"default task-1" #97prio=5 os_prio=0 tid=0x000000000401cfe0 nid=0x44d5 runnable [0x00007fd1f6dd7000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e2fa5718> (a sun.nio.ch.Util$3)
- locked <0x00000000e2fa5708> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e2fa55f0> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.xnio.nio.SelectorUtils.await(SelectorUtils.java:51)
at org.xnio.nio.NioSocketConduit.awaitReadable(NioSocketConduit.java:358)
Issue
● Intermittent long-running request thread 발생
○ over 5 secs, normally under 1 secs
○ Causing running threads accumulation !!
● Performance Issue !!!
● Why does this occur ?
● Needs investigation
2
3.
"default task-1" #97prio=5 os_prio=0 tid=0x000000000401cfe0 nid=0x44d5 runnable [0x00007fd1f6dd7000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e2fa5718> (a sun.nio.ch.Util$3)
- locked <0x00000000e2fa5708> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e2fa55f0> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.xnio.nio.SelectorUtils.await(SelectorUtils.java:51)
at org.xnio.nio.NioSocketConduit.awaitReadable(NioSocketConduit.java:358)
at org.xnio.conduits.AbstractSourceConduit.awaitReadable(AbstractSourceConduit.java:66)
at org.xnio.conduits.AbstractSourceConduit.awaitReadable(AbstractSourceConduit.java:66)
at io.undertow.conduits.ReadDataStreamSourceConduit.awaitReadable(ReadDataStreamSourceConduit.java:101)
at io.undertow.conduits.FixedLengthStreamSourceConduit.awaitReadable(FixedLengthStreamSourceConduit.java:285)
at org.xnio.conduits.ConduitStreamSourceChannel.awaitReadable(ConduitStreamSourceChannel.java:151)
at io.undertow.channels.DetachableStreamSourceChannel.awaitReadable(DetachableStreamSourceChannel.java:77)
at io.undertow.server.HttpServerExchange$ReadDispatchChannel.awaitReadable(HttpServerExchange.java:2161)
at org.xnio.channels.Channels.readBlocking(Channels.java:295)
at io.undertow.servlet.spec.ServletInputStreamImpl.readIntoBuffer(ServletInputStreamImpl.java:184)
at io.undertow.servlet.spec.ServletInputStreamImpl.read(ServletInputStreamImpl.java:160)
at com.fasterxml.jackson.core.json.ByteSourceJsonBootstrapper.ensureLoaded(ByteSourceJsonBootstrapper.java:522)
...
at io.undertow.servlet.handlers.ServletInitialHandler.dispatchRequest(ServletInitialHandler.java:272)
at io.undertow.servlet.handlers.ServletInitialHandler.access$000(ServletInitialHandler.java:81)
at io.undertow.servlet.handlers.ServletInitialHandler$1.handleRequest(ServletInitialHandler.java:104)
at io.undertow.server.Connectors.executeRootHandler(Connectors.java:326)
at io.undertow.server.HttpServerExchange$1.run(HttpServerExchange.java:812)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
3
4.
● Web Browser=> Apache => JBoss EAP
● Where is it from ?
○ EAP ?
○ Apache ?
● Access log
● Capturing tcpdumps
Investigation
4
5.
● Web Browser=> Apache => JBoss EAP
● By the tcpdump analysis,
● There is time gap between request header and body packet
● in Client side.
Investigation - conclusion
5
6.
Undertow 버전
● EAP7.1 은 Undertow 1.4.18.Final 버전을 사용
○ https://access.redhat.com/articles/112673#EAP_7
○ https://github.com/undertow-io/undertow/tree/1.4.18.Final
6
RequestBufferingHandler 기본 소개
●Undertow 가 제공하는 HTTP Handler(filter) 중 하나
● 기능:
○ Request 의 모든 패킷 데이터가 도착 하면 Request를 Worker Thread 로 dispatch 한다.
● 효과:
○ 해당 필터를 추가하면 간헐적 네트워크 지연등으로 Request 패킷 전송이 늦어지는 경우
Worker Thread 의 데이터 읽기 대기 상태(epollWait)로 인한 thread blocking 상태를 피할 수
있다.
