Downloaded 43 times



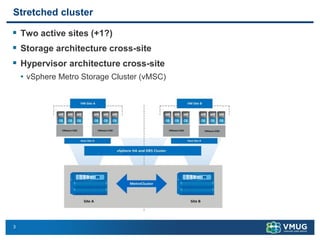
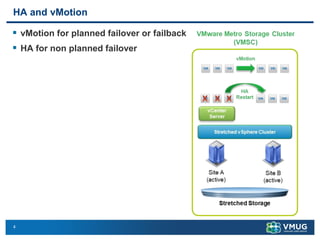



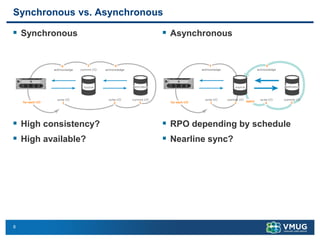
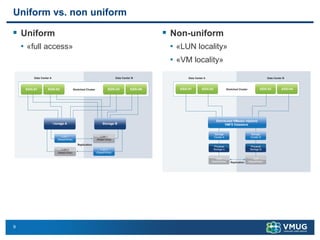



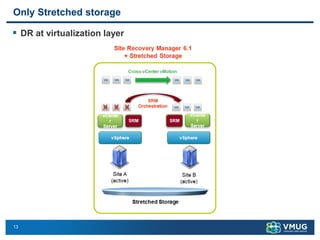
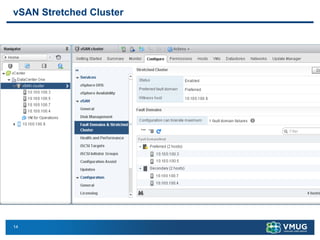

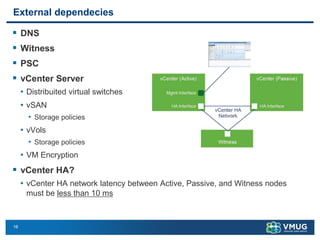







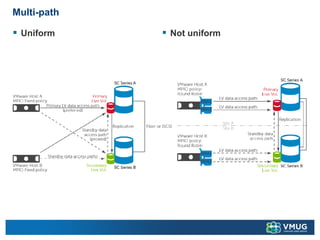



A stretched cluster connects data centers across different sites with shared storage and live migration capabilities. It provides both disaster avoidance and recovery benefits. Key requirements include low latency storage replication, sufficient network bandwidth for vMotion, and considerations for split-brain scenarios. While it improves availability during localized failures, a stretched cluster has limitations compared to independent disaster recovery sites. Additional sites or a traditional DR configuration provide multiple levels of protection.


































































