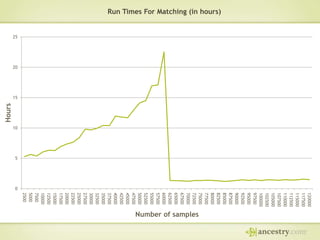
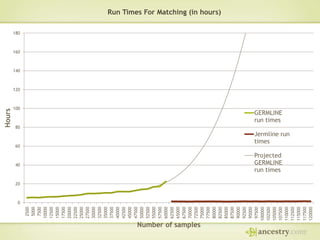
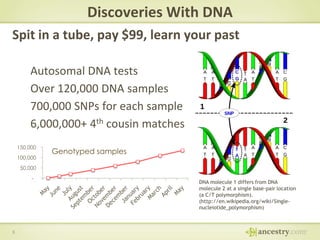
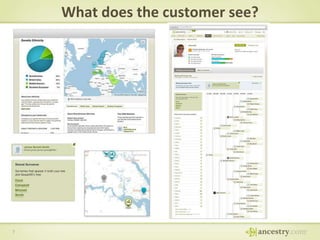
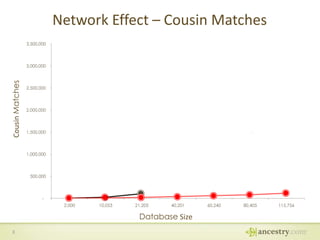
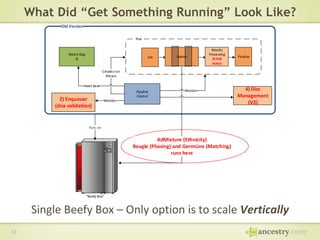
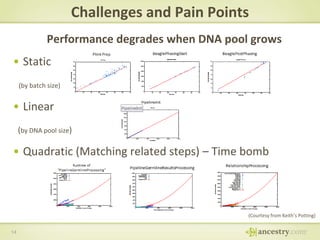
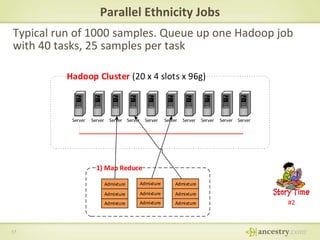
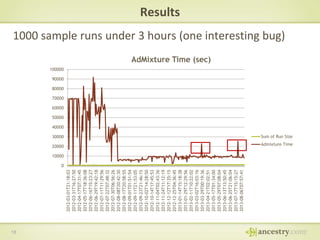
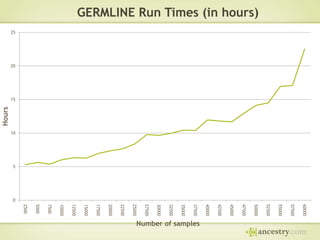
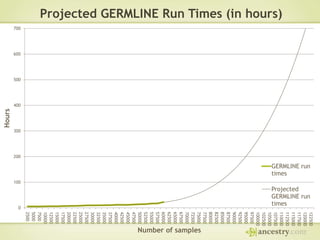
The document describes Ancestry's journey moving from a single machine DNA matching process to a scalable Hadoop and HBase solution. It details how they first parallelized the ethnicity prediction step using Hadoop as a job scheduler. This freed resources for the more challenging matching algorithm. It then explains how they developed "Jermline", storing matching data in HBase and using MapReduce to efficiently find new matches for incremental DNA samples. The new distributed solution allowed matching to scale to millions of DNA samples.




























![The
Starbuck
2_ACTGA_0
way
Adama
Step one : Update the hash table.
1
2_TTAAG_0
1
2_CCTAG_1
1
1
2_TTGAC_2
1
Already stored in HBase
1
Baltar : TTAAG CCTAG GGGCG
New sample to add
Add a column for every new sample for each user
Key : [CHROMOSOME]_[WORD]_[POSITION]
Qualifier : [USER ID]
Cell value : A byte set to 1, denoting that the user has that word at that
position on that chromosome](https://image.slidesharecdn.com/utahbigmountain-ancestrydnahbasehadoop9-7-2013billyetman-130928100600-phpapp02-131112114437-phpapp02/85/Utahbigmountain-ancestrydnahbasehadoop9-7-2013billyetman-130928100600-phpapp02-37-320.jpg)
![The
2_Starbuck
2_Starbuck
2_Adama
way
2_Adama
Step two : Find matches.
{ (1, 2), ...}
{ (1, 2), ...}
Baltar and Adama match from position 0 to position 1
Baltar and Starbuck match at position 1
Already
stored in
HBase
New
matches to
add
“Fuzzy Match” the consecutive words. Worst case: Identical twins
Key : [CHROMOSOME]_[USER ID]
Qualifier : [CHROMOSOME]_[USER ID]
Cell value : A list of ranges where the two users match on a chromosome](https://image.slidesharecdn.com/utahbigmountain-ancestrydnahbasehadoop9-7-2013billyetman-130928100600-phpapp02-131112114437-phpapp02/85/Utahbigmountain-ancestrydnahbasehadoop9-7-2013billyetman-130928100600-phpapp02-38-320.jpg)