● 영향:
○ GC 대상 객체 추가 발생. 지연 발생 요청 건마다 RequestBufferingHandler 의 이벤트 listener
객체(40 bytes)가 생성되고 요청 완료 후 GC의 대상이됨.
● 소스코드:
○ https://github.com/undertow-io/undertow/blob/1.4.18.Final/core/src/main/java/io/undertow/serv
er/handlers/RequestBufferingHandler.java
8
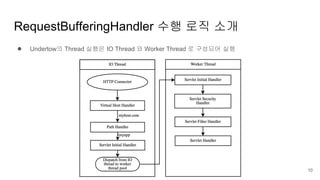
● Undertow의 Thread실행은 IO Thread 와 Worker Thread 로 구성되어 실행
RequestBufferingHandler 수행 로직 소개
10
11.
● IO Thread는 이름 그대로 I/O 만 담당하는 Thread
● Request의 비즈니스 로직 수행은 Worker Thread 에서 실행
● IO Thread 는 항상 non-blocking 방식으로 처리된다.
○ IO Thread 는 I/O 수행 요청이 생기면 즉시 I/O 에 대한 부분만 처리 후 다른 처리 부분은
Worker Thread 로 넘기고 즉시 또 다른 I/O 수행을 처리하거나 대기하게됨
● 반면 Worker Thread 는 하나의 Request의 완전한 처리를 위해서 blocking 되어 처리를 수행함
● Undertow는 request/response 의 모든 데이터를 HttpServerExchange 객체에 담아서 처리한다.
RequestBufferingHandler 수행 로직 소개
11
12.
● Undertow는 Requestheader가 도착하면 HttpServerExchange 객체를 생성하여
RequestBufferingHandler.handleRequest() 메소드를 호출한다.
● RequestBufferingHandler.handleRequest() 메소드는 Request의 모든 데이터를 읽기 시도한다.
● 하지만 만약 패킷 전송 지연과 같은 경우 데이터 읽기를 기다려야 하는 경우 ChannelListener
객체를 생성하여 Connection 객체에 event listener로 등록한다.
● RequestBufferingHandler.handleRequest() 메소드의 수행은 종료된다.
● 이제 다시 나머지 패킷 데이터가 전송되면 Connection 객체가 등록된 listener 객체에 데이터 전송
이벤트를 알려주어 ChannelListener 객체의 handleEvent() 메소드가 콜백되어 다시 데이터를
읽게된다.
● 데이터를 모두 읽었다면 버퍼링 데이터 객체(bufferedData[]) 에 데이터를 넣고 HttpServerExchange
객체에 담은 후 다음 handler로 호출을 넘긴다.
RequestBufferingHandler 수행 로직 소개
12
● 새로운 Request가도착하면, 가장 먼저 해당 Request 의 모든 데이터가 이미 모두 읽혀졌는지
확인한다. 그리고 동시에 header에 "Expect: 100-continue" 가 존재하는지 확인한다.
○ if(!exchange.isRequestComplete() &&
!HttpContinue.requiresContinueResponse(exchange.getRequestHeaders()))
● 만약 Request 의 모든 데이터가 이미 모두 읽혀졌다면 RequestBufferingHandler의 버퍼링 로직
수행 없이 바로 다음 handler로 호출이 넘겨진다(=> 다음 filter 수행 또는 Worker Thread 로
dispatch).
● 만약 아직 Request 의 모든 데이터를 읽지 못 하였고, "Expect: 100-continue" header 가 존재하지
않는다면, 다음의 버퍼링 로직을 수행하게된다.
RequestBufferingHandler 수행 로직 상세
14
15.
RequestBufferingHandler 수행 로직상세
● Connection 채널에서 데이터를 읽어서 버퍼(b)에 채워넣는 루프를 수행한다.
● 데이터를 모두 읽었다면 버퍼(b) 데이터를 bufferedData[] 에 넣고 exchange 객체에 담은 후 다음
handler로 호출을 넘기고 루프를 종료한다.
