데이터를 얻으려는 노오오력
AWSKRUG발표
https://www.facebook.com/groups/awskrug
2017-06-29
Youngjae Kim
youngjae@bapul.net
2.
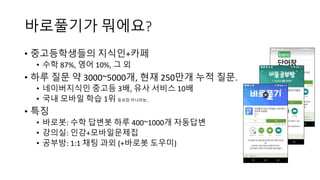
바로풀기가 뭐에요?
• 중고등학생들의지식인+카페
• 수학 87%, 영어 10%, 그 외
• 하루 질문 약 3000~5000개, 현재 250만개 누적 질문.
• 네이버지식인 중고등 3배, 유사 서비스 10배
• 국내 모바일 학습 1위 듣보잡 아니라능…
• 특징
• 바로봇: 수학 답변봇 하루 400~1000개 자동답변
• 강의실: 인강+모바일문제집
• 공부방: 1:1 채팅 과외 (+바로봇 도우미)
3.
기술적인 특징
• 모오오던클라우드 아키텍처
• PaaS 클라우드지향 설계 (VM 없음)
• 지역 분산, 트래픽 대응 자동 확장
• CQRS, MSA, …
• 여러 개의 로깅, APM, …
• 수식 전용 OCR 엔진 자체 개발
• 가장 저렴한 가상서버에서도 빠르게(<2초) 처리
• 데이터 구조 직접 설계
• Storage, Flat, Graph 등 직접 설계하고 구현
오늘 이야기
• 이야기안하는 것
• “잘나가는 알고리즘을 이런저런 도구로 컴퓨터에서 돌려봤어요 짠”
• 이야기 하는 것
• 근 10년간 데이터를 확보하기 위해 했던 일들
• 그에 따른 시행착오
• 현재 업계의 삽질들
• 이 세미나를 듣는 요령
• 반만 걸러 들으세요
• 에듀테크 쪽 예시가 많으므로 자신의 영역으로 적당히 바꿔 들어주세요
예전에 했던 이야기
•트레이닝할만한 것이 없다
• 딱히 인공지능이 필요하지 않다
• 대충 추천이라고 퉁친다
…이럼에도 인공지능을 만들었다면?
https://www.facebook.com/10152751988227794/posts/10153567475772794
9.
데이터 얘기에 왜인공지능 딴지부터 거냐
• 결국은 데이터에 발을 디디고 있어야 하니까…
• 좋은 데이터는 좋은 데이터 모델로부터
• 데이터 모델을 만드는 것은 생각보다 많은 시행착오가 필요
• 이를 위해 facebook, google은 그렇게나 API를 바꿨나보다…
• API에서 노출하는 데이터 모델도 꾸준히 바뀌어가는 것을 볼 수 있다
10.
엔지니어에겐 무엇이 인공지능일까제 사견입니다
• 비정형 콘텐츠를 다룰 수 있으면 인공지능이라고 생각해요
• 정형화된 콘텐츠만 다루면 그냥 알고리즘
• 에듀테크 쪽 예시
• “우리가 만든 문제를 풀면…학생을 파악해서...맞춤 교육이 가능합니다”
• 이건 그냥 알고리즘
• “아무 틀린 문제나 몇 개 보여주면…”
• 이 쯤은 되어야 인공지능에 가깝다
“시리야 음악 재생해줘” (동작함)
“음악 듣고 싶네… 시리야?” (동작안함)
꼭 규칙에 맞춰야만 동작하는데
그게 왜 인공지능인가…? 보이스커맨드지.
11.
어? 그러면 결론이벌써 나왔네
비정형 콘텐츠를
데이터 모델링을 할 줄 알면
알고리즘 적용이 쉬워지고
수준이 다른 서비스 개발
높아진 나의 연봉
빠른 은퇴 가능
교육 쪽에 첫관심을 들인 2010년 왜 그랬을까 내 인생
• 문득 궁금증: “왜 열심히 해도 성적이 안오르는 학생이 있을까”
• 가설: “잘 하는 학생의 행동만 따라해도 성적이 오른다”
‘달리기’는 자세만 따라해도 좋아지는데 공부는 어떨까?
14.
결론부터 말하자면
• 2010년부터5년간
• 9번의 거절 끝에
• 교육 저널에 기어코 인정받음
• “행동 훈련을 통한 수학 성적 향상”
• 원래 제목: 타블렛을 이용한 수학풀이에서의 실수를 줄이는 방법
• http://ieeexplore.ieee.org/document/7110369/
15.
