Sequence till now.
The agent’s prior knowledge about the environment.
The actions that the agent can carry out.
A rational agent always performs right action, where the right action means the action that
causes the agent to be most successful in the given percept sequence. The problem the agent
solves is characterized by Performance Measure, Environment, Actuators, and Sensors (PEAS).
31.
Rational Agent:
• Arational agent is an agent which has clear preference, models
uncertainty, and acts in a way to maximize its performance measure
with all possible actions.
• A rational agent is said to perform the right things. AI is about
creating rational agents to use for game theory and decision theory
for various real-world scenarios.
• For an AI agent, the rational action is most important because in
AI reinforcement learning algorithm, for each best possible action,
agent gets the positive reward and for each wrong action, an agent
gets a negative reward.
• The rationality of an agent is measured by its performance
measure.
32.
Intelligent Agents
• Artificialintelligence is defined as the study of rational agents. A
rational agent could be anything that makes decisions, as a person, firm,
machine, or software.
• It carries out an action with the best outcome after considering past and
current percepts(agent’s perceptual inputs at a given instance).
• An AI system is composed of an agent and its environment. The agents
act in their environment. The environment may contain other agents.
An agent is anything that can be viewed as :
• perceiving its environment through sensors and
• acting upon that environment through actuators
• Note: Every agent can perceive its own actions (but not always the
effects)
33.
Intelligent Agents
Thestructure of Intelligent Agents
consists Architecture and Agent programs.
• Architecture is the machinery that the agent
executes on. It is a device with sensors and
actuators, for example, a robotic car, a camera, a
PC.
• Agent program is an implementation of an agent
function. An agent function is a map from the
percept sequence(history of all that an agent has
perceived to date) to an action.
• Agent = Architecture + Agent Program
Examples of Agent:
• A software agent has Keystrokes, file contents,
received network packages which act as sensors
and displays on the screen, files, sent network
packets acting as actuators.
• A Human-agent has eyes, ears, and other organs
which act as sensors, and hands, legs, mouth, and
other body parts acting as actuators.
• A Robotic agent has Cameras and infrared range
finders which act as sensors and various motors
acting as actuators.
34.
Types of Agents
Agentscan be grouped into five classes based
on their degree of perceived intelligence and
capability :
• Simple Reflex Agents
• Model-Based Reflex Agents
• Goal-Based Agents
• Utility-Based Agents
• Learning Agent
35.
Simple reflex agents
•Simple reflex agents ignore the rest of the percept
history and act only on the basis of the current
percept. Percept history is the history of all that
an agent has perceived to date.
• The agent function is based on the condition-
action rule. A condition-action rule is a rule that
maps a state i.e, condition to an action. If the
condition is true, then the action is taken, else not.
This agent function only succeeds when the
environment is fully observable.
• Simple reflex agents operates in partially
observable environments, infinite loops are often
unavoidable. It may be possible to escape from
infinite loops if the agent can randomize its
actions.
Problems with Simple reflex agents are :
• Very limited intelligence.
• No knowledge of non-perceptual parts of the state.
• Usually too big to generate and store.
• If there occurs any change in the environment,
then the collection of rules need to be updated.
36.
Model-based reflex agents
•It works by finding a rule whose condition
matches the current situation.
• A model-based agent can handle partially
observable environments by the use of a
model about the world.
• The agent has to keep track of the internal
state which is adjusted by each percept and
that depends on the percept history. The
current state is stored inside the agent which
maintains some kind of structure describing
the part of the world which cannot be seen.
Updating the state requires information
about :
• how the world evolves independently from
the agent, and
• how the agent’s actions affect the world.
37.
Goal-based agents
• Thesekinds of agents take decisions
based on how far they are currently
from their goal (description of
desirable situations).
• Their every action is intended to
reduce its distance from the goal. This
allows the agent a way to choose
among multiple possibilities, selecting
the one which reaches a goal state.
• The knowledge that supports its
decisions is represented explicitly and
can be modified, which makes these
agents more flexible. They usually
require search and planning.
• The goal-based agent’s behavior can
easily be changed.
38.
Utility-based agents
• Theagents which are developed having their
end uses as building blocks are called utility-
based agents.
• When there are multiple possible
alternatives, then to decide which one is
best, utility-based agents are used.
• They choose actions based on a preference
(utility) for each state. Sometimes achieving
the desired goal is not enough.
• Agent happiness should be taken into
consideration. Utility describes
how “happy” the agent is. Because of the
uncertainty in the world, a utility agent
chooses the action that maximizes the
expected utility.
• A utility function maps a state onto a real
number which describes the associated
degree of happiness.
39.
Learning Agent
• Alearning agent in AI is the type of agent that
can learn from its past experiences or it has
learning capabilities. It starts to act with basic
knowledge and then is able to act and adapt
automatically through learning.
A learning agent has mainly four conceptual
components, which are:
• Learning element: It is responsible for making
improvements by learning from the environment
• Critic: The learning element takes feedback from
critics which describes how well the agent is
doing with respect to a fixed performance
standard.
• Performance element: It is responsible for
selecting external action
• Problem Generator: This component is
responsible for suggesting actions that will lead
to new and informative experiences.
40.
The Nature ofEnvironments
• Some programs operate in the entirely artificial
environment confined to keyboard input, database,
computer file systems and character output on a
screen.
• In contrast, some software agents (software robots or
softbots) exist in rich, unlimited softbots domains. The
simulator has a very detailed, complex environment.
The software agent needs to choose from a long array
of actions in real time. A softbot designed to scan the
online preferences of the customer and show interesting
items to the customer works in the real as well as
an artificial environment.
41.
Properties of Environment
Theenvironment has multifold properties −
• Discrete / Continuous − If there are a limited number of distinct, clearly defined, states
of the environment, the environment is discrete (For example, chess); otherwise it is
continuous (For example, driving).
• Observable / Partially Observable − If it is possible to determine the complete state of
the environment at each time point from the percepts it is observable; otherwise it is
only partially observable.
• Static / Dynamic − If the environment does not change while an agent is acting, then it
is static; otherwise it is dynamic.
• Single agent / Multiple agents − The environment may contain other agents which may
be of the same or different kind as that of the agent.
• Accessible / Inaccessible − If the agent’s sensory apparatus can have access to the
complete state of the environment, then the environment is accessible to that agent.
• Deterministic / Non-deterministic − If the next state of the environment is completely
determined by the current state and the actions of the agent, then the environment is
deterministic; otherwise it is non-deterministic.
• Episodic / Non-episodic − In an episodic environment, each episode consists of the
agent perceiving and then acting. The quality of its action depends just on the episode
itself. Subsequent episodes do not depend on the actions in the previous episodes.
Episodic environments are much simpler because the agent does not need to think
ahead.
Problem Solving
• Problemsolving is the key area of concern for
Artificial Intelligence.
• Problem solving is a process of generating
solutions from observed or given data.
• It is however not always possible to use direct
methods (i.e. go directly from data to solution).
• Instead, problem solving often needs to use
indirect or model based methods.
44.
Problem Solving
Problem solvingin AI involves:
• The process of defining the search space
• Deciding start and goal states
• Then, finding the path from start state to goal state
through search space.
The movement from start state to goal state is guided
by set of rules specifically designed for that particular
problem. These rules are called production rules. The
production rules are nothing but valid moves
described by the problems.
45.
Terms related toproblem solving
• Problem: It is the question which is to be solved.
• Search Space: It is the complete set of states including start
and goal states, where the answer of the problem is to be
searched.
• Search: It is the process of finding the solution in search
space.
• Well-defined problem: A problem description has three major
components: initial state, final state, space including
transition function or path function.
• Solution of the problem: A solution of the problem is a path
from initial state to goal state.
46.
Problem representation
AI problemscan be covered in following parts:
- A lexical part
- A structural part
- A procedural part
- A semantic part
There are two ways for problem representation:
- State space representation
- Problem reduction
47.
Features of goodrepresentation
- Capture the important feature and relations
- Expose natural constraints
- Bring object and relations together
- Suppress irrelevant details of the problem
- Transparency
- Should be complete
- Concise in nature
- Should be suitable from computational viewpoint
- Their storage should consume minimum memory
- They should be computable.
48.
Production System
AI systemdeveloped for solution of any problem is
called production system. Once the problem is defined,
analyzed and represented in a suitable formalism, the
production system is used for application of rules and
obtaining the solution.
Components of production system:
- Set of production rules
- One or more knowledge/data bases
- Control strategy
- Rule applier
49.
Features of productionrules
- Expressiveness and intuitiveness
- Simplicity
- Modularity and modifiability
- Knowledge intensive
- Efficiency
- Conflict resolution
Problem Characteristics
- Problemshould be decomposable.
- Problem should follow the steps.
- Problem should be predictable.
- Solution of the problem should be obvious or optimal.
- Solution of problem can be absolute or relative.
- Large amount of knowledge absolutely required to
solve the problem
- Solution of the problem require interaction between
the computer and a person.
52.
Nature of AIProblems
- Path finding Problem
- Decomposable Problem
- Recoverable Problem
- Predictable Problem
- Problem affecting the quality of solution
- State finding Problem
- Problems requiring Interaction
- Knowledge intensive problems
53.
Searching
Search Algorithm Terminologies:
•Search: Searching is a step by step procedure to solve a search-problem in a given
search space. A search problem can have three main factors:
– Search Space: Search space represents a set of possible solutions, which a
system may have.
– Start State: It is a state from where agent begins the search.
– Goal state/function: It is a function which observe the current state and returns
whether the goal state is achieved or not.
• Search tree: A tree representation of search problem is called Search tree. The root
of the search tree is the root node which is corresponding to the initial state.
• Actions: It gives the description of all the available actions to the agent.
• Transition model: A description of what each action do, can be represented as a
transition model.
• Path Cost: It is a function which assigns a numeric cost to each path.
• Solution: It is an action sequence which leads from the start node to the goal node.
• Optimal Solution: If a solution has the lowest cost among all solutions.
54.
Properties of SearchAlgorithms:
Essential properties of search algorithms:
• Completeness: A search algorithm is said to be complete if it
guarantees to return a solution if at least any solution exists for
any random input.
• Optimality: If a solution found for an algorithm is guaranteed
to be the best solution (lowest path cost) among all other
solutions, then such a solution for problem is said to be an
optimal solution.
• Time Complexity: Time complexity is a measure of time for an
algorithm to complete its task.
• Space Complexity: It is the maximum storage space required at
any point during the search, as the complexity of the problem.
Search Techniques
Blind/Unguided/Uninformed Search:
This search methodology have no additional information about
states. In this search, total search space is looked for solution.
The uninformed search does not contain any domain knowledge
such as closeness, the location of the goal.
It operates in a brute-force way as it only includes information
about how to traverse the tree and how to identify leaf and goal
nodes.
Uninformed search applies a way in which search tree is
searched without any information about the search space like
initial state operators and test for the goal, so it is also called
blind search.
It examines each node of the tree until it achieves the goal node.
57.
Search Techniques
Heuristic/Guided/Informed Search:
These are the search techniques where additional information
about the problem is provided in order to guide the search in
a specific direction.
Informed search algorithms use domain specific knowledge.
In an informed search, problem information is available
which can guide the search. Informed search strategies can
find a solution more efficiently than an uninformed search
strategy.
A heuristic is a way which might not always be guaranteed
for best solutions but guaranteed to find a good solution in
reasonable time.
58.
Uninformed Search Algorithms
•Uninformed search is a class of general-purpose
search algorithms which operates in brute force-way.
Various types of uninformed search algorithms:
• Breadth-first Search
• Depth-first Search
• Depth-limited Search