● 하지만 데이터를 읽는 중에 네트워크 지연등의 이유로 데이터가 아직 도착하지 않고 기다려야 하는
조건이 발생하면 기다리지 않고(non-blocking) 즉시 ChannelListener 객체를 생성하여 Connection
객체에 event listener로 등록한다. 이렇게되면 더이상 Thread 실행 없이 기다릴 수 있게된다
(non-blocking).
● (나머지 패킷) 데이터가 다시 도착하면 IO Thread에서 Connection 객체가 등록된 event listener
객체에 데이터 전송 이벤트를 알려주어 handleEvent() 메소드가 콜백되어 데이터를 읽게된다.
● 이제 다시 나머지 패킷 데이터가 전송되면, 위의 수행 로직과 동일한 "Connection 채널에서
데이터를 읽어서 버퍼(b)에 채워넣는 루프"를 수행한다. 데이터를 모두 읽었다면 버퍼(b) 데이터를
bufferedData[] 에 넣고 exchange 객체에 담은 후 다음 handler로 호출을 넘기고 루프를 종료한다. 15
16.
public void handleRequest(finalHttpServerExchange exchange) throws Exception {
if(!exchange.isRequestComplete() && !HttpContinue.requiresContinueResponse(exchange.getRequestHeaders())) {
do {
// 채널에서 데이터를 읽어서 버퍼(b)에 채워넣기기 루프
ByteBuffer b = buffer.getBuffer();
r = channel.read(b);
if (r == -1) {
// 데이터 다읽어서 exchange 객체에 담고 리턴
} else if(r == 0) {
// 데이터 없어서 기다림
channel.getReadSetter().set(new ChannelListener<StreamSourceChannel>() {
public void handleEvent(StreamSourceChannel channel) {
do {
// 채널에서 데이터를 읽어서 버퍼(b)에 채워넣기 루프
if (r == -1) {
// 데이터 다읽어서 exchange 객체에 담고 리턴
} else if (r == 0) {
// 데이터 없어서 기다림
} else if (!b.hasRemaining()) {
// 버퍼(b)가 꽉참 => 데이터 크기가 버퍼보다 크다는 의미
// expression="buffer-request(buffers=2)" 와 같이 buffers 사이즈가 1보다 크다면
// bufferedData[]에 버퍼(b)를 백업하고 새로운 버퍼(b)를 할당 받아서 "채널에서 데이터 읽어서 버퍼(b)에 채워넣기기 루프"를 돌면서 나머지 데이터를 읽게됨
}
// 버퍼(b)에 아직 빈 공간이 남아있음
} while (true);
}
});
} else if (!b.hasRemaining()) {
// 버퍼(b)가 꽉참 => 데이터 크기가 버퍼보다 크다는 의미
}
// 버퍼(b)에 아직 빈 공간이 남아있음
} while (true);
}
next.handleRequest(exchange);
}
16
17.
● Connection 채널에서데이터를 읽는 단위가 버퍼(b) 사이즈이다.
○ 버퍼(b) 사이즈는 IO subsystem의 buffer-size 값으로 설정된다.
○ <buffer-pool name="default" buffer-size="<정수값>"/>
○ 기본값 16 kbytes
● buffer-size * buffers 배열 사이즈 만큼 Request 데이터를 버퍼링 할 수 있다.
○ buffers 는 버퍼(b)들을 담는 배열 객체
○ <expression-filter name="buf" expression="buffer-request(buffers=<정수값>)"/>
● buffer-size 를 기본값 보다 크게 buffers 값을 1보다 크게 설정한다면 “java.lang.OutOfMemoryError:
Direct buffer memory” 에러가 발생할 수 있다.
● RequestBufferingHandler 에서 버퍼링 사이즈가 부족하더라도
FixedLengthStreamSourceConduit.read() 에서 데이터를 모두 읽어서 Request는 정상 처리됨
● 기본 설정값 사용 권장 buffer-size 기본값(16kb), buffers=1
추가 상세 정보
17
18.
추가 상세 정보
[1]buffer-size 를 기본값 보다 크게 buffers 값을 1보다 크게 설정한다면 “java.lang.OutOfMemoryError: Direct buffer memory”
에러가 발생할 수 있다.
