Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
aiichiro
573 views
増える実績データ、投資できない現実。少ない投資で最大限のパフォーマンスを得るにはどうするか?他のユーザーはどうしているか?
2014 dbtechshowcase 大阪 資料
Data & Analytics
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
11
/ 46
12
/ 46
13
/ 46
14
/ 46
15
/ 46
16
/ 46
17
/ 46
18
/ 46
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
More Related Content
PDF
イノベーションスプリント2011 nttデータにおける制約理論を活用した分散アジャイル開発~アジャイルとtocの融合
by
InnovationSprint2011
PDF
レガシーシステム再生のアンチパターン
by
Kent Ishizawa
PDF
けぷ人とけぷ太
by
ESM SEC
PDF
製品の質と、仕事の質を向上させるふりかえりの活用
by
ESM SEC
PDF
Qlik viewご紹介 v1.0
by
Yusuke-Ishii
PPTX
深層学習インフラ、借りるべきか?買うべきか?
by
Keisuke Fukuda
PDF
Cloudera impala
by
外道 父
PDF
20161125 Asakusa Framework Day オラクル講演資料
by
オラクルエンジニア通信
イノベーションスプリント2011 nttデータにおける制約理論を活用した分散アジャイル開発~アジャイルとtocの融合
by
InnovationSprint2011
レガシーシステム再生のアンチパターン
by
Kent Ishizawa
けぷ人とけぷ太
by
ESM SEC
製品の質と、仕事の質を向上させるふりかえりの活用
by
ESM SEC
Qlik viewご紹介 v1.0
by
Yusuke-Ishii
深層学習インフラ、借りるべきか?買うべきか?
by
Keisuke Fukuda
Cloudera impala
by
外道 父
20161125 Asakusa Framework Day オラクル講演資料
by
オラクルエンジニア通信
Similar to 増える実績データ、投資できない現実。少ない投資で最大限のパフォーマンスを得るにはどうするか?他のユーザーはどうしているか?
PDF
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
PDF
20150630_データ分析に最適な基盤とは? -コスト/スピードでビジネスバリューを得るために- by 株式会社インサイトテクノロジー CTO 石川雅也
by
Insight Technology, Inc.
PDF
たった1時間でシステム構築!“激速”環境構築を実現する“パターン技術”の秘密とは
by
Rina Owaki
PDF
A24 SQL Server におけるパフォーマンスチューニング手法 - 注目すべきポイントを簡単に by 多田典史
by
Insight Technology, Inc.
PDF
C14_ひとつのdbでは夢を現実に変えられない!Human Dreams.Make IT Real by 石川太一
by
Insight Technology, Inc.
PPT
yokyo-unv.
by
hirano
PPTX
アプリケーション性能を管理するのに必要なこと
by
Atsushi Takayasu
PDF
業界ごとのデータ分析を支援するIBM Data and AI Acceleratorsのご紹介
by
Tsuyoshi Hirayama
PDF
CGS_J_28.2.12
by
Hemant_Kumar_Setya
PDF
最適なビックデータ・システムの構築のために
by
IBM Systems @ IBM Japan, Ltd.
PDF
A12 既存のデータベース環境で分析業務を加速させるには? DB2が実現するソフトウエア分析ソリューション(DB2 BLU Acceleration)の仕...
by
Insight Technology, Inc.
PDF
CGS_J_29.2.12
by
Hemant_Kumar_Setya
PDF
CGS_J_7.4.12
by
Hemant_Kumar_Setya
PDF
IBMのITインフラビジョン
by
IBM Systems @ IBM Japan, Ltd.
PDF
B23,B31 sap sybase iq ~全部話します。IQのカラムストア方式、ビットワイズインデックス、DQP、カラム圧縮、等々 by Toshih...
by
Insight Technology, Inc.
PDF
IRM_J_9.3.12
by
Hemant_Kumar_Setya
PPT
IT部門がビジネスに貢献するためのメソドロジー
by
UNIRITA Incorporated
PDF
第26回「インメモリー・コンピューティングの現状と将来」(2013/05/23 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
PDF
IRM_J_7.4.12
by
Hemant_Kumar_Setya
PDF
CGS_J_3.2.12
by
Hemant_Kumar_Setya
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
20150630_データ分析に最適な基盤とは? -コスト/スピードでビジネスバリューを得るために- by 株式会社インサイトテクノロジー CTO 石川雅也
by
Insight Technology, Inc.
たった1時間でシステム構築!“激速”環境構築を実現する“パターン技術”の秘密とは
by
Rina Owaki
A24 SQL Server におけるパフォーマンスチューニング手法 - 注目すべきポイントを簡単に by 多田典史
by
Insight Technology, Inc.
C14_ひとつのdbでは夢を現実に変えられない!Human Dreams.Make IT Real by 石川太一
by
Insight Technology, Inc.
yokyo-unv.
by
hirano
アプリケーション性能を管理するのに必要なこと
by
Atsushi Takayasu
業界ごとのデータ分析を支援するIBM Data and AI Acceleratorsのご紹介
by
Tsuyoshi Hirayama
CGS_J_28.2.12
by
Hemant_Kumar_Setya
最適なビックデータ・システムの構築のために
by
IBM Systems @ IBM Japan, Ltd.
