언어의 기본이 되는 CharacterSet 에 대한 내용입니다.
비투엔 사내세미나 발표. 2014-05-15
목차
I. 들어가며
II. 언어의 특징 (IT 관점)
III. 한글의 전산화 과정
IV. 유니코드(Unicode)
V. 오라클 캐릭터셋(Oracle Characterset)
| 글로벌 어플리케이션개발 시 고려사항
글로벌 어플리케이션?
4
언어
• 다양한 언어
• 각종 메시지
• 저장방법
• 쓰기방향
• 정렬
돈
• 통화
• 환율
지역 관련
• 통화
• 날짜 형식
• 달력
• 숫자 형식
시간
• 국가별 시간대
• 시차
• 서머타임
6.
2014 ⓒ B2ENConsulting All Rights Reserved
II. 언어의 특징 (IT 관점)
1. 언어 개요
2. 쓰기방향
3. 문자집합
4. 관련 용어
7.
| 글로벌 어플리케이션개발 시 고려사항
세계의 언어
6
언어의 종류
약3,500
문자의 종류
약100
출처: 눈높이대백과
8.
| 글로벌 어플리케이션개발 시 고려사항
주요 언어 분포
7
57.35
16
11
1.14
2
1
6.15
8
5
16.49
25
4
5.43
27
55
0
10
20
30
40
50
60
70
80
90
100
Native Speakers
by Population
Internet User
Language
Internet
Content
English
Chinese
Spanish
Arbic
Portuguese
Russian
Japanese
German
Korean
French
Other
1) 출처 : wikipedia.org
2) 출처 : w3techs.com
1) 2) 2)
9.
| 글로벌 어플리케이션개발 시 고려사항
가로쓰기 – 좌횡서 LTR(Left to Right)
• 쓰기방향은 왼쪽오른쪽, 위아래
• 대부분의 언어
8
동해물과 백두산이 마르고 닳도록
하느님이 보우하사 우리나라 만세.
무궁화 삼천리 화려강산
대한 사람, 대한으로 길이 보전하세
The quick brown fox jumps over the lazy dog
The quick brown fox jumps over the lazy dog
The quick brown fox jumps over the lazy dog
The quick brown fox jumps over the lazy dog
10.
| 글로벌 어플리케이션개발 시 고려사항
가로쓰기 – 우횡서 RTL(Right to Left)
• 쓰기방향은 오른쪽왼쪽, 위아래
• 주로 중동지방: Arabic, Persian, Hebrew
9
11.
| 글로벌 어플리케이션개발 시 고려사항
가로쓰기 – BiDi(bi-directional)
• 쓰기방향은 상황에 따라 왼쪽오른쪽 또는 오른쪽왼쪽
• Chinese
※ 현재는 언어적 특성으로 이야기하지 않고, 여러 쓰기 방향이 섞여있는 단락을 지칭하기도 함
10
12.
| 글로벌 어플리케이션개발 시 고려사항
세로쓰기 – 우종서
• 쓰는 방향은 위아래, 오른쪽왼쪽
• 과거 한, 중, 일
11
13.
| 글로벌 어플리케이션개발 시 고려사항
쓰기방향은 데이터베이스와 관련이 적다!
12
"…오라클 및 다른 데이터베이스는 데이터를 논리적인 방향으로
저장한다. 어떤 방향으로 보여주는 가는 내(데이터베이스)가
관여할 일이 아니라서…"
Oracle said,
14.
| 글로벌 어플리케이션개발 시 고려사항
문자 집합character set과 인코딩encoding
13
SOS
encoding
decoding
SOS character set
15.
| 글로벌 어플리케이션개발 시 고려사항
관련 용어
• 문자 집합 character set
• 특정 시스템에서 사용되는 문자나 부호들의 집합
• 문자 인코딩 character encoding
• 컴퓨터에서 전송 또는 저장을 목적으로 하는 부호화
• 일부 문자 집합은 문자 인코딩 방법과 정확히 맞아 떨어지기 때문에,
문자 집합이라는 용어와 혼용되어 사용되는 경우도 있음
• 코드페이지 code page
• 문자집합을 정의하기 위해 IBM에서 사용했던 고유 용어
• 포함관계, 부분집합 superset/subset
• 두 문자 집합을 비교했을 때, 한 문자 집합의 문자가 다른 문자 집합의 문자의 일부분이 될 때의 포함관계
• 완벽한 부분집합 strict superset : 코드 값 까지 동일할 때
14
16.
