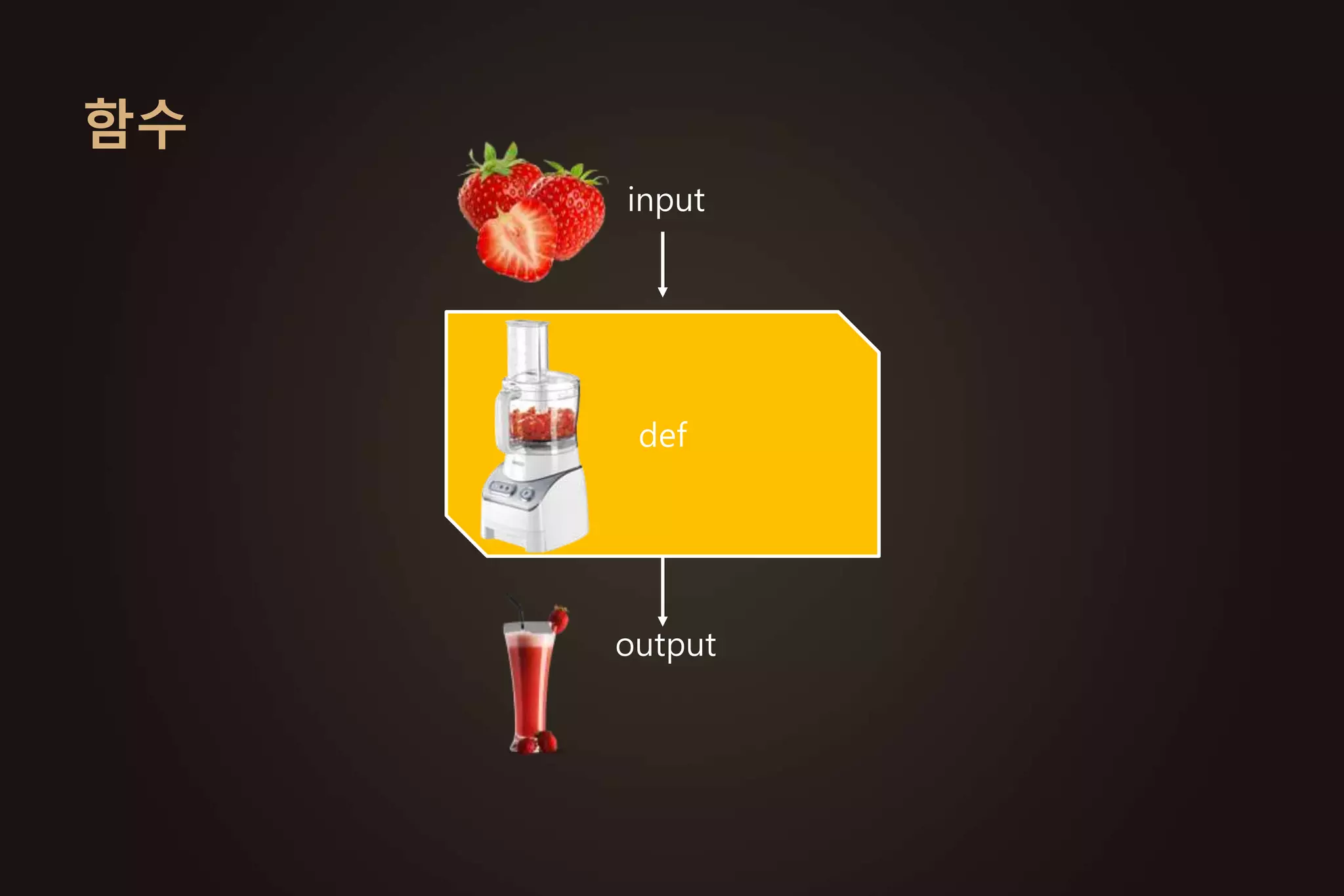
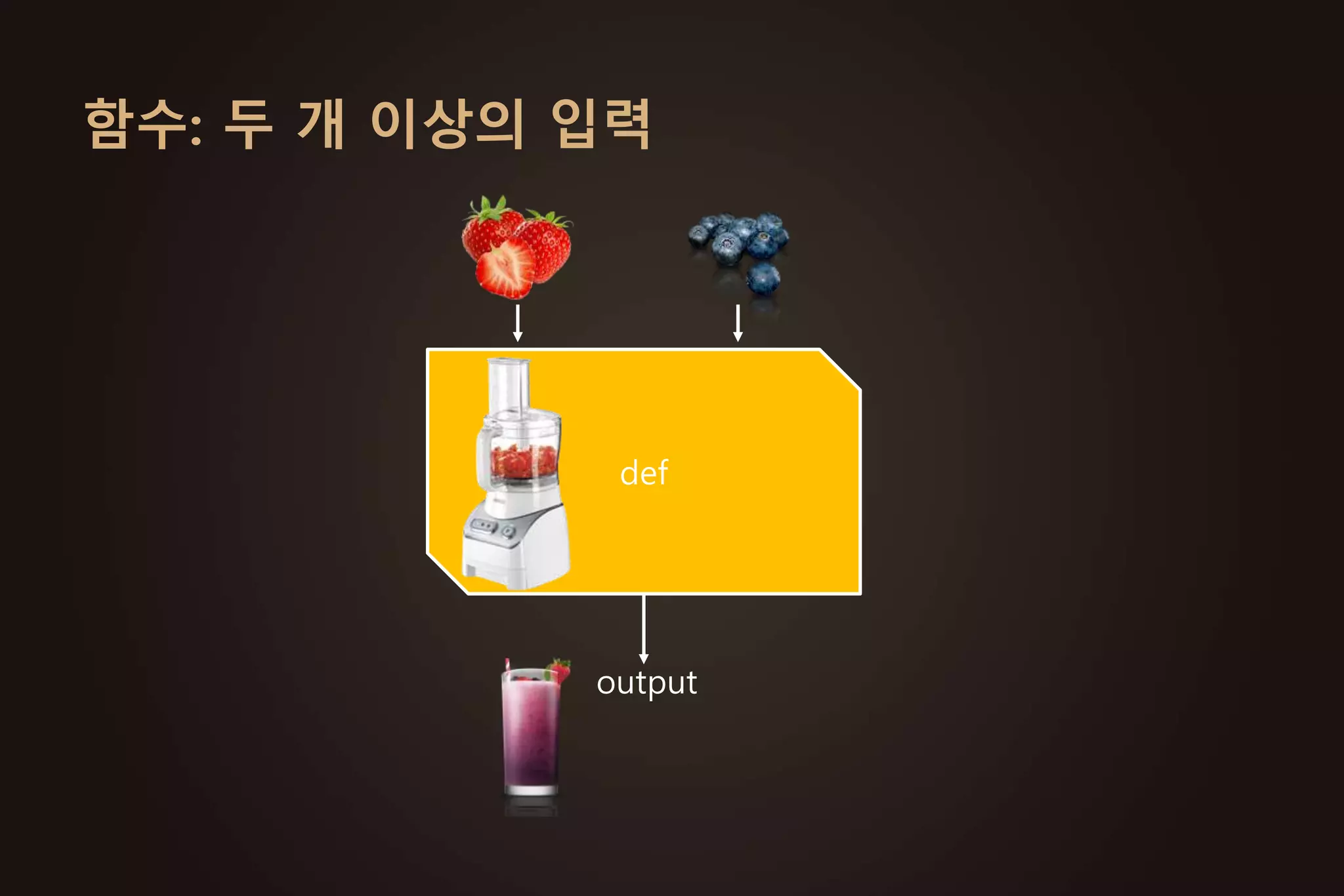
주요 파이썬 모듈
모듈설명 설치
webbrowser 브라우저에서 특정 페이지 조회. 표준 라이브러리
requests 웹페이지와 파일을 요청 pip install requests
BeautifulSoup HTML 문서에서 정보 추출 pip install beautifulsoup4
웹문서 = HTMLx CSS
HTML 소스
<html>
<body>
<h1>웹 스크래핑</h1>
<p>인터넷 데이터</p>
</body>
</html>
웹브라우저 출력
19.
<html>
</html>
HTML 페이지 구조
•body
• 브라우저에서 출력
• head
• 웹페이지의 제목 등
• body 내용 출력에 필요한 설정
<head>
</head>
<body>
</body>
20.
HTML 문법 기본
HTML태그 구조
<태그명>내용</태그명>
<태그명 속성=값, …>내용</태그명>
<태그 속성=값, …>
예시
<h1>제목1</h1>
<p>본문</p>
<img src=‘image.png’>
태그
• 태그는 대부분 쌍으로 이루어진
다.
• 태그 종류
• 시작: <태그명>
• 종료: </태그명>
• 태그는 속성을 가질 수 있다.
21.
HTML 텍스트 파일열기
• HTML 텍스트 파일을 바로 웹
브라우저에서 볼 수 있다.
• 웹서버가 없어도 된다.
• 외부에서는 조회 불가능
• URL
• 프로토콜: file://
• 경로: 파일시스템
22.
브라우저에서 소스 보기
•웹브라우저 메뉴의 개발자 도
구 활용
• 브라우저마다 메뉴가 다르다.
• 특정 요소의 HTML 태그 확인
가능
CSS 선택자 조합
CSS
p{ … }
.content p { … }
#footer p { … }
HTML
<div class="content">
<h1>웹문서</h1>
<p>HTML과 CSS</p>
</div>
<div id="footer">
<p>이성주</p>
</div>
27.
CSS 선택자 조합예시
