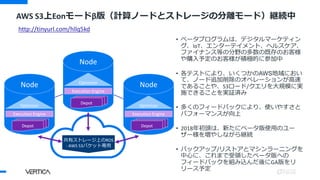
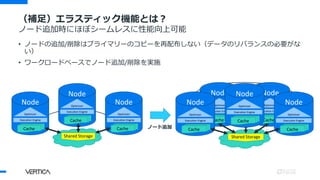
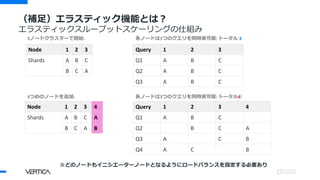
(補足)エラスティック機能とは?
エラスティックスループットスケーリングの仕組み
Query 1 23 4
Q1 A B C
Q2 B C A
Q3 A C B
Q4 A C B
Node 1 2 3 4
Shards A B C A
B C A B
3ノードクラスターで開始:
Query 1 2 3
Q1 A B C
Q2 A B C
Q3 A B C
Node 1 2 3
Shards A B C
B C A
4つめのノードを追加:
各ノードは3つのクエリを同時実可能: トータル 3
各ノードは3つのクエリを同時実可能: トータル4!
※どのノードもイニシエーターノードとなるようにロードバランスを設定する必要あり
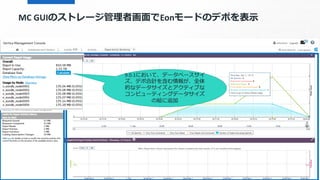
1
Depot Usage Percentage
0.05%
Alsoa link to Depot Activity:
Find out what’s happening in Depot!
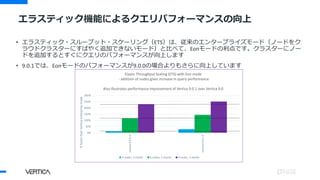
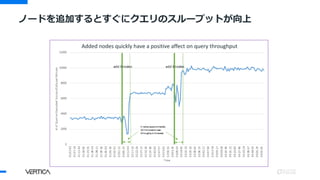
9.0.1において、データベースサイ
ズ、デポ合計を含む情報が、全体
的なデータサイズとアクティブな
コンピューティングデータサイズ
の絵に追加
MC GUIのストレージ管理者画面でEonモードのデポを表示
9.0以前:ヒント句の確認に3ステップが必要
user=> CREATE DIRECTEDQUERY OPTIMIZER optPlan select
customer_name, customer_state from customer_dimension;
CREATE DIRECTED QUERY
user=> ACTIVATE DIRECTED QUERY optPlan;
ACTIVATE DIRECTED QUERY
user=> select query_name, annotated_query from
DIRECTED_QUERIES where query_name='optPlan';
query_name |
annotated_query
------------+--------------------------------------------
---------------------------------------------------------
---------------------------------------------------------
---------------------------------------------------------
--
optPlan | SELECT /*+verbatim*/
customer_dimension.customer_name AS customer_name,
customer_dimension.customer_state AS customer_state
FROM public.customer_dimension AS
customer_dimension/*+projs('public.customer_dimension')*/
(1 row)
9.0SP1以降:1ステップでヒント句が確認可能
user=> EXPLAIN ANNOTATED select customer_name,
customer_state from customer_dimension;
QUERY PLAN
-----------------------------------------------------
-----------------------------------------------------
-------------------
SELECT /*+verbatim*/
customer_dimension.customer_name AS customer_name,
customer_dimension.customer_state AS customer_state
FROM public.customer_dimension AS
customer_dimension/*+projs('public.customer_dimension
')*/
(2 rows)
Directedクエリがより使いやすく
9.0以前は、Directedクエリの内容を確認するために複数ステップを踏む必要があったが、1ス
テップで情報を確認可能に
16.
9.0以前
user=> CREATE TABLEfoo (a INTEGER);
user=> COPY foo (f FILLER VARCHAR, a AS
f::INTEGER) FROM STDIN REJECTED DATA AS
TABLE foo_rej;
1
2a
3
.
ERROR 2827: Could not convert "foo" from
column "*FILLER*".a_vc to an int8
user=> SELECT a FROM foo;
a
---
(0 rows)
9.0SP1以降(REJECTMAX指定で最大REJECT行も設
定可能)
user=> CREATE TABLE foo (a INTEGER);
user=> SELECT
set_config_parameter('CopyFaultTolerantExpressions', 1);
user=> COPY foo (f FILLER VARCHAR, a AS f::INTEGER) FROM STDIN
REJECTED DATA AS TABLE foo_rej;
1
2a
3
.
user=> SELECT a FROM foo;
a
---
1
3
(2 rows)
user=> SELECT rejected_data, rejected_reason FROM foo_rej;
rejected_data | rejected_reason
---------------+-----------------------------------------------
Tuple (2a) | ERROR 2827: Could not convert "2a" from column
"*FILLER*".f to an int8
(1 row)
COPY文のエラーハンドリングがよりフレキシブルに
9.0以前は、COPY実行中に変換処理によるエラーが発生した場合、ただちにロールバックする仕
様であったが、エラー行のみREJECTしその他の正常データをコピーすることが設定可能に
• 課題: 後から復元するためにデータベースをバックアップする際に、モデルをバックアップできるよう
にする必要がありました。また、Verticaバージョンをアップグレードする場合、ユーザーは以前のバー
ジョンで作成したmlモデルを使用できるようにする必要がありました。
•解決策: 異なるバージョン間でのモデルのバックアップとリストアがサポートされるようになりました。
• 利点: ユーザーは、機械学習モデルを作成し、バックアップしたものを新しいバージョンでリストアで
きるようになります。
• 例:
SELECT UPGRADE_MODEL(USING PARAMETERS model_name =
‘myLogisticRegModel’);
※dbadminユーザーは、「 SELECT UPGRADE_MODEL();」を使用して、アップグレードすべきすべてのモデルを
アップグレード可能
※下記のようなエラーが発生した場合も、適用可能
ERROR 5861:Error calling setup() in User Function apply_kmeansat [src/Common/GPredict.cpp:47], error code: 0, message:
Error in setup: [Error in setup: Model 'public.mykmeansmodel' is not in the current version format. Please run
upgrade_model]
機械学習モデルのバックアップリストア関連追加機能
機械学習モデルのアップグレード関数












