










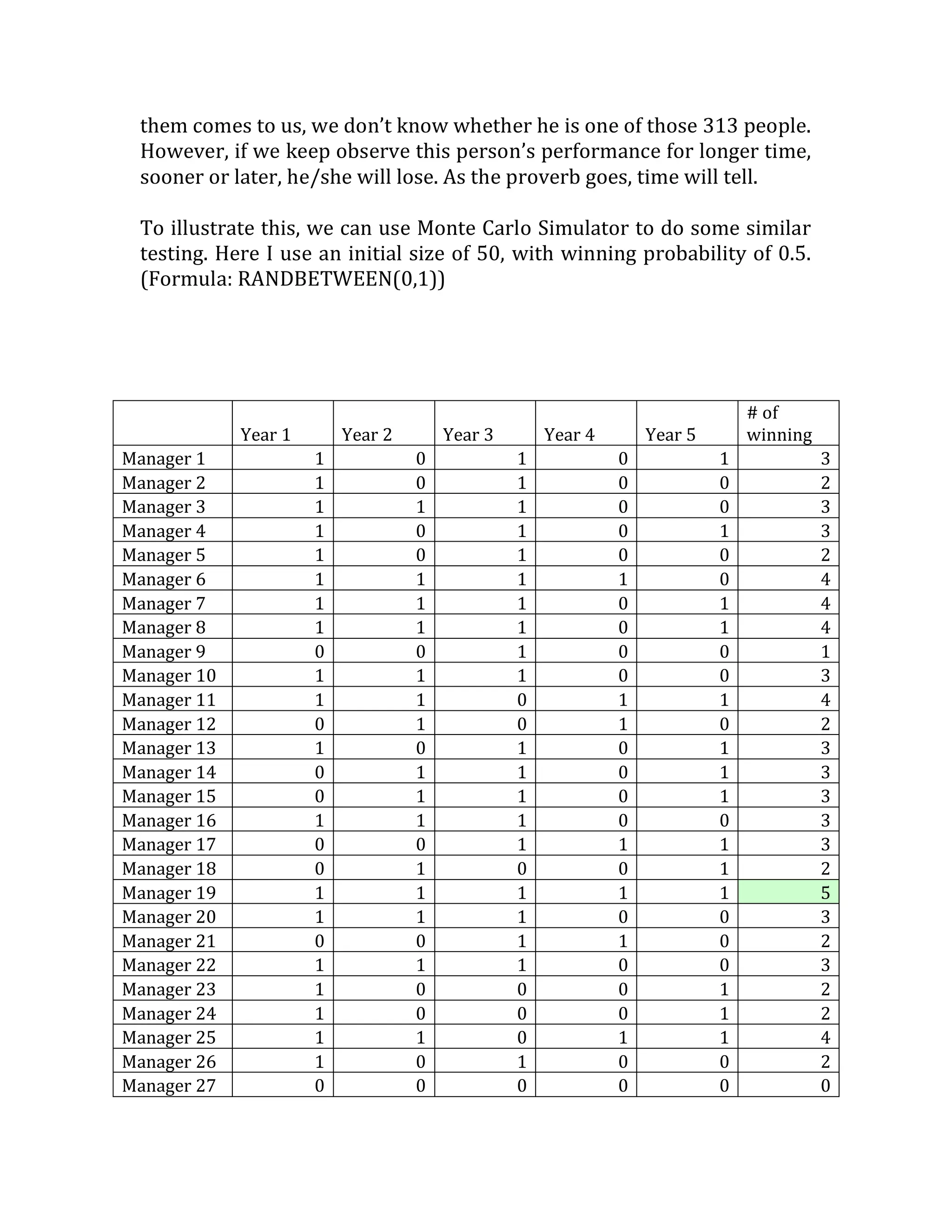
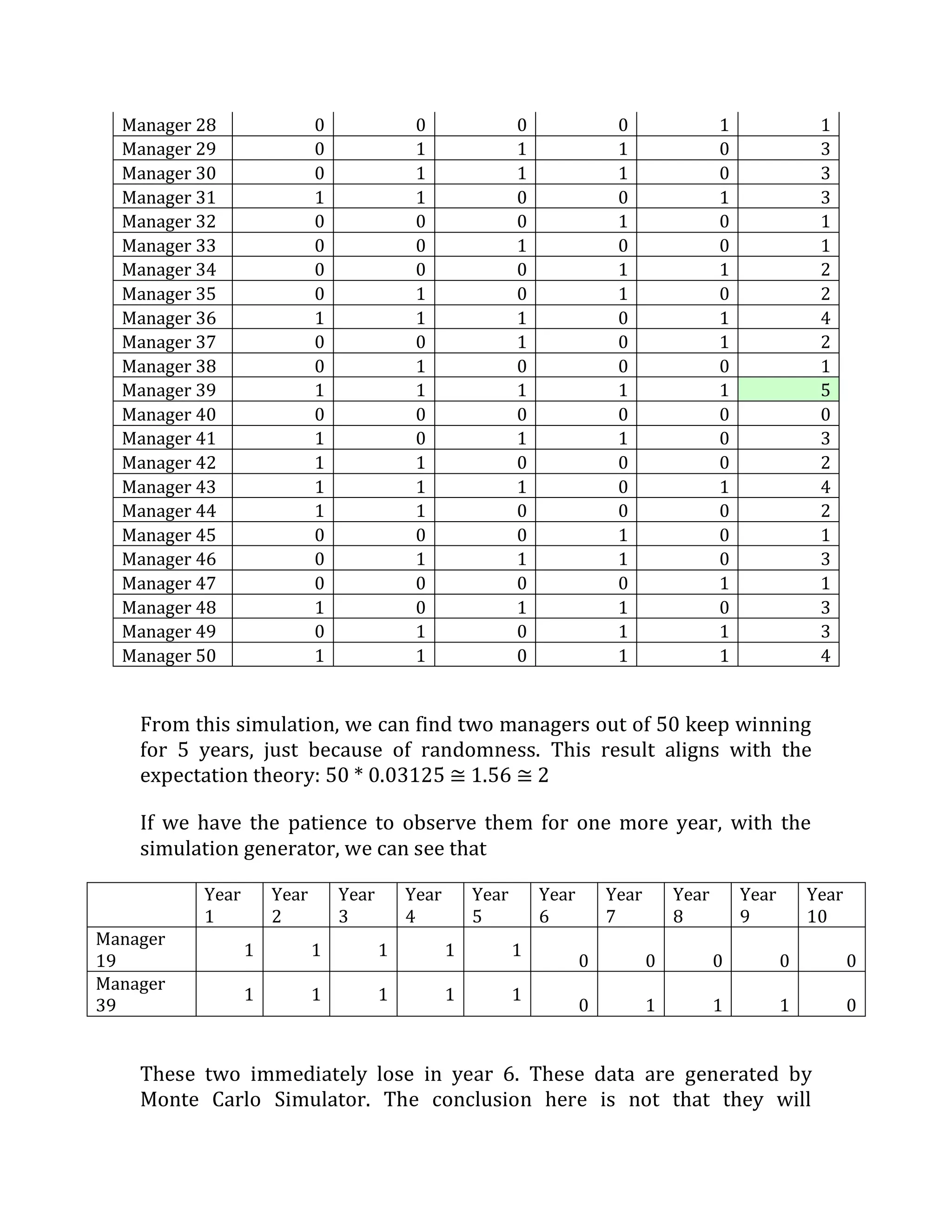
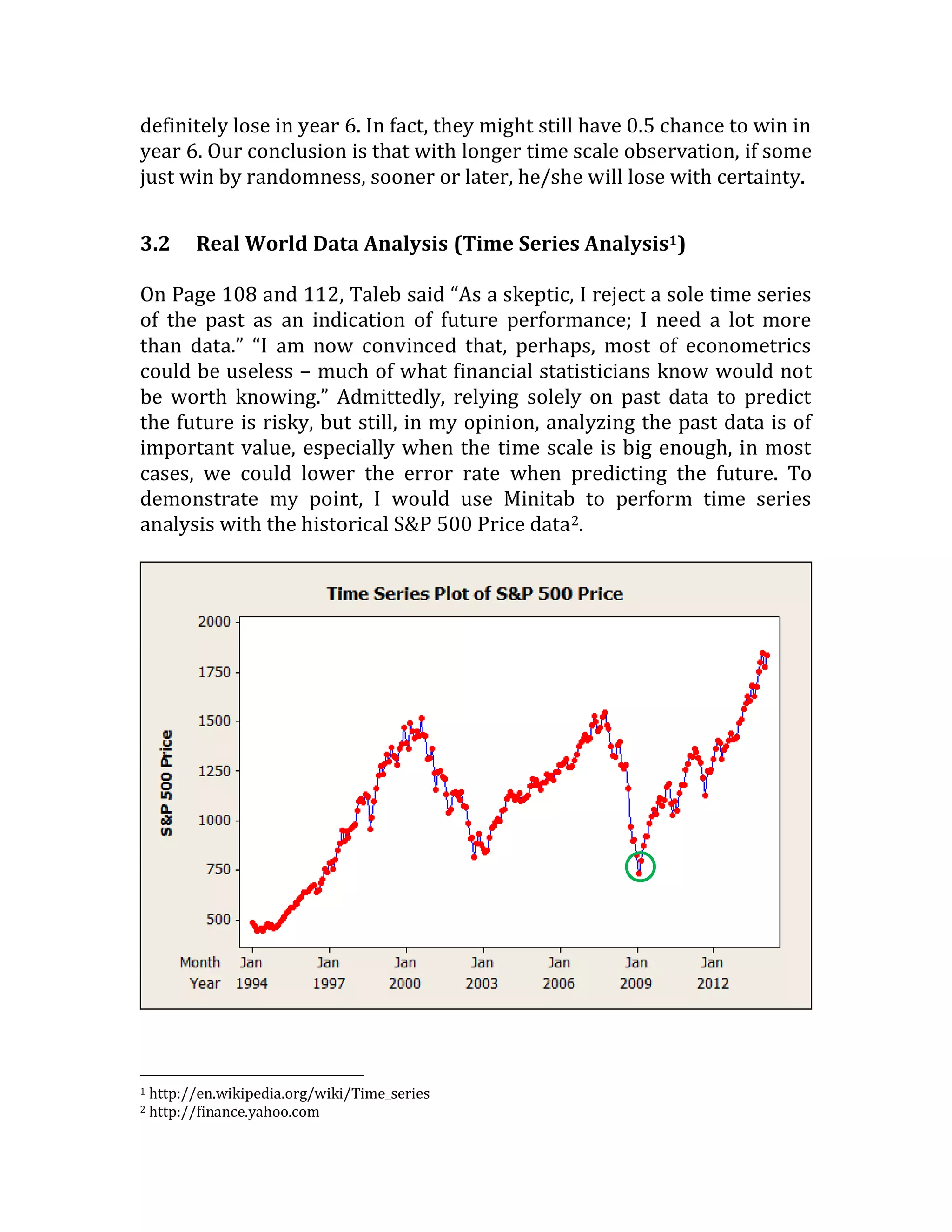
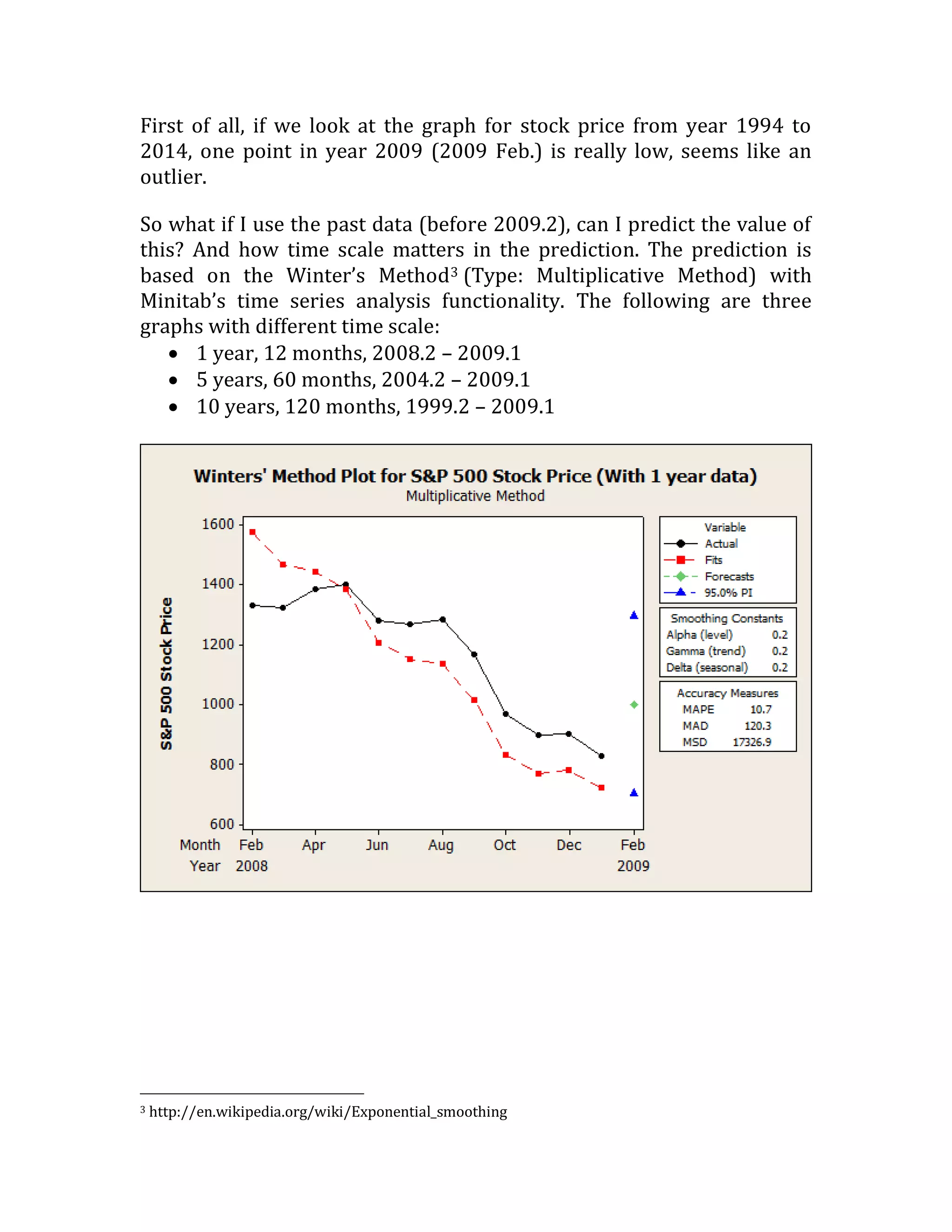
