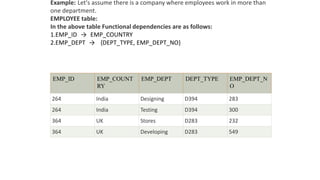
The document discusses data normalization and anomalies in relational database design, highlighting types of anomalies such as insertion, update, and deletion anomalies. It explains the process of normalization through various normal forms, including first, second, and third normal forms, along with Boyce-Codd Normal Form, and the importance of functional dependencies. Additionally, it covers the advantages and disadvantages of normalization and decomposition in a database management system.