2014 ⓒ B2ENConsulting All Rights Reserved
III. 한글의 전산화 과정
1. 아스키
2. 확장아스키
3. 조합형 한글 vs 완성형 한글
4. EUC-KR
5. CP949
17.
| 글로벌 어플리케이션개발 시 고려사항
아스키 ASCII
• American Standard Code for Information Interchange – 미국 정보 교환 표준 코드
• 7bit의 문자 인코딩: 27(128)개
• 숫자(10), 알파벳(52), 특수문자(32), 제어문자(33), 공백문자(1)로 구성
• 한국의 KS X 1003는 ASCII를 그대로 채용
16
숫자
알파벳
기호
제어문자
18.
| 글로벌 어플리케이션개발 시 고려사항
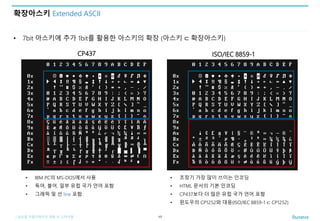
확장아스키 Extended ASCII
• 7bit 아스키에 추가 1bit를 활용한 아스키의 확장 (아스키 ⊂ 확장아스키)
17
CP437 ISO/IEC 8859-1
• IBM PC의 MS-DOS에서 사용
• 독어, 불어, 일부 유럽 국가 언어 포함
• 그래픽 및 선 line 포함
• 초창기 가장 많이 쓰이는 인코딩
• HTML 문서의 기본 인코딩
• CP437보다 더 많은 유럽 국가 언어 포함
• 윈도우의 CP1252와 대응(ISO/IEC 8859-1 ⊂ CP1252)
19.
| 글로벌 어플리케이션개발 시 고려사항
조합형한글 vs 완성형한글
• 한글 인코딩 표준과 관련한 1985~1995년대 논쟁
18
조합형한글 완성형한글
기본원리
• 초성,중성,종성 각각에 코드를 부여해서 최종적인 글
자 하나는 세 코드의 조합
예) ㄱ+ㅏ+ㅂ 갑
• 초성,중성,종성을 합한 하나의 온전한 글자에 코드를
부여함
예) 갑
구현
• 2바이트 조합형
한글여부(1비트) + 초성(5비트) + 중성(5비트) + 종성
(5비트) : 1 xxxxx yyyyy zzzzz
• 한글 글자별 코드를 부여
• 저장공간의 한계로 자주 사용되는 한글 2,350개 선정
주장 이유
• 한글 창제 원리에 맞는다
• 현대 한글을 모두 표현할 수 있다는 것
• 타 언어와 혼용해서 쓰기 좋다.
약점
• 현대 한글은 11,172자만 현대 한국어 발음을 표현함
잘못 조합된 문자가 생길 수 있음
• 다양한 조합형 표준안의 난립
예) 3바이트 조합형, 2바이트 조합형
2바이트 조합형도 삼보조합형, 상용조합형,…
• 표현 글자수가 너무 적음
(일부 표준어 조차 표현 못함)
• 자소 정보 추출 불가
주요 진영
• 대부분의 개발자: 개발이 용이함
• 팬택, 금성, 삼성, 등 큰 기업들: 이미 그렇게 개발함
• 한국이동통신 (국제 호환성)
승자 X (너무 난립됨) O (국제적 호환성 : ISO-2022)
• KSC5601 제정 MS윈도우95로 휴전 Unicode 2.0 이후로 마무리
20.
| 글로벌 어플리케이션개발 시 고려사항
EUC-KR (Extended Unix Code - Korean)
• 가변길이 인코딩 (1~2byte)
• 00-7F : 1byte로 인식하며, KS X 1003(ASCII와 유사)에 대응된다.