이정은 and 김원경,“중학생들의 일차 방정식에 관한 문장제 해결 전략 및 오류 분석 (kor),” Journal of the Korean Society of Mathematical Education. Series A, vol. 38, no. 1, pp. 77-85, 1999.
계산 실수로 틀린게 모르는 경우보다 많더라
“이거….계산 실수만 줄여도 되는거 아니냐?”
16.
첫번째 난관
• 학생의문제풀이 행위를 시간으로 기록해보자.
• 문제풀 때 필기, 표정 모두를 타블렛에 기록하자.
• 2010년, 디지털잉크+시간 기록을 동시에 하는 것이 어려움
필기에 딜레이가 발생ㅠㅠ
• 필기를 상쾌하게 해야 유저 경험이 좋아진다.
그래야 더 데이터다운 데이터를 수집하지
• 필기 경험을 극대화하자 드라이버를 직접 만들자 왜그랬을까ㅠㅠ
17.
Real-time Stroke Recording
•일반적인 타블렛PC의 입력처리: 22 ticks
• Naive method (event hooking): 253 ticks (ver 1.0)
Driver
Input
Dot
Rendering
Canvas
Object
Event
Driver
Input
Dot
Rendering
Canvas
Object
Event Fetch current time Data array
CPU
CPU
18.
Real-time Stroke Recording
•Parallel processing: 25 ticks (x10 faster)
• Parallel processing + timestamp: 16 ticks (60% faster)
Custom
Driver
Dot
Rendering
Canvas
Object
Event
Custom
Driver
Dot
Rendering
Canvas
Object
Event
Fetch absolute timestamp
(remove locale loops)
Embed
Data
Array
Data
Array
Fetch
Current time
Embed
GPU
GPU
CPU
CPU
19.
Real-time Stroke Recording
•Re-arrange timestamp processing: 13 ticks. (20% faster) < 10ms
• 10ms 이하의 초고속 처리를 달성함으로 사용성의 개선
• 학습자가 문제풀이에 집중할 수 있게 함
• 이 목적 만을 위한 소프트웨어라서 외부 API까지 고려하는 범용보다 빠르게 처리가 가능했음
Custom
Driver
Dot
Rendering
Canvas
Object
Flagging
Data
Array
Fetch
timestamp
GPU
CPU
20.
이 노력을 했더니
•전에 없던 데이터 새로운 해석 새로운 인사이트!
• 전에 있던 데이터일지라도
• 보다 정교한 측정
• 보다 깊은 조사
• 보다 다양한 통계
• 보다 신뢰성 있는 과정과 결론
• 개발기간 6개월. 괜찮은 노오오력이었다
21.
문제풀이 단계와 시간
A.H. Schoenfeld, “Learning to think mathematically: Problem solving,
metacognition, and sense making in mathematics,” Handbook of research on
mathematics teaching and learning (1992): 334-370.
90년대 초
비디오카메라로
촬영하고
수작업으로
태깅했던 어느 연구
무엇을 하는 것인가
•거국적 목표: 질문에 자동답변을 하도록 한다.
• 좀 더 자세히: 질문 사진을 올리면 기존에 있는 답변은 즉시 제시
• 세부 목표
1. 질문 이미지에서 정보를 추출
2. 질문의 유사도 검색
3. 유사한 질문 중 (좋은) 답변을 제시
4. 동일하지 않을 경우 관련 단원 정보 제시
33.
무엇을 하는 것인가[자세히] 1/4
• 이미지워싱
1. 이미지를 깨끗하게 한다: 각도보정, 잡티제거, 글씨 또렷하게, 흑백화
2. 잘못된 형태는 거른다: 여러 문제 사진, 똥화질, 너무 작은 글씨 등
3. 문제 영역만 찾는다: [글+이미지+객관식] 영역과 [다른 문제, 장식, 배경] 등 구분
34.
무엇을 하는 것인가[자세히] 2/4
• 개념+수식인식
1. 흑백 글자를 모두 점/선으로 변환
2. 수식과 한글을 분리
3. 수식을 인식 수식의 수준을 파악
4. 한글을 인식 개념 관련 단어를 취합
수식인식을 통해 “이차방정식” 정보를 추가로 얻음
35.