• Iterative deepening depth-first search
• Uniform cost search
• Bidirectional Search
59.
Breadth-first Search:
• Breadth-firstsearch is the most common search strategy for
traversing a tree or graph. This algorithm searches breadth
wise in a tree or graph, so it is called breadth-first search.
• BFS algorithm starts searching from the root node of the
tree and expands all successor node at the current level
before moving to nodes of next level.
• The breadth-first search algorithm is an example of a
general-graph search algorithm.
• Breadth-first search implemented using FIFO queue data
structure.
61.
• Time Complexity:Time Complexity of BFS algorithm can be
obtained by the number of nodes traversed in BFS until the
shallowest Node. Where the d= depth of shallowest solution
and b is a node at every state.
T (b) = 1+b2
+b3
+.......+ bd
= O (bd
)
• Space Complexity: Space complexity of BFS algorithm is
given by the Memory size of frontier which is O(bd
).
• Completeness: BFS is complete, which means if the shallowest
goal node is at some finite depth, then BFS will find a solution.
• Optimality: BFS is optimal if path cost is a non-decreasing
function of the depth of the node.
62.
Advantages:
• BFS willprovide a solution if any solution exists.
• If there are more than one solutions for a given problem,
then BFS will provide the minimal solution which
requires the least number of steps.
Disadvantages:
• It requires lots of memory since each level of the tree
must be saved into memory to expand the next level.
• BFS needs lots of time if the solution is far away from the
root node.
63.
Depth-first Search
• Depth-firstsearch is a recursive algorithm for
traversing a tree or graph data structure.
• It is called the depth-first search because it starts
from the root node and follows each path to its
greatest depth node before moving to the next path.
• DFS uses a stack data structure for its
implementation.
• The process of the DFS algorithm is similar to the
BFS algorithm except depth.
65.
• Completeness: DFSsearch algorithm is complete within finite
state space as it will expand every node within a limited search
tree.
• Time Complexity: Time complexity of DFS will be equivalent to
the node traversed by the algorithm. It is given by:
T(n)= 1+ n2
+ n3
+.........+ nm
=O(nm
)
where, m= maximum depth of any node and this can be much
larger than d (Shallowest solution depth)
• Space Complexity: DFS algorithm needs to store only single path
from the root node i.e linear function of the depth, hence space
complexity of DFS is equivalent to the size of the fringe set, which
is O(bm).
• Optimal: DFS search algorithm is non-optimal, as it may generate
a large number of steps or high cost to reach to the goal node.
66.
Advantage:
• DFS requiresvery less memory as it only needs to store a
stack of the nodes on the path from root node to the current
node.
• It takes less time to reach to the goal node than BFS
algorithm (if it traverses in the right path).
Disadvantage:
• There is the possibility that many states keep re-occurring,
and there is no guarantee of finding the solution.
• DFS algorithm goes for deep down searching and sometime it
may go to the infinite loop.
67.
Depth-Limited Search Algorithm
•A depth-limited search algorithm is similar to depth-first
search with a predetermined limit.
• Depth-limited search can solve the drawback of the infinite
path in the Depth-first search.
• In this algorithm, the node at the depth limit will treat as it
has no successor nodes further.
• Depth-limited search can be terminated with two Conditions
of failure:
Standard failure value: It indicates that problem does not
have any solution.
Cutoff failure value: It defines no solution for the problem
within a given depth limit.
69.
• Completeness: DLSsearch algorithm is complete
if the solution is above the depth-limit.
• Time Complexity: Time complexity of DLS
algorithm is O(bℓ
).
• Space Complexity: Space complexity of DLS
algorithm is O(b×ℓ).
• Optimal: Depth-limited search can be viewed as
a special case of DFS, and it is also not optimal
even if ℓ>d.
70.
Advantages:
• Depth-limited searchis Memory efficient.
Disadvantages:
• Depth-limited search also has a disadvantage
of incompleteness.
• It may not be optimal if the problem has more
than one solution.
71.
Uniform-cost Search Algorithm
•Uniform-cost search is a searching algorithm used for traversing a
weighted tree or graph.
• This algorithm comes into play when different cost is available for
each edge.
• The primary goal of the uniform-cost search is to find a path to the
goal node which has the lowest cumulative cost.
• Uniform-cost search expands nodes according to their path costs
form the root node.
• It can be used to solve any graph/tree where the optimal cost is in
demand.
• A uniform-cost search algorithm is implemented by the priority
queue. It gives maximum priority to the lowest cumulative cost.
• Uniform cost search is equivalent to BFS algorithm if the path cost
of all edges is the same.
73.
Completeness:
• Uniform-cost searchis complete, such as if there is a solution,
UCS will find it.
Time Complexity:
• Let C* is Cost of the optimal solution, and ε is each step to get
closer to the goal node. Then the number of steps is = C*/ε+1.
Here we have taken +1, as we start from state 0 and end to C*/ε.
• Hence, the worst-case time complexity of Uniform-cost search
isO(b1 + [C*/ε]
)/.
Space Complexity:
• The same logic is for space complexity so, the worst-case space
complexity of Uniform-cost search is O(b1 + [C*/ε]
).
Optimal:
• Uniform-cost search is always optimal as it only selects a path
with the lowest path cost.
74.
Advantages:
• Uniform costsearch is optimal because at every
state the path with the least cost is chosen.
Disadvantages:
• It does not care about the number of steps
involve in searching and only concerned about
path cost. Due to which this algorithm may be
stuck in an infinite loop.
75.
Iterative deepening depth-firstSearch
• The iterative deepening algorithm is a combination of DFS and
BFS algorithms. This search algorithm finds out the best depth
limit and does it by gradually increasing the limit until a goal is
found.
• This algorithm performs depth-first search up to a certain
"depth limit", and it keeps increasing the depth limit after each
iteration until the goal node is found.
• This Search algorithm combines the benefits of Breadth-first
search's fast search and depth-first search's memory efficiency.
• The iterative search algorithm is useful uninformed search
when search space is large, and depth of goal node is unknown.
76.
1'st Iteration-----> A
2'ndIteration----> A, B, C
3'rd Iteration------>A, B, D, E, C, F, G
4'th Iteration------>A, B, D, H, I, E, C, F, K, G
In the fourth iteration, the algorithm will find the goal node.
77.
Completeness:
• This algorithmis complete is if the branching factor is finite.
Time Complexity:
• Let's suppose b is the branching factor and depth is d then
the worst-case time complexity is O(bd
).
Space Complexity:
• The space complexity of IDDFS will be O(bd).
Optimal:
• IDDFS algorithm is optimal if path cost is a non- decreasing
function of the depth of the node.
78.
Advantages:
• It combinesthe benefits of BFS and DFS
search algorithm in terms of fast search and
memory efficiency.
Disadvantages:
• The main drawback of IDDFS is that it repeats
all the work of the previous phase.
79.
Bidirectional Search Algorithm
•Bidirectional search algorithm runs two simultaneous
searches, one form initial state called as forward-search
and other from goal node called as backward-search, to
find the goal node.
• Bidirectional search replaces one single search graph with
two small subgraphs in which one starts the search from an
initial vertex and other starts from goal vertex.
• The search stops when these two graphs intersect each
other.
• Bidirectional search can use search techniques such as
BFS, DFS, DLS, etc.
81.
• Completeness: BidirectionalSearch is
complete if we use BFS in both searches.
• Time Complexity: Time complexity of
bidirectional search using BFS is O(bd
).
• Space Complexity: Space complexity of
bidirectional search is O(bd
).
• Optimal: Bidirectional search is Optimal.
82.
Advantages:
• Bidirectional searchis fast.
• Bidirectional search requires less memory
Disadvantages:
• Implementation of the bidirectional search tree
is difficult.
• In bidirectional search, one should know the
goal state in advance.
83.
EXPERT SYSTEM
• Expertsystems are used to perform a number of complicated
tasks that could be performed by only a limited number of
highly experienced human experts.
• In simple words, expert system is computer program that acts
intelligently and solves the problem as human expert will.
• Expert system are knowledge intensive programs to solve
problems in a domain that requires significant amount of
technical expertise or
• An expert system is defined as a computer application to
solve complex problems that require human expertise. To do
that, human reasoning process is simulated by applying
specific knowledge and inferences.
84.
EXPERT SYSTEM
• Anexpert system is defined as a computer program that act
intelligently and performs the task of designing, diagnosing,
analyzing, monitoring, advising and scheduling etc.
• According to Professor Edward Feigenbaum, “Expert system is
defined as an intelligent computer program that uses knowledge and
inference procedures to solve problems that are difficult enough to
require human expertise for their solutions.”
• According to British Computer Society’s Committee of the specialist
group on Expert Systems, “Expert system is defined as the
embodiment within a computer of a knowledge-based component
from an expert skill in such a form that the machine can offer
intelligent advice or take an intelligent decision about a processing
function.
85.
Characteristics of EXPERTSYSTEM
As knowledge intensive programs, an ideal expert system can be
characterized as follows:
• Extensive specific knowledge from domain of interest
• Solve difficult problems in a domain as good as or better than human
experts
• Application of search techniques
• Facility for incorporation of heuristic analysis
• Capacity to deduce or infer new knowledge from existing knowledge
• Ability to clarify or justify its own reasoning and conclusions
• Accept, modify, update and expand advice specified by different sources
• Deal with uncertain and irrelevant data
• Communication with the users in their own natural languages
• Ability to cater the individual desires
• Facility for symbolic processing rather numeric processing
86.
Difference b/w human& expert system
Human expert Expert system
1. Human experts possess deep knowledge of problem domain.
They are able to apply heuristic knowledge and common sense
when required.
2. Human experts have ability to provide explanations. They are
able to explain why the solution is most appropriate.
3. Human experts have flexibility and robustness in nature to solve
the problem. If there is any difficulty to solve the problem
immediately, they can wait and find some new plan to solve the
problem.
4. Human experts can learn from experiences they acquire over the
years without any extra effort. They keep on adding to their
knowledge by experience.
5. Human experts are not easily available and they have
limitations of working time. In addition, one expert can deal
with one problem at a time.
6. Human expertise is not economical in nature.
7. The expertise of human experts is not remaining forever. Human
experts may quit or die.
8. It is difficult to use multiple humans to work on a single
problem at a time.
9. Due to emotions, sometimes the results are affected produced by
human experts and may not be ideal solutions.
10. Human expert cannot act as an intelligent tutor.
11. Knowledge possessed by human experts cannot be explored by
others and cannot be refined or corrected if needed.
1. Expert systems find difficulty in capturing deep knowledge.
They lack in application of common sense knowledge &
functioning depends on the knowledge base.
2. Expert systems are not able to provide explanations about the
facts due to lack of deep knowledge.
3. Expert systems are not flexible and robust in nature. Whatever
result they produce immediately, the same will be provided ever
after.
4. On the other hand, expert systems once built cannot learn
anything from experiences. Their performance will remain same
until modifications are done to their program.
5. Expert systems are easily available to any computer once they
developed. One expert system can be used at different places at
the same time.
6. Use of expert systems is more economical than humans.
7. The expertise of expert systems remains forever. Expert system
will last indefinitely.
8. Multiple expert systems can be used to work simultaneously on
one problem at a time and combined expertise may exceed that
of a single human expert.
9. Expert systems do not have emotions, hence results produced by
them are unaffected by circumstances.
10. Expert system can act as tutor for someone who want to learn
the reasoning and approach used to solve a particular problem
11. The knowledge base of an expert system can be checked and
refined if needed. So, quality of knowledge possessed by expert
system is improved.
87.
Role of knowledgein expert
system
• Knowledge is the essential factor that is responsible for making a person
expert of a particular field. The knowledge of a particular area possessed by
an expert of that area is called domain-knowledge.
• The job of experts is to solve any problem related to the area of interest. For
solution of the any problem, first and necessary step is to identify the
information related to the problem to be solved. After that, the problem is
passed to an expert who possesses required amount of knowledge.
• This is general form of expertise that is common across a number of domains.
Thus, the domain-specific knowledge is required for expert system to solve the
complex problem.
• Knowledge plays a significant role in expert system. In expert system to solve a
problem, it is needed to require deep knowledge of a particular area. This
knowledge can be acquired from human experts and coding of the same is
done into a form that is applicable by a computer to solve the problem. On the
basis of that knowledge, the expert can solve the problem of a particular
domain.
88.
Analysis of knowledge
Theknowledge is analyzed on the basis of its different components that define the expert’s
ability to perform. The components can be specified as:
• Facts: These are the statements that relate some element of truth regarding subject domain.
For example:
Sky is blue.
Dog is an animal.
• Procedural rules: These are invariant and well-defined rules that describe basic sequences
of events and relations relative to the domain. For example:
Always check the traffic before attempting to merge onto the free-way.
• Heuristic rules: These are the general rules in the form of hunches or rules of thumb that
suggest procedures to be followed when invariant procedural rules are not available. These
rules are approximate and have been gathered by experts through years of experience. The
presence of heuristic rules specifies the power and flexibility of expert system and
distinguishes expert system from more traditional software. For example:
It is better to attempt an emergency landing under controlled conditions than to fly in an
unknown condition.
In addition to these specific forms of knowledge, an expert has a general conceptual model
of the subject domain and an overall scheme for finding the solution of problem. This global
view is helpful for making a basic framework for the expert’s application of detailed
knowledge.
89.
Levels of knowledgeanalysis
• Knowledge identification: At this level, knowledge is identified using depth
interviews where the knowledge engineer encourages the expert to talk about
how the work is to be done and what they will do to complete the work. In this
way, the knowledge engineer can understand the domain well.
• Knowledge conceptualization: At this level, the primary concepts and
conceptual relations of the problem domain are to be find out.
• Epistemological analysis: The structural properties of the conceptual
knowledge are to be uncovered at this level, for e.g. taxonomic relations
(classifications).
• Logical analysis: How the reasoning is to be performed in the problem domain
is decided at this level. This kind of knowledge can be particularly hard to
acquire.
• Implementational analysis: At this level, systematic procedures for
implementing and testing the system are defined.
90.
Architecture of expertsystem
USER
USER INTERFACE
EXPLANATION FACILITY
KNOWLEDGE UPDATE FACILITY
KNOWLEDGE BASE
INFERENCE ENGINE
91.
USER
There are differentfaces of an expert system, which a user perceives. The
user of an expert system can play any of the roles from several modes:
• Tester: As a tester, user attempts to verify the validity of the behavior of
system.
• Tutor: As a tutor, the user acts as an archive and information generator
for different types of problems. User provides additional knowledge to the
system or updates the existing knowledge already present in the system.
• Pupil: As a pupil, the user wants to develop personal expertise related to
subject domain by extracting well organized and distilled knowledge from
the system.
• Customer: As a customer, user applies the system’s expertise to specific
real task.
These are the different faces, which a user perceives.
92.
USER INTERFACE
• Userinterface provides the facilities for the user to communicate with
the system.
• It acts as a bridge between user and expert system.
• User interface facility must accept information from the user and
translate it into a form that is acceptable to the remainder of the system
or accept information from the system and convert it into a form that
can be understandable by the user. Because for a naive user, it is not
possible to understand the knowledge from internal representation.
• It is the responsibility of the user interface to convert internal
representation into an understandable form.
• User interface facility consists of a Natural Language Processing
(NLP) system that accepts and returns information in the same form as
that accepted or provided by a human expert.
• User interface facilities are designed to recognize the level of user’s
expertise and the nature of the transaction.
93.
Knowledge storage andGeneration system
• This is the heart of an expert system. It consists of knowledge base and inference
engine. To store expert knowledge, retrieval of knowledge from storage and to
deduce or infer new knowledge (when required) is the function of this system.
• Knowledge base: Knowledge base is the repository of knowledge in expert system.
It is the storehouse of knowledge primitives (i.e. facts, procedural rules and
heuristic) or it can be considered as the warehouse of domain-specific knowledge
captured from the human expert with the help of knowledge acquisition process.
• The knowledge stored in the knowledge base establishes the system’s capability to
perform as an expert.
• In general, knowledge is stored in the form of facts and rules on the basis of some
specific schemes used for storing the information.
• The expert system uses this stored knowledge to answer the queries or to provide
consultation to the user and capabilities of expert system are also depend on this
knowledge.
• A lot of knowledge is required to build an effective knowledge base and that
knowledge can be acquired from various sources.
• The process of acquiring or gathering the knowledge is defined as knowledge
acquisition and this job is performed by knowledge engineers. After the gathering
of knowledge, knowledge is encoded in a suitable format for storage in memory of
computer.
94.
Knowledge storage andGeneration
system(CONT..)
• Knowledge Engineering: Knowledge engineering is the process of
acquiring the domain-specific knowledge and building it into the
knowledge base. Knowledge can be secured from a variety of sources i.e.
documentation and existing information system.
• Knowledge provided by expert is domain specific in nature.
• A knowledge engineer (KE) is the person who acquires the knowledge
from domain expert and transports it to the knowledge base.
• Knowledge engineer transforms the representation of knowledge as a
part of transportation process because, according to the requirement of
expert system, knowledge is stored on the basis of knowledge
representation convention in knowledge base.
• To get the essential knowledge, the KE must establish the complete
understanding of domain firstly and develop a basic understanding of
the key concepts.
• After that succinct knowledge must be distilled from the information
provided by the expert.
95.
Knowledge storage andGeneration
system(CONT..)
Inference engine
• Expert system deals with different kinds of situations. The capability to
respond to different situations depends on the ability to infer new
knowledge from the existing knowledge.
• In the processing of expert system, inference engine is the module which
finds an answer from the knowledge base.
• Inference engine deduce new knowledge by deciding the satisfaction of
rules, decides the priorities of the satisfied rules and executes the rules
with highest priority.
• As the primitives are used, one of the greatest difficulties arises. This
problem is named as combinatorial explosion in which few individual
elements or primitives can be combined into a large number of unique
combinations.
• To overcome the problem, expert systems use compiled knowledge i.e. high
level knowledge generated in background mode through the years of
experience rather than attempt to operate from primitives.
96.
Knowledge storage andGeneration
system(CONT..)
• The inference engine is the software system that locates
knowledge and infers new knowledge from the base or existing
knowledge.
• The engine’s inference paradigm is a searching strategy that is
used to build up essential knowledge.
• An expert system uses different paradigms, but most are based
on one of two basic concepts: forward chaining and
backward chaining.
• Forward chaining is a bottom-up reasoning process that
starts with known conditions and works toward the desired
goal and
• Backward chaining is a top-down reasoning process that
starts from desired goals and works backward toward required
conditions.
97.
KNOWLEDGE UPDATE
Knowledge canbe expanded and updated in complex domains. The
knowledge update facility is used to perform such modifications.
Modifications can be done by one of three basic ways, as follows:
• Manual knowledge update: In this form, the update is performed by
Knowledge Engineer (KE) who interprets information provided by a
domain expert and updates the knowledge base by using limited knowledge
update system.
• Direct update by domain expert: In expert system, this form represents the
state of art. In this form, domain expert enters the revised knowledge
directly. Knowledge engineer has no role in this form.
• Machine learning: New knowledge is generated automatically by the
system and that knowledge is based on generalizations drawn from past
experiences. The system learns from experience and is self-updating. The
ability to learn is an important element of intelligence and significantly
improves the power of expert system.
On the basis of these, all enhancements of the knowledge system are
implemented by expanding the knowledge base.
98.
EXPLANATION SYSTEM
• Anexpert system is capable of explaining the reasoning that is used to get the
conclusion. Generally, this facility is missing from traditional computer systems.
• The explanation facility allows the program to explain its reasoning and how and
why a specific conclusion is drawn. This facility increases the belief of user in
expert system.
• The explanation consists of identification of the steps in the reasoning process
and justification for each step.
• The system access the record of knowledge that was used in processing, based on
knowledge base representation scheme, and translates this knowledge into a
form that is understandable to the user.
The explanation of expert system plays significant role in different ways i.e.
- To satisfy the need of users that conclusions of program are correct for their
particular problem.
- To check that knowledge is applied properly or not.
- To check that a system module is working properly that is responsible for making
the decisions.
99.
PROGRAMMING LANGUAGES FOREXPERT
SYSTEM
In a simple way, programming of expert systems focuses on issues of inference
and heuristic search. It depends on the manipulations of symbols.
The aim of programming is to implement the representation and control
structure required for intelligent problem solving.
The programming languages named LISP and PROLOG are the languages used
in development of expert system.
The main advantage of these languages is that their syntactic and semantic
features formulate the ways of thinking about the problems and their solutions.
These languages are used to maintain the big knowledge base, to build
inference engine and natural language interface and for dynamic knowledge
acquisition. LISP is a functional language in which every statement is a
description of function. PROLOG is a logic language in which every statement
is an expression in formal logic syntax.
Symbolic processing is important in expert systems because the knowledge
primitives and the relationships between the knowledge primitives are stored by
using symbolic representation in a knowledge base.
It is very helpful for expert system when programming languages deal freely
with “things” without being concerned with the composition of those things.
100.
Expert system developmentprocess
• Expert system development process is similar to the software development life cycle process.
It consists of several basic stages as in software development life cycle segments.
• These stages consist of identification of problem, prototype construction, formalization,
implementation and evaluation etc.
• The first step in expert system development is to identify the appropriate problem. If the
problem can be described in terms of direct definition and algorithms, a traditional solution
is preferred for problem.
• If the problem is vague or it requires intensive human judgment, it can be complex for an
expert system.
• After the selection of the appropriate problem, a prototype or a blue print is constructed to
understand the complete problem and to estimate the task of building the complete solution.
• In the development process, the next step is to formalize the problem statement and design
complete expert system. After the completion of formalization, the implementation is
conducted. It consists of knowledge acquisition, knowledge base update and test.
• Following the implementation, evaluation is performed. This phase is used to evaluate the
level to which system approaches the expert’s behavior.
• After the evaluation, the expert system enters in long-term evolution. During this, the system
continues to grow in capability and is revised in response to changes in domain-specific
knowledge.
101.
Expert system developmentprocess
Expert system is used to solve the complex problems in real world.
The main function of expert system is to make available a quality
tool for the users so that they are capable to deal with the problems
in cost-effective manner and within the specific time period.
Expert system development process is similar to software
development process. In traditional software development, well-
defined methods for performing the activities are specified.
Software engineering specifies the software development
techniques.
On the other hand, development of expert system not only uses
portions of traditional software development but also uses the
methods of acquisition and maintenance of knowledge.
102.
Expert system development
process
Expert system development is different from conventional software development in
following ways:
In traditional software, fixed algorithms are used for different problems. But there is no
algorithmic approach in expert system.
In traditional software development, there is a limited discussion between developer
and user. The developer studies the existing system, identifies the shortcomings,
visualizes the enhancements, design and implements the system. On the other hand,
expert system development is a cooperative effort. Both the developer and domain
expert work together from the initial stages to the completion of the system.
There is a limited interaction between developer and implementor in traditional
software development. System is evaluated by user after significant progress. But there
must be frequent interaction in development of expert system and every small step must
be demonstrated and discussed.
Changes in traditional system are made if the user wants. But there are frequent
changes in expert system for the successful development of system in a particular
domain.
Phases of EXPERTSYSTEM LIFE
CYCLE
• Problem Identification:
This phase is considered as one of the most difficult
phase in development life-cycle.
In this phase, problem is to be identified on the basis of
its characteristics, scope and extent. Different resources
(man power, computing resources, finance etc.) needed
for solving the problems is identified.
The overall specification related to complexity and
conceptual solution of the problem is also defined in this
phase.
106.
Problem Identification:
Identification ofProblem
Problem survey Candidate Analysis
Cost/Benefit Analysis