A12 既存のデータベース環境で分析業務を加速させるには? DB2が実現するソフトウエア分析ソリューション(DB2 BLU Acceleration)の仕...
by
Insight Technology, Inc.
CGS_J_29.2.12
by
Hemant_Kumar_Setya
CGS_J_7.4.12
by
Hemant_Kumar_Setya
IBMのITインフラビジョン
by
IBM Systems @ IBM Japan, Ltd.
B23,B31 sap sybase iq ~全部話します。IQのカラムストア方式、ビットワイズインデックス、DQP、カラム圧縮、等々 by Toshih...
by
Insight Technology, Inc.
IRM_J_9.3.12
by
Hemant_Kumar_Setya
IT部門がビジネスに貢献するためのメソドロジー
by
UNIRITA Incorporated
第26回「インメモリー・コンピューティングの現状と将来」(2013/05/23 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
IRM_J_7.4.12
by
Hemant_Kumar_Setya
CGS_J_3.2.12
by
Hemant_Kumar_Setya
増える実績データ、投資できない現実。少ない投資で最大限のパフォーマンスを得るにはどうするか?他のユーザーはどうしているか?
1.
増える実績データ、投資できない現実。 小規模でも少ない投資で最大限のパフォーマンスを 得るにはどうするか? 他のユーザーはどうしているか? 日本アイ・ビー・エム ソフトウェア事業 インフォメーション・マネジメント事業部 インフォメーション・アーキテクト 野間 愛一郎
2.
Please note ワークショップ、セッション、および資料は、IBMまたはセッション発表者によって準備され、それぞれ独自の見解を反 映したものです。それらは情報提供の目的のみで提供されており、いかなる参加者に対しても法律的またはその他の指導 や助言を意図したものではなく、またそのような結果を生むものでもありません。本講演資料に含まれている情報につい ては、完全性と正確性を期するよう努力しましたが、「現状のまま」提供され、明示または暗示にかかわらずいかなる保 証も伴わないものとします。本講演資料またはその他の資料の使用によって、あるいはその他の関連によって、いかなる 損害が生じた場合も、IBMは責任を負わないものとします。 本講演資料に含まれている内容は、IBMまたはそのサプライヤ ーやライセンス交付者からいかなる保証または表明を引きだすことを意図したものでも、IBMソフトウェアの使用を規定 する適用ライセンス契約の条項を変更することを意図したものでもなく、またそのような結果を生むものでもありませ ん。 本講演資料でIBM製品、プログラム、またはサービスに言及していても、IBMが営業活動を行っているすべての国でそれら が使用可能であることを暗示するものではありません。本講演資料で言及している製品リリース日付や製品機能は、市場 機会またはその他の要因に基づいてIBM独自の決定権をもっていつでも変更できるものとし、いかなる方法においても将 来の製品または機能が使用可能になると確約することを意図したものではありません。本講演資料に含まれている内容 は、参加者が開始する活動によって特定の販売、売上高の向上、またはその他の結果が生じると述べる、または暗示する ことを意図したものでも、またそのような結果を生むものでもありません。
パフォーマンスは、管理された環境において 標準的なIBMベンチマークを使用した測定と予測に基づいています。ユーザーが経験する実際のスループットやパフォー マンスは、ユーザーのジョブ・ストリームにおけるマルチプログラミングの量、入出力構成、ストレージ構成、および処 理されるワークロードなどの考慮事項を含む、数多くの要因に応じて変化します。したがって、個々のユーザーがここで 述べられているものと同様の結果を得られると確約するものではありません。 記述されているすべてのお客様事例は、それらのお客様がどのようにIBM製品を使用したか、またそれらのお客様が達成 した結果の実例として示されたものです。実際の環境コストおよびパフォーマンス特性は、お客様ごとに異なる場合があ ります。 IBM、IBM ロゴ、ibm.com、DB2、およびPureDataは、世界の多くの国で登録されたInternational Business Machines Corporationの商標です。 他の製品名およびサービス名等は、それぞれIBMまたは各社の商標である場合があります。 現時点での IBM の商標リストについては、www.ibm.com/legal/copytrade.shtmlをご覧ください。
3.
データ量の 増加 アプリケーションやサービスの高度化・多様化への対応 基幹DB トランザクション 88% ログ・データ 73% イベント
59% Eメール 57% ソーシャル・メディア 43% センサー 42% 外部フィード 42% RFIDスキャンまたはPOSデータ 41% フリー・フォーム・テキ スト 41% 地理情報 40% 音声 38% 静止画/ビデオ 34% すでにビッグデータに取り組んでいる組織に占める割合 ( ) 組織における ビッグデータに対する 積極的な取り組みの 一環として、 現在収集して分析している データ・ソースについて 質問した。 2012年、IBM Institute for Business Valueとサイード・ビジネス・スクールが共同で、 全世界のビッグデータに対する取り組みを調査
4.