무엇을 하는 것인가[자세히] 3/4
• 이미지DNA생성
• 하나의 그림으로서의 고유한 특징을 수치화한다
• 어려운 점: 무엇을 수치화해야 하는가? 특징점, 비율, 배치 등
0
34
45
200
121
3
149
52
98
34
39
189
14
13
2
56
200
200
200
200
200
140
170
35
140
16
34
45
145
36.
무엇을 하는 것인가[자세히] 4/4
• 기존 질문 찾기
• 결국 저장되는건 각 문제의 특징을 요약한 형태
• 어려운 점: ‘같은 값’이 아닌 ‘비슷한 값’을 찾도록 만들어야 한다는 것
수식
a, b, x, y, 이차방정식
이미지 DNA
비율 2:1 (470px*240px)
글자 비율 15%
고정 정보
중1, 방정식 단원, 4월
중요도 2
중요도 2
중요도 3
중요도 1
중요도 1
중요도 3
같은 문제 찾을 때:
비슷한 문제 찾을 때:
37.
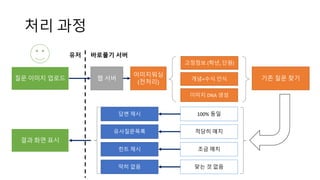
처리 과정
질문 이미지업로드
이미지워싱
(전처리)
딱히 없음
개념+수식 인식 기존 질문 찾기
이미지 DNA 생성
고정정보 (학년, 단원)
답변 제시
유사질문목록
힌트 제시
맞는 것 없음
100% 동일
적당히 매치
조금 매치
결과 화면 표시
웹 서버
유저 바로풀기 서버
38.
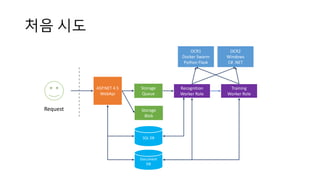
처음 시도
SQL DB
ASP.NET4.5
WebApi
Storage
Blob
Recognition
Worker Role
Request
Training
Worker Role
OCR1
Docker Swarm
Python Flask
OCR2
Windows
C# .NET
Storage
Queue
Document
DB
프로그래밍의 꽃 =최적화
• 목표: 저렴한 컴퓨팅 파워로 E2E 2초 이내 응답!
• http 콜 한번으로 처리
• 런칭: 6400ms
• 중간: 4200ms (medium 2 core x 5대)
• 현재: 1400ms (small instance 1 core x 2대)
• 향후: 1100ms (small instance 1 core 1대)
• 주요 변곡점: C 코드로 일부 전환, 중복 처리 제거, CQRS 제거, 키워드 최적화, 인덱싱
개선. 이미지 각도 보정은 UX로 해결
• 더 빨리 할 구석이 많지만 일단 퀄리티는 확보했음.
43.
주요 지표
• 인덱싱개선은 노오오력 대비 효과가 뚜렷하진 않음
• 데이터 자체가 중요하지
어떻게 더 잘 찾는건 그 다음
• 한 달 15,000개 답변
• 수학 질문의 30%는 봇이 처리
• Apache Korean Lucene이 아닌
수학문제 전용이 필요 만드는중
0
100
200
300
400
500
600
700
800
900
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
바로봇 답변 숫자
인덱싱 개선 1차 인덱싱 개선 2차
어느 날 문득
•“수학 문제 풀면 성취도를 분석하는 서비스들이 많네…”
• 문제 일일이 만들던데…
• 문제의 값어치는 매우 낮다 그걸 해야하나
• 있는 문제를 다 디지털화 하면 어떨까
• 수학은 논리의 언어이므로, 해볼 만 하다.
48.
수학 콘텐츠를 온전히semantic하게 다루고 싶다
• 현재 수학 관련 서비스들
• 99% 아래아한글로 제작
• 제작한 문제를 이미지 캡처로 제공
• 문제은행 DB도 이미지+메타데이터로 트리 탐색+키워드 검색 수준
• 하나의 문제 셋트의 구성
• 정적 정보
• 단원, 문제 번호
• 지문, 객관식/주관식, 해설, 정답
• 관련개념, 난이도, 출처
• 지문의 구성: 평문, 수식, 그림
• 동적 정보: 오답률, 응시자 수 등등
49.
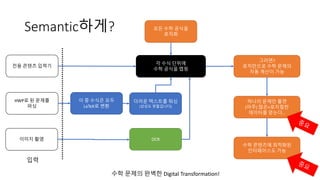
Semantic하게? 모든 수학공식을
로직화
HWP로 된 문제를
파싱
각 수식 단위에
수학 공식을 맵핑
그러면?
