This is the summary of my bachelor thesis. It is about Musical Instrument recognition and shows:
* Features that can be extracted from sound.
* Machine learning basis.
* Decision algorithms.
* Statistical results.
Selecció de
característiques
Selecció de
classificadors
Configuració
Corpus
Configuració d’escenaris
Sistema de reconeixement
automàtic
Anàlisi de resultats
6.
Intensitat ivolum
Intensitat: quantitat absoluta
Volum: valor subjectiu
Altura: freqüència
Escala Mel
Duració
Timbre: permet diferenciar el mateix so produït per
dos instruments diferents
7.
Informació que s’extreude cada un dels petits
fragments en que es talla el senyal d’àudio
En el domini freqüencial
Centroide
Extensió
Coeficients MFCC
Roll-Off
En el domini temporal
Taxa de pas per zero
Energia
8.
Model de mesclesGaussianes (GMM)
Probabilístic i sense supervisió
K-veí més proper (k-NN)
Basat en distància
Molt senzill d’implementar. Alt cost de computació
Support Vector Machines (SVM)
Basat en distància
Dissenyat per a discernir entre dues classes.
Versions multi-classe.
9.
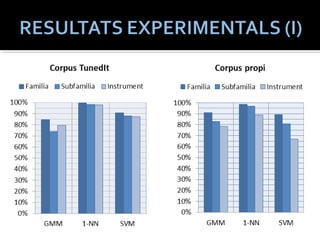
TunediT
115.000mostres (no es disposa de l’àudio original)
70 – 30 % (entrenament – test)
18 instruments (2 famílies – 8 subfamílies)
Generació pròpia
18 instruments (2 famílies – 8 subfamílies)
Entrenament: Gravació de cada una de les notes de
l’extensió de l’instrument
Test: Gravacions amb fraseig per cada instrument.
10.
Funcions relacionades ambl’extracció de les
característiques acústiques
cAudioList = TFCLoadAudioList (filename)
Cfeatures = TFCExtractFeatures (cAudioList,
windowSize)
TFCExportFeatures (audioListFile,
featuresFile, windowSize)
11.
Funcions relacionades ambla classificació
vWhat = [x x x x x x x x x x x x x x x x x x]
MFCC1 … MFCC13
cResults = TFCGMMCheck (cFTraining,
vWhat, scale, classType)
CResults = TFCGMMClassify (cFTraining,
cFTest, vWhat, scale, classType)
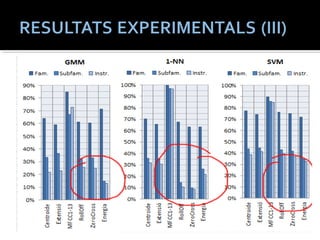
Centroide
Extensió
RollOff
ZeroCross
Energia
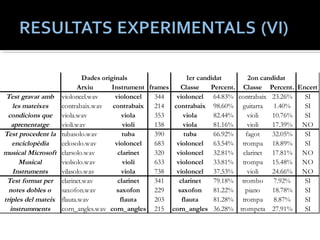
Arxiu Instrument framesClasse Percent. Classe Percent. Encert
violoncel.wav violoncel 344 violoncel 64.83% contrabaix 23.26% SI
contrabaix.wav contrabaix 214 contrabaix 98.60% guitarra 1.40% SI
viola.wav viola 353 viola 82.44% violi 10.76% SI
violi.wav violi 138 viola 81.16% violi 17.39% NO
tubasolo.wav tuba 390 tuba 66.92% fagot 32.05% SI
celosolo.wav violoncel 683 violoncel 63.54% trompa 18.89% SI
clarsolo.wav clarinet 320 violoncel 32.81% clarinet 17.81% NO
violsolo.wav violi 633 violoncel 33.81% trompa 15.48% NO
vilasolo.wav viola 738 violoncel 37.53% violi 24.66% NO
clarinet.wav clarinet 341 clarinet 79.18% trombo 7.92% SI
saxofon.wav saxofon 229 saxofon 81.22% piano 18.78% SI
flauta.wav flauta 203 flauta 81.28% trompa 8.87% SI
corn_angles.wav corn_angles 215 corn_angles 36.28% trompeta 27.91% SI
Test gravat amb
les mateixes
condicions que
aprenentatge
Test procedent la
enciclopèdia
musical Microsoft
Musical
Instruments
Test format per
notes dobles o
triples del mateix
instrumments
Dades originals 1er candidat 2on candidat
20.
Implementació funcionsper a:
Extreure característiques acústiques
Classificar e identificar mostres
Analitzar resultats
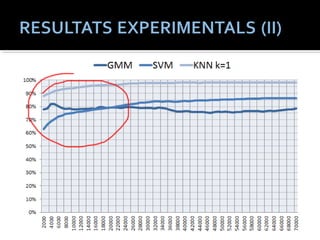
Experiments que mostren entre altres:
El nombre de mostres afecta de diferent manera als
resultats segons el mètode de classificació
La rellevància de les característiques acústiques depèn del
mètode de classificació
Hi ha instruments més fàcils d’identifcar amb un mètode
que amb un altre
El fraseig harmònic redueix el percentatge d’encerts
#2 Sóc Juan Castro Mayorgas i aquesta es la presentació del treball de fi de carrera d’Enginyeria Tècnica de Telecomunicacions especialitat Telemàtic amb el títol: “RECONEIXEMENT AUTOMATIC D’INSTRUMENTS MUSICALS”
#3 Aquesta és l’organització de la presentació:
En primer lloc, es descriu el context en què el reconeixement automàtic d’instruments musical es desenvolupa i els objectius marcats en aquest Treball.