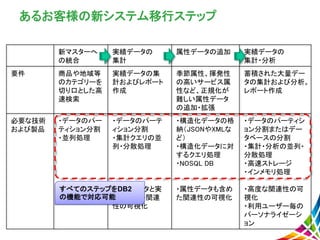
新マスターへ の統合 実績データの 集計 属性データの追加 実績データの 集計・分析 要件 商品や地域等 のカテゴリーを 切り口とした高 速検索 実績データの集 計およびレポート 作成 季節属性、揮発性 の高いサービス属 性など、正規化が 難しい属性データ の追加・拡張 蓄積された大量デー タの集計および分析。 レポート作成 必要な技術 および製品 ・データのパー ティション分割 ・並列処理 ・検索ワードに 関連した検索 ・データのパーテ ィション分割 ・集計クエリの並 列・分散処理 ・商品データと実 績データの関連 性の可視化 ・構造化データの格 納(JSONやXMLな ど) ・構造化データに対 するクエリ処理 ・NOSQL
DB ・属性データも含め た関連性の可視化 ・データのパーティシ ョン分割またはデー タベースの分割 ・集計・分析の並列・ 分散処理 ・高速ストレージ ・インメモリ処理 ・高度な関連性の可 視化 ・利用ユーザー毎の パーソナライゼーシ ョン あるお客様の新システム移行ステップ 新マスタDB 実績DB NoSQLDB
5.
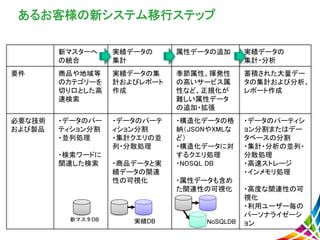
新マスターへ の統合 実績データの 集計 属性データの追加 実績データの 集計・分析 要件 商品や地域等 のカテゴリーを 切り口とした高 速検索 実績データの集 計およびレポート 作成 季節属性、揮発性 の高いサービス属 性など、正規化が 難しい属性データ の追加・拡張 蓄積された大量デー タの集計および分析。 レポート作成 必要な技術 および製品 ・データのパー ティション分割 ・並列処理 ・検索ワードに 関連した検索 ・データのパーテ ィション分割 ・集計クエリの並 列・分散処理 ・商品データと実 績データの関連 性の可視化 ・構造化データの格 納(JSONやXMLな ど) ・構造化データに対 するクエリ処理 ・NOSQL
DB ・属性データも含め た関連性の可視化 ・データのパーティシ ョン分割またはデー タベースの分割 ・集計・分析の並列・ 分散処理 ・高速ストレージ ・インメモリ処理 ・高度な関連性の可 視化 ・利用ユーザー毎の パーソナライゼーシ ョン あるお客様の新システム移行ステップ 新マスタDB 実績DB NoSQLDB 新システム追加 新システム追加
6.
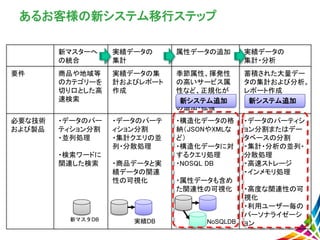
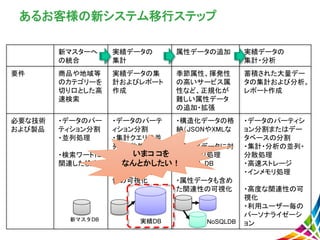
新マスターへ の統合 実績データの 集計 属性データの追加 実績データの 集計・分析 要件 商品や地域等 のカテゴリーを 切り口とした高 速検索 実績データの集 計およびレポート 作成 季節属性、揮発性 の高いサービス属 性など、正規化が 難しい属性データ の追加・拡張 蓄積された大量デー タの集計および分析。 レポート作成 必要な技術 および製品 ・データのパー ティション分割 ・並列処理 ・検索ワードに 関連した検索 ・データのパーテ ィション分割 ・集計クエリの並 列・分散処理 ・商品データと実 績データの関連 性の可視化 ・構造化データの格 納(JSONやXMLな ど) ・構造化データに対 するクエリ処理 ・NOSQL
DB ・属性データも含め た関連性の可視化 ・データのパーティシ ョン分割またはデー タベースの分割 ・集計・分析の並列・ 分散処理 ・高速ストレージ ・インメモリ処理 ・高度な関連性の可 視化 ・利用ユーザー毎の パーソナライゼーシ ョン あるお客様の新システム移行ステップ 新マスタDB 実績DB NoSQLDB いまコ コを なんとかしたい!
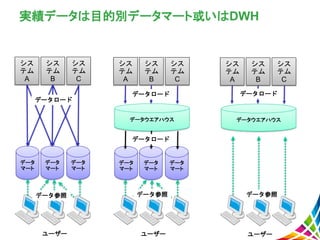
7.
実績データは目的別データマート或いはDWH シス テム A シス テム B シス テム C データ マート ユーザー データ マート データ マート シス テム A シス テム B シス テム C データ マート データウエアハウス ユーザー データ マート データ マート シス テム A シス テム B シス テム C データウエアハウス ユーザー データロード データロード データロード データロード データ参照 データ参照 データ参照
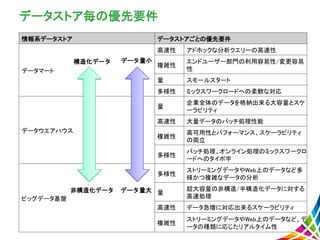
8.