로직만으로 수학 문제의
자동 계산이 가능
이 중 수식은 모두
LaTeX로 변환
더러운 텍스트를 워싱
(상상도 못할겁니다)
수학 문제의 완벽한 Digital Transformation!
이미지 촬영 OCR
입력
전용 콘텐츠 입력기
하나의 문제만 풀어도
(아주) 많은+로지컬한
데이터를 얻게 된다…
수학 콘텐츠에 최적화된
인터페이스도 가능
50.
만들었음
자동으로 계산,
같은 유형의문제를
무제한 생성 가능!
수식 파싱으로
IDE처럼 뷰티풀한
컬러처리 가능!
소개글: https://www.facebook.com/youngjaekim81/posts/10154783298082794
데이터 마이닝 (현실)
•가장 큰 문제는, 쌓인게 그리 쓸모있지 않다는걸 알았을 때다
• 이럴 때, 서비스라면 UX부터 수정해야 한다
• 유저를 잘 이끄는 인터페이스가 있어야 좋은 데이터도 가능!
• 저는요
• 쓸모있지 않다는걸 알면 가장 먼저 UX부터 고침
• 새로 들어오는 자료라도 좀 더 목적에 맞도록
• 앱/프론트 개발 체인이 잘 돌아가는 팀이면 여기서 큰 이득
57.
똥인지 된장인지 어떻게아나
• Correlation 파악부터 시작하면 좋음
• 여러 전통적인 통계 기법을 활용 엑셀 무시하지 말라능
• ANOVA, MANOVA, t-검정, …
• 최소 데이터 1만건 정도면 대강은 파악
• 이를 통해, 전처리 필터를 빡시게 조여준다
• 이러면 정작 얻는 데이터는 많지 않음
• 필터가 별로 필요없다면
• 트레이닝 비교하기 좋도록
Categorizing, Sampling을 단계별/규모별로 나누자
똥을 꼭
먹어봐야 아.나.
통계는…
• 전처리 과정에서가치 있는 값을 선별 전처리를 무시하지 맙시다
• 데이터를 처리한 결과가 각이 나올지 미리 판단할 수 있음
• 처리 결과로 가설을 검증할 때 중요
실제로 “데이터로 일한다”고 하면
이 정도 비중이랄까…
60.
이렇게 말하면…
• 머신러닝:“야! 통계는 다른 얘기야 바보야“
• 통계: “야! 머신러닝은 통계에서는 말이 안되는데 왜 엮어”
• 하지만, 데이터로 뭐 하겠다고 할 때
둘 중 하나라도 부족하면 최종 서비스의 완성도가 떨어짐
61.
왜 통계인가
• 보다성숙한 학문이기에, 보다 많은 케이스가 고려되어 있음.
• 각 방법론마다의 장단점과 반론이 탄탄함 적용하기 전에 되돌아봄
• 알고리즘 만으로는 해석/디버깅하기 어려운 부분을 통계가 보완
• 솔직히 내 손으로 디버깅 못하는 것에 대한 보완의 의미도 있어요
• 머신러닝보다 좋은 결과를 내는 경우도 있음.
• 모수가 적을 때 차라리 통계만으로 rule set을 정하는게 낫다.
• 대부분의 경우, 뭘 하든 처음엔 모수가 적다.
62.
인공지능/머신러닝으로 상품화 했지만
제품이이상했던 스타트업들이 놓친 점 세가지
1. 통계로 미리 봤다면
• 미리 수집 데이터의 품질을 알았다면
• 미리 쓰레기 입력값을 걸렀다면
2. 알파/베타 테스트 과정이 너무 적었던건 아닐까
• 물론 했다
• 하지만 테스트만 했을 뿐 피드백을 별로 반영 안했다 (못했다?)
3. 입력과 출력의 연관성/정합성 확인이 좀 더 필요
• 결과에 대한 해석을 ‘머신러닝 알고리즘이 내놓은 결과’라고 퉁친다
• 결과 해석에 설계만큼 공을 써야 디버깅도 할 수 있다
• 실제 유저와 얼굴 보면서 테스트도 필요
• 이런 방법을 촌스럽다고 생각하지 말아요
63.
데이터 부터?
