Download to read offline





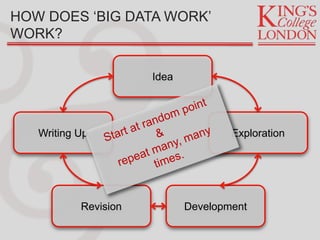
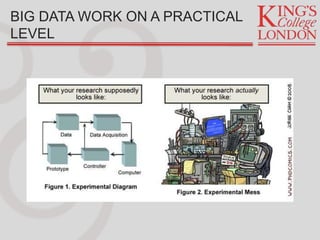




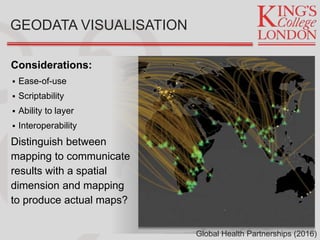
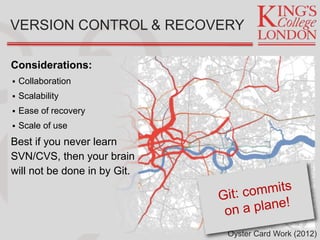








Jon Reades provides an overview of tools and technologies for effective development practices and research, drawing from his background in programming and academia. He discusses various considerations for selecting programming languages, collaboration tools, and data management practices while highlighting the shift from expensive proprietary software to affordable open-source options. Reades emphasizes the importance of documentation, backups, and utilizing proper data processes in research and operational environments.























