Després, s’exposen els fonaments teòrics que són el punt de partida de tota la part d’implementació.
Segueix amb la descripció dels Corpus que es fan sevir pels experiments i de les funcions més importants implementades.
Finalment, amb l’anàlisi dels experiments realitzats, es fa un resum del que han sigut les aportacions d’aquest treball.
#4 El reconeixement automàtic d’instruments musicals és una de les àrees de treball dintre de l’àmbit multidisciplinari de la Recuperació d’Informació de la Música (de l-anglès Music Information Retrieval) que també recull camps com la notació automàtica, la identificació de cançons, la classificació de gèneres musicals i els sistemes de recomanació basats en paràmetres de similitud.
#5 Per a entendre els objectius d’aquest treball, és apropiat veure primerament quin és el principi en el que es basa un sistema de reconeixement d’instruments musicals.
Un sistema d’aquest tipus consta, bàsicament, de dos mòduls. El primer d’ells consisteix en treure del senyal d’àudio d-entrada un conjunt de propietats acústiques que el caracteritzin. El segon mòdul utilitza aquestes característiques per a alimentar un sistema d’aprenentatge que, tal com es veu en la figura, serveixi com a model de referència en la identificació dels instruments de posteriors senyals f-audio
#6 Aquest esquema reflexa els objectius del treball. El que s’ha volgut fer es estudiar el comportament d’un conjunt de caracteristiques acustiques i tècniques de classificació en el reconeixement automatic d’instruments musicals. Es a dir, es vol obtenir respostes a preguntes tals com:
Hi ha carateristiques que son mes rellevants en un sistema de classificacio que un altre?, Com varia el resultat segons el nombre de mostres?, etc.
Per assolir aquests objetius, s’ha hagut també de desenvolupar tota una serie de funcions d’alt nivell que implementin els mòduls d’un sistema de reconeixement automatic i que , a més, ofereixen les eines que facilitin configurar els escenaris i l’anàlisi posterior dels resultats.
#7 La percepcio del so es basa en quatre atributs:
La intensiitat i el volum informen sobre la quantitat de so que es genera i es percep. La intensitat es un valor que es pot mesurar quantiativament i el volum es un valor subjectiu que depen de la sensibilitat uditiva de l’oient.
L’altura correspon a la frequencia de vibració de la font que l’origina. En música, aquestes frequencies estan prefixades a uns valors determinats segons uns criteris d’afinacio. Per exemple, la nota «LA» central d’un piano te una frequencia de 440 Hz.
L’escala mel es una forma de mesurar l’altura dels sons en funció de la percepció que l’oient té de la distància entre d’ells.
La duració és el temps trascorregut desde l’inici dela emissió del so fins la seva finalitzacio.
Finalment, el timbre es l’atribut que permet diferenciar dos instruments musicals que estan tocant la mateixa nota amb la mateixa intensitat i duració.
#8 S’han considerat les següents característiques acústiques per la seva rellevancia:
Centroide: es com el centre de gravetat de l’espectre.
Extensió: Correpon al rang de frequencies ponderat en el centroide.
Coeficients MFCC: com es veura a continuacio, contitueixen una caracerística basica. Es calculen a partir de l’espectre del so.
RollOff: Indica els limits frequencials on resideix el 85% de la energia total de l’espectre.
Taxa de pas per zero: es un indicador del contingut sorollos d’un senyal.
Energia: correspon a l’energia mitjana del senyal. Es un indicador de la seva intensitat.
#9 Son les eines que permeten, per una banda entrenar al sistema i, per l’altre, classificar noves dades segons l’entrenament realitzat.
El model de mescles gaussianes es un metode probabilistic i sense supervisio. Sense supervisio vol dir que les propies mostres d’aprenentatge no son etiquetades i que es el propi classificador qui les classifica.
El metode k-vei mes proper es molt senzill dimplementar pero en contrapartida, te un lt cost de omputacio. Es basa normalment en la distancia euclidiana.
Support Vector machines, es una altra metode basat en la distancia dissenyat inicilament per a la discernit entre dues classes. Es seu fonament es trobar l’hiperpla que optimitzi la distancia que el separa de les mostres de les dues classes. D’aquest meotde existeixen version multiclasse.
#10 Un dels problemes que es presenten en aquest tipus d’estufis és l’obtenciño de suficients dades per a ffer provbes.
Amb aquest fianiltat per incorporar de forma addicional un conjunt de mostres procedent de TunedIt.
Son 115000 mostres en una proporcio 70-30 (entrenament-test) corespodnente a 18 instruments que pertaneyen a 2 families i 8 subfamilies.
