The document outlines the data science project lifecycle, detailing each critical step including understanding the business problem, data collection, data preparation, data modeling, and model deployment. It emphasizes the roles of various team members like business analysts, data analysts, and data scientists in building effective data science projects, as well as the importance of rigorous testing and proper communication of results. Additionally, it introduces the OSEMN framework and highlights essential skills needed in data preprocessing and model interpretation.







![import pandas as pd
df = pd.read_csv('my_csv.csv')
2. Reading an Excel file
The read_excel method of the Pandas library takes an excel file as a parameter and returns
a dataframe.
import pandas as pd
df = pd.read_excel('my_excel.xlsx')
Once the data has been read into a data frame, display the data frame to see if the data has been
read correctly.
Selecting the dataset:
After carefully inspecting our dataset, we are going to create a matrix of features in our dataset (X)
and create a dependent vector (Y) with their respective observations. To read the columns, we will
use iloc of pandas (used to fix the indexes for selection) which takes two parameters — [row
selection, column selection].
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
Step 3: Handling the Missing Data](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-8-2048.jpg)
![An example of Missing data and Imputation
The data we get is rarely homogenous. Sometimes data can be missing and it needs to be handled so
that it does not reduce the performance of our machine learning model.
To do this we need to replace the missing data by the Mean or Median of the entire column. For this
we will be using the sklearn.preprocessing Library which contains a class called Imputer which will
help us in taking care of our missing data.
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
Our object name is imputer. The Imputer class can take parameters like :
1. missing_values : It is the placeholder for the missing values. All occurrences of missing_values
will be imputed. We can give it an integer or “NaN” for it to find missing values.
2. strategy : It is the imputation strategy — If “mean”, then replace missing values using the mean
along the axis (Column). Other strategies include “median” and “most_frequent”.
3. axis : It can be assigned 0 or 1, 0 to impute along columns and 1 to impute along rows.
Now we fit the imputer object to our data.
imputer = imputer.fit(X[:, 1:3])
Now replacing the missing values with the mean of the column by using transform method.](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-9-2048.jpg)
![X[:, 1:3] = imputer.transform(X[:, 1:3])
Ranking :
Pandas Dataframe.rank() method returns a rank of every respective index of a series passed.
The rank is returned on the basis of position after sorting.
Syntax:
DataFrame.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’,
ascending=True, pct=False)
Parameters:
axis: 0 or ‘index’ for rows and 1 or ‘columns’ for Column.
method: Takes a string input(‘average’, ‘min’, ‘max’, ‘first’, ‘dense’) which tells pandas what to
do with same values. Default is average which means assign average of ranks to the similar
values.
numeric_only: Takes a boolean value and the rank function works on non-numeric value only if
it’s False.
na_option: Takes 3 string input(‘keep’, ‘top’, ‘bottom’) to set position of Null values if any in the
passed Series.
ascending: Boolean value which ranks in ascending order if True.
pct: Boolean value which ranks percentage wise if True.
# pandas is imported as pd
import pandas as pd
# dictionary is created
data = {'Book_Name':
['Oxford', 'Arihant',
'Pearson', 'Disha',
'Cengage'],
'Author': ['Jhon Pearson', 'Madhumita Pattrea', 'Oscar Wilde', 'Disha', 'G Tewani'],
'Price': [350,880,490,1100,450]}
# creating DataFrame
df = pd.DataFrame(data)
# printing DataFrame
print("Pandas DataFrame:n",df)
print()
# Printing the rank of
DataFrame.