Candidate Selection
Availability of Expert
Domain Applicability
Final Candidate Selection
Scope of the Problem
107.
Problem Identification:
• ProblemSurvey:
This is very brainstorming session of problem
identification.
In it, a list of problems is to be compiled to
select the problem. The criterion is very liberal
for inclusion on the list.
The list can consist 30 to 50 items by one-line
entry for a typical large organization.
108.
Problem Identification:
Candidate Selection:
The main purpose of problem identification phase is to select only
those applications from the list that will require expertise
consideration.
For the selection of those applications, a screening criterion is to
be set to evaluate the original list. The applications those meet all
of the screening criteria are considered in advance to the
candidate list.
The purpose of this screening criterion is to filter out the problems
that fail to meet the criteria and to get the problems that require
expertise. After that, problem will be analyzed in more detail.
109.
Candidate Selection Criteria:
Thefollowing factors are considered in the basic screening criteria:
• Does the problem require use of expert knowledge?
• Is the required expertise inadequate or sufficient?
• Expert who know how to perform the task are available or not.
• Experts agree on solution or not. / is there any reason to believe that a traditional
algorithmic solution would be difficult to implement?
• Does the problem require judgmental knowledge or some uncertainties in
problem are present or not?
• Does the problem require primarily verbal/mental skill rather than physical skill?
• Does the problem involve common sense reasoning and knowledge?
• What is the level of difficulty of problem?
• What is the amount of time available for development of the system?
• Solution of the problem is valuable to the organization or not.
• Is the solution likely to stay valuable for several years to come that is valuable
today?
• Is it acceptable for the system to fail to find a solution occasionally or to produce
a suboptimum response in some cases?
110.
Problem Identification:
• CandidateAnalysis
The problem is to be analyzed on the basis of
different factors. This step consists different sub-steps
for the analysis of problem which are following:
- Domain applicability
- Expert availability
- Problem Scope
- Cost-benefit Analysis
• Final Candidate Selection
111.
PROTOTYPE CONSTRUCTION
Oncea problem has been identified, the next task is to build a
prototype that represents a small model of the final system.
Less number of test cases and less time will be required to
complete the prototype (i.e only 5 to 10 test cases will be addressed
and few weeks to few months will be required for completion of
prototype) depending on the scope and difficulty of problem.
The process of prototype is to build a blueprint of model. Prototype
construction is same as an artist produce a charcoal sketch of a
painting.
It will be helpful to estimate the work accurately in a form that will
be easy to change. Prototyping as a blueprint acts as a lively
representative in planning and design process.
112.
PROTOTYPE CONSTRUCTION
The specificpurposes of prototype are as following:
1. To get a deeper comprehension of nature and
scope of problem and different problem-solving
technique.
2. To demonstrate the overall functionality of the
system. It allows to evaluate the usefulness of the
system and to decide whether to continue with the
development of complete system or not.
3. To test the primary design decisions.
113.
PROTOTYPE CONSTRUCTION
The processof prototype construction consists following steps:
• Initial knowledge acquisition
• Basic problem approach
• General consultation model
• Selection of Inference paradigm
• Selection of knowledge representation
• Tool selection
• Implementation of prototype
• Prototype testing
• Prototype demonstration
• Project revisions(if necessary)
114.
FORMALIZATION
• Formalization phaseis the next key task in development
process after prototype construction.
• Following the verification of the prototype, work on the
final system begins.
• Formalization is considered as an important phase in ES
development as it is in the development of any other large
complex software system.
• It can be more important because there is a need to capture
an understanding of problem that is initially not well
understood because there is always the danger of failing
into a kludge.
115.
FORMALIZATION
The main purposesof the formalization phase are following:
• To get and record the main understandings developed
during the prototype phase
• Force planning prior to the start of full implementation
• Record decisions in respect to implementation strategies
• Offer visibility to all existing understanding to allow more
people to contribute to the project
• Provide visibility and checkpoints to allow for
management of project and user to be concerned in the
project
• Allow for concurrent development of test, deployment and
long-term support facilities
116.
FORMALIZATION
Following are thesub-phases of formalization:
• Detailed Problem Definition:
• Design:
• Project Planning:
• Test Planning:
• Product Planning
• Support Planning:
• Implementation Planning:
117.
IMPLEMENTATION
After the formalization,implementation of ES
begins. Implementation phase depends on various
steps which are following:
• Prototype revision
• System framework development
• Core knowledge acquisition
• Ancillary software development
• Internal integration
• Internal verification
118.
IMPLEMENTATION
The prototype revisionconsists of following steps:
• Revision of representation and inference decisions: In this step,
knowledge representation scheme and inference scheme are
updated to comply with decisions made during the design phase.
Following this, the scheme for knowledge primitives assignment
is re-evaluated.
• Component representation level revision: This involves review of
representation level, object selection, and the attributes
associated with those objects. This re-evaluation is based on
understanding of the domain that results from the prototype
development and from fundamental revisions of representation
and inference scheme occurred during design phase.
119.
IMPLEMENTATION
• Establishment ofknowledge base partitioning: Knowledge base is divided into
logically independent segments. This is the effective technique to deal with
complexity in which system is decomposed into manageable sub-parts. Partitioning
can be done at an architectural level by dividing the task into independent subtask.
Partitioning within knowledge base can be done by following concepts:
Cohesion: The extent to which different knowledge chunks are closely related with
each other i.e. how well the parts of a segment are closed with each other.
Coupling: It identifies the number of connections between segments.
Partitioning base: It specifies the properties that are used for grouping the chunks
into segments.
For knowledge base partitioning, the KE first selects the partitioning base and
then groups chunks on the basis of cohesion and coupling where cohesion should
be maximized and coupling should be minimized.
120.
IMPLEMENTATION
• Following thePrototype revision, the largest
development phase begins. This phase includes the
development of system framework, core knowledge
acquisition and development of ancillary software.
Generally, these activities can be executed in parallel.
• The basic framework of the system specifies the
inference engine, user interface etc. specifications.
The core knowledge base is made up of the knowledge
required to complete the test cases identified in test
plan.
121.
IMPLEMENTATION
Internal Integration andVerification:
The main system components must be integrated into one
comprehensive system. This integration generally requires
conflict resolution among various modules i.e. result of
misunderstanding of interface conventions.
As the system is integrated, then it is verified by the KE and
the domain expert. This is a comprehensive analysis that
should include representative test cases from all parts of the
system. It is necessary that both the KE and the expert should
agree that system is correctly implemented before sending it
for formal verification by external people.
122.
Evaluation
In this phase,system is evaluated. An ESs
response should be evaluated relative to the
domain expert’s and the responses given by the
group of experts.
It is also possible to evaluate the structure
rather than the function of the system. Always
the focus remains on verifying the
completeness and consistency of the system.
123.
Long-Term Evolution
A numberof evolutions are involved through-out the life of a large
software system. These are following:
• Increase in general functionality
• Knowledge base corrections
• Additions to the knowledge base to make the base more complete
• Expansion of the domain
• Revisions required by external modifications
• The indirect benefit is that an ES forces the expert to articulate and
structure knowledge. In all the cases, the expert can revise his/her
own thinking to produce better solutions. In this way, the long-term
evolution then becomes one of joint growth of expert and system.
124.
Advantages of ExpertSystem
- Highly reproducible system
- Can be used for risky places where human
presence is not safe
- Error possibilities are less
- Performance remains steady as it is not
affected by emotions, tension etc.
- Quick response to a particular query
125.
Limitations of expertsystem
- Response may get wrong if KB contains wrong
information.
- Cannot produce creative output for different
scenario like human.
- High maintenance and development cost.
- Knowledge acquisition for designing is difficult.
- Cannot learn from itself. It requires manual
updates.
Knowledge
defined asthe body of facts and principles accumulated by
human being, or act or state of knowing.
Components of knowledge:
- Set of data
- Form of belief or hypothesis
- Kind of information
Knowledge consists of facts, beliefs and heuristics.
It is different from belief and hypothesis i.e.
- belief is any meaningful coherent expression that can be
expressed & may be true or false and
- hypothesis is a belief that is not known to be true.
128.
Types of Knowledge
-Domain specific knowledge: about a particular domain.
- Declarative knowledge: the knowledge, which gives the simple facts
about any organization or phenomenon. Facts may be static or
dynamic.
- Procedural knowledge: the procedural knowledge represent the
functioning of organization. It describes dynamic attributes using
production rules.
- Inheritable knowledge: based on relationships.
- Inferential knowledge: the knowledge which can use inference
mechanism to use the knowledge.
- Relational knowledge: in this type of knowledge, the facts are
represented as a set of relations in a tabular form.
- Heuristic knowledge: experimental, rarely discussed and
individualistic knowledge. This is more of a judgemental knowledge
of any performance.
129.
Types of Knowledge(cont..)
-Common sense knowledge: general contextual knowledge about any
phenomenon. It is gained by our experience. Unlike other knowledge,
it is domain independent knowledge.
- Explicit knowledge: the one which an individual holds explicitly and
which remains in ones conscious. It can be expressed clearly into
formal languages such as mathematical expression etc. explicit
knowledge is communicable to others, verbally or in stored form.
- Tacit knowledge: the form of knowledge that an individual possesses
about which he/she may or may not be aware of. This type of
knowledge is acquired by experience and involves intangible factors.
It is difficult to express in form of formal language.
Can be represented in two dimensions:
Technical dimension
Cognitive dimension
- Uncertain knowledge: it is uncertain and usually incomplete.
130.
Knowledge storage
- Machinereadable knowledge base
- Human readable knowledge base
Knowledge base consists:
- Factual knowledge
- Heuristic knowledge
131.
Knowledge Acquisition
- Thegathering of knowledge from various
sources is called Knowledge Acquisition.
- Also known as the process of eliciting,
collecting, analyzing, modeling and validating
knowledge for various knowledge engineering
and management process.
132.
Knowledge Creation orConversion
- From tacit to tacit (Socialization): means sharing experience to
create tacit knowledge since tacit knowledge in form of
experience.
- From explicit to tacit (Internalization): means written form of
knowledge into ones head. Knowledge is verbalized into
documents or oral stories.
- From tacit to explicit (Externalization): means articulating
knowledge in the head into communicable form through concepts,
hypothesis and models.
- From explicit to explicit (Combination): means transferring
knowledge through documents, meetings and conversations and
reconfiguration of knowledge by sorting, combining etc.
Knowledge Organization &
Management
-Indexed organization of knowledge
To keep the similar clusters together
Dataitem (k, m)
Property list
- Human Associative Memory System(HAM)
135.
Knowledge Engineering
- artof designing and building Knowledge-base system.
Techniques/activities:
- Assessment of problem
- Acquisition of knowledge from various sources
- Implement the knowledge from structured to specific form
- Testing & validate the knowledge
- Development of knowledge base
- Maintenance of the system
- Revise & evaluate the knowledge base
136.
Views of KE
-Transfer View
- Modeling View: facts & rules
137.
What is knowledgerepresentation?
• Humans are best at understanding, reasoning, and interpreting
knowledge. Human knows things, which is knowledge and as per their
knowledge they perform various actions in the real world.
• But how machines do all these things comes under knowledge
representation and reasoning.
So, Knowledge representation can be defined as follows:
• Knowledge representation and reasoning (KR, KRR) is the part of
Artificial intelligence which concerned with thinking and how thinking
contributes to intelligent behavior of agents.
• It is responsible for representing information about the real world so that
a computer can understand and can utilize this knowledge to solve the
complex real world problems.
• Knowledge representation is not just storing data into some database, but
it also enables an intelligent machine to learn from that knowledge and
experiences so that it can behave intelligently like a human.
138.
What to Represent:
•Object: All the facts about objects in our world domain.
• Events: Events are the actions which occur in our world.
• Performance: It describe behavior which involves knowledge about
how to do things.
• Meta-knowledge: It is knowledge about what we know.
• Facts: Facts are the truths about the real world and what we
represent.