80-FF : 2byte의 일부로 인식하며, KS X 1001(구 KS C 5601)에 대응된다.
• 서로의 영역이 다르기 때문에 특정 1 byte를 가져왔을 때, 1 byte 문자인지 2 byte 문자인지 판별 가능
• KS C 5601 (ISO 2022에 준함)
• 1byte, 2byte 모두 A1~FE까지의 영역만을 사용(배정 가능한 문자는 94*94=8836자)
• 많이 사용하는 한글 음절 2,350자, 한자 4,888자, 특수문자 1,128자, 기타 470자를 수록
19
ASCII 문자
기호, 라틴어, 일어
완성형한글
한자
80xx
90xx
A0xx
B0xx
C0xx
D0xx
E0xx
F0xx
00 40 80 F010 20 30 50 60 70 90 A0 B0 D0C0 E0
1byte의 경우
2byte의 경우
00 40 80 F010 20 30 50 60 70 90 A0 B0 D0C0 E0
21.
| 글로벌 어플리케이션개발 시 고려사항
EUC-KR – 한계
• KSC5601에 있는 2,350자의 한글 이외의 한글 표현 불가능
• 2,350자는 실제 사용되는 한글 음절보다 적은 개수임.
• 일부 표준어 조차 표현 불가능
20
樂 樂 樂 樂
D1E2 D5A5 E4C5 E8F9
낙 락 악 요
• 받침 없는 문자가 존재
• 특정 문자를 쓰기 위해 거쳐가는 문자가 존재하지 않음
• 한글 독음을 기준으로 한자를 수록함으로 모양이 같은 한자가 중복 수록됨
• 유니코드에서도 이러한 문자가 한중일 호환용 한자가 동시 수록됨
뢔(X)뢨(O), 쌰(X)썅(O), 쎼(X)쏀(O), 쓔(X)쓩(O), 쬬(X)쭁(O)
찦차를 타고 온 펲시맨과 쑛다리 똠방각하.
뾼차를 타고 온 최시맨과 뉵다리 駝방각하.
22.
| 글로벌 어플리케이션개발 시 고려사항
CP949 (확장 완성형한글)
• Microsoft에서 EUC-KR을 보완하여 만든 인코딩
• MS윈도우95부터 주로 사용됨 사실상 표준
• KSC5601로 표현이 불가능했던 한글 8,822자를 추가
• 남은 영역에 가나다순
• 기존 EUC-KR과 호환성을 위함
• 추후 EUC-KR은 CP949를 의미 (예를들어 웹브라우저에서 EUC-KR 설정)
• KSC5601 ⊂ CP949
ASCII 문자
기호, 라틴어, 일어
완성형한글
한자
확장 완성형한글
80xx
90xx
A0xx
B0xx
C0xx
D0xx
E0xx
F0xx
00 40 80 F010 20 30 50 60 70 90 A0 B0 D0C0 E0
00 40 80 F010 20 30 50 60 70 90 A0 B0 D0C0 E0
1byte의 경우
2byte의 경우
21
23.
| 글로벌 어플리케이션개발 시 고려사항
CP949 (확장 완성형한글) – 한계
• 특정 바이트를 가져왔을 때 1 byte / 2 byte로 인코딩 하는 기준 문제
• 기존 EUC-KR에서는 1~2 byte별 사용 영역이 다르므로 발생하지 않던 문제
• 가장 앞 바이트부터 차례차례 읽어야 함
• 오류로 인해 일부 바이트가 소실되면 해당 바이트 이후의 내용은 깨질 수 있음
• 정렬 오류 문제
• 기존의 한글 2,350자나 새로 추가된 8,822자끼리는 정렬순서 대로 배치되어 있음
• 모든 한글을 기준으로 볼 때, 정렬순서 대로 배치되어 있지 않음
가 똠 마 뷁 햏 힛
8C63 94EE B0A1 B8B6 C164 C8FD
똠 뷁 가 마 햏 힛
원하는결과
실제결과
안 녕 하 세 요 반 갑 습 니 다
BE C8 B3 E7 C7 CF BC BC BF E4 B9 DD B0 A9 BD C0 B4 CF B4 D9
홰 聆 究 셀 阿 腑 ㈌ 윱 求 ?
