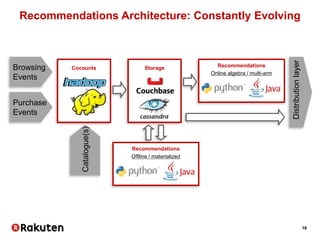
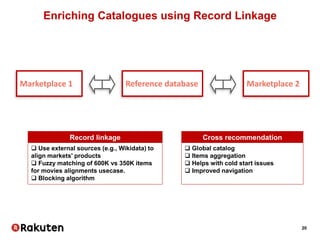
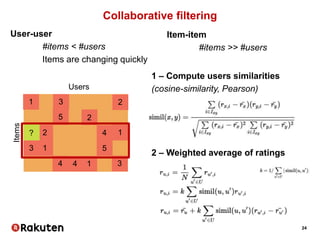
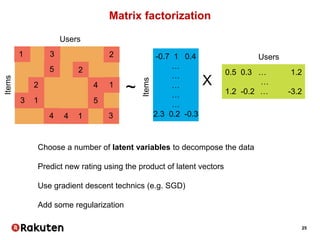
The document outlines Vincent Michel's insights on data science within the e-commerce industry, particularly at Rakuten. It emphasizes the significance of integrating data science in software engineering, open-source contributions, and developing effective recommendation systems while addressing challenges such as user behavior and catalog management. Additionally, it highlights hiring practices and the evolving landscape of big data technologies in Rakuten's operations.


















![26
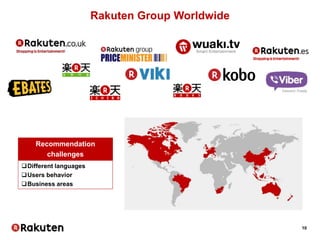
Matrix factorization – MovieLens example
Read files
import csv
movies_fname = '/path/ml-latest/movies.csv'
with open(movies_fname) as fobj:
movies = dict((r[0], r[1]) for r in csv.reader(fobj))
ratings_fname = ’/path/ml-latest/ratings.csv'
with open(ratings_fname) as fobj:
header = fobj.next()
ratings = [(r[0], movies[r[1]], float(r[2])) for r in csv.reader(fobj)]
Build sparse matrix
import scipy.sparse as sp
user_idx, item_idx = {}, {}
data, rows, cols = [], [], []
for u, i, s in ratings:
rows.append(user_idx.setdefault(u, len(user_idx)))
cols.append(item_idx.setdefault(i, len(item_idx)))
data.append(s)
ratings = sp.csr_matrix((data, (rows, cols)))
reverse_item_idx = dict((v, k) for k, v in item_idx.iteritems())
reverse_user_idx = dict((v, k) for k, v in user_idx.iteritems())](https://image.slidesharecdn.com/telecomdatasciencemasterpublic-160616143648/85/Telecom-datascience-master_public-26-320.jpg)
![27
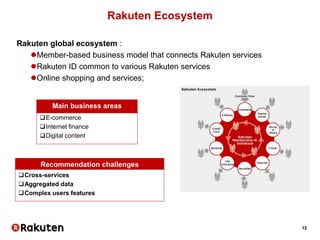
Matrix factorization – MovieLens example
Fit Non-negative Matrix Factorization
from sklearn.decomposition import NMF
nmf = NMF(n_components=50)
user_mat = nmf.fit_transform(ratings)
item_mat = nmf.components_
Plot results
component_ind = 3
component = [(reverse_item_idx[i], s)
for i, s in enumerate(item_mat[component_ind , :]) if s>0.] For
movie, score in sorted(component, key=lambda x: x[1], reverse=True)[:10]:
print movie, round(score)
Terminator 2: Judgment Day (1991) 24.0
Terminator, The (1984) 23.0
Die Hard (198 19.0
Aliens (1986) 17.0
Alien (1979) 16.0
Exorcist, The (1973) 8.0
Halloween (197 7.0
Nightmare on Elm Street, A (1984) 7.0
Shining, The (1980) 7.0
Carrie (1976) 7.0
Star Trek II: The Wrath of Khan (1982) 10.0
Star Trek: First Contact (1996) 10.0
Star Trek IV: The Voyage Home (1986) 9.0
Contact (1997) 8.0
Star Trek VI: The Undiscovered Country (1991) 8.0
Blade Runner (1982) 8.0](https://image.slidesharecdn.com/telecomdatasciencemasterpublic-160616143648/85/Telecom-datascience-master_public-27-320.jpg)



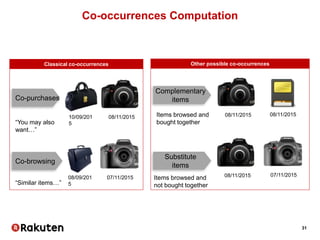


![34
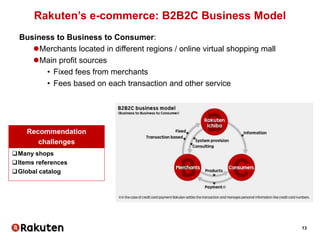
Python Algebra Example
Purchase-based
Top-20
Asymmetric
Conditional probability
Browsing-based
Similarity > 0.01
Symmetric
Cosine similarity
+ 0.2 Composite engine
>>> engine1 = RecommendationsEngine(nb_recos=20,
datatype=‘purchase’,
asymmetric=True,
distance=‘conditional_probability’)
>>> engine2 = RecommendationsEngine(similarity_th=0.01,
datatype=‘browsing’,
asymmetric=False,
distance=‘cosine_similarity’)
>>> composite_engine = engine1 + 0.2 * engine2
Get recommendations from items (item-to-item)
>>> recos = composite_engine.recommendations_by_items([123, 456,
789, …])](https://image.slidesharecdn.com/telecomdatasciencemasterpublic-160616143648/85/Telecom-datascience-master_public-34-320.jpg)





























![[Rakuten TechConf2014] [A-4] Rakuten Ichiba](https://cdn.slidesharecdn.com/ss_thumbnails/a4presentationoftechconf2014final-141105035710-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






