• Knowledge-Base: The central component of the knowledge-based
agents is the knowledge base (KB).
The Knowledgebase is a group of the Sentences (Here, sentences are
used as a technical term and not identical with the English
language).
Reasoning
• The reasoningis the mental process of deriving
logical conclusion and making predictions from
available knowledge, facts, and beliefs.
• "Reasoning is a way to infer facts from existing
data." It is a general process of thinking
rationally, to find valid conclusions.
• In artificial intelligence, the reasoning is essential
so that the machine can also think rationally as a
human brain, and can perform like a human.
141.
Types of Reasoning
•Deductive reasoning
• Inductive reasoning
• Abductive reasoning
• Common Sense Reasoning
• Analogical reasoning
• Cause and Effect reasoning
• Critical thinking
• Decompositional reasoning
• Monotonic Reasoning
• Non-monotonic Reasoning
142.
Types of Reasoning(CONT…)
Deductivereasoning:
• Deductive reasoning is deducing new information from logically related
known information. It is the form of valid reasoning, which means the
argument's conclusion must be true when the premises are true.
• Deductive reasoning is a type of propositional logic, and it requires
various rules and facts. It is sometimes referred to as top-down reasoning,
and contradictory to inductive reasoning.
• In deductive reasoning, the truth of the premises guarantees the truth of the
conclusion.
• Deductive reasoning mostly starts from the general premises to the specific
conclusion as follows:
Example:
• Premise-1: All the human eats veggies
• Premise-2: Suresh is human.
• Conclusion: Suresh eats veggies.
143.
Types of Reasoning(CONT…)
InductiveReasoning:
• Inductive reasoning is a form of reasoning to arrive at a conclusion
using limited sets of facts by the process of generalization. It starts
with the series of specific facts or data and reaches to a general
statement or conclusion.
• Inductive reasoning is a type of propositional logic, which is also
known as cause-effect reasoning or bottom-up reasoning.
• In inductive reasoning, we use historical data or various premises to
generate a generic rule, for which premises support the conclusion.
• In inductive reasoning, premises provide probable supports to the
conclusion, so the truth of premises does not guarantee the truth of
the conclusion.
Example:
• Premise: All of the pigeons we have seen in the zoo are white.
• Conclusion: Therefore, we can expect all the pigeons to be white.
144.
Types of Reasoning(CONT…)
Abductivereasoning:
• Abductive reasoning is a form of logical reasoning which starts
with single or multiple observations then seeks to find the most
likely explanation or conclusion for the observation.
• Abductive reasoning is an extension of deductive reasoning, but
in abductive reasoning, the premises do not guarantee the
conclusion.
Example:
• Implication: Cricket ground is wet if it is raining
• Axiom: Cricket ground is wet.
• Conclusion: It is raining.
145.
Types of Reasoning(CONT…)
CommonSense Reasoning
• Common sense reasoning is an informal form of reasoning,
which can be gained through experiences.
• Common Sense reasoning simulates the human ability to
make presumptions about events which occurs on every day.
• It relies on good judgment rather than exact logic and
operates on heuristic knowledge and heuristic rules.
Example:
• One person can be at one place at a time.
• If I put my hand in a fire, then it will burn.
146.
Types of Reasoning(CONT…)
•Analogical reasoning:
Analogical reasoning is a form of thinking that finds similarities between two or
more things and then uses those characteristics to find other qualities common
to them.
• Cause-and-effect reasoning:
Cause-and-effect reasoning is a type of thinking in which the linkage is specified
between two events. This reasoning is used to explain what may happen if an
action takes place or why things happen when some conditions are present.
• Critical thinking:
Critical thinking involves extensive rational thought about a specific subject in
order to come to a definitive conclusion.
• Decompositional reasoning:
Decompositional reasoning is the process of breaking things into constituent
parts to understand the function of each component and how it contributes to
the operation of the item as a whole.
147.
Types of Reasoning(CONT…)
MonotonicReasoning:
• In monotonic reasoning, once the conclusion is taken, then it will
remain the same even if we add some other information to existing
information in our knowledge base.
• In monotonic reasoning, adding knowledge does not decrease the set
of prepositions that can be derived.
• To solve monotonic problems, the valid conclusion can be drawn
from the available facts only, and it will not be affected by new facts.
• Monotonic reasoning is not useful for the real-time systems, as in
real time, facts get changed, so we cannot use monotonic reasoning.
• Monotonic reasoning is used in conventional reasoning systems, and
a logic-based system is monotonic.
• Any theorem proving is an example of monotonic reasoning.
148.
Advantages of MonotonicReasoning:
• In monotonic reasoning, each old proof will always remain valid.
• If we deduce some facts from available facts, then it will remain
valid for always.
Disadvantages of Monotonic Reasoning:
• We cannot represent the real world scenarios using Monotonic
reasoning.
• Hypothesis knowledge cannot be expressed with monotonic
reasoning, which means facts should be true.
• Since we can only derive conclusions from the old proofs, so new
knowledge from the real world cannot be added.
149.
Types of Reasoning(CONT…)
Non-monotonicReasoning
• In Non-monotonic reasoning, some conclusions may be invalidated if we add
some more information to our knowledge base.
• Logic will be said as non-monotonic if some conclusions can be invalidated
by adding more knowledge into our knowledge base.
• Non-monotonic reasoning deals with incomplete and uncertain models.
• "Human perceptions for various things in daily life, "is a general example of
non-monotonic reasoning.
Example:
• Birds can fly
• Penguins cannot fly
• Kane is a bird
So, we can conclude that Kane can fly.
However, if we add one another sentence into knowledge base “Kane is a
penguin", which concludes “Kane cannot fly", so it invalidates the above
conclusion.
150.
Advantages of Non-monotonicreasoning:
• For real-world systems such as Robot navigation,
we can use non-monotonic reasoning.
• In Non-monotonic reasoning, we can choose
probabilistic facts or can make assumptions.
Disadvantages of Non-monotonic Reasoning:
• In non-monotonic reasoning, the old facts may be
invalidated by adding new sentences.
• It cannot be used for theorem proving.
151.
Knowledge Representation basedon
logic(Monotonic Reasoning)
• Logic is the expression given to the reasoning
process performed by mind in form of symbolic
language of a calculus.
• In context of AI, logic is a language used to
represent facts.
152.
Logical Representation
• Logicalrepresentation is a language with some
concrete rules which deals with propositions and
has no ambiguity in representation.
• Logical representation means drawing a
conclusion based on various conditions.
• It consists of precisely defined syntax and
semantics which supports the sound inference.
Each sentence can be translated into logics
using syntax and semantics.
153.
Logical Representation
Syntax:
• Syntaxesare the rules which decide how we can construct
legal sentences in the logic.
• It determines which symbol we can use in knowledge
representation.
• How to write those symbols.
Semantics:
• Semantics are the rules by which we can interpret the
sentence in the logic.
• Semantic also involves assigning a meaning to each sentence.
Propositional logic
• Propositionallogic (PL) is the simplest form of logic
where all the statements are made by propositions.
• A proposition is a declarative statement which is
either true or false.
• It is a technique of knowledge representation in
logical and mathematical form.
For example:
- New Delhi is the capital of India.(True)
- The Sun rises from west. (False)
156.
Propositional logic
There aretwo types of Propositions:
• Atomic Proposition: Atomic propositions are
the simple propositions. It consists of a single
proposition symbol. These are the sentences
which must be either true or false.
• Compound proposition: Compound
propositions are constructed by combining
simpler or atomic propositions, using
parenthesis and logical connectives.
157.
Syntax of Propositionallogic
Atomic symbol
• Logical connectives: are used to connect two simpler propositions
or representing a sentence logically. We can create compound
propositions with the help of logical connectives. There are mainly
five connectives, which are given as follows:
Negation: A sentence such as ¬ P is called negation of P. A literal
can be either Positive literal or negative literal.
Conjunction: A sentence which has ∧ connective such as, P ∧
Q is called a conjunction.
158.
Syntax of Propositionallogic
Disjunction: A sentence which has connective, such as
∨ P
Q
∨ . is called disjunction, where P and Q are the
propositions.
Implication: A sentence such as P → Q, is called an
implication. Implications are also known as if-then rules.
Biconditional: A sentence such as P Q is a Biconditional
⇔
sentence if both are same.
Equivalence: When both P and Q are equal.
159.
Facts about propositionalLogic
• Propositional logic is also called Boolean logic as it
works on 0 and 1.
• In propositional logic, we use symbolic variables to
represent the logic, and we can use any symbol for a
representing a proposition, such A, B, C, P etc.
• Propositions can be either true or false, but it cannot
be both.
• Propositional logic consists of an object, relations or
function, and logical connectives.
• These connectives are also called logical operators.
• The propositions and connectives are the basic
elements of the propositional logic.
160.
Facts about propositionalLogic
• Connectives can be said as a logical operator which
connects two sentences.
• A proposition formula which is always true is
called tautology, and it is also called a valid sentence.
• A proposition formula which is always false is
called Contradiction.
• A proposition formula which has both true and false values is
called Logical consequence
• Statements which are questions, commands, or opinions are
not propositions such as "Where is Rohini", "How are you",
"What is your name", are not propositions.
161.
Properties of statements
•Valid
• Satisfiable
• Unsatisfiable or Contradiction
• Equivalence
• Logical Consequence
162.
Limitation of Propositionallogic
• We cannot represent relations like ALL, some, or
none with propositional logic. Example:
– All the girls are intelligent.
– Some apples are sweet.
• Propositional logic has limited expressive power.
• In propositional logic, we cannot describe
statements in terms of their properties or logical
relationships.
163.
Predicate logic
First-orderlogic is another way of knowledge representation in artificial intelligence
and FOL is sufficiently expressive to represent the natural language statements in a
concise way.
First-order logic is also known as Predicate logic or First-order predicate logic.
First-order logic is a powerful language that develops information about the objects
in a more easy way and can also express the relationship between those objects.
First-order logic (like natural language) does not only assume that the world
contains facts like propositional logic but also assumes the following things in the
world:
– Objects: A, B, people, numbers, colors, wars, theories, squares, ......
– Relations: It can be unary relation such as: red, round, is adjacent, or n-any
relation such as: the sister of, brother of, has color, comes between
– Function: Father of, best friend, third inning of, end of, ......
As a natural language, first-order logic also has two main parts:
– Syntax
– Semantics
164.
Predicate logic characteristics
Ithas sound theoretical foundation.
Inferencing can be applied in Predicate logic.
It allows accurate representation of real world
facts.
It is commonly used for program design.
A predicate that has no variable is called a
ground axiom.
Syntax of Predicatelogic
Atomic sentences:
• Atomic sentences are the most basic sentences of first-order logic. These
sentences are formed from a predicate symbol followed by a parenthesis with a
sequence of terms.
• We can represent atomic sentences as Predicate (term1, term2, ......, term n).
Example: Ravi and Ajay are brothers: => Brothers(Ravi, Ajay).
Chinky is a cat: => cat (Chinky).
Complex Sentences:
• Complex sentences are made by combining atomic sentences using connectives.
First-order logic statements can be divided into two parts:
• Subject: Subject is the main part of the statement.
• Predicate: A predicate can be defined as a relation, which binds two atoms
together in a statement.
Consider the statement: "x is an integer.", it consists of two parts, the first part x is
the subject of the statement and second part "is an integer," is known as a
predicate.
167.
Syntax of Predicatelogic
Quantifiers in First-order logic:
• A quantifier is a language element which generates
quantification, and quantification specifies the
quantity of specimen in the universe of discourse.
• These are the symbols that permit to determine or
identify the range and scope of the variable in the
logical expression. There are two types of quantifier:
– Universal Quantifier, (for all, everyone, everything)
– Existential quantifier, (for some, at least one).
168.
quantifiers
Universal Quantifier:
• Universalquantifier is a symbol of logical
representation, which specifies that the statement
within its range is true for everything or every instance
of a particular thing.
• The Universal quantifier is represented by a symbol ,
∀
which resembles an inverted A.
∀x man(x) → drink (x, coffee).
• It will be read as: There are all x where x is a man who
drink coffee.
169.
quantifiers
Existential Quantifier:
• Existentialquantifiers are the type of quantifiers, which
express that the statement within its scope is true for at
least one instance of something.
• It is denoted by the logical operator , which resembles
∃
as inverted E. When it is used with a predicate variable
then it is called as an existential quantifier.
∃x, : boys(x) intelligent(x)
∧
• It will be read as: There are some x where x is a boy
who is intelligent.
170.
Semantics of Predicatelogic
• Interpretation
• Truth value of FOL expression
• Use of quantifiers
171.
Inference rules
• Inferencerules are the templates for generating valid arguments.
Inference rules are applied to derive proofs in artificial intelligence, and
the proof is a sequence of the conclusion that leads to the desired goal.