データストア毎の優先要件 情報系データストア データストアごとの優先要件 データマート 高速性 アドホックな分析クエリーの高速性 複雑性 エンドユーザー部門の利用容易性/変更容易 性 量
スモールスタート 多様性 ミックスワークロードへの柔軟な対応 データウエアハウス 量 企業全体のデータを格納出来る大容量とスケ ーラビリティ 高速性 大量データのバッチ処理性能 複雑性 高可用性とパフォーマンス、スケーラビリティ の両立 多様性 バッチ処理、オンライン処理のミックスワークロ ードへのタイポ宇 ビッグデータ基盤 多様性 ストリーミングデータやWeb上のデータなど多 様かつ複雑なデータの分析 量 超大容量の非構造/半構造化データに対する 高速処理 高速性 データ急増に対応出来るスケーラビリティ 複雑性 ストリーミングデータやWeb上のデータなど、デ ータの種類に応じたリアルタイム性 データ量小 データ量大 構造化データ 非構造化データ
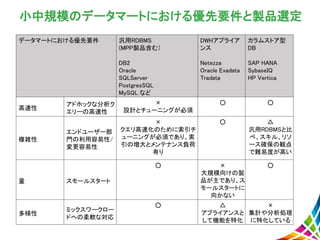
9.
小中規模のデータマートにおける優先要件と製品選定 データマートにおける優先要件 汎用RDBMS (MPP製品含む) DB2 Oracle SQLServer PostgresSQL MySQL など DWHアプライア ンス Netezza Oracle
Exadata Tradata カラムストア型 DB SAP HANA SybaseIQ HP Vertica 高速性 アドホックな分析ク エリーの高速性 × 設計とチューニングが必須 ○ ○ 複雑性 エンドユーザー部 門の利用容易性/ 変更容易性 × クエリ高速化のために索引チ ューニングが必須であり、索 引の増大とメンテナンス負荷 有り ○ △ 汎用RDBMSと比 べ、スキル、リソ ース確保の観点 で難易度が高い 量 スモールスタート ○ × 大規模向けの製 品が主であり、ス モールスタートに 向かない ○ 多様性 ミックスワークロー ドへの柔軟な対応 ○ △ アプライアンスと して機能を特化 × 集計や分析処理 に特化している
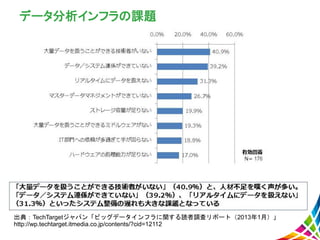
10.
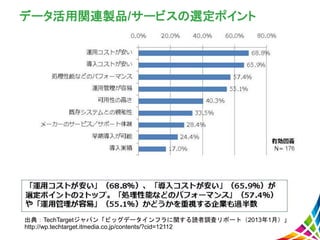
データ分析インフラの課題 出典:TechTargetジャパン「ビッグデータインフラに関する読者調査リポート(2013年1月)」 http://wp.techtarget.itmedia.co.jp/contents/?cid=12112
11.
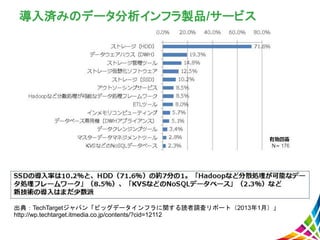
データ活用関連製品/サービスの選定ポイント 出典:TechTargetジャパン「ビッグデータインフラに関する読者調査リポート(2013年1月)」 http://wp.techtarget.itmedia.co.jp/contents/?cid=12112
12.
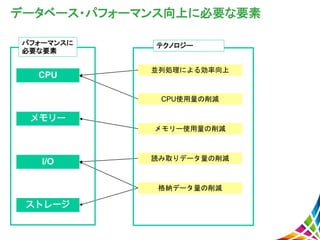
導入済みのデータ分析インフラ製品/サービス 出典:TechTargetジャパン「ビッグデータインフラに関する読者調査リポート(2013年1月)」 http://wp.techtarget.itmedia.co.jp/contents/?cid=12112
13.
例)集計・分析業務で実行されるクエリー -- Query 02
- Minimum Cost Supplier Query select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment from tpcd.part, tpcd.supplier, tpcd.partsupp, tpcd.nation, tpcd.region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and p_size = 15 and p_type like '%BRASS' and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE‘ and ps_supplycost = ( select min(ps_supplycost) from tpcd.partsupp, tpcd.supplier, tpcd.nation, tpcd.region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE' ) order by s_acctbal desc, n_name, s_name, p_partkey fetch first 100 rows only ; サンプルクエリ ー 特定の部品を特定地域から注文する場合の、最もコスト低い取引先一覧を取得しよう とするクエリー。 4つの表を結合する副照会と、5つの表の結合処理とが組み合わさっています。
14.
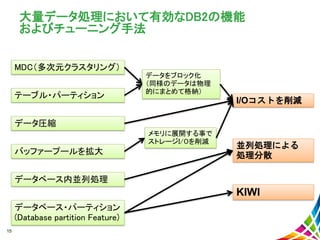
データベース・パフォーマンス向上に必要な要素 メモリー CPU I/O 読み取りデータ量の削減 メモリー使用量の削減 並列処理による効率向上 CPU使用量の削減 ストレージ 格納データ量の削減 パフォーマンスに 必要な要素 テクノロジー
15.