![vbrでオブジェクトを指定時にワイルドカードが使用可能に
データベースオブジェクト:
- スキーマ:s, s1, s2
- テーブル:s.t, s.tt, s1.t1, s1.tt1, s2.t2, s2.tt2
構成ファイル設定
objects=
includeObjects=s*,s.*
excludeObjects=s,s.t
バックアップ対象:
- s1, s2, s.tt
$ vbr -c vbr.ini -t backup
Starting backup of database xli.
Participating nodes: node01, node02,
node03.
Include objects: s*, s.*; exclude
objects: s, s.t
Snapshotting database.
Snapshot complete.
Backing up objects: s1,s2,s.tt
Approximate bytes to copy: 0 of 0 total.
[=======================================
===========] 100%
Copying backup metadata.
Finalizing backup.
Deleting old restore points.
Backup complete!](https://image.slidesharecdn.com/jpvertica9-181101061352/85/Vertica-9-0-1-18-320.jpg)
![S3バックアップ時のクライアント側の暗号化機能を追加
(参考) https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/serv-side-encryption.html
vbrの構成ファイルの[S3]セクションに以下の2つのパラメーターを追加
- s3_encrypt_at_rest:
- 「sse」に設定することにより、バックアップを暗号化。デフォルトはNone
- s3_sse_kms_key_id:
- KMSキーのIDを入力することにより、SSE-KMSを有効化。デフォルトはNone
- S3バケットは、KMSキーと同じリージョン内にある必要あり
- s3_encrypt_transportの有効化必須
In general, only set s3_encrypt_at_rest will use SSE-S3, set both s3_encrypt_at_rest and
s3_sse_kms_key_id will use SSE-KMS.
set s3_encrypt_at_restのみの設定の場合、SSE-S3を使用し、s3_encrypt_at_restと
s3_sse_kms_key_idの両方を設定するとSSE-KMSが使用される](https://image.slidesharecdn.com/jpvertica9-181101061352/85/Vertica-9-0-1-19-320.jpg)








![• 課題: 後から復元するためにデータベースをバックアップする際に、モデルをバックアップできるよう
にする必要がありました。また、Verticaバージョンをアップグレードする場合、ユーザーは以前のバー
ジョンで作成したmlモデルを使用できるようにする必要がありました。
• 解決策: 異なるバージョン間でのモデルのバックアップとリストアがサポートされるようになりました。
• 利点: ユーザーは、機械学習モデルを作成し、バックアップしたものを新しいバージョンでリストアで
きるようになります。
• 例:
SELECT UPGRADE_MODEL(USING PARAMETERS model_name =
‘myLogisticRegModel’);
※dbadminユーザーは、「 SELECT UPGRADE_MODEL();」を使用して、アップグレードすべきすべてのモデルを
アップグレード可能
※下記のようなエラーが発生した場合も、適用可能
ERROR 5861:Error calling setup() in User Function apply_kmeansat [src/Common/GPredict.cpp:47], error code: 0, message:
Error in setup: [Error in setup: Model 'public.mykmeansmodel' is not in the current version format. Please run
upgrade_model]
機械学習モデルのバックアップリストア関連追加機能
機械学習モデルのアップグレード関数](https://image.slidesharecdn.com/jpvertica9-181101061352/85/Vertica-9-0-1-29-320.jpg)














![[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c25hpfacebook-141120232027-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] A13: 最新版VerticaのAnalytics機能を駆使して実現する簡単ログ分析 by日本...](https://cdn.slidesharecdn.com/ss_thumbnails/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004-thumbnail.jpg?width=640&height=640&fit=bounds)





![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










![[よくわかるクラウドデータベース] AWSデータベースアップデート 20140117](https://cdn.slidesharecdn.com/ss_thumbnails/20140117awsdbupdatesv1-140128175124-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