CSS 선택자 예시 선택되는 요소
h1 모든 <h1>
#content id=“content” 속성을 갖는 모든 요소
.result class=“result” 속성을 갖는 모든 요소
div h1 <div> 내 모든 <h1>
div > h1 <div>에 직접 속한 <h1>
input[name] <input> 요소 중 name 속성을 갖는 것
input[type=“email”] <input> 요소 중 type=”email” 속성을 갖는 것
참조: http://www.w3schools.com/cssref/css_selectors.asp
정리
• webdriver
• 파이썬코드와 브라우저 상호 작용에 필요
• 크롬, 파이어폭스 지원
• 대상 웹브라우저 설치 필요
• 웹브라우저 버전에 맞는 드라이버 파일 필요
• 요소 선택
• browser.find_element_by_css_selector(CSS선택자)
관심 뉴스 웹사이트
제목웹사이트 CSS선택자*
JTBC http://news.jtbc.joins.com/ #jtbcBody a[href^="http://news.jtbc.joins.com/html"]
KBS http://news.kbs.co.kr/common/main.html #container a[href^="/news/view.do?ncd"]
MBC http://imnews.imbc.com/ #middle a[href^="http://imnews.imbc.com/news"]
SBS http://news.sbs.co.kr/news/newsMain.do .w_inner a[href^="/news/endPage.do?news_id"]
*2017-01-17 기준
49.
정리
• 뉴스 웹사이트기사 추출
• 특정 형식의 URL 선택
• CSS 속성 선택 활용
• 관심 뉴스 웹사이트 전체에서 기사 추출
• 각 웹사이트별 CSS 선택자 분석 필요
• 텍스트 또는 엑셀 파일 활용
• 자동 로그인 수행
• 계정 정보 입력 상자 요소 선택
• 입력 상자 요소 값 채우기: WebElement.send_keys()