2018-02-17 11:25:30,259 ERROR [org.xnio.listener] (default I/O-1) org.xnio.ChannelListeners:94 - XNIO001007: A channel event listener threw an
exception: java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:693)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at org.xnio.BufferAllocator$2.allocate(BufferAllocator.java:57)
at org.xnio.BufferAllocator$2.allocate(BufferAllocator.java:55)
at org.xnio.ByteBufferSlicePool.allocate(ByteBufferSlicePool.java:147)
at io.undertow.server.XnioByteBufferPool.allocate(XnioByteBufferPool.java:53)
at io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:177)
at io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:97)
at org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
at io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:231)
at io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:218)
at org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
at org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
at org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
at org.xnio.nio.WorkerThread.run(WorkerThread.java:591) 18
19.
[2] 데이터를 읽는중에 네트워크 지연등의 이유로 데이터가 아직 도착하지 않고 기다려야 하는 조건이 발생하면
ChannelListener 객체를 생성하여 Connection 객체에 event listener로 등록한다.
https://github.com/undertow-io/undertow/blob/1.4.18.Final/core/src/main/java/io/undertow/server/handlers/RequestBufferingHandler.java#L124-L125
RETURN *** Called io.undertow.server.handlers.RequestBufferingHandler.handleRequest() in thread default I/O-1
io.undertow.server.handlers.RequestBufferingHandler.handleRequest(RequestBufferingHandler.java:125)
io.undertow.predicate.PredicatesHandler.handleRequest(PredicatesHandler.java:93)
io.undertow.server.handlers.SetHeaderHandler.handleRequest(SetHeaderHandler.java:90)
io.undertow.server.handlers.accesslog.AccessLogHandler.handleRequest(AccessLogHandler.java:138)
org.wildfly.extension.undertow.Host$HostRootHandler.handleRequest(Host.java:345)
io.undertow.server.handlers.NameVirtualHostHandler.handleRequest(NameVirtualHostHandler.java:54)
io.undertow.server.handlers.error.SimpleErrorPageHandler.handleRequest(SimpleErrorPageHandler.java:78)
io.undertow.server.handlers.CanonicalPathHandler.handleRequest(CanonicalPathHandler.java:49)
org.wildfly.extension.undertow.Server$DefaultHostHandler.handleRequest(Server.java:189)
io.undertow.server.handlers.ChannelUpgradeHandler.handleRequest(ChannelUpgradeHandler.java:211)
io.undertow.server.protocol.http2.Http2UpgradeHandler.handleRequest(Http2UpgradeHandler.java:129)
io.undertow.server.handlers.DisallowedMethodsHandler.handleRequest(DisallowedMethodsHandler.java:61)
io.undertow.server.Connectors.executeRootHandler(Connectors.java:326)
io.undertow.server.protocol.http.HttpReadListener.handleEventWithNoRunningRequest(HttpReadListener.java:254)
io.undertow.server.protocol.http.HttpReadListener.handleEvent(HttpReadListener.java:136)
io.undertow.server.protocol.http.HttpReadListener.handleEvent(HttpReadListener.java:59)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
org.xnio.nio.WorkerThread.run(WorkerThread.java:591)
19
20.
[3] (나머지 패킷)데이터가 다시 도착하면 IO Thread에서 Connection 객체가 등록된 event listener 객체에 데이터 전송
이벤트를 알려주어 handleEvent() 메소드가 콜백되어 데이터를 읽게된다.
https://github.com/undertow-io/undertow/blob/1.4.18.Final/core/src/main/java/io/undertow/server/handlers/RequestBufferingHandler.java#L77-L99
RETURN *** Called io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent() in thread default I/O-1
io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:99)
io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:77)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:231)
io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:218)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
org.xnio.nio.WorkerThread.run(WorkerThread.java:591)
20


!["default task-1" #97 prio=5 os_prio=0 tid=0x000000000401cfe0 nid=0x44d5 runnable [0x00007fd1f6dd7000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e2fa5718> (a sun.nio.ch.Util$3)
- locked <0x00000000e2fa5708> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e2fa55f0> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.xnio.nio.SelectorUtils.await(SelectorUtils.java:51)
at org.xnio.nio.NioSocketConduit.awaitReadable(NioSocketConduit.java:358)
Issue
● Intermittent long-running request thread 발생
○ over 5 secs, normally under 1 secs
○ Causing running threads accumulation !!
