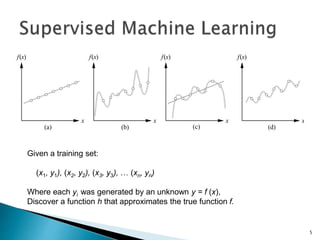
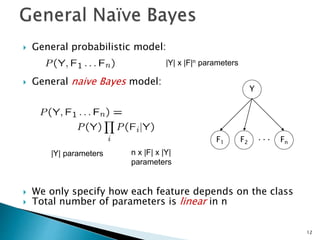
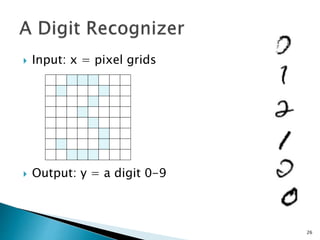
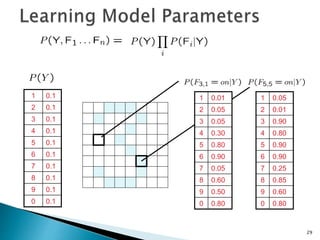
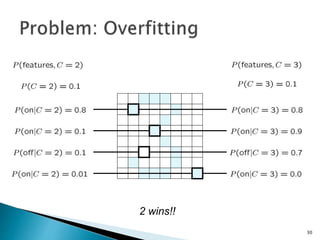
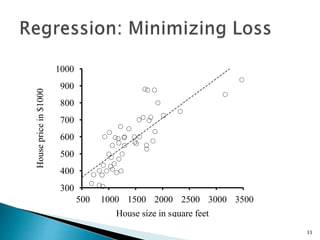
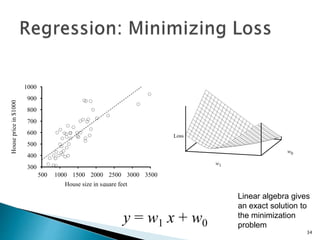
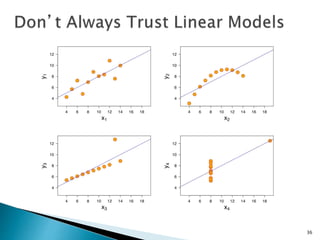
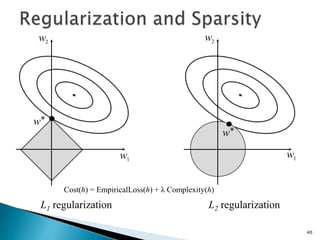
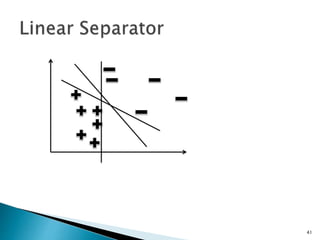
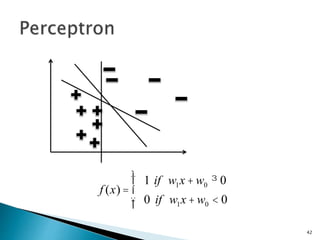
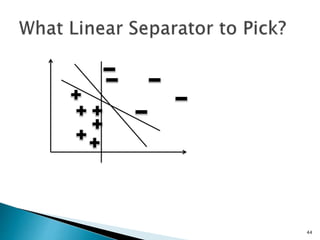
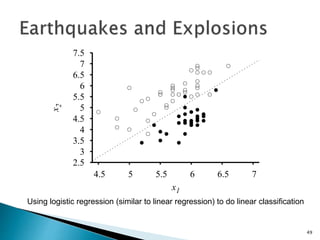
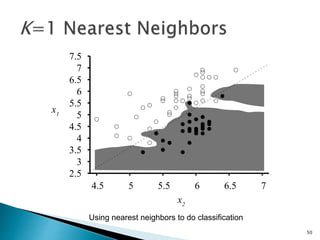
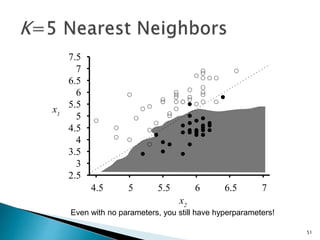
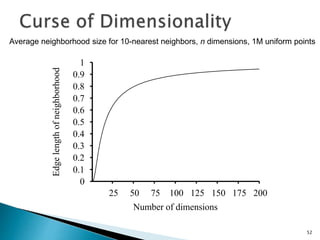
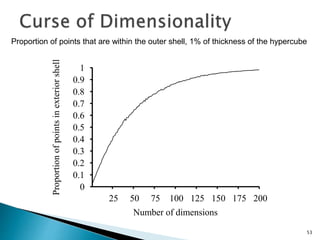
This document discusses machine learning concepts including supervised and unsupervised learning, prediction, diagnosis, and discovery. It provides examples of using naive Bayes classifiers for spam filtering and digit recognition. For spam filtering, it shows how to represent emails as bags-of-words and learn word probabilities from labeled training emails. It also discusses issues with overfitting and the need for smoothing techniques like Laplace smoothing when estimating probabilities. For digit recognition, it outlines representing images as feature vectors over pixel values and using a naive Bayes model to classify images.