15 大量データ処理において有効なDB2の機能 およびチューニング手法 MDC(多次元クラスタリング) データをブロック化 (同様のデータは物理 的にまとめて格納) データ圧縮 バッファープールを拡大 メモリに展開する事で ストレージI/Oを削減 テーブル・パーティション データベース内並列処理 データベース・パーティション (Database partition Feature) I/Oコストを削減 並列処理による 処理分散 KIWI
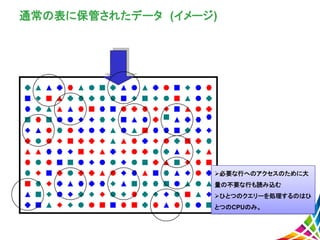
16.
通常の表に保管されたデータ (イメージ) 必要な行へのアクセスのために大 量の不要な行も読み込む ひとつのクエリーを処理するのはひ とつのCPUのみ。
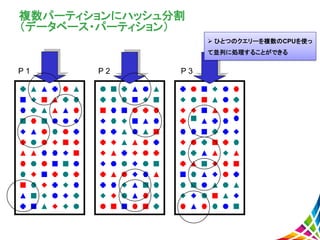
17.
複数パーティションにハッシュ分割 (データベース・パーティション) P 1 P
2 P 3 ひとつのクエリーを複数のCPUを使っ て並列に処理することができる
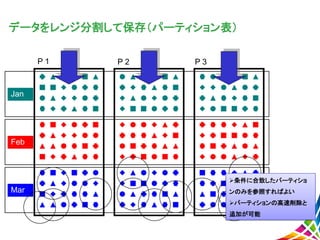
18.
データをレンジ分割して保存(パーティション表) P 1 Jan Feb Mar P 2
P 3 条件に合致したパーティショ ンのみを参照すればよい パーティションの高速削除と 追加が可能
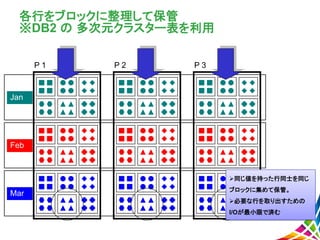
19.
各行をブロックに整理して保管 ※DB2 の 多次元クラスター表を利用 P
1 Jan Feb Mar P 2 P 3 同じ値を持った行同士を同じ ブロックに集めて保管。 必要な行を取り出すための I/Oが最小限で済む
20.
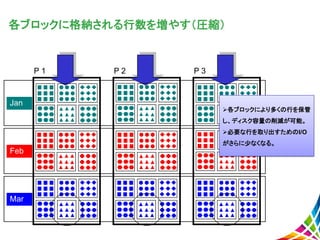
各ブロックに格納される行数を増やす(圧縮) P 1 Jan Feb Mar P 2
P 3 各ブロックにより多くの行を保管 し、ディスク容量の削減が可能。 必要な行を取り出すためのI/O がさらに少なくなる。
22.
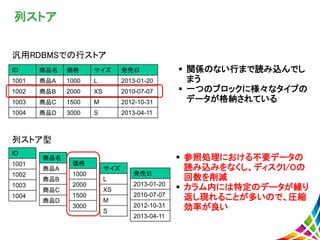
列ストア 汎用RDBMSでの行ストア 列ストア型 参照処理における不要データの 読み込みをなくし、ディスクI/Oの 回数を削減 カラム内には特定のデータが繰り 返し現れることが多いので、圧縮 効率が良い ID
商品名 価格 サイズ 発売日 1001 商品A 1000 L 2013-01-20 1002 商品B 2000 XS 2010-07-07 1003 商品C 1500 M 2012-10-31 1004 商品D 3000 S 2013-04-11 ID 1001 1002 1003 1004 商品名 商品A 商品B 商品C 商品D 価格 1000 2000 1500 3000 サイズ L XS M S 発売日 2013-01-20 2010-07-07 2012-10-31 2013-04-11 関係のない行まで読み込んでし まう 一つのブロックに様々なタイプの データが格納されている
23.
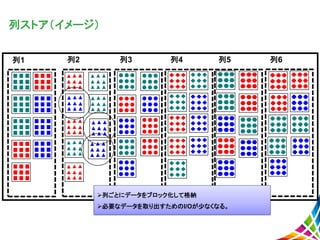
列ストア(イメージ) 列1 列2 列3
列4 列5 列6 列ごとにデータをブロック化して格納 必要なデータを取り出すためのI/Oが少なくなる。
24.
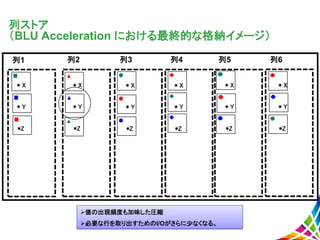
列ストア (BLU Acceleration における最終的な格納イメージ) 列1 値の出現頻度も加味した圧縮 必要な行を取り出すためのI/Oがさらに少なくなる。 列2
列3 列4 列5 列6 * X * Y *Z * X * Y *Z * X * Y *Z * X * Y *Z * X * Y *Z * X * Y *Z
26.