● Performance Issue !!!
● Why does this occur ?
● Needs investigation
2](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-2-320.jpg)
!["default task-1" #97 prio=5 os_prio=0 tid=0x000000000401cfe0 nid=0x44d5 runnable [0x00007fd1f6dd7000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x00000000e2fa5718> (a sun.nio.ch.Util$3)
- locked <0x00000000e2fa5708> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000000e2fa55f0> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.xnio.nio.SelectorUtils.await(SelectorUtils.java:51)
at org.xnio.nio.NioSocketConduit.awaitReadable(NioSocketConduit.java:358)
at org.xnio.conduits.AbstractSourceConduit.awaitReadable(AbstractSourceConduit.java:66)
at org.xnio.conduits.AbstractSourceConduit.awaitReadable(AbstractSourceConduit.java:66)
at io.undertow.conduits.ReadDataStreamSourceConduit.awaitReadable(ReadDataStreamSourceConduit.java:101)
at io.undertow.conduits.FixedLengthStreamSourceConduit.awaitReadable(FixedLengthStreamSourceConduit.java:285)
at org.xnio.conduits.ConduitStreamSourceChannel.awaitReadable(ConduitStreamSourceChannel.java:151)
at io.undertow.channels.DetachableStreamSourceChannel.awaitReadable(DetachableStreamSourceChannel.java:77)
at io.undertow.server.HttpServerExchange$ReadDispatchChannel.awaitReadable(HttpServerExchange.java:2161)
at org.xnio.channels.Channels.readBlocking(Channels.java:295)
at io.undertow.servlet.spec.ServletInputStreamImpl.readIntoBuffer(ServletInputStreamImpl.java:184)
at io.undertow.servlet.spec.ServletInputStreamImpl.read(ServletInputStreamImpl.java:160)
at com.fasterxml.jackson.core.json.ByteSourceJsonBootstrapper.ensureLoaded(ByteSourceJsonBootstrapper.java:522)
...
at io.undertow.servlet.handlers.ServletInitialHandler.dispatchRequest(ServletInitialHandler.java:272)
at io.undertow.servlet.handlers.ServletInitialHandler.access$000(ServletInitialHandler.java:81)
at io.undertow.servlet.handlers.ServletInitialHandler$1.handleRequest(ServletInitialHandler.java:104)
at io.undertow.server.Connectors.executeRootHandler(Connectors.java:326)
at io.undertow.server.HttpServerExchange$1.run(HttpServerExchange.java:812)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
3](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-3-320.jpg)







![● Undertow는 Request header가 도착하면 HttpServerExchange 객체를 생성하여
RequestBufferingHandler.handleRequest() 메소드를 호출한다.
● RequestBufferingHandler.handleRequest() 메소드는 Request의 모든 데이터를 읽기 시도한다.
● 하지만 만약 패킷 전송 지연과 같은 경우 데이터 읽기를 기다려야 하는 경우 ChannelListener
객체를 생성하여 Connection 객체에 event listener로 등록한다.
● RequestBufferingHandler.handleRequest() 메소드의 수행은 종료된다.
● 이제 다시 나머지 패킷 데이터가 전송되면 Connection 객체가 등록된 listener 객체에 데이터 전송
이벤트를 알려주어 ChannelListener 객체의 handleEvent() 메소드가 콜백되어 다시 데이터를
읽게된다.
● 데이터를 모두 읽었다면 버퍼링 데이터 객체(bufferedData[]) 에 데이터를 넣고 HttpServerExchange
객체에 담은 후 다음 handler로 호출을 넘긴다.
RequestBufferingHandler 수행 로직 소개
12](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-12-320.jpg)


![RequestBufferingHandler 수행 로직 상세
● Connection 채널에서 데이터를 읽어서 버퍼(b)에 채워넣는 루프를 수행한다.
● 데이터를 모두 읽었다면 버퍼(b) 데이터를 bufferedData[] 에 넣고 exchange 객체에 담은 후 다음
handler로 호출을 넘기고 루프를 종료한다.