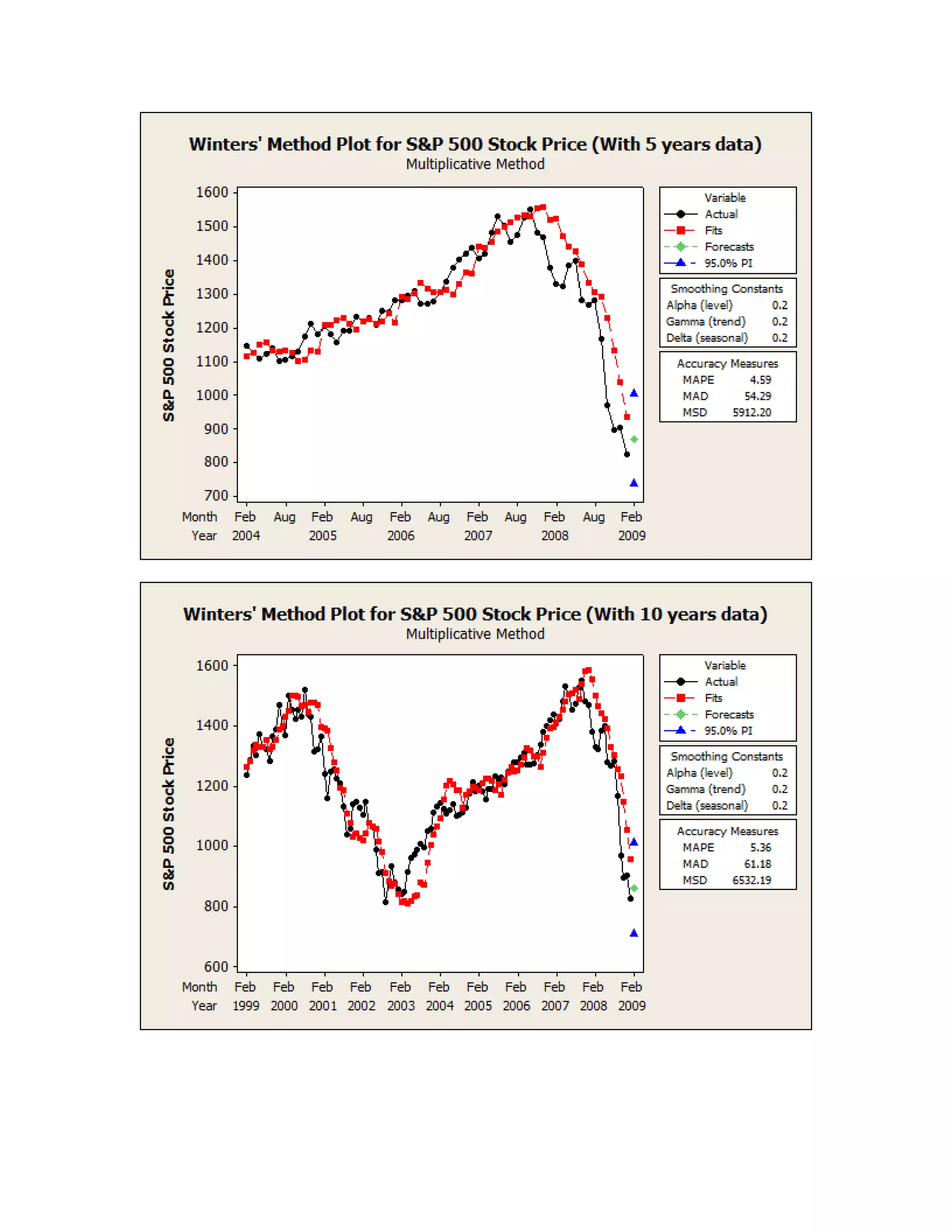


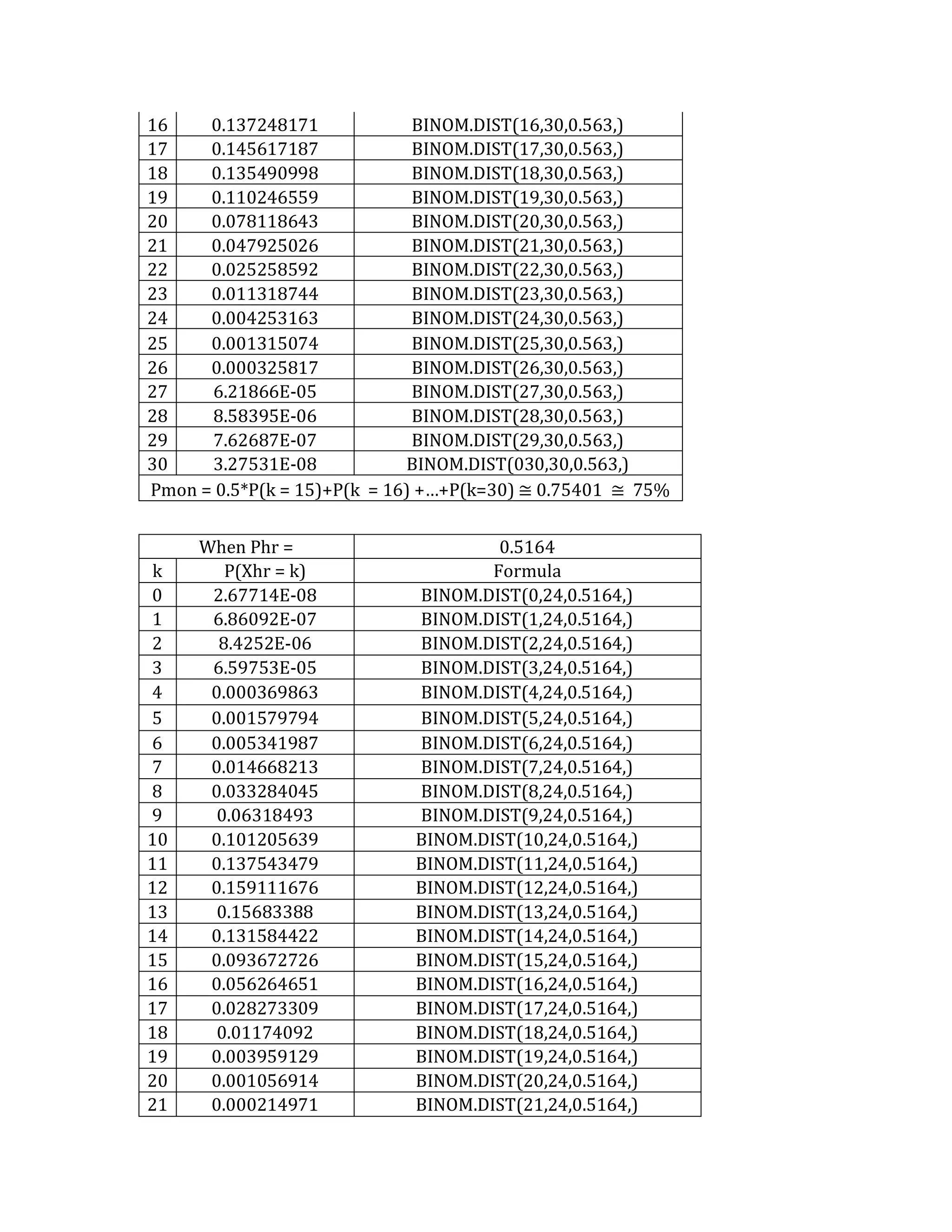
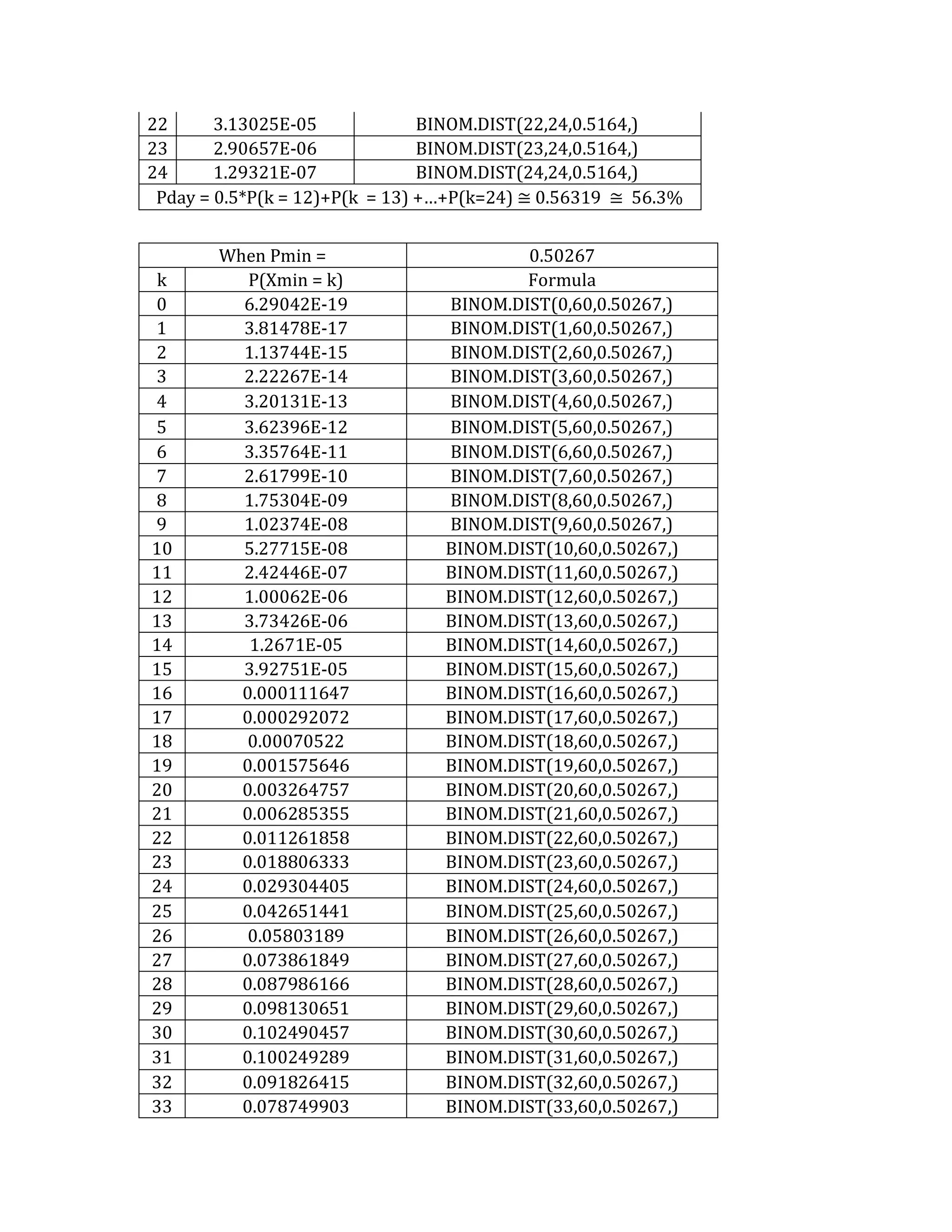
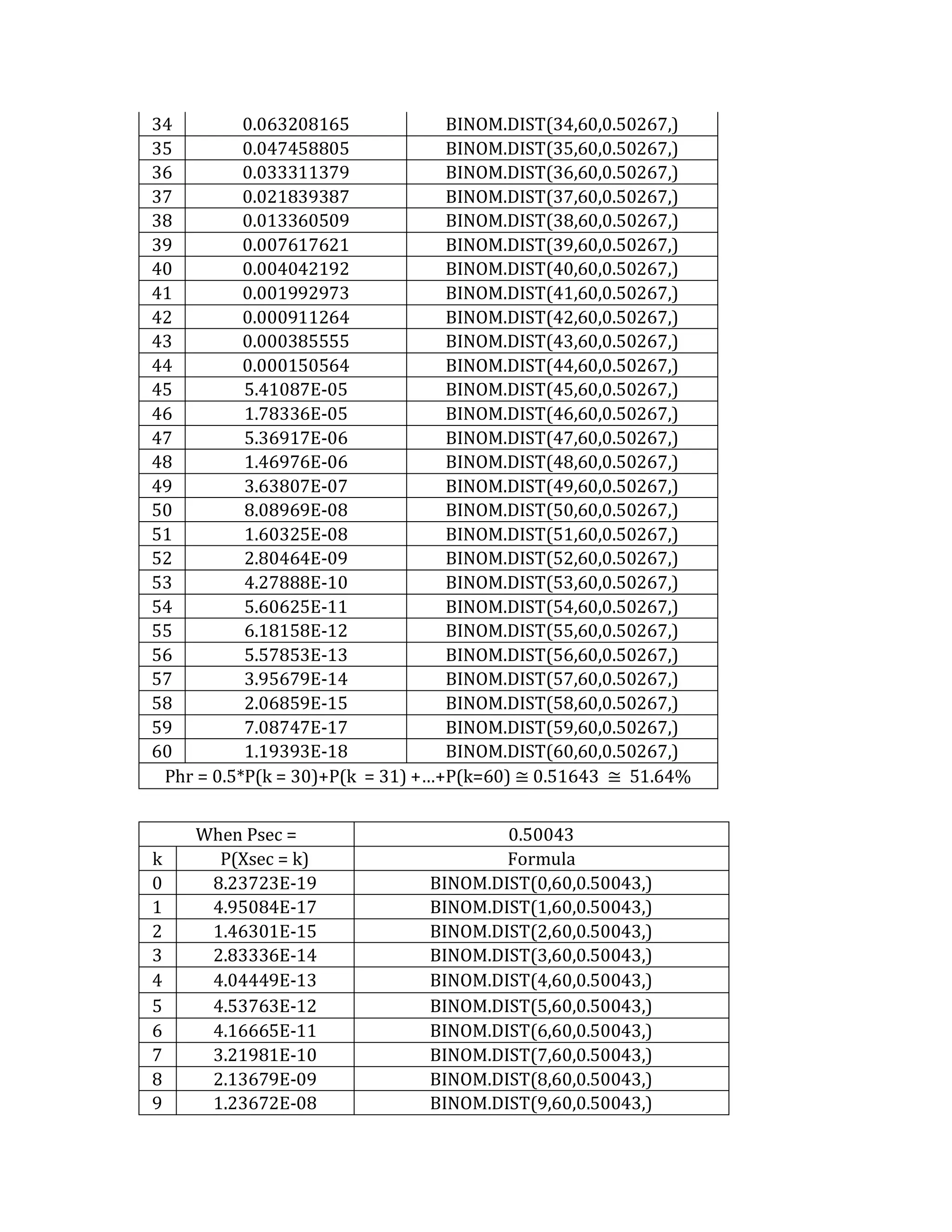
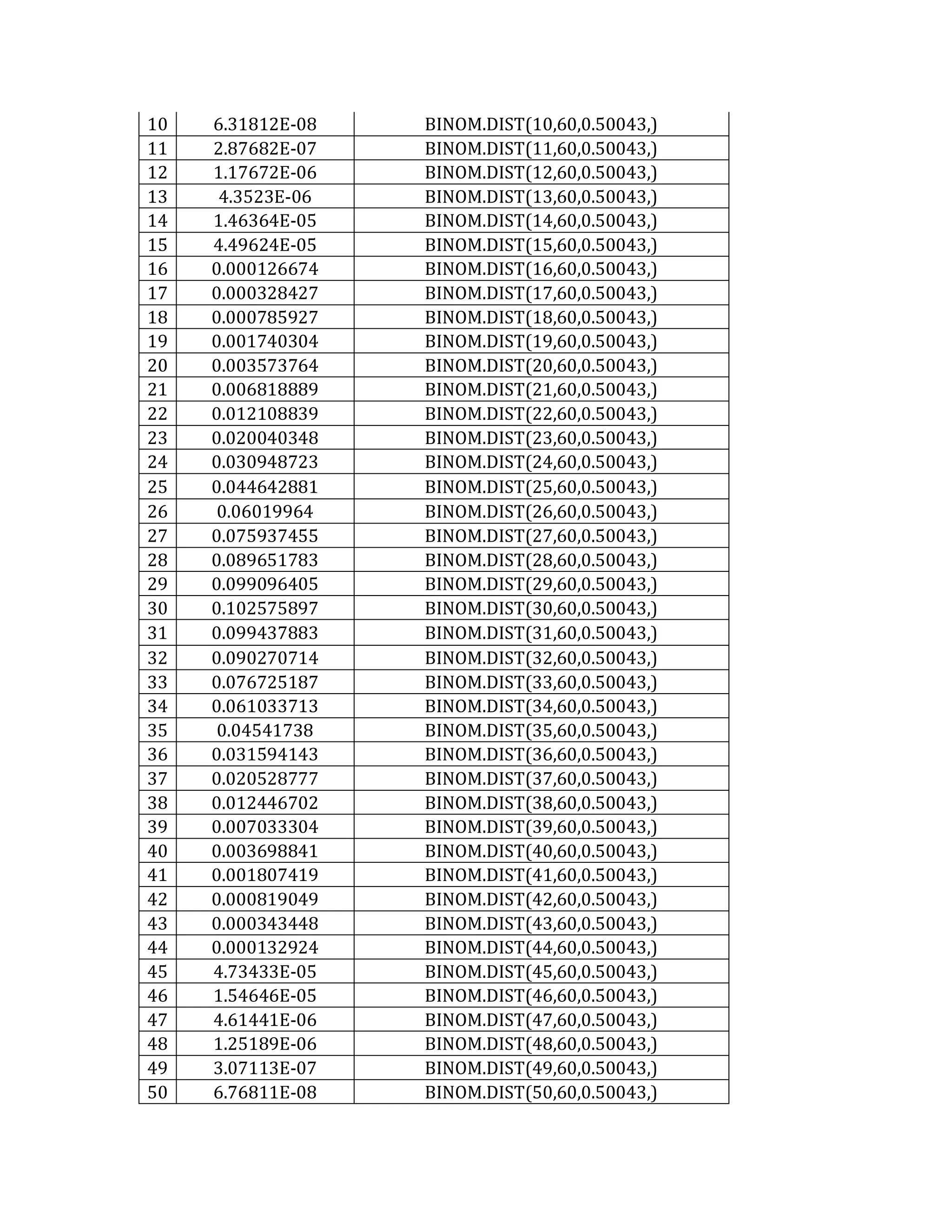