• In inference rules, the implication among all the connectives plays an
important role. Following are some terminologies related to inference
rules:
• Implication: It is one of the logical connectives which can be
represented as P → Q. It is a Boolean expression.
• Converse: The converse of implication, which means the right-hand side
proposition goes to the left-hand side and vice-versa. It can be written as
Q → P.
• Contrapositive: The negation of converse is termed as contrapositive,
and it can be represented as ¬ Q → ¬ P.
• Inverse: The negation of implication is called inverse. It can be
represented as ¬ P → ¬ Q.
172.
Types of Inferencerules:
1. Modus Ponens:
• The Modus Ponens rule is one of the most important rules
of inference, and it states that if P and P → Q is true, then
we can infer that Q will be true. It can be represented as:
Example:
• Statement-1: "If I am sleepy then I go to bed" ==> P→ Q
Statement-2: "I am sleepy" ==> P
Conclusion: "I go to bed." ==> Q.
Hence, we can say that, if P→ Q is true and P is true then
Q will be true.
173.
Types of Inferencerules:
2. Modus Tollens:
• The Modus Tollens rule state that if P→ Q is
true and ¬ Q is true, then ¬ P will also true. It
can be represented as:
• Statement-1: "If I am sleepy then I go to bed"
==> P→ Q
Statement-2: "I do not go to the bed."==> ~Q
Statement-3: Which infers that "I am not
sleepy" => ~P
174.
Types of Inferencerules:
3. Hypothetical Syllogism:
• The Hypothetical Syllogism rule state that if P→R is true
whenever P→Q is true, and Q→R is true. It can be
represented as the following notation:
Example:
• Statement-1: If you have my home key then you can unlock
my home. P→Q
Statement-2: If you can unlock my home then you can take
my money. Q→R
Conclusion: If you have my home key then you can take my
money. P→R
175.
Types of Inferencerules:
4. Disjunctive Syllogism:
• The Disjunctive syllogism rule state that if P Q
∨
is true, and ¬P is true, then Q will be true. It can
be represented as
Example:
• Statement-1: Today is Sunday or Monday.
==>P Q
∨
Statement-2: Today is not Sunday. ==> ¬P
Conclusion: Today is Monday. ==> Q
176.
Types of Inferencerules:
5. Addition:
• The Addition rule is one the common inference
rule, and it states that If P is true, then P Q will
∨
be true.
Example:
• Statement: I have a vanilla ice-cream. ==> P
Statement-2: I have Chocolate ice-cream.
Conclusion: I have vanilla or chocolate ice-
cream. ==> (P Q)
∨
177.
Types of Inferencerules:
6. Simplification:
• The simplification rule state that if P Q
∧ is true,
then Q or P will also be true.
7. Resolution:
• The Resolution rule state that if P Q and ¬ P R
∨ ∧
is true, then Q R will also be true.
∨
8. Conjunction:
• For any two given statements P and Q, infer P Q
∧
178.
resolution
• Resolution isa theorem proving technique that proceeds by building
refutation proofs, i.e., proofs by contradictions. It was invented by a
Mathematician John Alan Robinson in the year 1965.
• Resolution is used, if there are various statements given, and we need
to prove a conclusion of those statements. Unification is a key
concept in proofs by resolutions. Resolution is a single inference rule
which can efficiently operate on the conjunctive normal form or
clausal form.
• Clause: Disjunction of literals (an atomic sentence) is called
a clause. It is also known as a unit clause.
• Conjunctive Normal Form: A sentence represented as a conjunction
of clauses is said to be conjunctive normal form or CNF.
Resolution
Steps for Resolution:
•Conversion of facts into first-order logic.
• Convert FOL statements into CNF
• Negate the statement which needs to prove
(proof by contradiction)
• Draw resolution graph (unification).
181.
Resolution
Example:
• John likesall kind of food.
• Apple and vegetable are food
• Anything anyone eats and not killed is food.
• Anil eats peanuts and still alive
• Harry eats everything that Anil eats.
Prove by resolution that:
• John likes peanuts.
Resolution
Step-2: Conversion of
FOLinto CNF
• In First order logic
resolution, it is required
to convert the FOL into
CNF as CNF form
makes easier for
resolution proofs.
• Eliminate all implication
(→) and rewrite
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ food(vegetables)
– ∀x y ¬ [eats(x, y)
∀ Λ ¬
killed(x)] V food(y)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀x ¬ eats(Anil, x) V eats(Harry,
x)
– ∀x¬ [¬ killed(x) ] V alive(x)
– ∀x ¬ alive(x) V ¬ killed(x)
– likes(John, Peanuts).
184.
Resolution
• Move negation(¬)inwards
and rewrite
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ
food(vegetables)
– ∀x y ¬ eats(x, y) V
∀
killed(x) V food(y)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀x ¬ eats(Anil, x) V
eats(Harry, x)
– ∀x ¬killed(x) ] V alive(x)
– ∀x ¬ alive(x) V ¬ killed(x)
– likes(John, Peanuts).
• Rename variables or
standardize variables
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ
food(vegetables)
– ∀y z ¬ eats(y, z) V killed(y)
∀
V food(z)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀w¬ eats(Anil, w) V
eats(Harry, w)
– ∀g ¬killed(g) ] V alive(g)
– ∀k ¬ alive(k) V ¬ killed(k)
– likes(John, Peanuts).
185.
Resolution
• Eliminate existential
instantiationquantifier by
elimination.
In this step, we will
eliminate existential
quantifier , and this process
∃
is known as Skolemization.
• But in this example problem
since there is no existential
quantifier so all the
statements will remain same
in this step.
• Drop Universal quantifiers.
In this step we will drop all
universal quantifier since all the
statements are not implicitly
quantified so we don't need it.
– ¬ food(x) V likes(John, x)
– food(Apple)
– food(vegetables)
– ¬ eats(y, z) V killed(y) V food(z)
– eats (Anil, Peanuts)
– alive(Anil)
– ¬ eats(Anil, w) V eats(Harry, w)
– killed(g) V alive(g)
– ¬ alive(k) V ¬ killed(k)
– likes(John, Peanuts).
186.
Resolution
• Distribute conjunction
overdisjunction ¬.
∧
This step will not make
any change in this
problem.
Step-3: Negate the
statement to be proved
• In this statement, we
will apply negation to
the conclusion
statements, which will
be written as
¬likes(John, Peanuts)
• Step-4: Draw
Resolution graph:
What is Unification?
•Unification is a process of making two different logical atomic
expressions identical by finding a substitution. Unification
depends on the substitution process.
• It takes two literals as input and makes them identical using
substitution.
• Let Ψ1 and Ψ2 be two atomic sentences and be a unifier such
𝜎
that, Ψ1 = Ψ
𝜎 2𝜎, then it can be expressed as UNIFY(Ψ1, Ψ2).
• The UNIFY algorithm is used for unification, which takes two
atomic sentences and returns a unifier for those sentences (If any
exist).
• Unification is a key component of all first-order inference
algorithms.
• It returns fail if the expressions do not match with each other.
• The substitution variables are called Most General Unifier or
MGU.
189.
UNIFY ALGORITHM
• Step.1: If Ψ1 or Ψ2 is a variable or constant, then: a) If Ψ1 or Ψ2 are identical,
then return NIL. b) Else if Ψ1is a variable, a. then if Ψ1 occurs in Ψ2, then return
FAILURE b. Else return { (Ψ2/ Ψ1)}. c) Else if Ψ2 is a variable, a. If Ψ2 occurs in
Ψ1 then return FAILURE, b. Else return {( Ψ1/ Ψ2)}. d) Else return FAILURE.
• Step.2: If the initial Predicate symbol in Ψ1 and Ψ2 are not same, then return
FAILURE.
• Step. 3: IF Ψ1 and Ψ2 have a different number of arguments, then return
FAILURE.
• Step. 4: Set Substitution set(SUBST) to NIL.
• Step. 5: For i=1 to the number of elements in Ψ1. a) Call Unify function with the
ith element of Ψ1 and ith element of Ψ2, and put the result into S. b) If S = failure
then returns Failure c) If S ≠ NIL then do, a. Apply S to the remainder of both L1
and L2. b. SUBST= APPEND(S, SUBST).
• Step.6: Return SUBST.
Limitations of logic
•Theorem proving takes too long time.
• Logic is not suitable for different kinds of
knowledge i.e it cannot represent facts which have
multiple values.
• Logic cannot represent uncertain situations.
• Heuristic information cannot be represented by
logic.
• The knowledge involving user’s belief cannot be
represented using logic.
192.
Knowledge representation based
onrules
• Knowledge representation concentrates on the use of logical
assertions.
• In logic, logical assertions are in declarative form i.e declarative
representation of knowledge in which knowledge is specified but
the use to which that knowledge is to be put is not given.
• To use a declarative representation, we must augment it with
program that specifies what is to be done to the knowledge and
how.
• In this approach, logical assertions can be viewed as program
rather than data to a program. This can be considered as
procedural representation of knowledge.
193.
Knowledge representation based
onrules
In knowledge representation based on rules, propositions
and predicates are used to encode knowledge of rule based
systems.
Two categories of representations are used in rule-based
knowledge base:
- Declarative representation: consists of facts and logical
assertions about the problem. The set of logical assertion
can be combined with resolution.
- Procedural representation: It is one in which the control
information that is necessary to use the knowledge is
considered to be embedded in knowledge itself.
194.
Knowledge representation based
onrules
Forward and Backward Reasoning:
These are the techniques to implement the
search procedures from initial to goal state.
These are also known as forward and
backward chaining respectively. Inference
engine also proceeds in these modes.
Forward chaining starts from start state.
Backward chaining starts from goal state.
195.
Forward Chaining
Forwardchaining is a form of reasoning which start with atomic
sentences in the knowledge base and applies inference rules
(Modus Ponens) in the forward direction to extract more data
until a goal is reached.
The Forward-chaining algorithm starts from known facts, triggers
all rules whose premises are satisfied, and add their conclusion to
the known facts. This process repeats until the problem is solved.
Properties of Forward-Chaining:
• It is a Bottom-up approach, as it moves from bottom to top.
• It is a process of making a conclusion based on known facts or
data, by starting from the initial state and reaches the goal state.
• Forward-chaining approach is also called as data-driven as we
reach to the goal using available data.
• Forward -chaining approach is commonly used in the expert
system, such as CLIPS, business, and production rule systems.
196.
Backward Chaining
Abackward chaining algorithm is a form of reasoning, which
starts with the goal and works backward, chaining through rules
to find known facts that support the goal.
Properties of backward chaining:
• It is known as a top-down approach.
• Backward-chaining is based on modus ponens inference rule.
• In backward chaining, the goal is broken into sub-goal or sub-
goals to prove the facts true.
• It is called a goal-driven approach, as a list of goals decides
which rules are selected and used.
• Backward -chaining algorithm is used in game theory, automated
theorem proving tools, inference engines, proof assistants etc.
• The backward-chaining method mostly used a depth-first
search strategy for proof.
197.
Differences b/w Forward&
Backward Chaining
Forward Chaining Backward Chaining
1. Forward chaining starts from known facts and
applies inference rule to extract more data unit it
reaches to the goal.
Backward chaining starts from the goal and works
backward through inference rules to find the required
facts that support the goal.
2. It is a bottom-up approach It is a top-down approach
3. Forward chaining is known as data-driven
inference technique as we reach to the goal using
the available data.
Backward chaining is known as goal-driven technique
as we start from the goal and divide into sub-goal to
extract the facts.
4. Forward chaining reasoning applies a breadth-first
search strategy.
Backward chaining reasoning applies a depth-first
search strategy.
5. Forward chaining tests for all the available rules Backward chaining only tests for few required rules.
6. Forward chaining is suitable for the planning,
monitoring, control, and interpretation application.
Backward chaining is suitable for diagnostic,
prescription, and debugging application.
7. Forward chaining can generate an infinite number
of possible conclusions.
Backward chaining generates a finite number of
possible conclusions.
8. It operates in the forward direction. It operates in the backward direction.
9. Forward chaining is aimed for any conclusion. Backward chaining is only aimed for the required
data.
198.
Matching
Matching is theprocess to find which rules are
applicable, the current state of the problem
and whether the precondition are matched or
not.
Matching techniques:
- Indexing
- Matching with variables
- Complex and Approximate matching
199.
Backtracking in Matching
Theprocess to find out the alternate path when
no exact goal found is named as backtracking.
Predicates used for backtracking:
- Cut: Not possible to return to find an alternate
path.
- Fail: it returns all possible answers one after
the other.
Conflict Resolution
In productionsystem, control structure allows only
one rule to fire in one cycle. If more than one rules
are found to be applicable, then a situation named
‘conflict’ occurs.
In the situation of conflict, control structure must
determine which rule to fire from this conflict set of
active rules. This selection is called ‘conflict
resolution’.
It is the job of search method to decide on the order
in which rules will be applied.
202.
Conflict Resolution Strategies
Basicapproaches for conflict resolution:
Preference based on rule that matched
Preference based on objects that matched
Preference based on the action that the matched rule
would perform
Preference based on priority
preference based on maximum number of matched
condition
Preference based on most recently used and added
Preference based on random selection
203.
Non-monotonic Reasoning
• Thereasoning in which uncertainty present and
the process carried out with beliefs, justifications,
hypothesis and evidences.
• Not complete with respect to the domain of
interest.
• Not consistent or inconsistent in nature
• Consists reasoning based on uncertainty and
probability
204.
Dealing with Uncertainty
Differenttypes of uncertainty which are
common:
- Uncertain knowledge
- Uncertain data
- Incomplete information
- Randomness
For all these types of uncertainty, non-
monotonic reasoning is required
205.
Dealing with Uncertainty
•The problem are to be solved on the basis of
beliefs that are subject to change the given
information.
• Tentative beliefs are generally based on
default assumptions that are made in light of
the lack of evidences.
• For each tentative belief, justifications are to
be drawn.
206.
Logics for non-monotonic
reasoning