22
24.
2014 ⓒ B2ENConsulting All Rights Reserved
IV. 유니코드
1. 개요
2. 역사
3. 유니코드 평면
4. 한중일 통합 한자
5. UTF
25.
| 글로벌 어플리케이션개발 시 고려사항
유니코드 개요
• 유니코드 Unicode
• 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
• 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자들을 다루기 위한 알고리즘 등을 포함
• 존재하는 모든 문자들을 하나의 문자집합에 담으려는 원대한 꿈
• 문자의 코드는 U+xxxx 형태로 표기
• 유니코드 컨소시엄 Unicode Consortium
• 다국어를 위한 코드 체계를 제정하기 위해 설립된 회사(1989)
• ISO/IEC 10646
• 국제표준기구ISO에서도 국제표준코드를 만들기 위한 시도를 하고 있었음
• 유니코드 컨소시엄과 협조하여 유니코드와 사실상 동일한 ISO/IEC-10646을 제정
• 사용되는 용어나 개념은 일부 상이함 (유니코드:사용/구현위주, ISO:표준위주)
24
26.
| 글로벌 어플리케이션개발 시 고려사항
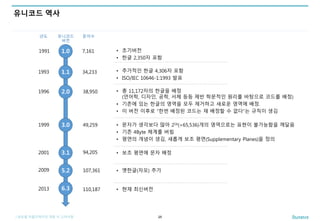
유니코드 역사
25
1.0
2.0
3.1
5.2
1991
1996
• 초기버전
• 한글 2,350자 포함
• 추가적인 한글 4,306자 포함
• ISO/IEC 10646-1:1993 발표
1.11993
• 총 11,172자의 한글을 배정
(언어학, 디자인, 공학, 서체 등등 제반 학문적인 원리를 바탕으로 코드를 배정)
• 기존에 있는 한글의 영역을 모두 제거하고 새로운 영역에 배정.
• 이 버전 이후로 “한번 배정된 코드는 재 배정할 수 없다”는 규칙이 생김
7,161
34,233
38,950
2001 94,205 • 보조 평면에 문자 배정
2009 107,361 • 옛한글(자모) 추가
6.32013 110,187 • 현재 최신버전
3.01999 49,259 • 문자가 생각보다 많아 216(=65,536)개의 영역으로는 표현이 불가능함을 깨달음
• 기존 4Byte 체계를 버림
• 평면의 개념이 생김, 새롭게 보조 평면(Supplementary Planes)을 정의
년도 문자수유니코드
버전
27.
| 글로벌 어플리케이션개발 시 고려사항
유니코드에서 한글
• Unicode 1.0
• 조합형 코드의 조합은 3만 자가 넘기 때문에 수용하기 어려웠음
최소한으로 요청한 11,172자도 당시 국제사회에서 받아들이기 어려웠음.(65,536자 중 거의 절반을 사용)
유니코드 1.0에 KSC5601-1987완성형 코드만을 포함
• Unicode 2.0
• 윈도우95/NT에서의 한글 지원 문제로 고심하던 MS가 활약
• 유니코드 2.0에서 온전한 현대어 한글완성형 11,172자를 확보
• 단일 문자로는 가장 많은 문자를 배정받는 국가가 됨 (한자는 한국·중국·일본·대만 등에서 사용)
• 과학적 조합 원리
• 초성(19) * 중성(21) * 종성(28) = 11,172자
• 유니코드의 한글은 KSC5601완성형 코드와는 다르게 일정한 조합 원리를 갖고 있음
• 특정 공식을 이용하여 한글의 자소를 추출할 수 있음
26
28.