• 데이터“분석” 부터 아님 데이터 “수집” 부터
• 애초에 내가 원하는 형태의 데이터는 없거나 부족함
• 딜레마
• 오래된 서비스에서 기존 데이터의 대부분은 쓰레기다
• 새로운 서비스를 만들자니 데이터가 전혀 없다
• 그렇다면! 급성장하는 새로운 서비스라면?
뭘 데이터로 할지 인사이트가 안생겨요
데이터 고민할 시간도 없음
와장창ㅠㅠ
64.
딜레마는 아직 끝나지않았다
• 데이터 저장 전략: DB 선택
• 자유분방하게 쌓고 갈무리를 잘하자!
• MongoDB 같은 도큐먼트 기반 DBMS 사용
• 단점: 데이터 아구가 안맞을 때가 많음
• 장점: 확장성이 있어서 좋음
• 시작부터 깐깐하게 쌓자!
• 전통적인 RDBMS
• 단점: 서비스 성장에 발목잡힘
• 장점: 즉시즉시 쿼리로 통계를 만들기에 좋음
• 생각할 시간도 없이 일단 쌓자!
• 날 것의 txt 로깅
• 단점: 후임자가 알아서 job을 만들어 돌리겠지
• 장점: 빠르고 튼튼데스네.
65.
그나마 데이터 수집하기좋은 어프로치 #1
• 시작부터 클라우드에 쌓으면 좋습니다
• 데이터 유실 걱정 없고
• 데이터 가공 서비스를 제공하므로 빠르게 적용 가능
• 빨리 실패하고 다시 하면 그만
• 멋진 시각화도 쉽게 가능
66.
그나마 데이터 수집하기좋은 어프로치 #2
• 쌓을 데이터 유형을 미리 정해놓으면 좋다.
• Key-Value
• Table (RDBMS)
• Tree (json)
• Graph
67.
결국 귀결되는 것 모.델.링.
• 하아…그런데 그게 쉽나요
• 설계 잘 하는 동료와 일하는 것도 복이에요
• 모델링을 여기서 설명할 수는 없어요
• 도메인마다 고유의 특징이 있기 때문이죠
• 데이터가 힘이라는데
쌓인 바이너리가 힘이 아니라
모델링한 데이터가 많은 것이 힘
당장 모델링 적용할 수 있는 툴을 갖추면 더 좋음
68.
좋은 모델링을 위한강력추천 팁
Excel, R, SPSS
•간단필터+통계로 간보기
Python
•스크립팅을 하면서 로직 작성/트레이닝
C#/Java
•Typed language로 1:1 컨버팅 후 테스트/프로덕션
Tooling
•웹이든 데스크톱이든 시각화/전용툴/대시보드 개발
없으면 만들자 (X)있어도 만들자 (O)
• 왜 바퀴를 새로 만드나
http://knowyourmeme.com/memes/princess-monster-truck
http://www.mtbnj.com/forum/threads/end-of-society-bike.37340/page-2
몇가지 프로그래밍에 대한주관
• 반드시 시각적이어야 한다
• 콘솔질 극혐!
• 모르는 사람도 한 눈에 파악할 수 있도록
• Visualization 라이브러리가 넘치는데 시각화를 안하는건 말이 안됨
• Tool-centric Development. GUI 구려도 됨. 하지만 GUI가 없으면 안됨.
• 마우스만으로 다룰 수 있는 툴을 만든다
• 나는 개발에 집중하고 이를 이용한 활용은 비전공자가 할 수 있음.
• 최신 데이터 인덱싱 1000개를 해야 합니다 “이 프로그램에서 1000 입력하고 버튼 누르세요”
• 주의: GUI 버그가 있을 수도 있다.
• 그!래!서! 좋은 GUI 프레임워크를 선택하는 것도 필요.
• MVVM 아키텍처가 GUI를 빠르게 만들기엔 가장 좋더군요. XAML+C# 또는 TypeScript+Angular4 기반의 것들
• GUI 만드는 개발자가 더 배려심 있습니다.