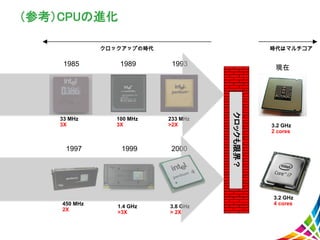
1985 33 MHz 3X 1989 100 MHz 3X 1993 233
MHz >2X 1997 450 MHz 2X 1999 1.4 GHz >3X 2000 3.8 GHz > 2X 現在 3.2 GHz 2 cores 3.2 GHz 4 cores クロックアップの時代 時代はマルチコア クロックも限界? (参考)CPUの進化
27.
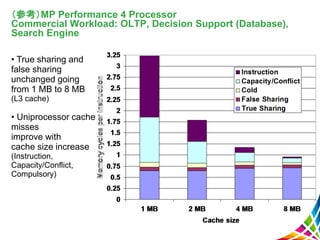
27 (参考)MP Performance 4
Processor Commercial Workload: OLTP, Decision Support (Database), Search Engine • True sharing and false sharing unchanged going from 1 MB to 8 MB (L3 cache) • Uniprocessor cache misses improve with cache size increase (Instruction, Capacity/Conflict, Compulsory)
28.
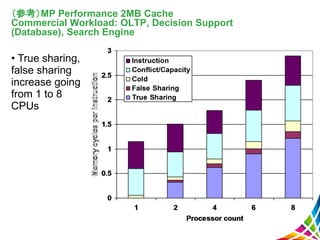
28 (参考)MP Performance 2MB
Cache Commercial Workload: OLTP, Decision Support (Database), Search Engine • True sharing, false sharing increase going from 1 to 8 CPUs
29.
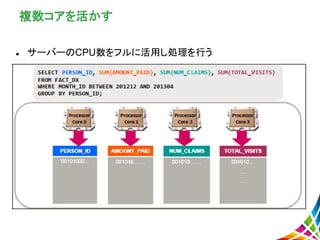
複数コアを活かす サーバーのCPU数をフルに活用し処理を行う
31.
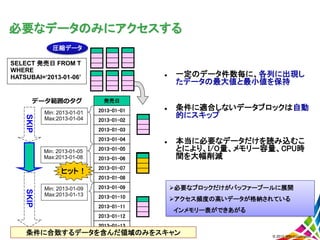
必要なデータのみにアクセスする 一定のデータ件数毎に、各列に出現し たデータの最大値と最小値を保持 条件に適合しないデータブロックは自動 的にスキップ
本当に必要なデータだけを読み込むこ とにより、I/O量、メモリー容量、CPU時 間を大幅削減 発売日 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06 2013-01-07 2013-01-08 2013-01-09 2013-01-10 2013-01-11 2013-01-12 2013-01-13 Min: 2013-01-09 Max:2013-01-13 SELECT 発売日 FROM T WHERE HATSUBAI=‘2013-01-06’ Min: 2013-01-01 Max:2013-01-04 SKIP 条件に合致するデータを含んだ領域のみをスキャン Min: 2013-01-05 Max:2013-01-08 SKIP ヒット! 圧縮データ データ範囲のタグ © 2013 IBM Corporation 必要なブロックだけがバッファープールに展開 アクセス頻度の高いデータが格納されている インメモリー表ができあがる
32.
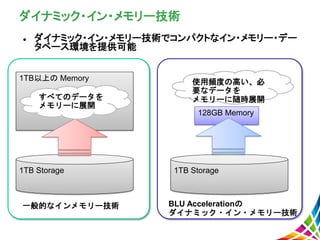
ダイナミック・イン・メモリー技術 ダイナミック・イン・メモリー技術でコンパクトなイン・メモリー・デー タベース環境を提供可能 1TB以上の Memory 128GB
Memory 1TB Storage 1TB Storage 一般的なインメモリー技術 BLU Accelerationの ダイナミック・イン・メモリー技術 すべてのデータを メモリーに展開 使用頻度の高い、必 要なデータを メモリーに随時展開
34.
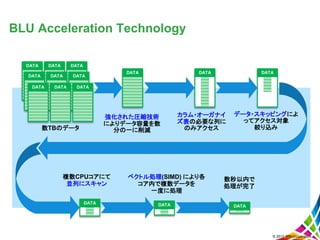
数TBのデータ 強化された圧縮技術 によりデータ容量を数 分の一に削減 複数CPUコアにて 並列にスキャン ベクトル処理(SIMD) により各 コア内で複数データを 一度に処理 数秒以内で 処理が完了 カラム・オーガナイ ズ表の必要な列に のみアクセス データ・スキッピングによ ってアクセス対象 絞り込み DATA DATA DATA DATA DATA DATA DATA DATA DATA DATA DATA
DATA DATA DATA DATA © 2013 IBM Corporation BLU Acceleration Technology
35.