•Non-monotonic reasoning is performed on the
basis of Default reasoning where conclusions are to
be drawn based on what is most likely to be true.
• Approaches for non-monotonic reasoning:
- Non-monotonic logic: with Modal operator
- Default Logic: A:B/C=> A is provable and
consistent to assume B then conclude C
Abduction
Inheritance
207.
Truth maintenance system
•TMS is an implementation of NMRS.
• It operates as a knowledge base management system
and every time the reasoning system generates a new
truth value.
• TMS takes any action required to modify dependent
beliefs to maintain consistency in Knowledge base.
• It’s role is purely passive; it never initiates generation
of inferences.
• In TMS, a node represents one unit of knowledge: a
fact, rule, or assertion.
208.
Truth maintenance system
•At any point in execution, every node is in one of two
conditions.
IN: Currently believed to be true
OUT: Currently believed to be false. A node can be out
because there is no possible condition that would make it true.
INFERENCE ENGINE TRUTH MAINTENANCE SYSTEM
KNOWLEDGE BASE
209.
Truth maintenance system
•Support List Justification: Support associated with each node are known as
justification for the node’s truth value.
• For each node that is IN, TMS records a well-founded support: proof of the validity
of the node, starting from the system’s facts and justifications.
For example:
1. It is sunny.
2. It is daytime.
3. It is raining.
4. It is warm.
Node No. Knowledge Justification
5. It is sunny [SL(2) (3)(4)]
6. It is day time [SL() ()]
7. It is raining [SL() (1)]
8. It is warm [SL(1)(4)]
IN: (1, 2, 4)
OUT: (3)
210.
Truth maintenance system
•Different types of nodes can be justified by a
support list:
- Premise: A premise is a fact that is always valid.
- Normal deduction: It is an inference that is
formed in the normal sense of a monotonic
system.
- Assumption: An assumption is a belief that is
supported by the lack of contrary information.
211.
Truth maintenance system
•Conditional Proof Justifications: A conditional
proof is second type of justification that is used
to support hypothetical reasoning.
• Format of a CP is: [CP(consequent)
(in_hypothesis)]
• A CP justification is valid if and only if the
consequent node is IN whenever all of the
nodes on in_hypothesis are IN.
212.
Truth maintenance system
Typesof Truth maintenance System:
- Justification based TMS: TMS itself does not
know anything about the structure of assertion
themselves.
- Assumption based TMS: Alternative paths are
maintained in parallel.
- Logic based TMS: A contradiction would be
asserted automatically
213.
Murder in hotelroom
• A: His brother said he was with me
• B : I was out of city
• C: he was in the city
• C is murderer….. Hypothesis
• Evidences….. No evidence against c, evidences
shows the presence of B
214.
Probabilistic Reasoning
• Probabilisticreasoning is a way of knowledge representation where we
apply the concept of probability to indicate the uncertainty in knowledge.
• In probabilistic reasoning, we combine probability theory with logic to
handle the uncertainty.
• This is a method that can be used to strengthen knowledge representation
techniques with statistical measures that describe levels of evidence and
belief.
Need of probabilistic reasoning in AI:
• When there are unpredictable outcomes.
• When specifications or possibilities of predicates becomes too large to
handle.
• When an unknown error occurs during an experiment.
215.
Probabilistic Reasoning
Common termsrelated to probabilistic reasoning:
• Probability: Probability can be defined as a chance that an uncertain event
will occur. It is the numerical measure of the likelihood that an event will
occur. The value of probability always remains between 0 and 1 that represent
ideal uncertainties.
• Event: Each possible outcome of a variable is called an event.
• Sample space: The collection of all possible events is called sample space.
• Random variables: Random variables are used to represent the events and
objects in the real world.
• Prior probability: The prior probability of an event is probability computed
before observing new information. P(event)
• Posterior Probability: The probability that is calculated after all evidence or
information has taken into account. It is a combination of prior probability
and new information. P(event|evidence)
• Conditional probability: Conditional probability is a probability of occurring
an event when another event has already happened.
216.
Probability and bayes’theorem
•Bayes' theorem is also known as Bayes' rule, Bayes' law,
or Bayesian reasoning, which determines the probability of
an event with uncertain knowledge.
• Bayes' theorem was named after the British
mathematician Thomas Bayes. The Bayesian inference is an
application of Bayes' theorem, which is fundamental to
Bayesian statistics.
• It is a way to calculate the value of P(B|A) with the
knowledge of P(A|B).
• Bayes’Theorem states that
• P(HiE) =
217.
The patient hasmeasles
• Patient has spots on the body=evidences
• Patient has fever= evidences
218.
CERtainty factor
• Certaintyfactor is an informal mechanism for quantifying the
degree to which we believe/disbelieve a given conclusion based on
the presence of given set of evidences.
• A certainty factor(CF[h,e]) is defined in terms of two components:
- MB[h,e]: a measure(between 0 and 1) of belief in hypothesis h
given the evidences e. MB measures the extent to which the
evidence support the hypothesis. It is zero if the evidence fails to
support the hypothesis.
- MD[h,e]: a measure(between 0 and 1) of disbelief in hypothesis h
given the evidences e. MD measures the extent to which the
evidence support the negation of hypothesis. It is zero if the
evidence support the hypothesis.
From these measures, certainty factor is defined as:
CF(h,e) = MB[h,e] - MD[h,e]
219.
Bayesian Network
• ABayesian network is a probabilistic graphical model which
represents a set of variables and their conditional dependencies
using a directed acyclic graph.
• It is also called a Bayes network, belief network, decision
network, or Bayesian model.
• Bayesian networks are probabilistic, because these networks are
built from a probability distribution, and also use probability
theory for prediction and anomaly detection.
• Bayesian Network can be used for building models from data and
experts opinions, and it consists of two parts:
Directed Acyclic Graph
Table of conditional probabilities.
• The generalized form of Bayesian network that represents and
solve decision problems under uncertain knowledge is known as
an Influence diagram.
220.
Bayesian Network
• ABayesian network graph is made up of nodes and Arcs
(directed links), where:
• Each node corresponds to the random variables, and a
variable can be continuous or discrete.
• Arc or directed arrows represent the causal relationship or
conditional probabilities between random variables. These
directed links or arrows connect the pair of nodes in the
graph.
These links represent that one node directly influence the
other node, and if there is no directed link that means that
nodes are independent with each other.
221.
Bayesian Network
– Inthe above diagram, A, B, C, and D are random variables represented
by the nodes of the network graph.
– If we are considering node B, which is connected with node A by a
directed arrow, then node A is called the parent of Node B.
– Node D is independent of node A.
Rainy Season (A)
Sprinkles(B) Rain(C)
Wet(D)
222.
Dempster-shafer theory
Thisalternative approach considers sets of propositions and
assigns to each of them an interval:
[Belief, Plausibility]
In which the degree of belief must be lie. Belief measures the
strength of evidence in favor of a set of propositions.
It ranges from 0 (indicating no evidence) to 1(denoting certainty).
Plausibility is defined as:
Pl(s) = 1-Bel(¬s)
Frame of Discernment(Θ) is used to check the evidences related to
hypothesis.
For example: [Flu, Cold, Pneu] = 0.6 Θ = 0.4
Semantic Network
• Asemantic net is a graphical knowledge representation
scheme primarily based on network structure.
• It focuses on the graphical representation of relations
between elements in a domain.
• Its basic components are nodes and links.
• Nodes are used to represent domain elements. They are
shown graphically as rectangle and are labeled with name of
represented elements.
• Links or arcs represent relations between elements. A link is
shown as a vector from one node to another. It is labeled
with the name of relation.
Semantic Network(cont….)
Reasoning withSemantic network:
Reasoning is generally straightforward
because associations can be made simply by
tracing the linkages in the system.
Property inheritance is used to make the
inferences.
227.
Frame
• Frame wasintroduced by Marvin Minsky in 1975.
• It is a method to represent conceptual and commonsense
knowledge.
• Frames are used to represent a mental model of a
stereotypical situation.
• It is a structure for organizing knowledge-with an emphasis
on default knowledge.
• Each frame represents a class of elements.
• A frame consists a series of slots each of which represents a
standard property or attribute of the element represented by
frame.
228.
Frame(Cont….)
• Thus, aframe is a data structure that has slots for various objects
and these slots contain some values.
• Each slot is identified by the name of corresponding attribute and
includes the value, or range of values, that can be associated with
the slot.
• A default value for the slot may also be indicated.
• Types of frames:
A frame that consists only descriptive type of knowledge is known
as declarative frame.
Besides declarative knowledge, a frame may consists of knowledge
about the actions or procedures. These types of frame are known as
procedural frame.
229.
Frame(Cont….)
• A normalframe consists of slots for:
- actor: which holds the information about who is performing the activity
- Object: giving the information about the item to be operated on
- Source slot: holds the information from where the action has to begin
- Destination slot: holds the information about the place where action has
to end
• A general frame structure is:
(<frame name>
(<slot1> (Facet1 <value1>……<value k>)
(Facet2 <value1>……<value k>)
(Facet3 <value1>……<value k>)
…………
(Facet n <value1>……<value k>)
230.
Frame(Cont….)
Frame: Car
Specialization of:Land Vehicle
Model:
Range: (Sedan, convertible)
Default: Sedan
Body: Steel
Windows: glass
Mobility Mechanism: has wheels
Tires: rubber
Fuel:
Range: (Petrol, Diesel)
Default: Petrol
Fuel Remaining:
Range: (empty, ¼ tank, ½ tank, full)
Default: none
IF-NEEDED: check fuel guage
Number of Seats: (1-7)
Default: None
231.
Frame(Cont….)
Reasoning with frames:
Frame system allow to reason even though the
information available is incomplete.
It allows to infer facts that are not explicitly observed
Firstly, select a frame to represent the current situation.
Then, instantiate the selected frame on the basis of the
specific current conditions.
Lastly, knowledge can be defined with the specific
individual characteristics to generic class description.
232.
Script
Script, specializationof frame, is a structure that is used to store
prototypes of expected sequences of events.
Various components are used to construct a script:
- Entry condition: the conditions that must exist for the script to
be applicable.
- Script result: conditions that will be true after the events in the
script have occurred.
- Props: slots that represent objects that are involved in the script.
- Roles: slots that represent agents that perform actions in the
script.
- Scenes: specific sequences of events that make up the script.
233.
Script(cont…)
Script: TRIP TOZOO
Props:
Car
Keys
Parking space
Roles:
Owner
Valet
Entry Conditions:
Owner & Car at start point
Results:
Owner & Car at zoo
Scene 1: START UP
-Owner finds keys
-Unlock car door
-Starts car
-Place car in gear & release parking brake
Scene 2: DRIVE
-Owner finds opening in traffic
-Enters traffic & drives to Zoo
Scene 3: VALET CONTACT
-Owner stops car & exits car
-Gives keys to valet
Scene 4: VALET PARKING
-Valet enters car
-Finds empty parking space & enters parking space
-Stops car & sets parking brake
-Exits car
234.
Reasoning with ScripT
Firstly,select an appropriate script.
Selection process can be best-fit match between
observed conditions and entry conditions of
script.
Useful to view the event sequences as a series of
cause-effect relations that establish a causal
chain.
Not reliable for predicting future events on the
basis of scene.
Perception
Perception inAI is the process of interpreting vision, sounds, smell, and
touch. Perception helps to build machines or robots that react like
humans.
Perception is a process to interpret, acquire, select and then organize
the sensory information that is captured from the real world to make
actions like humans.
For example: Human beings have sensory receptors such as touch,
taste, smell, sight and sound. So, the information received from these
receptors is transmitted to human brain to organize the received
information.
According to the received information, action is taken by interacting
with the environment to manipulate and navigate the object.
237.
Vision
• It opensup a new realm of computer applications.
• These applications include mobile robot navigation, manufacturing
task, analysis and processing of images.
• Operations performed on images:
- Signal processing: enhancing the image
- Measurement analysis: for images containing a single object,
determining the 2-D extent of the object depicted
- Pattern recognition: for single object images, classifying the object
into a category drawn from a finite set of possibilities.
- Image understanding: for image containing many objects, locating
the objects in the image, classifying them and building a 3-D model
of the scene
238.
Vision(Cont…)
•Natural scene imagecaptured by sensor
•2-D image collection from light sensitive surface
•Digitization of usage(local processing low level)
•smoothing
•Intermediate level
•Connecting, filling in, combining boundaries, determining regions and assigning descriptive label to objects
•Knowledge storage data structure
•High level image processing( identify the important objects in the image and convert them in well formed knowledge structure.
239.
Speech recognition
• Speechrecognition is one such technology that is empowered by
AI to add convenience to its users. This technology has the
power to convert voice messages to text. And it also has the
ability to recognize an individual based on their voice command.
• It provides interface for human-computer communication.
• Accuracy measurement of speech recognition systems:
- Speaker dependence vs speaker independence
- Continuous vs isolated-word speech
- Real-time vs offline processing
- Broad vs narrow grammar
- Large vs small vocabulary