• 반드시 엔드유저가 경험하도록 한다
• 저는 서비스에 노출 안된 기술은 구라라고 생각해요





























![무엇을 하는 것인가 [자세히] 1/4
• 이미지워싱
1. 이미지를 깨끗하게 한다: 각도보정, 잡티제거, 글씨 또렷하게, 흑백화
2. 잘못된 형태는 거른다: 여러 문제 사진, 똥화질, 너무 작은 글씨 등
3. 문제 영역만 찾는다: [글+이미지+객관식] 영역과 [다른 문제, 장식, 배경] 등 구분](https://image.slidesharecdn.com/zixpa40oqkcl9u7zs3ji-signature-4fe94b8ef6f9957b119e6aaba55076acb102b745696a63de7d12b112aa4fa578-poli-170703223608/85/slide-33-320.jpg)
![무엇을 하는 것인가 [자세히] 2/4
• 개념+수식인식
1. 흑백 글자를 모두 점/선으로 변환
2. 수식과 한글을 분리
3. 수식을 인식 수식의 수준을 파악
4. 한글을 인식 개념 관련 단어를 취합
수식인식을 통해 “이차방정식” 정보를 추가로 얻음](https://image.slidesharecdn.com/zixpa40oqkcl9u7zs3ji-signature-4fe94b8ef6f9957b119e6aaba55076acb102b745696a63de7d12b112aa4fa578-poli-170703223608/85/slide-34-320.jpg)
![무엇을 하는 것인가 [자세히] 3/4
• 이미지DNA생성
• 하나의 그림으로서의 고유한 특징을 수치화한다
• 어려운 점: 무엇을 수치화해야 하는가? 특징점, 비율, 배치 등
0
34
45
200
121
3
149
52
98
34
39
189
14
13
2
56
200
200
200
200
200
140
170
35
140
16
34
45
145](https://image.slidesharecdn.com/zixpa40oqkcl9u7zs3ji-signature-4fe94b8ef6f9957b119e6aaba55076acb102b745696a63de7d12b112aa4fa578-poli-170703223608/85/slide-35-320.jpg)
![무엇을 하는 것인가 [자세히] 4/4
• 기존 질문 찾기
• 결국 저장되는건 각 문제의 특징을 요약한 형태
• 어려운 점: ‘같은 값’이 아닌 ‘비슷한 값’을 찾도록 만들어야 한다는 것
수식
a, b, x, y, 이차방정식
이미지 DNA
비율 2:1 (470px*240px)
글자 비율 15%
고정 정보
중1, 방정식 단원, 4월
중요도 2
중요도 2
중요도 3
중요도 1
중요도 1
중요도 3
같은 문제 찾을 때:
비슷한 문제 찾을 때:](https://image.slidesharecdn.com/zixpa40oqkcl9u7zs3ji-signature-4fe94b8ef6f9957b119e6aaba55076acb102b745696a63de7d12b112aa4fa578-poli-170703223608/85/slide-36-320.jpg)

































![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DEVIEW 2017] 14일만에 GitHub 스타 1K 받은 차트 오픈소스 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/deview2017-billboard-171018033912-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Line Developer Day 2014] 라인 글로벌 게임 서버 개발하기](https://cdn.slidesharecdn.com/ss_thumbnails/pdf-150310080952-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PYCON Korea 2018] Python Application Server for Recommender System](https://cdn.slidesharecdn.com/ss_thumbnails/20180818pyconapplicationserverforrecommendersystematkakaorev3-180819041338-thumbnail.jpg?width=640&height=640&fit=bounds)
![[114]파파고 서비스 2년의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/114papago-181011030516-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DEVIEW 2016] 네이버의 모던 웹 라이브러리 - egjs](https://cdn.slidesharecdn.com/ss_thumbnails/egjs-161115043853-thumbnail.jpg?width=640&height=640&fit=bounds)
![[1A2]반응형무한스크롤](https://cdn.slidesharecdn.com/ss_thumbnails/1a2-140927230447-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Partner TechForum] 딥러닝 기반의 챗봇 기술을 활용한 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/chatbotaws-171122013303-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2대학생세미나]lovely algrorithm](https://cdn.slidesharecdn.com/ss_thumbnails/d2lovelyalgrorithm-140827015148-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[WTM18] 커리어에 데이터사이언스 더하기](https://cdn.slidesharecdn.com/ss_thumbnails/wtm18datascience-180409193139-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Paper] auto ml part 1](https://cdn.slidesharecdn.com/ss_thumbnails/paperautomlpart1-210413122952-thumbnail.jpg?width=640&height=640&fit=bounds)