print("Ranking of Pandas
Dataframe:n",df.rank())
Pandas DataFrame:
Book_Name Author Price
0 Oxford Jhon Pearson 350
1 Arihant Madhumita Pattrea 880
2 Pearson Oscar Wilde 490
3 Disha Disha 1100
4 Cengage G Tewani 450
Ranking of Pandas Dataframe:
Book_Name Author Price
0
1
2
3
4
4.0
1.0
5.0
3.0
2.0
3.0 1.0
4.0 4.0
5.0 3.0
1.0 5.0
2.0 2.0
# creating new column Ranked_Author and storing Author column's ranked data in descending order,
df['Ranked_Author']=df['Author'].rank(ascending=False)](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-10-2048.jpg)
![print("Ranking of Pandas Dataframe Author Column:n",df)
Ranking of Pandas Dataframe Author Column:
Book_Name Author Price
Ranked_Author
0 Oxford Jhon Pearson 350 3.0
1 Arihant Madhumita Pattrea 880 2.0
2 Pearson Oscar Wilde 490 1.0
3 Disha Disha 1100 5.0
4 Cengage G Tewani 450 4.0
Sorting Column with some similar values
import pandas as pd
df = pd.DataFrame.from_dict({
'Date': ['2021-12-01', '2021-12-01',
'2021-12-01', '2021-12-02', '2021-12-
02'],
'Stock_Owner': ['Robert', 'Jhon', 'Maria', 'Juliet', 'Maxx'],
'Stocks': [100, 110, 100, 95, 130]
})
print("Pandas DataFrame:n",df)
print()
df.sort_values("Stocks", inplace = True)