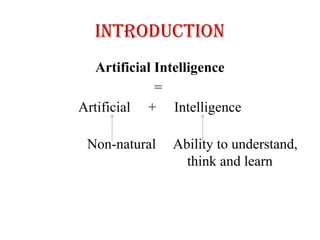




![Artificial Intelligence
• The term Artificial Intelligence was coined by McCarthy in 1956.
• According to John McCarthy(1956), Artificial Intelligence is “The science
and engineering of making intelligent machines, especially intelligent
computer programs”.
• AI is the study of how to make computers do things at which, at the moment,
people are better. [Rich & Knight]
• AI is the art of making computers or machine do smart things.
[Waldrop]
• AI is the activity of providing such machines as computers with the ability to
display behavior that would be regarded as intelligent if it were observed in
humans. [R. McLoed]
• A field that focuses on developing techniques to enable computer systems to
perform activities that are considered intelligent (in humans and other
animals). [Dyer]](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-7-320.jpg)
![Artificial Intelligence
• AI is the study of the combinations that make it possible to
perceive, reason and act. [Winston]
• Computational Intelligence is the study of the design of
intelligent agents. [Poole]
• Artificial Intelligence is the study and design of intelligent
agents, where an intelligent agent is a system that perceives its
environment and takes actions that maximize its chance of
success.
Artificial Intelligence is the branch of engineering employed for
the creation of computers that possess some form of intelligence
and can be used to solve real world problems and functions within
a domain](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-8-320.jpg)



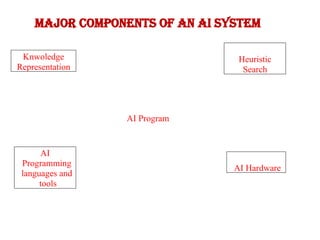






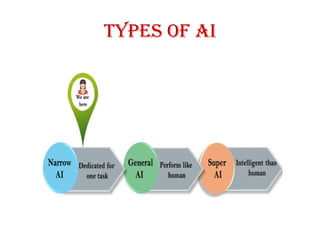



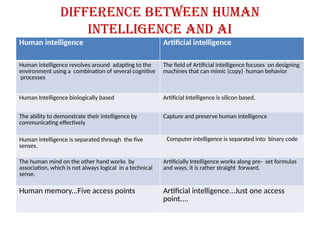



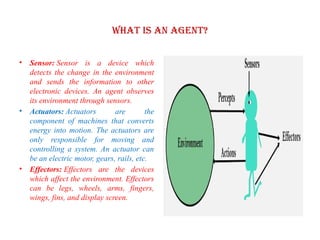




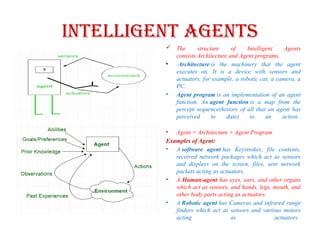

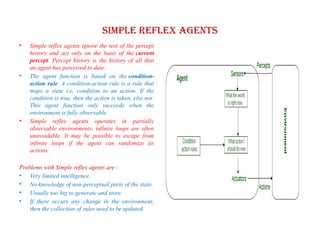
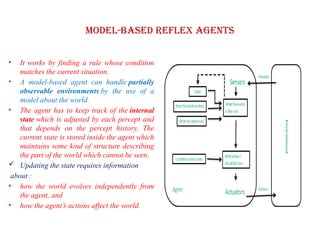
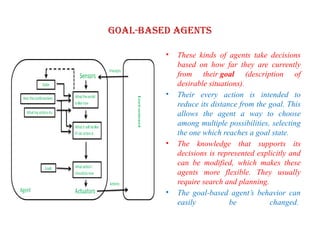
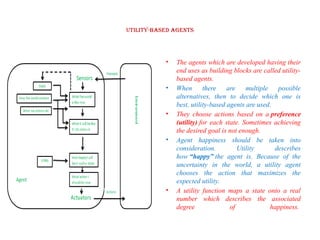
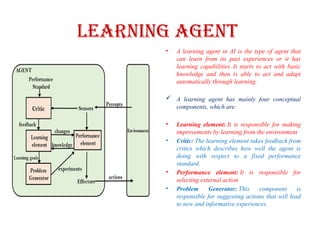




















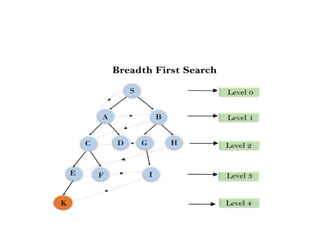



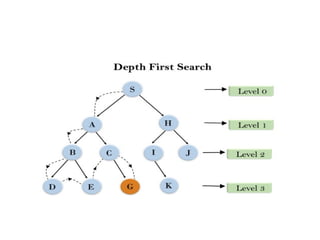



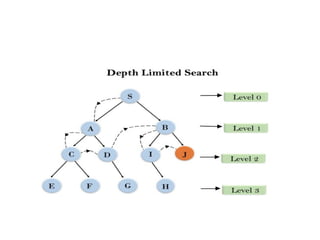



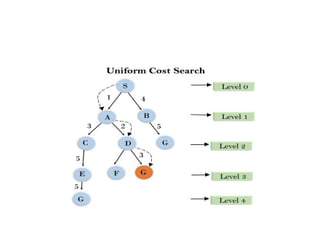
![Completeness:
• Uniform-cost search is complete, such as if there is a solution,
UCS will find it.
Time Complexity:
• Let C* is Cost of the optimal solution, and ε is each step to get
closer to the goal node. Then the number of steps is = C*/ε+1.
Here we have taken +1, as we start from state 0 and end to C*/ε.
• Hence, the worst-case time complexity of Uniform-cost search
isO(b1 + [C*/ε]
)/.
Space Complexity:
• The same logic is for space complexity so, the worst-case space
complexity of Uniform-cost search is O(b1 + [C*/ε]
).
Optimal:
• Uniform-cost search is always optimal as it only selects a path
with the lowest path cost.](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-73-320.jpg)


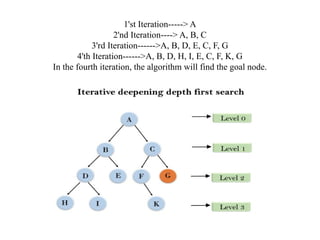



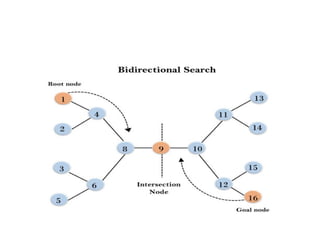









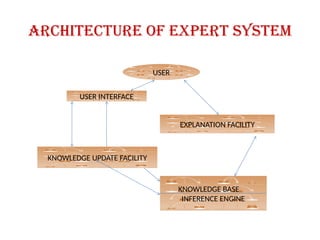












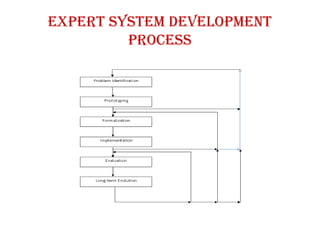

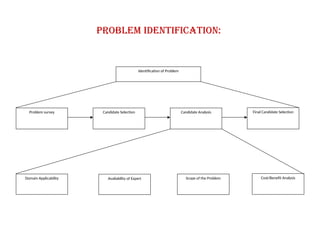
































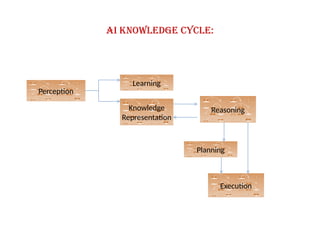











































![Resolution
Step-2: Conversion of
FOL into CNF
• In First order logic
resolution, it is required
to convert the FOL into
CNF as CNF form
makes easier for
resolution proofs.
• Eliminate all implication
(→) and rewrite
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ food(vegetables)
– ∀x y ¬ [eats(x, y)
∀ Λ ¬
killed(x)] V food(y)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀x ¬ eats(Anil, x) V eats(Harry,
x)
– ∀x¬ [¬ killed(x) ] V alive(x)
– ∀x ¬ alive(x) V ¬ killed(x)
– likes(John, Peanuts).](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-183-320.jpg)
![Resolution
• Move negation (¬)inwards
and rewrite
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ
food(vegetables)
– ∀x y ¬ eats(x, y) V
∀
killed(x) V food(y)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀x ¬ eats(Anil, x) V
eats(Harry, x)
– ∀x ¬killed(x) ] V alive(x)
– ∀x ¬ alive(x) V ¬ killed(x)
– likes(John, Peanuts).
• Rename variables or
standardize variables
– ∀x ¬ food(x) V likes(John, x)
– food(Apple) Λ
food(vegetables)
– ∀y z ¬ eats(y, z) V killed(y)
∀
V food(z)
– eats (Anil, Peanuts) Λ
alive(Anil)
– ∀w¬ eats(Anil, w) V
eats(Harry, w)
– ∀g ¬killed(g) ] V alive(g)
– ∀k ¬ alive(k) V ¬ killed(k)
– likes(John, Peanuts).](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-184-320.jpg)
























![Truth maintenance system
• Support List Justification: Support associated with each node are known as
justification for the node’s truth value.
• For each node that is IN, TMS records a well-founded support: proof of the validity
of the node, starting from the system’s facts and justifications.
For example:
1. It is sunny.
2. It is daytime.
3. It is raining.
4. It is warm.
Node No. Knowledge Justification
5. It is sunny [SL(2) (3)(4)]
6. It is day time [SL() ()]
7. It is raining [SL() (1)]
8. It is warm [SL(1)(4)]
IN: (1, 2, 4)
OUT: (3)](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-209-320.jpg)

![Truth maintenance system
• Conditional Proof Justifications: A conditional
proof is second type of justification that is used
to support hypothetical reasoning.
• Format of a CP is: [CP(consequent)
(in_hypothesis)]
• A CP justification is valid if and only if the
consequent node is IN whenever all of the
nodes on in_hypothesis are IN.](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-211-320.jpg)






![CERtainty factor
• Certainty factor is an informal mechanism for quantifying the
degree to which we believe/disbelieve a given conclusion based on
the presence of given set of evidences.
• A certainty factor(CF[h,e]) is defined in terms of two components:
- MB[h,e]: a measure(between 0 and 1) of belief in hypothesis h
given the evidences e. MB measures the extent to which the
evidence support the hypothesis. It is zero if the evidence fails to
support the hypothesis.
- MD[h,e]: a measure(between 0 and 1) of disbelief in hypothesis h
given the evidences e. MD measures the extent to which the
evidence support the negation of hypothesis. It is zero if the
evidence support the hypothesis.
From these measures, certainty factor is defined as:
CF(h,e) = MB[h,e] - MD[h,e]](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-218-320.jpg)


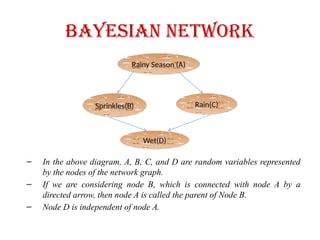
![Dempster-shafer theory
This alternative approach considers sets of propositions and
assigns to each of them an interval:
[Belief, Plausibility]
In which the degree of belief must be lie. Belief measures the
strength of evidence in favor of a set of propositions.
It ranges from 0 (indicating no evidence) to 1(denoting certainty).
Plausibility is defined as:
Pl(s) = 1-Bel(¬s)
Frame of Discernment(Θ) is used to check the evidences related to
hypothesis.
For example: [Flu, Cold, Pneu] = 0.6 Θ = 0.4](https://image.slidesharecdn.com/vnd-250920201744-669119db/85/vnd-openxmlformats-officedocument-presentationml-presentation-rendition-1-pptx-222-320.jpg)