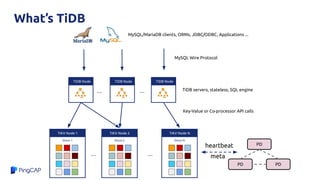
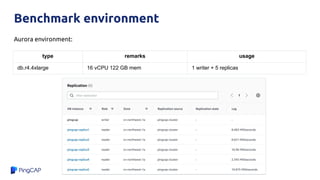
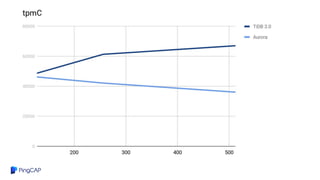
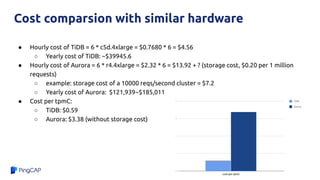
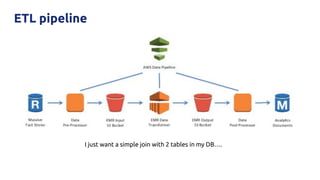
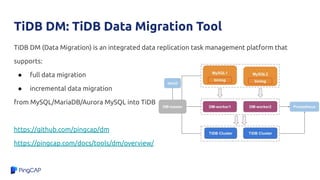
TiDB and Amazon Aurora can be combined to provide analytics on transactional data without needing a separate data warehouse. TiDB Data Migration (DM) tool allows migrating and replicating data from Aurora into TiDB for analytics queries. DM provides full data migration and incremental replication of binlog events from Aurora into TiDB. This allows joining transactional and analytical workloads on the same dataset without needing ETL pipelines.







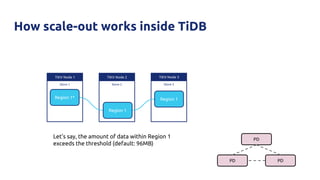
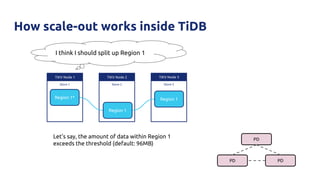
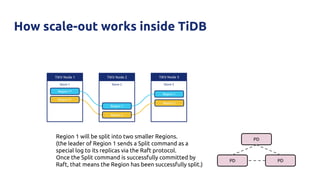
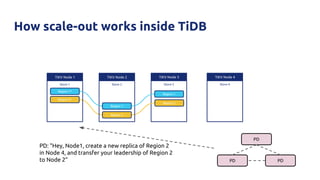
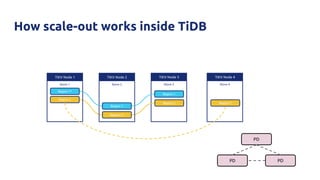
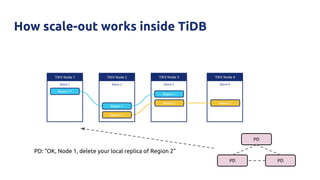
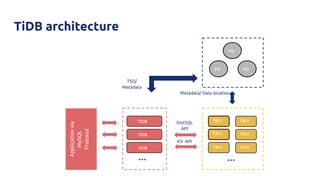





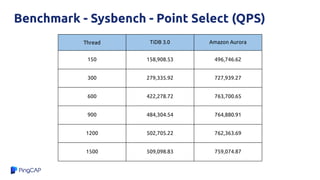
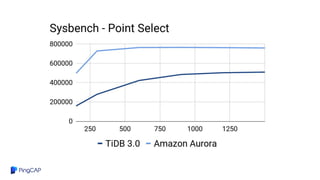
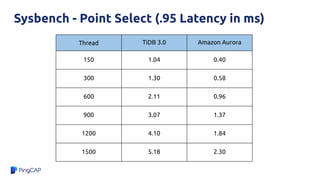
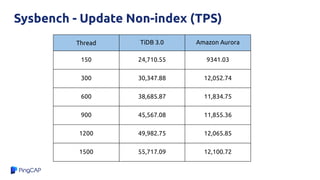
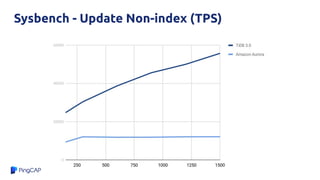
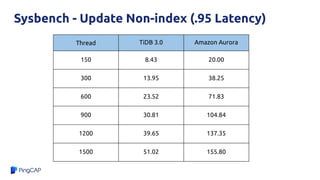
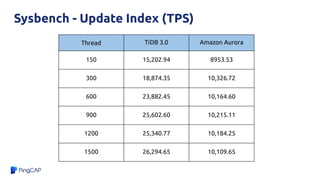
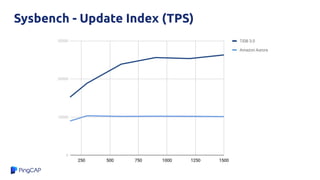
![Why?
A Query Execution Plan Example:
TiDB(root@127.0.0.1:test) > explain select count(*) from t1, t2 where t1.a=t2.a;
+--------------------------+----------+------+---------------------------------------------------------------------+
| id | count | task | operator info |
+--------------------------+----------+------+---------------------------------------------------------------------+
| StreamAgg_13 | 1.00 | root | funcs:count(1) |
| └─MergeJoin_33 | 12500.00 | root | inner join, left key:test.t1.a, right key:test.t2.a |
| ├─IndexReader_25 | 10000.00 | root | index:IndexScan_24 |
| │ └─IndexScan_24 | 10000.00 | cop | table:t1, index:a, range:[NULL,+inf], keep order:true, stats:pseudo |
| └─IndexReader_28 | 10000.00 | root | index:IndexScan_27 |
| └─IndexScan_27 | 10000.00 | cop | table:t2, index:a, range:[NULL,+inf], keep order:true, stats:pseudo |
+--------------------------+----------+------+---------------------------------------------------------------------+
6 rows in set (0.00 sec)](https://image.slidesharecdn.com/tidbvsaurora-221117112903-77427392/85/TiDB-vs-Aurora-pdf-43-320.jpg)


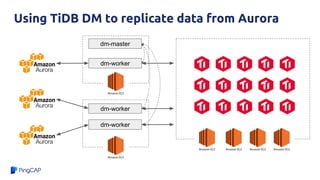

![Check list
● Enable binlog for Amazon Aurora, use ‘ROW’ mode
○ https://aws.amazon.com/premiumsupport/knowledge-center/enable-binary-logging-aurora/
● Enable GTID for Amazon Aurora
○ https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/mysql-replication-gtid.html#mysql-replication-gtid.co
nfiguring-aurora
● Make sure DM can connect to Amazon Aurora master (check security group rules)
● Ignore some unsupported syntax
○ ignore-checking-items: ["dump_privilege", "replication_privilege"]
○ example task.yaml: https://gist.github.com/c4pt0r/bcbf645ab475e5a603ad3d79d95c1757](https://image.slidesharecdn.com/tidbvsaurora-221117112903-77427392/85/TiDB-vs-Aurora-pdf-55-320.jpg)



![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)






![Introducing TiDB [Delivered: 09/25/18 at Portland Cloud Native Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/portlandk8smeetupintroducingtidb-180926052719-thumbnail.jpg?width=640&height=640&fit=bounds)




















![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)



![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