| 글로벌 어플리케이션개발 시 고려사항
한중일 통합 한자 CJK(Chinese-Japanese-Korean) Unified Ideographs
• 유니코드 이전
• 각 나라별 일부 한자만 선택적으로 포함: 나라별로 쓰는 한자 대역이 다름
• 한국 EUC-KR, 일본:SHIFT-JIS, 중국: GB18030
• 중국 – 최소 4,000자 한자, 완전한 문자생활을 위해서는 40,000자 한자
• 형태는 같을지라도 음이 다르거나 각각 처리하는 방식이 다름
• EUC-KR의 한자의 경우 한글 발음 순서대로
• 같은 한자 다른 발음이 중복 수록됨 – 낙,락,악,요(樂)
• 유니코드 이후
• 한국·중국·일본(·베트남)의 경우 통합 한자는 공유함
• 한자를 부수와 획수에 맞추어 배열함
• 기타 각국에서만 독특하게 사용하는 한자의 경우 한자 사용 국가끼리 협의
• 보조 한자들이 계속 추가됨
27
한국어 일본어
중국어
한자
27
29.
| 글로벌 어플리케이션개발 시 고려사항
기본 다국어 평면 Basic Multilingual Plane
• U+0000 ~ U+FFFF (총 65,536개)
• 사용되는 대부분의 언어가 포함되어 있음
한글음절 11,172자
한글자모 256자
한글자모확장 208자
28
| 글로벌 어플리케이션개발 시 고려사항
보조 평면 Supplementary Plane
• U+10000 ~ U+10FFFF
• 이론상 각 평면 별 65,536개의 코드를 배정할 수 있음
• 유니코드에서는 총 17개의 평면을 사용하며, Unicode 6.3 기준으로 6개의 평면을 사용중임
BMP SMP
0000-FFFF 10000-1FFFF 20000-2FFFF
Plane 0 Plane 1 Plane 2
100000-10FFFF
Plane 16
F0000-FFFFF
Plane 15
다국어
대부분이 포함
고대글자들,
음악기호,
수학기호,
픽토그래픽,
카드, 도미노 등
SIP
고대 한/중/일
한자
Private Use Area Planes
알아서 사용
30
32.
| 글로벌 어플리케이션개발 시 고려사항
[예시] 유니코드 문자
31
U+1D11E
U+0041 U+0414 U+AC00
U+13000 U+1F018 U+1F600 U+1F3E7
U+6A02
樂악 樂낙 樂락 樂요
U+0031
기본
다국어
평면
보조
다국어
평면
U+6A02 U+F914 U+F95C U+F9BF
같은 모양
다른 한자
33.
| 글로벌 어플리케이션개발 시 고려사항
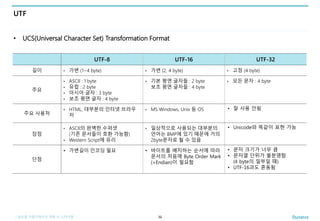
UTF
• UCS(Universal Character Set) Transformation Format
32
UTF-8 UTF-16 UTF-32
길이 • 가변 (1~4 byte) • 가변 (2, 4 byte) • 고정 (4 byte)
주요
• ASCII : 1 byte
• 유럽 : 2 byte
• 아시아 글자 : 3 byte
• 보조 평면 글자 : 4 byte
• 기본 평면 글자들 : 2 byte
보조 평면 글자들 : 4 byte
• 모든 문자 : 4 byte
주요 사용처
• HTML, 대부분의 인터넷 브라우
저
• MS Windows, Unix 등 OS • 잘 사용 안됨
장점
• ASCII의 완벽한 수퍼셋
(기존 문서들이 호환 가능함)
• Western Script에 유리
• 일상적으로 사용되는 대부분의
언어는 BMP에 있기 때문에 거의
2byte문자로 될 수 있음
• Unicode와 똑같이 표현 가능
단점
• 가변길이 인코딩 필요 • 바이트를 배치하는 순서에 따라
문서의 처음에 Byte Order Mark
(=Endian)이 필요함
• 문자 크기가 너무 큼
• 문자열 단위가 불분명함
(4 byte의 일부일 때)
• UTF-16과도 혼동됨
34.