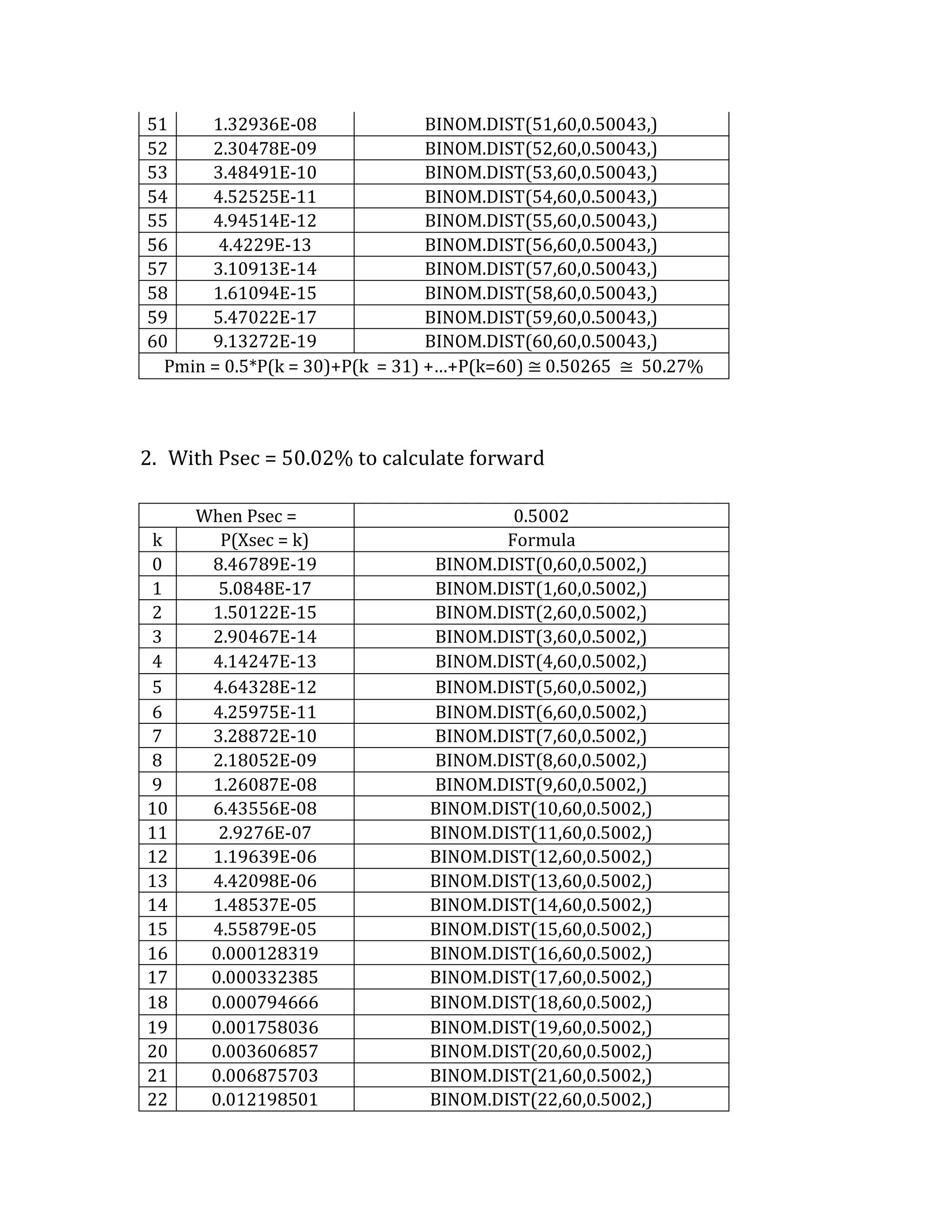
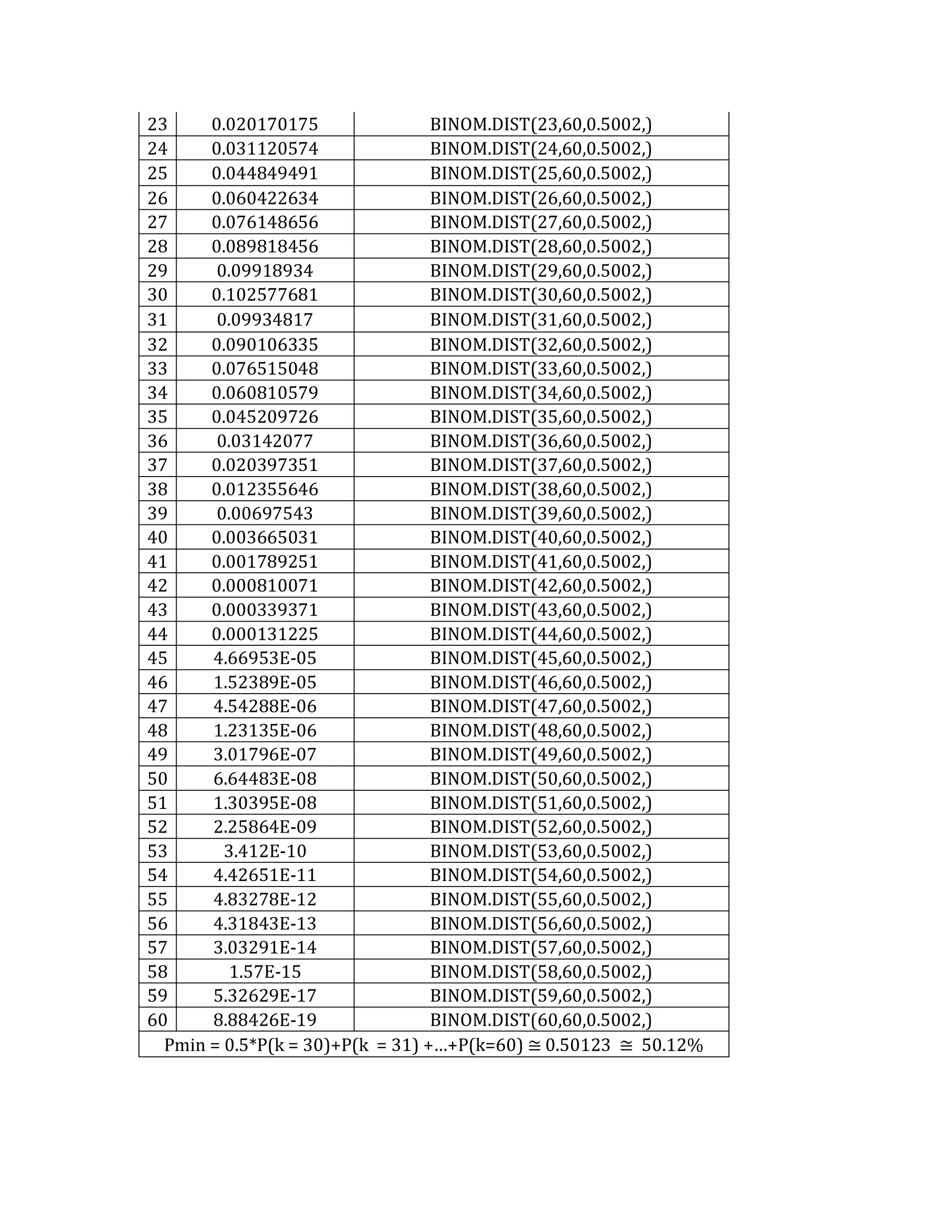
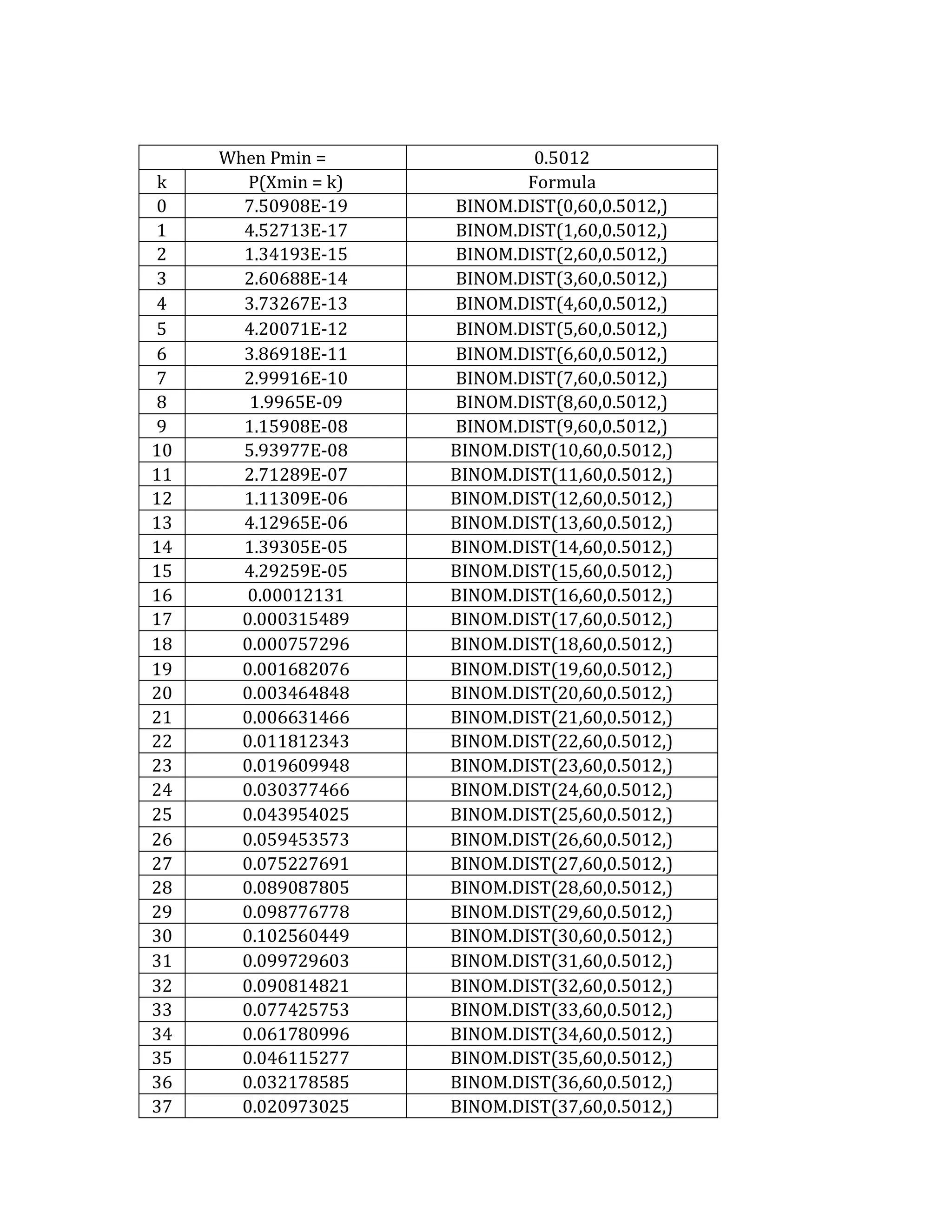
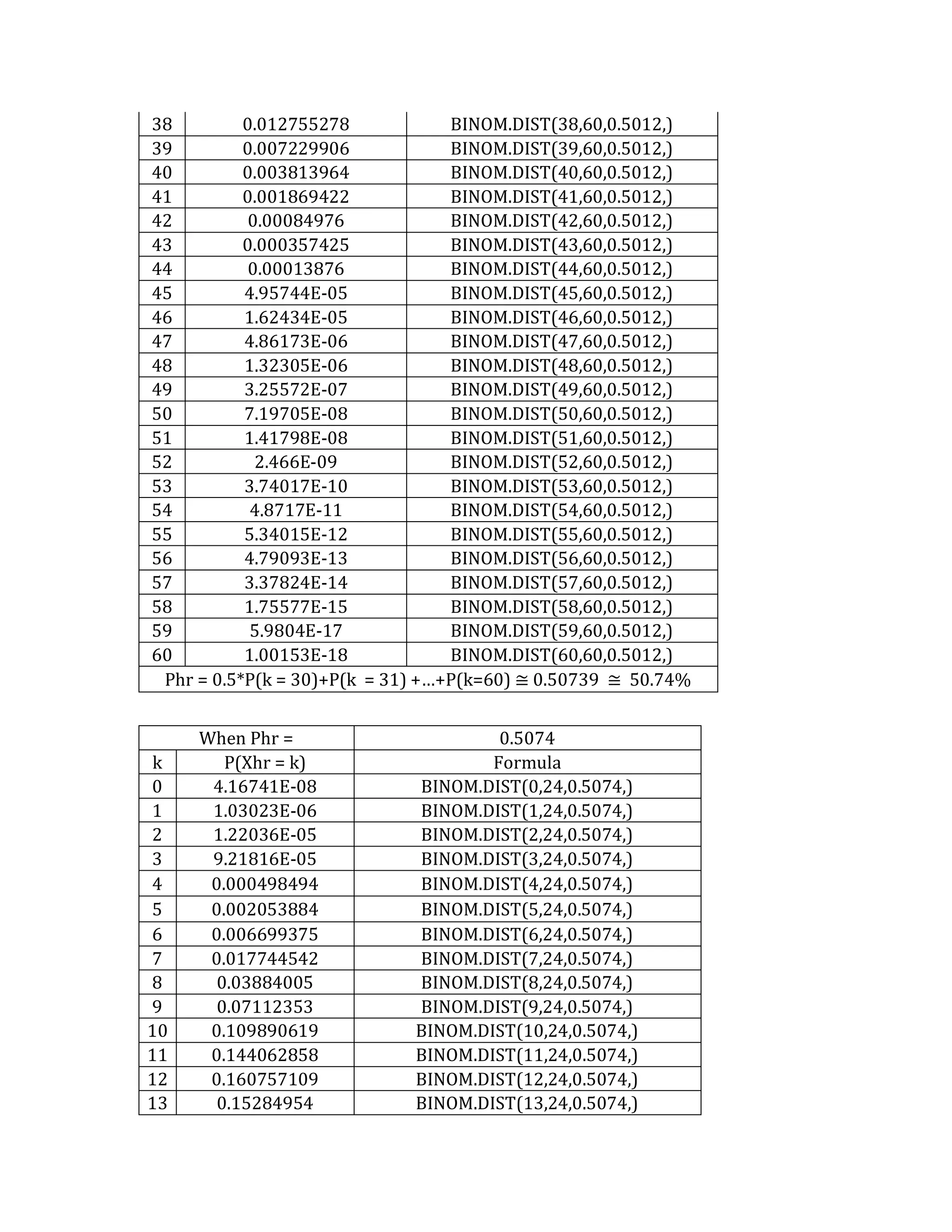
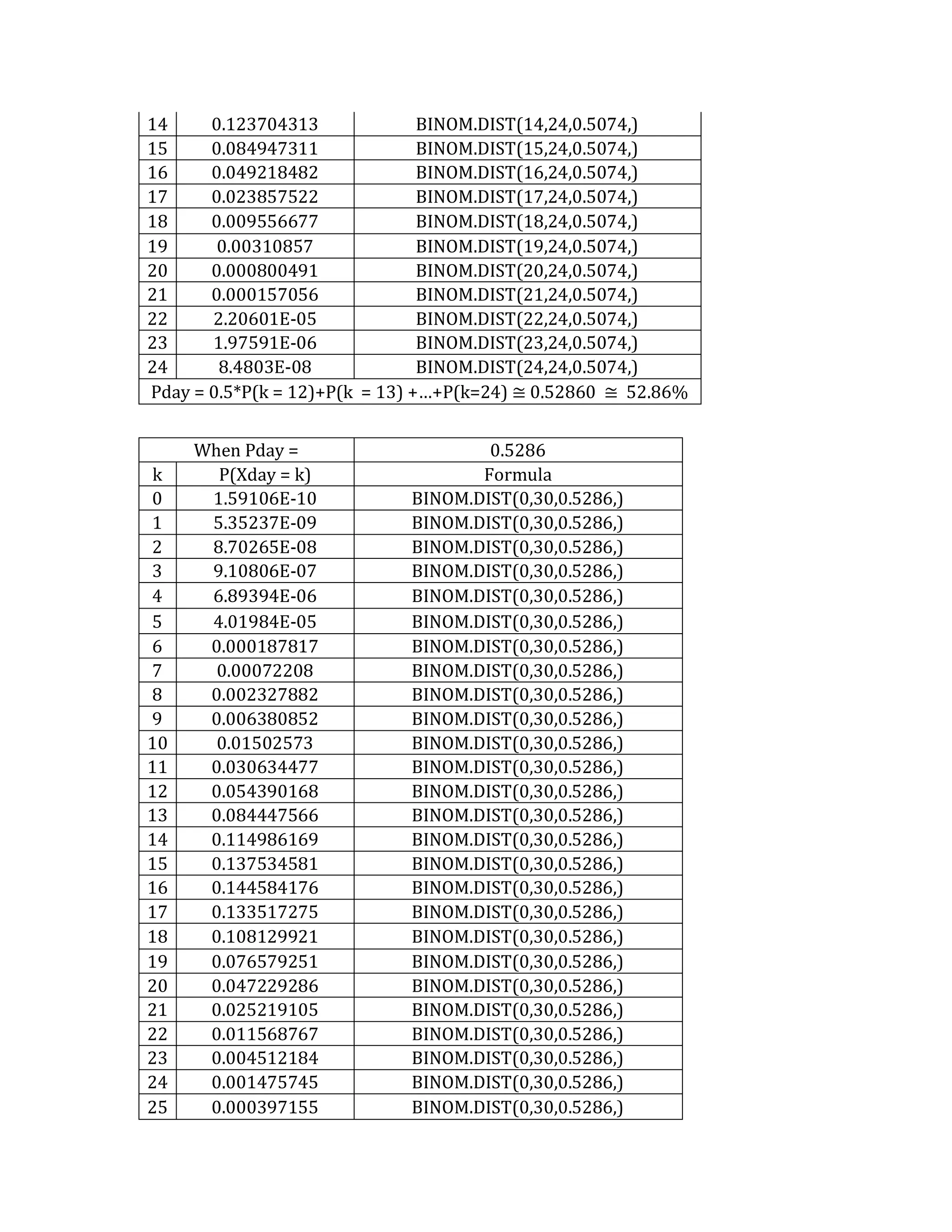