![CSS 선택자 조합 예시
CSS 선택자 예시 선택되는 요소
h1 모든 <h1>
#content id=“content” 속성을 갖는 모든 요소
.result class=“result” 속성을 갖는 모든 요소
div h1 <div> 내 모든 <h1>
div > h1 <div>에 직접 속한 <h1>
input[name] <input> 요소 중 name 속성을 갖는 것
input[type=“email”] <input> 요소 중 type=”email” 속성을 갖는 것
참조: http://www.w3schools.com/cssref/css_selectors.asp](https://image.slidesharecdn.com/slide-160524235702/75/slide-27-2048.jpg)

















![CSS 선택자 속성값 지정
CSS 선택자 예시 선택 태그 예시
[attribute] [href] <a href="…">
<a href="…" class="article">
[attribute="value"] [href="/python"] <a href="/python">
[attribute~="value"] [value~="python"] <option value="python">
<option value="automate python">
<option value="python data">
[attribute|="value"] [class|="main] <div class="main">
<div class="main container">
<div class="main-container">
[attribute^="value"] [href^="/post"] <a href="/post/1">
<a href="/post/python/1">
[attribute$="value"] [href$="python"] <a href="/post/python">
<a href="category/python">
[attribute*="value"] [href*="py"] <a href="python">
<a href="/post/python">
<a href="automate python">](https://image.slidesharecdn.com/slide-160524235702/75/slide-47-2048.jpg)
![관심 뉴스 웹사이트
제목 웹사이트 CSS선택자*
JTBC http://news.jtbc.joins.com/ #jtbcBody a[href^="http://news.jtbc.joins.com/html"]
KBS http://news.kbs.co.kr/common/main.html #container a[href^="/news/view.do?ncd"]
MBC http://imnews.imbc.com/ #middle a[href^="http://imnews.imbc.com/news"]
SBS http://news.sbs.co.kr/news/newsMain.do .w_inner a[href^="/news/endPage.do?news_id"]
*2017-01-17 기준](https://image.slidesharecdn.com/slide-160524235702/75/slide-48-2048.jpg)













![[2014널리세미나] 시맨틱한 HTML5 마크업 구조 설계, 어떻게 할까?](https://cdn.slidesharecdn.com/ss_thumbnails/08-140827030216-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














![[커빙 아키텍쳐] 커빙은 어떻게 소셜 컨텐츠를 모아올까요?](https://cdn.slidesharecdn.com/ss_thumbnails/cubbyingtechstackfinal-130825210422-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PyConKR 2014] 30분만에 따라하는 동시성 스크래퍼](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-140830104844-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














![정찬명 - CSS Selectors in HTML [WSConf. Seoul 2016/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/cssselectorsinhtml-161222095114-thumbnail.jpg?width=640&height=640&fit=bounds)
