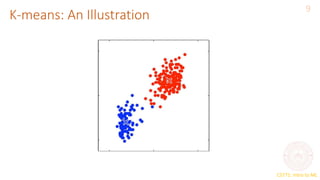
This document provides an overview of the k-means clustering algorithm. It explains that k-means is an unsupervised learning method that groups unlabeled data points into k clusters based on their similarity. The algorithm works by first randomly initializing k cluster centers and then alternating between assigning data points to the closest cluster center and recalculating the cluster centers based on the mean of assigned points. This process repeats until cluster assignments stop changing, minimizing within-cluster distances. The document discusses how k-means can be formulated as optimizing an objective function measuring distortion between points and clusters.









![CS771: Intro to ML
What Loss Function is K-means Optimizing?
12
Let 𝝁1, 𝝁2, … , 𝝁𝐾 be the K cluster centroids/means
Let 𝑧𝑛𝑘 ∈ {0, 1} be s.t. 𝑧𝑛𝑘 = 1 if 𝒙𝑛 belongs to cluster 𝑘, and 0
otherwise
Define the distortion or “loss” for the cluster assignment of 𝒙𝑛
Total distortion over all points defines the 𝐾-means “loss function”
The 𝐾-means problem is to minimize this objective w.r.t. µ and 𝒁
Alternating optimization on this loss would give the K-means (Lloyd’s) algorithm we
X Z
𝝁
N
K K
K
≈
Row 𝑛 is 𝒛𝑛
(one-hot
vector)
Row 𝑘 is
𝝁𝑘
𝒛𝑛 = [𝑧𝑛1, 𝑧𝑛2, … , 𝑧𝑛𝐾]
denotes a length 𝐾 one-
hot encoding of 𝒙𝑛](https://image.slidesharecdn.com/lec201-240409131909-71b728d4/85/unsupervised-learning-k-means-model-pptx-12-320.jpg)






























