● 하지만 데이터를 읽는 중에 네트워크 지연등의 이유로 데이터가 아직 도착하지 않고 기다려야 하는
조건이 발생하면 기다리지 않고(non-blocking) 즉시 ChannelListener 객체를 생성하여 Connection
객체에 event listener로 등록한다. 이렇게되면 더이상 Thread 실행 없이 기다릴 수 있게된다
(non-blocking).
● (나머지 패킷) 데이터가 다시 도착하면 IO Thread에서 Connection 객체가 등록된 event listener
객체에 데이터 전송 이벤트를 알려주어 handleEvent() 메소드가 콜백되어 데이터를 읽게된다.
● 이제 다시 나머지 패킷 데이터가 전송되면, 위의 수행 로직과 동일한 "Connection 채널에서
데이터를 읽어서 버퍼(b)에 채워넣는 루프"를 수행한다. 데이터를 모두 읽었다면 버퍼(b) 데이터를
bufferedData[] 에 넣고 exchange 객체에 담은 후 다음 handler로 호출을 넘기고 루프를 종료한다. 15](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-15-320.jpg)
![public void handleRequest(final HttpServerExchange exchange) throws Exception {
if(!exchange.isRequestComplete() && !HttpContinue.requiresContinueResponse(exchange.getRequestHeaders())) {
do {
// 채널에서 데이터를 읽어서 버퍼(b)에 채워넣기기 루프
ByteBuffer b = buffer.getBuffer();
r = channel.read(b);
if (r == -1) {
// 데이터 다읽어서 exchange 객체에 담고 리턴
} else if(r == 0) {
// 데이터 없어서 기다림
channel.getReadSetter().set(new ChannelListener<StreamSourceChannel>() {
public void handleEvent(StreamSourceChannel channel) {
do {
// 채널에서 데이터를 읽어서 버퍼(b)에 채워넣기 루프
if (r == -1) {
// 데이터 다읽어서 exchange 객체에 담고 리턴
} else if (r == 0) {
// 데이터 없어서 기다림
} else if (!b.hasRemaining()) {
// 버퍼(b)가 꽉참 => 데이터 크기가 버퍼보다 크다는 의미
// expression="buffer-request(buffers=2)" 와 같이 buffers 사이즈가 1보다 크다면
// bufferedData[]에 버퍼(b)를 백업하고 새로운 버퍼(b)를 할당 받아서 "채널에서 데이터 읽어서 버퍼(b)에 채워넣기기 루프"를 돌면서 나머지 데이터를 읽게됨
}
// 버퍼(b)에 아직 빈 공간이 남아있음
} while (true);
}
});
} else if (!b.hasRemaining()) {
// 버퍼(b)가 꽉참 => 데이터 크기가 버퍼보다 크다는 의미
}
// 버퍼(b)에 아직 빈 공간이 남아있음
} while (true);
}
next.handleRequest(exchange);
}
16](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-16-320.jpg)

![추가 상세 정보
[1] buffer-size 를 기본값 보다 크게 buffers 값을 1보다 크게 설정한다면 “java.lang.OutOfMemoryError: Direct buffer memory”
에러가 발생할 수 있다.
2018-02-17 11:25:30,259 ERROR [org.xnio.listener] (default I/O-1) org.xnio.ChannelListeners:94 - XNIO001007: A channel event listener threw an
exception: java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:693)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at org.xnio.BufferAllocator$2.allocate(BufferAllocator.java:57)
at org.xnio.BufferAllocator$2.allocate(BufferAllocator.java:55)
at org.xnio.ByteBufferSlicePool.allocate(ByteBufferSlicePool.java:147)
at io.undertow.server.XnioByteBufferPool.allocate(XnioByteBufferPool.java:53)
at io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:177)
at io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:97)
at org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
at io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:231)
at io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:218)
at org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
at org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
at org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
at org.xnio.nio.WorkerThread.run(WorkerThread.java:591) 18](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-18-320.jpg)
![[2] 데이터를 읽는 중에 네트워크 지연등의 이유로 데이터가 아직 도착하지 않고 기다려야 하는 조건이 발생하면
ChannelListener 객체를 생성하여 Connection 객체에 event listener로 등록한다.