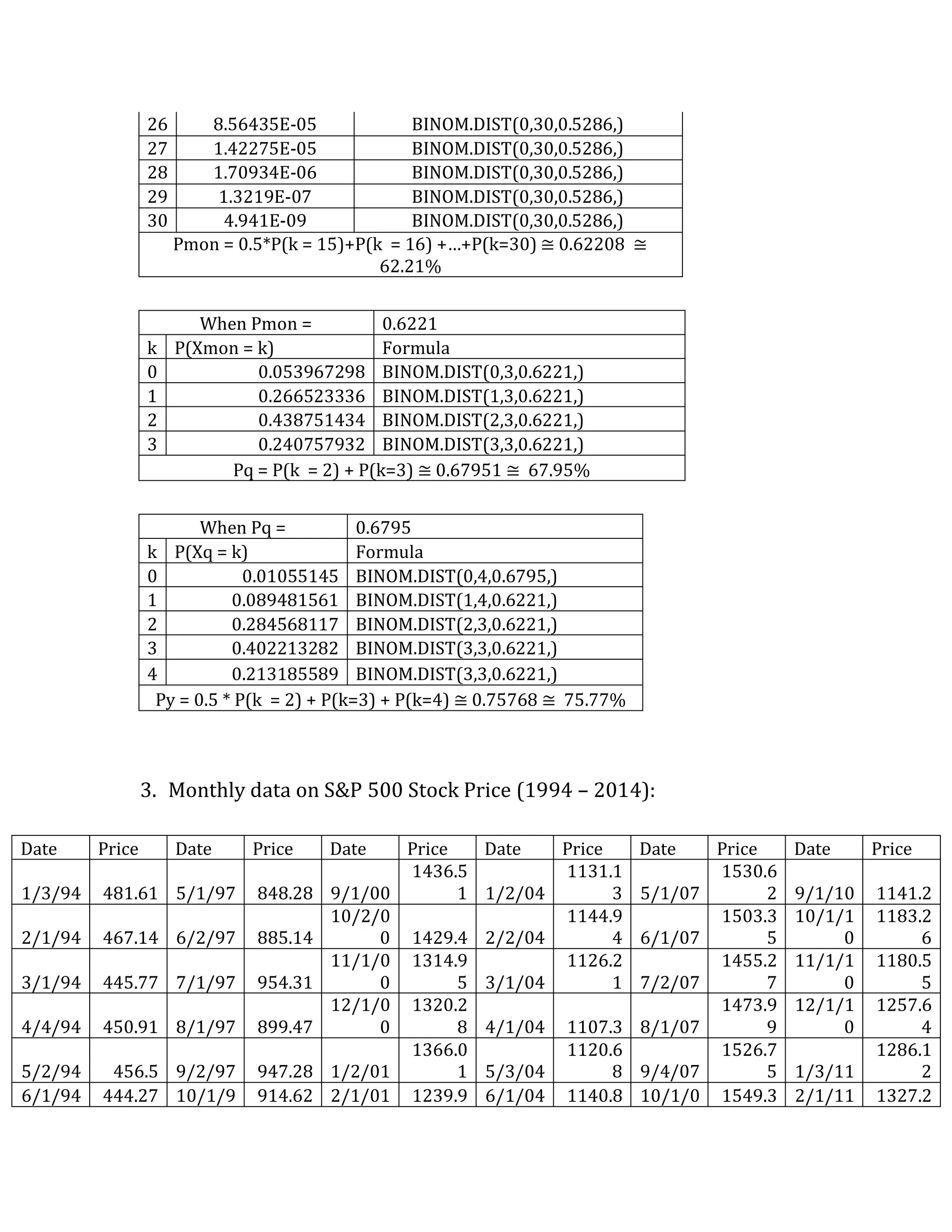
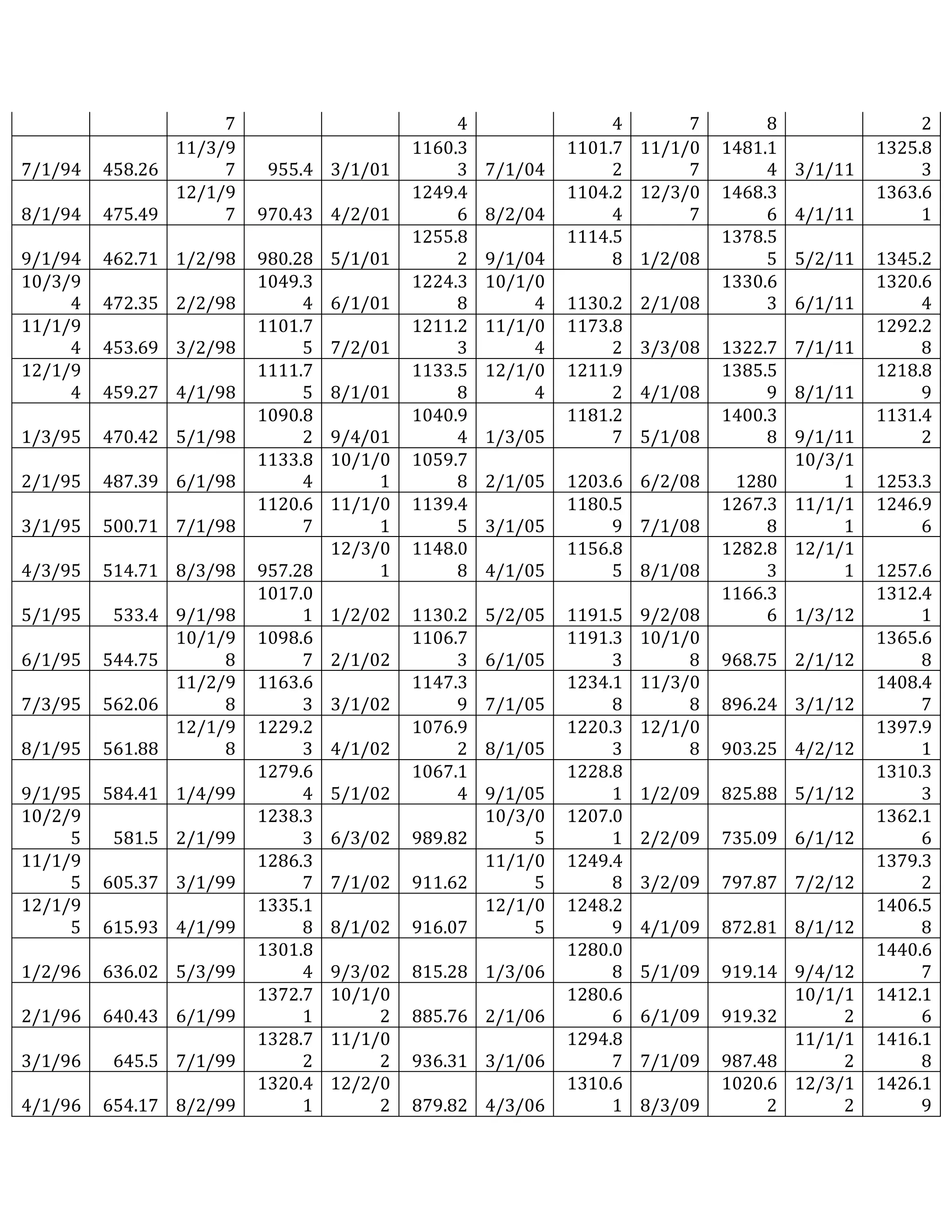
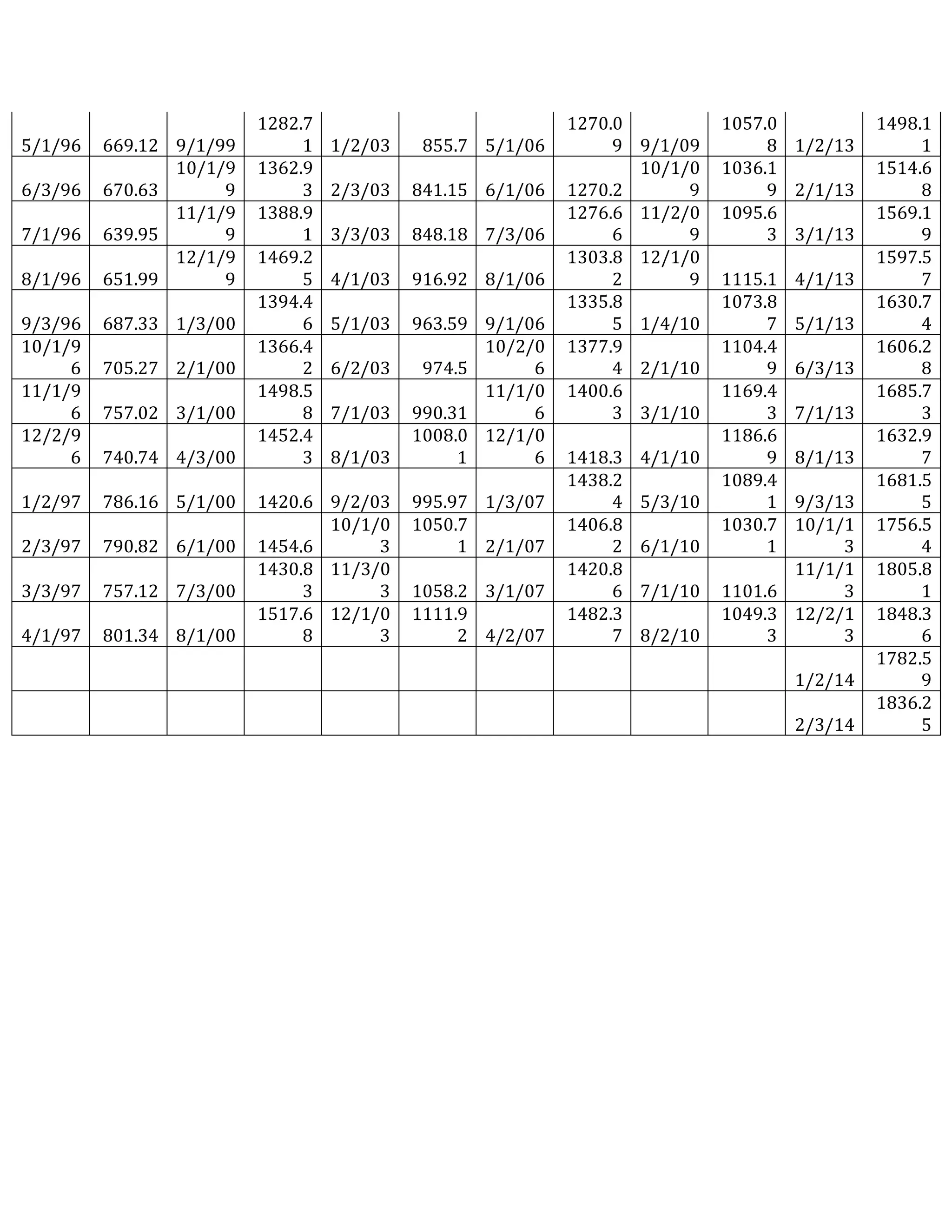


This document outlines a student's final project analyzing the book "Fooled by Randomness" by Nassim Nicholas Taleb. The project will focus on how time scale matters and will use statistical analysis to examine examples from the book and real world data. The student will first analyze examples from the book using probability distributions to validate the author's arguments about how time scale affects outcomes. Then they will perform time series analysis on historical S&P 500 price data to demonstrate how analyzing long-term past data can provide valuable insights despite the author's skepticism of econometrics. Lastly, the student will summarize interpretations from the statistical analysis and how understanding time scale can inform decision making.
























