| 글로벌 어플리케이션개발 시 고려사항
UTF-8 Encoding/Decoding
• Encoding
33
Source (Unicode) Target (UTF-8)
대상 문자
사용
비트수
최대 가능수
1번째
바이트
2번째
바이트
3번째
바이트
4번째
바이트
총 비트수
U+0000 ~ U+007F 7 127 0xxxxxxx 7
U+0080 ~ U+07FF 11 (2,047-127)=1920 110xxxxx 10xxxxxx (5+6)=11
U+0800 ~ U+FFFF 16 (65,535-2,047)=63488 1110xxxx 10xxxxxx 10xxxxxx (4+6+6)=16
U+10000 ~ U+10FFFF 20 1,114,111-65535=1,048,576 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (3+6+6+6)=21
• Decoding
1. 어떤 바이트가 0으로 시작하면, 그 바이트는 1바이트가 한 글자임.(=ASCII)
2. 어떤 바이트가 110으로 시작하면, 거기서부터 2바이트가 한 글자임.
3. 어떤 바이트가 1110으로 시작하면, 거기서부터 3바이트가 한 글자임.
4. 어떤 바이트가 11110으로 시작하면, 거기서부터 4바이트가 한 글자임.
5. 어떤 바이트가 10으로 시작하면, 그 바이트는 어떤 글자의 중간 지점임.
U+AC00
11101010 10110000 10000000
10101100 00000000
0xEA 0xB0 0x80
2014 ⓒ B2ENConsulting All Rights Reserved
V. 오라클 캐릭터셋
1. Oracle Database Globalization Support
2. 한글 관련 주요 캐릭터셋
3. 다른 캐릭터셋 간 마이그레이션
37.
| 글로벌 어플리케이션개발 시 고려사항
Oracle Database Globalization Support
36
Oracle Database Globalization Support
Language Support
Territory Support
Date and Time Formats
Monetary and Numeric
Formats
Calendar Systems
Linguistic Sorting
Character Set Support
Character Semantics
Customization of Locale and
Calendar Data
Unicode Support
38.
| 글로벌 어플리케이션개발 시 고려사항
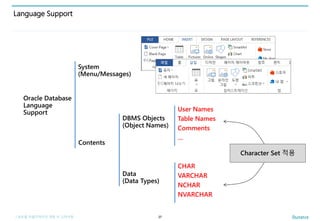
Language Support
37
System
(Menu/Messages)
Contents
Data
(Data Types)
DBMS Objects
(Object Names)
User Names
Table Names
Comments
…
CHAR
VARCHAR
NCHAR
NVARCHAR
Oracle Database
Language
Support
Character Set 적용
39.
| 글로벌 어플리케이션개발 시 고려사항
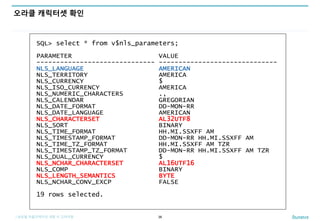
오라클 캐릭터셋 확인
38
SQL> select * from v$nls_parameters;
PARAMETER VALUE
------------------------------ ------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_CHARACTERSET AL32UTF8
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
19 rows selected.
40.
| 글로벌 어플리케이션개발 시 고려사항
한글 관련 주요 캐릭터셋
KO16KSC5601 KO16MSWIN949 UTF8 AL32UTF8 AL16UTF16
대응
캐릭터셋
EUC-KR (KCS5601) CP949 UTF-8 UTF-8 UTF-16
한글 2,350자 11,172자 11,172자
11,172자
+조합형, 옛한글 등
11,172자
+조합형, 옛한글 등
Database
Character Set
O O O O X
National
Character Set
X X O X O
특징 제한적 한글 표현
Binary 정렬 시
정렬 안됨
과거 버전 호환을
위한 캐릭터셋
(Unicode3.0까지 지원)
오라클 강력
권장 캐릭터셋
9.2 10.1 10.2 11.1 11.2 12.1
2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013
3.1 3.23.0 4.0 4.1 5.0 5.1 5.2 6.0 6.1 6.2 6.3
200120001999
9.1
• 오라클 버전 별 유니코드 지원 버전 (AL32UTF8)
Oracle DBMS
version
Unicode
version
39
41.