https://github.com/undertow-io/undertow/blob/1.4.18.Final/core/src/main/java/io/undertow/server/handlers/RequestBufferingHandler.java#L124-L125
RETURN *** Called io.undertow.server.handlers.RequestBufferingHandler.handleRequest() in thread default I/O-1
io.undertow.server.handlers.RequestBufferingHandler.handleRequest(RequestBufferingHandler.java:125)
io.undertow.predicate.PredicatesHandler.handleRequest(PredicatesHandler.java:93)
io.undertow.server.handlers.SetHeaderHandler.handleRequest(SetHeaderHandler.java:90)
io.undertow.server.handlers.accesslog.AccessLogHandler.handleRequest(AccessLogHandler.java:138)
org.wildfly.extension.undertow.Host$HostRootHandler.handleRequest(Host.java:345)
io.undertow.server.handlers.NameVirtualHostHandler.handleRequest(NameVirtualHostHandler.java:54)
io.undertow.server.handlers.error.SimpleErrorPageHandler.handleRequest(SimpleErrorPageHandler.java:78)
io.undertow.server.handlers.CanonicalPathHandler.handleRequest(CanonicalPathHandler.java:49)
org.wildfly.extension.undertow.Server$DefaultHostHandler.handleRequest(Server.java:189)
io.undertow.server.handlers.ChannelUpgradeHandler.handleRequest(ChannelUpgradeHandler.java:211)
io.undertow.server.protocol.http2.Http2UpgradeHandler.handleRequest(Http2UpgradeHandler.java:129)
io.undertow.server.handlers.DisallowedMethodsHandler.handleRequest(DisallowedMethodsHandler.java:61)
io.undertow.server.Connectors.executeRootHandler(Connectors.java:326)
io.undertow.server.protocol.http.HttpReadListener.handleEventWithNoRunningRequest(HttpReadListener.java:254)
io.undertow.server.protocol.http.HttpReadListener.handleEvent(HttpReadListener.java:136)
io.undertow.server.protocol.http.HttpReadListener.handleEvent(HttpReadListener.java:59)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
org.xnio.nio.WorkerThread.run(WorkerThread.java:591)
19](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-19-320.jpg)
![[3] (나머지 패킷) 데이터가 다시 도착하면 IO Thread에서 Connection 객체가 등록된 event listener 객체에 데이터 전송
이벤트를 알려주어 handleEvent() 메소드가 콜백되어 데이터를 읽게된다.
https://github.com/undertow-io/undertow/blob/1.4.18.Final/core/src/main/java/io/undertow/server/handlers/RequestBufferingHandler.java#L77-L99
RETURN *** Called io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent() in thread default I/O-1
io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:99)
io.undertow.server.handlers.RequestBufferingHandler$1.handleEvent(RequestBufferingHandler.java:77)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:231)
io.undertow.channels.DetachableStreamSourceChannel$SetterDelegatingListener.handleEvent(DetachableStreamSourceChannel.java:218)
org.xnio.ChannelListeners.invokeChannelListener(ChannelListeners.java:92)
org.xnio.conduits.ReadReadyHandler$ChannelListenerHandler.readReady(ReadReadyHandler.java:66)
org.xnio.nio.NioSocketConduit.handleReady(NioSocketConduit.java:89)
org.xnio.nio.WorkerThread.run(WorkerThread.java:591)
20](https://image.slidesharecdn.com/undertowrequestbufferinghandler-jbug-181206042613/85/Undertow-RequestBufferingHandler-20-320.jpg)




![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Partner TechForum] 딥러닝 기반의 챗봇 기술을 활용한 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/chatbotaws-171122013303-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC2018] 에이스프로젝트 안현석 - 유니티로 실시간 멀티플레이 게임서버를 만들 수 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/5-181023014511-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - Http Request](https://cdn.slidesharecdn.com/ss_thumbnails/nexters3httprequest-160927090840-thumbnail.jpg?width=640&height=640&fit=bounds)
![[E6]2012. netty internals](https://cdn.slidesharecdn.com/ss_thumbnails/e62012-nettyinternals-120919020847-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