© 2013 IBM
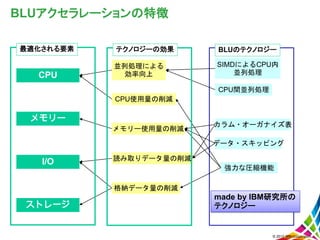
Corporation BLUアクセラレーションの特徴 メモリー CPU I/O 読み取りデータ量の削減 データ・スキッピング メモリー使用量の削減 並列処理による 効率向上 CPU使用量の削減 強力な圧縮機能 CPU間並列処理 SIMDによるCPU内 並列処理 カラム・オーガナイズ表 ストレージ 格納データ量の削減 最適化される要素 テクノロジーの効果 BLUのテクノロジー made by IBM研究所の テクノロジー
36.
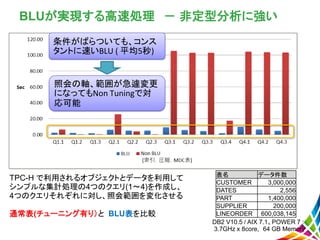
BLUが実現する高速処理 - 非定型分析に強い 表名
データ件数 CUSTOMER 3,000,000 DATES 2,556 PART 1,400,000 SUPPLIER 200,000 LINEORDER 600,038,145 DB2 V10.5 / AIX 7.1、POWER 7 : 3.7GHz x 8core, 64 GB Memory TPC-H で利用されるオブジェクトとデータを利用して シンプルな集計処理の4つのクエリ(1~4)を作成し、 4つのクエリそれぞれに対し、照会範囲を変化させる 通常表(チューニング有り)と BLU表を比較 条件がばらついても、コンス タントに速いBLU ( 平均5秒) 照会の軸、範囲が急遽変更 になってもNon Tuningで対 応可能
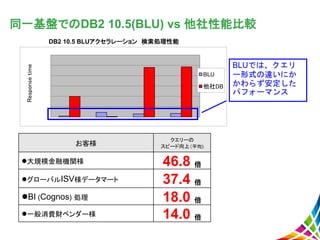
37.
同一基盤でのDB2 10.5(BLU) vs
他社性能比較Responsetime BLU 他社DB BLUでは、クエリ ー形式の違いにか かわらず安定した パフォーマンス DB2 10.5 BLUアクセラレーション 検索処理性能 お客様 クエリーの スピード向上(平均) 大規模金融機関様 46.8 倍 グローバルISV様データマート 37.4 倍 BI (Cognos) 処理 18.0 倍 一般消費財ベンダー様 14.0 倍
38.
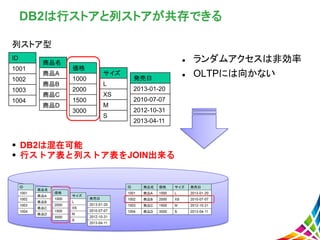
DB2は行ストアと列ストアが共存できる ランダムアクセスは非効率 OLTPには向かない
DB2は混在可能 行ストア表と列ストア表をJOIN出来る 列ストア型 ID 1001 1002 1003 1004 商品名 商品A 商品B 商品C 商品D 価格 1000 2000 1500 3000 サイズ L XS M S 発売日 2013-01-20 2010-07-07 2012-10-31 2013-04-11
39.
DB2 BLU Design
and Tuning • Create Table • Load data DB2では表にデータをロードするのみで利用可能 CREATE TABLE T1 ( C1 int, C2 char(200)) ORGANIZED BY COLUMN これだけ 索引や サマリー表も 必要ない アプライアンスに置き換える。ではなく、 汎用のRDBMSであるDB2の中で利用出来る
40.
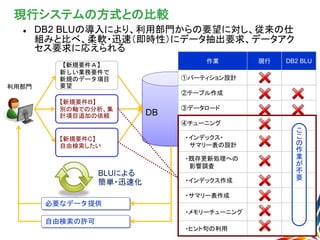
現行システムの方式との比較 DB2 BLUの導入により、利用部門からの要望に対し、従来の仕 組みと比べ、柔軟・迅速(即時性)にデータ抽出要求、データアク セス要求に応えられる DB 作業
現行 DB2 BLU ①パーティション設計 ②テーブル作成 ③データロード ④チューニング ・インデックス・ サマリー表の設計 ・既存更新処理への 影響調査 ・インデックス作成 ・サマリー表作成 ・メモリーチューニング ・ヒント句の利用 【新規要件A】 新しい業務要件で 新規のデータ項目 要望 【新規要件B】 別の軸での分析、集 計項目追加の依頼 【新規要件C】 自由検索したい 利用部門 必要なデータ提供 自由検索の許可 BLUによる 簡単・迅速化 こ こ の 作 業 が 不 要
41.
A社事例 : アドホッククエリの高速化
[目的] 全顧客情報を保有するDWHから作成される目的別データベース (データマート)のレスポンス向上を目的とした更改 [要件] ユーザー要件の変化への対応 (定型照会からBIツールによる非定型/アドホックな自由検索の増加) 同一データを利用するOLTP処理との共存 障害時の業務の継続性 既存IaaS環境の利用 上記の要件より、調査の結果、以下の技術は適合しないとの結論 NoSQL:データの一貫性が一部保てない インメモリDBMS:障害発生時のデータ再ロードが必要でありデータの永続性が一部保てない DWHアプライアンス(Nettezaテクノロジー):既存IaaS環境への適合ができず,また同一デー タを利用するOLTP処理との共存に考慮が必要 検索・集計処理のパフォーマンス(同一環境で実機検証したパフォーマン ス比較)、および処理特性に応じた最適なテーブル形式(行オーガナイズ表 /カラム・オーガナイズ表)を組み合わせて利用可能であることが評価ポイ ントとなり、DB2 10.5 BLU Accelerationを採用
42.