| 글로벌 어플리케이션개발 시 고려사항
Character Length Semantic
SQL> desc all_col_comments
Name Null? Type
----------------------------- -------- --------------------
OWNER NOT NULL VARCHAR2(30)
TABLE_NAME NOT NULL VARCHAR2(30)
COLUMN_NAME NOT NULL VARCHAR2(30)
COMMENTS VARCHAR2(4000)
• DBMS Object Name Length
• Byte/Character Semantics
SQL> create table t1 (c1 varchar2(3000 byte));
Table created.
SQL> desc t1
Name Null? Type
----------------------- -------- ------------------
C1 VARCHAR2(3000)
SQL> create table t2 (c1 varchar2(3000 char));
Table created.
SQL> desc t2
Name Null? Type
----------------------- -------- ------------------
C1 VARCHAR2(3000 CHAR) MAX : 3,000 Character
or 4,000 Byte
MAX : 3,000 Byte
MAX : 30 Byte
40
42.
| 글로벌 어플리케이션개발 시 고려사항
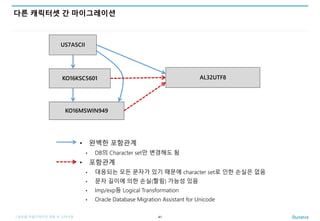
다른 캐릭터셋 간 마이그레이션
41
KO16KSC5601
KO16MSWIN949
AL32UTF8
US7ASCII
• 완벽한 포함관계
• DB의 Character set만 변경해도 됨
• 포함관계
• 대응되는 모든 문자가 있기 때문에 character set로 인한 손실은 없음
• 문자 길이에 의한 손실(짤림) 가능성 있음
• Imp/exp등 Logical Transformation
• Oracle Database Migration Assistant for Unicode


























![| 글로벌 어플리케이션 개발 시 고려사항
[예시] 기본 다국어 평면 중 [AC] 부분
29](https://image.slidesharecdn.com/v1-151117072010-lva1-app6892/85/V1-0-30-320.jpg)

![| 글로벌 어플리케이션 개발 시 고려사항
[예시] 유니코드 문자
31
U+1D11E
U+0041 U+0414 U+AC00
U+13000 U+1F018 U+1F600 U+1F3E7
U+6A02
樂악 樂낙 樂락 樂요
U+0031
기본
다국어
평면
보조
다국어
평면
U+6A02 U+F914 U+F95C U+F9BF
같은 모양
다른 한자](https://image.slidesharecdn.com/v1-151117072010-lva1-app6892/85/V1-0-32-320.jpg)

![| 글로벌 어플리케이션 개발 시 고려사항
[예시] UTF-8 / 16 / 32
34
U+1D11EU+0041 U+AC00
UTF-8
0x41
01000001
00000000:01000001
0x0041
UTF-16
UTF-32
0x00000041
00000000:00000000:
00000000:01000001
Unicode
0xEA 0xB0 0x80
11101010:10110000:10000000
10101100:00000000
0xAC00
00000000:00000000:
10101100:00000000
0x0000AC00
0xF0 0x9D 0x84 0x9E
11110000:10011101:
10000100:10011110
11011000:00110100:
11011101:00011110
0xD834 0xDD1E
00000000:00000001:
11010001:00011110
0x0001D11E
(1) (3) (4)
(2) (2) (4)
(4) (4) (4)](https://image.slidesharecdn.com/v1-151117072010-lva1-app6892/85/V1-0-35-320.jpg)


























![[Emocon 2017 S/S] 20170414 유니코드(Unicode)로 오픈소스에 기여하기](https://cdn.slidesharecdn.com/ss_thumbnails/20170414-170429081753-thumbnail.jpg?width=640&height=640&fit=bounds)