df["Rank"] = df["Stocks"].rank(method ='average')
print("Ranked DataFrame :n",df)
Pandas DataFrame:
Date Stock_Owner Stocks
0 2021-12-01 Robert 100
1 2021-12-01 Jhon 110
2 2021-12-01 Maria 100
3 2021-12-02 Juliet 95
4 2021-12-02 Maxx 130
Ranked DataFrame :
Date Stock_Owner Stocks Rank
3 2021-12-02 Juliet 95 1.0
0 2021-12-01 Robert 100 2.5
2 2021-12-01 Maria 100 2.5
1 2021-12-01 Jhon 110 4.0
4 2021-12-02 Maxx 130 5.0
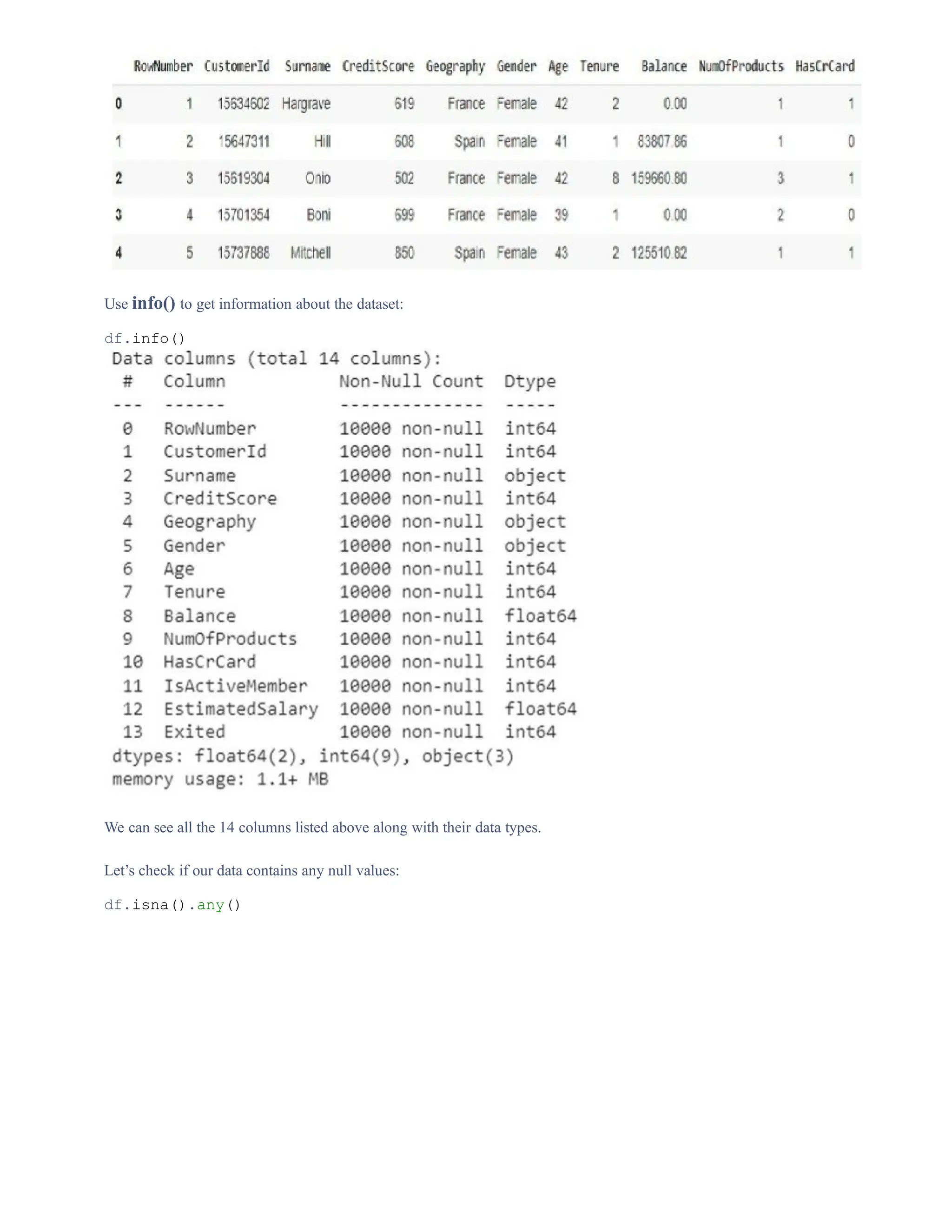
Sorting:
import pandas as pd
#Loading the dataset
df = pd.read_csv("Churn Modeling.csv")
df.head()](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-11-2048.jpg)
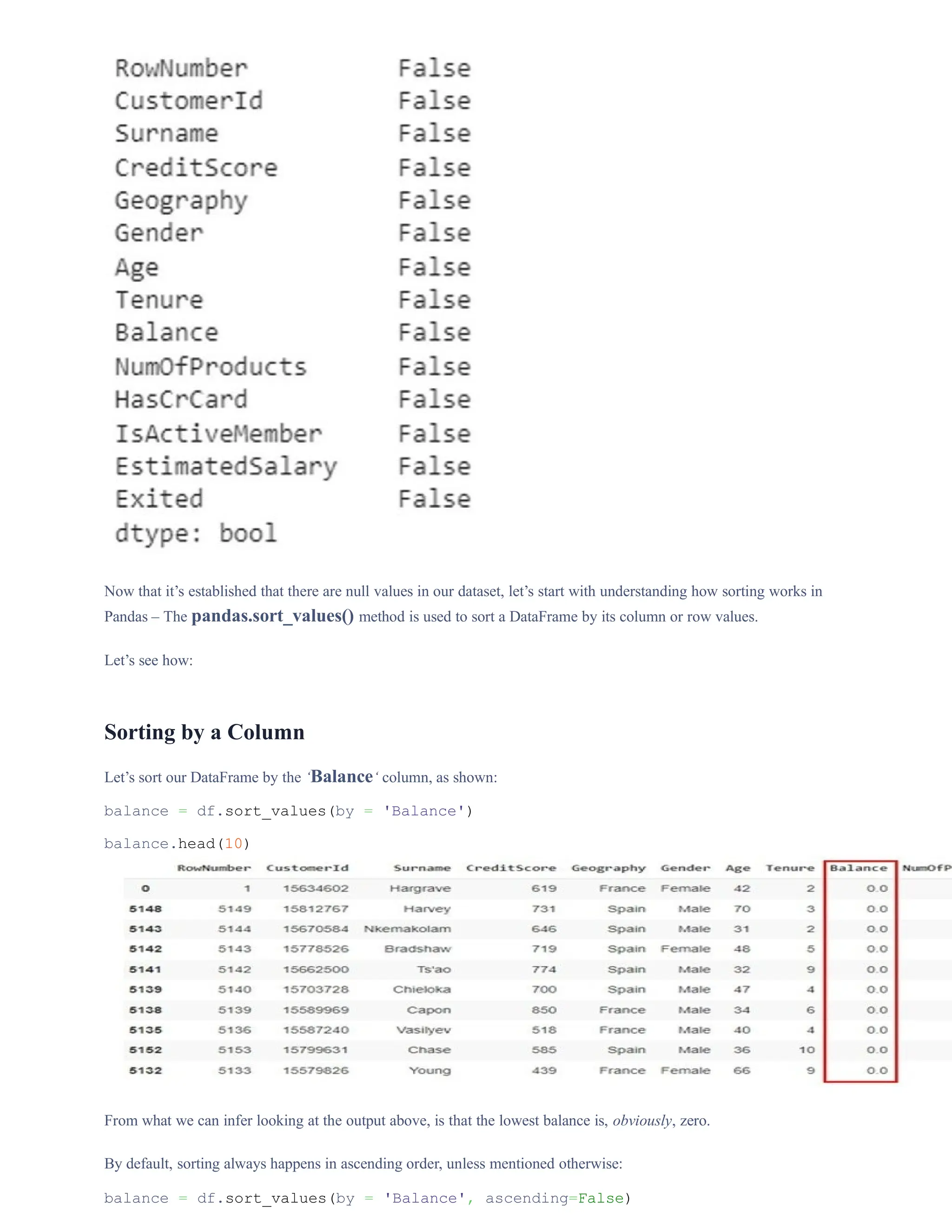
![balance.head(10)
Sorting by Multiple Columns
We can also sort our DataFrame by more than one column at a time:
df.sort_values(by=['Geography','CreditScore']).head(10)
Sorting by multiple column with different sort orders
Sorting by Column Names
The sort_index() method can also be used to sort the DataFrame using the column names instead of rows.
For this, we need to set the axis parameter to 1:
df.sort_index(axis=1).head(10)](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-14-2048.jpg)
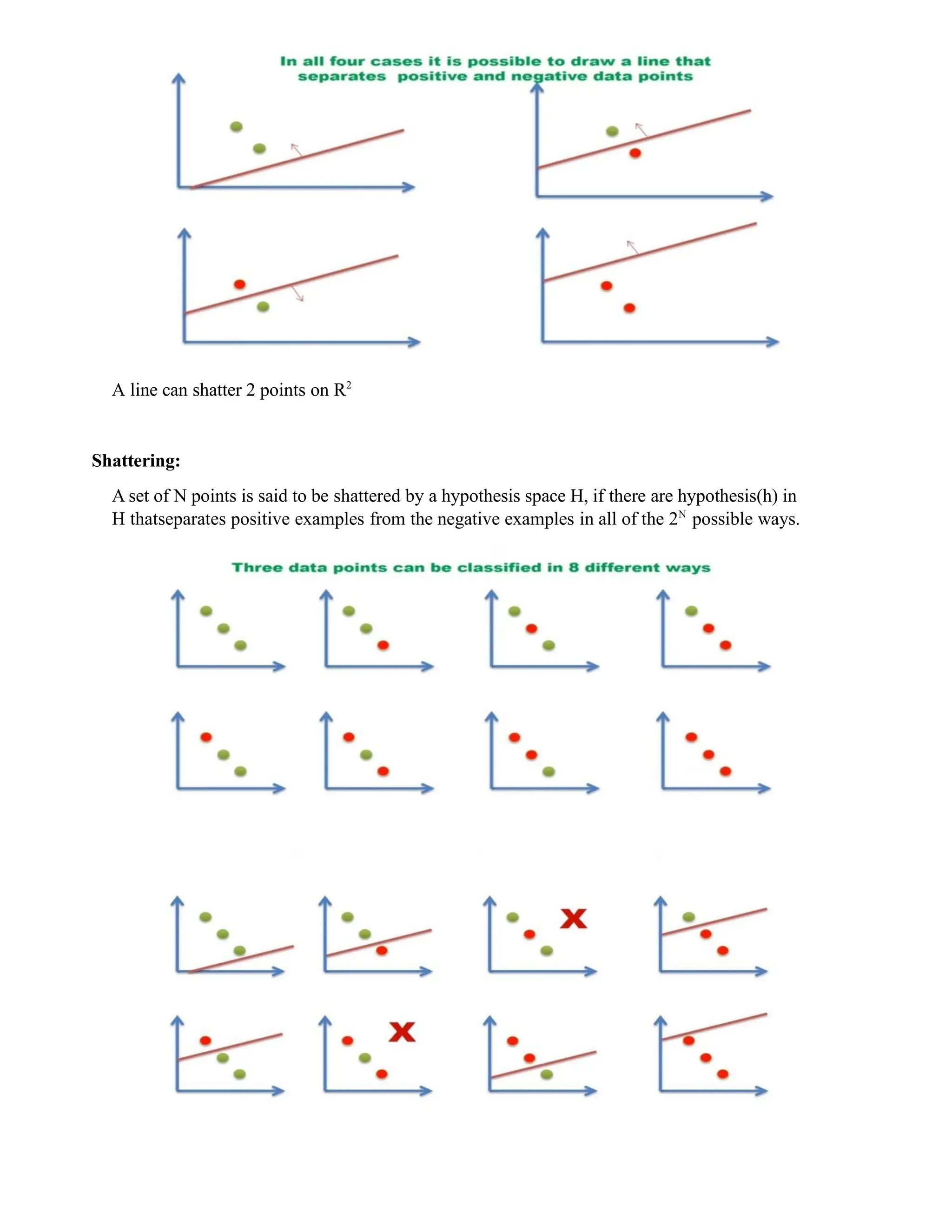