B社事例 : データマートのスモールスタート
[目的] Webからのログを収集蓄積する分析基盤としてのDMの構築 [要件] 分析データの一元管理(データ一貫性の確保,集計差異等の混乱排除) 容易に集計・分析を実現できる基盤の構築 データ管理基盤として,今後の多様化への対応が可能であること (追加拡張可能な基盤としての構築) 標準DBはPostgresSQLであったが、検索・集計処理のパフォーマンス(同一環境で実 機検証したパフォーマンス比較)、および処理特性に応じた最適なテーブル形式(行オ ーガナイズ表/カラム・オーガナイズ表)を組み合わせて利用可能であることが評価ポ イントとなり、DB2 10.5 BLU Accelerationを採用
43.
小中規模のデータマートにおける優先要件と DB2 BLU Acceleration データマートにおける優先要件
DB2 10.5 BLU Acceleration 高速性 アドホックな分析クエリーの高速性 ○ BLU Acceleration Technology により実現 複雑性 エンドユーザー部門の利用容易性/変更容易性 ○ 自動メンテナンス 自動チューニング 量 スモールスタート ○ RDBMSとしてスタートし、BLU を機能として利用 クラウド環境でも利用可能 多様性 ミックスワークロードへの柔軟な対応 ○ 用途に応じて行表と列表を使 い分ける 別途製品を必要としないため、 小中規模の統合データベース 基盤としてのニーズを満たす
44.
新マスターへ の統合 実績データの 集計 属性データの追加 実績データの 集計・分析 要件 商品や地域等 のカテゴリーを 切り口とした高 速検索 実績データの集 計およびレポート 作成 季節属性、揮発性 の高いサービス属 性など、正規化が 難しい属性データ の追加・拡張 蓄積された大量デー タの集計および分析。 レポート作成 必要な技術 および製品 ・データのパー ティション分割 ・並列処理 ・検索ワードに 関連した検索 ・データのパーテ ィション分割 ・集計クエリの並 列・分散処理 ・商品データと実 績データの関連 性の可視化 ・構造化データの格 納(JSONやXMLな ど) ・構造化データに対 するクエリ処理 ・NOSQL
DB ・属性データも含め た関連性の可視化 ・データのパーティシ ョン分割またはデー タベースの分割 ・集計・分析の並列・ 分散処理 ・高速ストレージ ・インメモリ処理 ・高度な関連性の可 視化 ・利用ユーザー毎の パーソナライゼーシ ョン あるお客様の新システム移行ステップ すべてのステップをDB2 の機能で対応可能
45.
Big Solution from
Small BOX !
Download










![A社事例 : アドホッククエリの高速化
[目的]
全顧客情報を保有するDWHから作成される目的別データベース
(データマート)のレスポンス向上を目的とした更改
[要件]
ユーザー要件の変化への対応
(定型照会からBIツールによる非定型/アドホックな自由検索の増加)
同一データを利用するOLTP処理との共存
障害時の業務の継続性
既存IaaS環境の利用
上記の要件より、調査の結果、以下の技術は適合しないとの結論
NoSQL:データの一貫性が一部保てない
インメモリDBMS:障害発生時のデータ再ロードが必要でありデータの永続性が一部保てない
DWHアプライアンス(Nettezaテクノロジー):既存IaaS環境への適合ができず,また同一デー
タを利用するOLTP処理との共存に考慮が必要
検索・集計処理のパフォーマンス(同一環境で実機検証したパフォーマン
ス比較)、および処理特性に応じた最適なテーブル形式(行オーガナイズ表
/カラム・オーガナイズ表)を組み合わせて利用可能であることが評価ポイ
ントとなり、DB2 10.5 BLU Accelerationを採用](https://image.slidesharecdn.com/db2dbtechshowcase2014osa2-160329145728/85/slide-41-320.jpg)
![B社事例 : データマートのスモールスタート
[目的]
Webからのログを収集蓄積する分析基盤としてのDMの構築
[要件]
分析データの一元管理(データ一貫性の確保,集計差異等の混乱排除)
容易に集計・分析を実現できる基盤の構築
データ管理基盤として,今後の多様化への対応が可能であること
(追加拡張可能な基盤としての構築)
標準DBはPostgresSQLであったが、検索・集計処理のパフォーマンス(同一環境で実
機検証したパフォーマンス比較)、および処理特性に応じた最適なテーブル形式(行オ
ーガナイズ表/カラム・オーガナイズ表)を組み合わせて利用可能であることが評価ポ
イントとなり、DB2 10.5 BLU Accelerationを採用](https://image.slidesharecdn.com/db2dbtechshowcase2014osa2-160329145728/85/slide-42-320.jpg)