Com no es tenen els arxius d’audio originals, cada mostra es considera com si fos un unic arxiu d’audio d’un unic frame.
El crpus de generacio propia es molt mes modest (no arriba al 10% en nombre de mostres). Per poder comparar resultats, s’ha generat gravant els sons dels mateixos 18 instruments que figuren el corpus de tunedit.
En canvi, la generacio del corpus propi ha permes experimenar amb la fase d’extraccio de característiques que no hauria sigut necessaria en cas d’utilitzar exclisivament TunedIt.
#11 Ara es mostren les funcinos desenvolupades per a la realiztzacio dels experiments:
La priemra fase es la extraccio de caracteristiques a partir de les gravacions d’àudio. Les funcions principals son:
La funcio TFCLoadAudioList Carrega una llsita ‘arcius d’audio a memoria
La funcion YXExtacyt features treu les features de totls els arxius d’aui de la llista. Aquí ja tenim les carcateriatiques de cada un dels frames de cada un dels arxius d’auidio.
La funcio TFXExport features crea un arxiu a les caracteristiques acustiques de l’arxiu donat per peramentre.
Com es logic, aquesta fase no es necessari aplicar-la al Corpus de TunedIt ja que es disposa directamente de les caracteristiques.
#12 Una vegada s’han extret les caracteristiques s’ha de procedir a la classificacio i identificacio.
Per a permetre escollir el conjut de catacterisitques que es vol implicar en l’estudi, es defineix un vector de 18 posicions. ON cada posicio fa referencia a les caracter9istiques tal com es mostren en l’esqueam. Nome per a aqueslles posicions en que el valor sigui 1, la caraceristica es tindra en compte.
Referent al metode GMM s’han es te les funcions:
TFCGMMCheck per a veure el resultat de la classificacio sobre el propi conjunt d’entrenament (tal com s’ha dit abans, GMM es un sistema sesne supervisio)
TFCGMMClassify retorna el resultat dela classificacio d’un conjunt de mostres TEST, on el model es TRAINING, WHAT indica quines caracteristiques s’han de tenir en compte, scale, imdica si s’han d’escalar en el rang `’1,¿1+, el valors i classtype indica sobre quin atribut s’ha de fer la cassigicacio (familia, subfamila, instrument)=
#13 Ara es mostren les funcinos per als metodes KNN i SVM:
Els parametres TRAINING, TEST, WHAT SCALE i CLASTYPE tenen el mateix significat que l-ex;licat anteriorment.
A KNN s-FEGEIX EL PARAMETRE k QUE SIGNIFICA EL NOMBRE DE VEINS MES PROPERS SOBRE EL QUE L-ALGORISME PRENDRA LA DECISSIO.
I EL PARAMETRE maxdist UE SIGINIFXa la maxoma distancia a la que un vei pot ser consierat com a tal.
De les tre versions implementades, la prmera retorna la clase predominamt dels k-veins resultants. Si no existeix una unica classe predomnianta el resutlat reyornat es de incertesa.
En la segona version no es necessari que hi hagi una unica lcass pred9moniant per a retorna una classe.
En la tercera opcion, en cas de que no tots els k resultats onicideixin en la classe, la decision es pren amb el metode3 SVM en el que les mostes de training son els k anteriors.
EL metode SVM no te el parametre scale per que es implicit.
#14 La funcio reports analutics fa un resym per instrument del nombre d-encert I erros en l-atrubiutd que es volia identifiar. Es un resum a nivell general que no te en compte les posibles mostres wue formen part dun mateix arxiu d-audio.
Aquest es al funcio valida per serutilitzada amb les dades de tunedirt.
En canvi, la fucio reportdecision, si que te en cimpte les mostres qye formen cada arxiu d-aidui. Els resutlatsm en aquests taula resum estan a nivell d-arcxiu on es visylaitzaen els primer I segon candidad amb els seus percetatges,
#19 Una analogia no garie sorprenent quan la guitarra sona com un piano sonre tot a les notes baixes si es punteja. De getr el piano tw unes cordes…
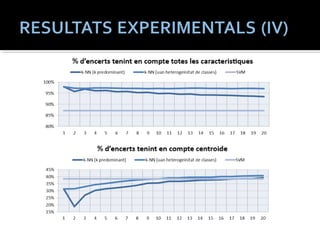
#20 Finaldment es mostren es resultats agrupanbt les mostres en funcion dels arxius d-auido originals.
#22 Aquí acaba la presentació. Moltes gràcies per la vostra atenció.









![Funcions relacionades amb la classificació
vWhat = [x x x x x x x x x x x x x x x x x x]
MFCC1 … MFCC13
cResults = TFCGMMCheck (cFTraining,
vWhat, scale, classType)
CResults = TFCGMMClassify (cFTraining,
cFTest, vWhat, scale, classType)
Centroide
Extensió
RollOff
ZeroCross
Energia](https://image.slidesharecdn.com/tfcett-141020040946-conversion-gate02/85/Automatic-Recognition-of-Musical-Instruments-11-320.jpg)