![Probably Approximately Correct (PAC) Learning
PAC learning is a framework for the mathematical analysis of machine learning.
Goal of PAC: With high probability(“Probable”), the selected hypothesis will have lower error
(“approximately correct”)
Ɛ and δ parameters:
In the PAC model, we specify two small parameters, Ɛ and δ, and require that with probability
at least(1-δ) a system learn a concept with error at most .
Ɛ
Ɛ gives an upper bound on the error in accuracy with which h approximated (accuracy: 1- )
Ɛ
δ gives the probability of failure in achieving this accuracy (Confidence: 1-δ)
Ex: Learn the concept of “medium built person”, when given height and weight of m
individuals. Theinstance will include [height, weight] pair and the person are medium built or
not.
The following figure shows the plot of the training examples in axis aligned rectangle in 2D
plane. Theaxis aligned rectangle is the target concept.
Instances within the rectangle represents positive instances ie medium built person. Instances
outsidethe rectangle is the negative instances ie the persons are not medium built.
The learning C is unknown to the learner, so the learner generates hypothesis h that
closelyapproximates C. Since h may not be exactly same as C, results in error region.
The instances that fall within the green shaded region are all positive members according to
actual function C whereas the generated hypothesis classifies them as negative, so these
instances are calledas False Negatives.
According to C, the instances in the yellow shaded region are negative, whereas the hypothesis
classifiesthese instances as positive, so they are called as False Positives.
Error Region: C XOR h](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-15-2048.jpg)



![Algorithmic steps:
Initially : G = [[?, ?, ?, ?, ?, ?], [?, ?, ?, ?, ?, ?],
[?, ?, ?, ?, ?,
?],
[?, ?, ?, ?, ?, ?], [?, ?, ?, ?, ?, ?],
[?, ?, ?, ?, ?,
?]]
S = [Null, Null, Null, Null, Null, Null]
For instance 1 : <'sunny','warm','normal','strong','warm
','same'> and positive output.
G1 = G
S1 = ['sunny','warm','normal','strong','warm
','same']
Candidate Elimination Algorithm:
The candidate elimination algorithm incrementally builds the version space given a hypothesis
space H and a set E of examples. The examples are added one by one; each example possibly
shrinks the version space by removing the hypotheses that are inconsistent with the example.
The candidate elimination algorithm does this by updating the general and specific boundary for
each new example.
You can consider this as an extended form of the Find-S algorithm.
Consider both positive and negative examples.
Actually, positive examples are used here as the Find-S algorithm (Basically they are
generalizing from the specification).
While the negative example is specified in the generalizing form.
Terms Used:
Concept learning: Concept learning is basically the learning task of the machine (Learn by
Train data)
General Hypothesis: Not Specifying features to learn the machine.
G = {‘?’, ‘?’,’?’,’?’…}: Number of attributes
Specific Hypothesis: Specifying features to learn machine (Specific feature)
S= {‘pi’,’pi’,’pi’…}: The number of pi depends on a number of attributes.
Version Space: It is an intermediate of general hypothesis and Specific hypothesis. It not only
just writes one hypothesis but a set of all possible hypotheses based on training data-set.
Algorithm:
Step1: Load Data set
Step2: Initialize General Hypothesis and Specific
Hypothesis.
Step3: For each training example
Step4: If example is positive example
if attribute_value == hypothesis_value:
Do
nothing
else:
replac
e
attribute
value
with '?'
(Basicall
y
generaliz
ing
it)
Step5: If example
is Negative example
Make
generalize
hypothesis
more
specific.
Example:
Consider the dataset
given below:](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-22-2048.jpg)
![For instance 2 : <'sunny','warm','high','strong','warm
','same'> and positive output.
G2 = G
S2 = ['sunny','warm',?,'strong','warm ','same']
For instance 3 : <'rainy','cold','high','strong','warm
','change'> and negative output.
G3 = [['sunny', ?, ?, ?, ?, ?], [?,
'warm', ?, ?, ?, ?], [?,
?, ?, ?, ?, ?],
[?, ?, ?, ?, ?, ?], [?, ?, ?, ?, ?, ?],
[?, ?, ?, ?,
?, 'same']]
S3 = S2
For instance 4 :
<'sunny','warm','high','strong','cool','change'> and
positive output.
G4 = G3
S4 = ['sunny','warm',?,'strong', ?, ?]
At last, by synchronizingthe G4 and S4 algorithm produce the
output.
Output :
G = [['sunny', ?, ?, ?, ?, ?], [?, 'warm', ?, ?, ?, ?]]
S = ['sunny','warm',?,'strong', ?, ?]
The Candidate Elimination Algorithm (CEA) is an improvement over the Find-S algorithm for
classification tasks. While CEA shares some similarities with Find-S, it also has some essential
differences that offer advantages and disadvantages. Here are some advantages and
disadvantages of CEA in comparison with Find-S:
Advantages of CEA over Find-S:
1. Improved accuracy: CEA considers both positive and negative examples to generate
the hypothesis, which can result in higher accuracy when dealing with noisy or
incomplete data.
2. Flexibility: CEA can handle more complex classification tasks, such as those with multiple
classes or non-linear decision boundaries.
3. More efficient: CEA reduces the number of hypotheses by generating a set of general
hypotheses and then eliminating them one by one. This can result in faster processing and
improved efficiency.
4. Better handling of continuous attributes: CEA can handle continuous attributes by
creating boundaries for each attribute, which makes it more suitable for a wider
range of datasets.
Disadvantages of CEA in comparison with Find-S:
5. More complex: CEA is a more complex algorithm than Find-S, which may make it more
difficult for beginners or those without a strong background in machine learning to use and
understand.
6. Higher memory requirements: CEA requires more memory to store the set of hypotheses
and
boundaries, which may make it less suitable for memory-constrained environments.
3. Slower processing for large datasets: CEA may become slower for larger datasets due to
the increased number of hypotheses generated.
4. Higher potential for overfitting: The increased complexity of CEA may make it more
prone to overfitting on the training data, especially if the dataset is small or has a high
degree of noise.](https://image.slidesharecdn.com/unit1-introductiontodatascience-241211144152-e88ccf2d/75/Unit-1-Introduction-to-Data-Science-pptx-23-2048.jpg)