발표자 소개
• 연구분야
• 데이터 마이닝, 정보검색, 데이터베이스, 빅데이터
• 연구 경력
• 군산대 통계컴퓨터과학과 조교수 (2014 – 현재)
• 서울대 차세대융합기술연구원 연구교수 (2011 – 2014)
• 일리노이대 차세대디지털과학센터 선임연구원 (2010)
• 브리티시컬럼비아대 박사후연구원 (2008 – 2009)
• 펜실베이니아주립대 컴퓨터공학 박사 (2007)
• 연구 업적
• CACM, KAIS 등 SCI 11편
• ICDM, ICDE, SDM 등 주요 데이터 마이닝 학회 논문 발표
• 폴리티즈, 뉴스소스, 사회문제 키워드 추출 시스템 등 시스템 개발 및 시
연
• 연구재단, 정보화진흥원, 에너지기술평가원, 닐슨 등 빅데이터 연구 과
제 수행
• Data Science Lab : datalab@kunsan.ac.kr
2
3.
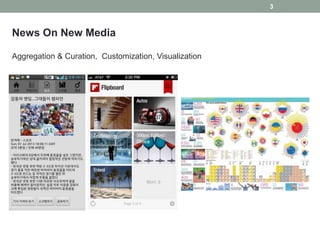
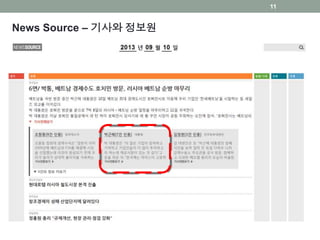
News On NewMedia
Aggregation & Curation, Customization, Visualization
3
4.
새로운 방식의 뉴스전달
낚시, 선정, 광고, 아마추어, 편향성, 쓸모 없음, 떨어지는 가독성…
4
5.
Journalism적인 가치
• 사실성,다양성, 심층성
• 사실성을 드러내는 관례
• 인용, 수치, 사례 등 [van Dijk 1988]
• 정보원 (News Source)
• 인용대상
• 기사 내용의 핵심 제공자
• 저널리즘 연구의 주요 주제
• [Sigal 1973], [Schudson 1978], & [Gans 1979]
5
6.
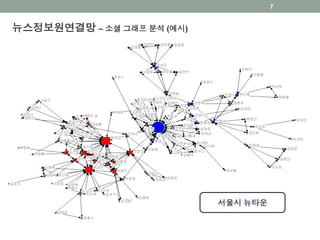
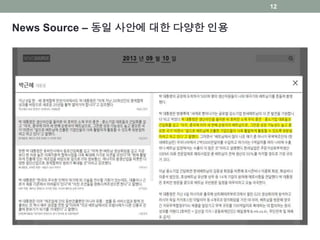
New Source NetworkAnalysis (뉴스 정보원 연결망 분석)
• 목표: 뉴스를 정보원 간의 관계를 통해 분류, 정리
• 뉴스 정보원 연결망
• 같은 기사에 두 정보원이 직접 인용문으로 함께 인용되면 이 정
보원들 간에 서로 의미론적 관계가 있다.
• 연결망(Network)을 분석하여 인물의 중요도를 계산
• 언론에서 중시되는 인물의 중요도를 소셜그래프의 중요도 척도
로 추정
• 같은 정보원이 있는 뉴스를 클러스터링 중복기사를 사건별로
정리
6
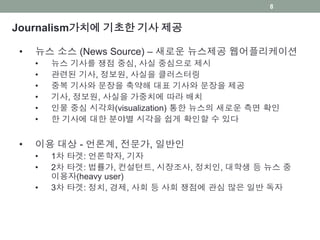
Journalism가치에 기초한 기사제공
• 뉴스 소스 (News Source) – 새로운 뉴스제공 웹어플리케이션
• 뉴스 기사를 쟁점 중심, 사실 중심으로 제시
• 관련된 기사, 정보원, 사실을 클러스터링
• 중복 기사와 문장을 축약해 대표 기사와 문장을 제공
• 기사, 정보원, 사실을 가중치에 따라 배치
• 인물 중심 시각화(visualization) 통한 뉴스의 새로운 측면 확인
• 한 기사에 대한 분야별 시각을 쉽게 확인할 수 있다
• 이용 대상 - 언론계, 전문가, 일반인
• 1차 타겟: 언론학자, 기자
• 2차 타겟: 법률가, 컨설턴트, 시장조사, 정치인, 대학생 등 뉴스 중
이용자(heavy user)
• 3차 타겟: 정치, 경제, 사회 등 사회 쟁점에 관심 많은 일반 독자
8
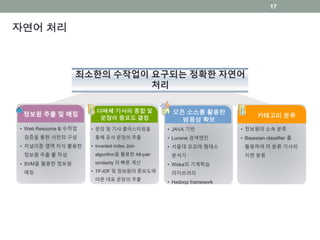
기술적 접근
• 자연어처리 (Natural Language Processing)
• 정보원의 자동 추출
• 이름, 조직, 직함
• 박근혜 대통령, 박 대통령, 박 전대표
• 통일부 김형석 대변인, 김형석 대변인, 김 대변인
• 익명이 많다 (김모씨, 이모씨, 청와대 모 관계자, 청와
대 핵심 관계자)
• 인용문의 추출
• Fact들도 추출 (숫자)
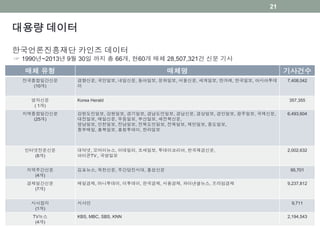
• 대용량 데이터
• 한국언론진흥재단 KINDS
• 28,507,321건의 기사
• 1990년 이후 66개 매체 기사
• 정보 시각화
자연어 처리
대용량 데이
터
정보 시각화
16
17.
자연어 처리
정보원 추출및 매칭
• Web Resource & 수작업
검증을 통한 사전의 구성
• 저널리즘 영역 지식 활용한
정보원 추출 룰 작성
• SVM을 활용한 정보원
매칭
최소한의 수작업이 요구되는 정확한 자연어
처리
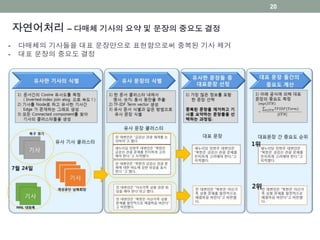
다매체 기사의 종합 및
문장의 중요도 결정 카테고리 분류
• 정보원의 소속 분류
• Bayesian classifier 를
활용하여 미 분류 기사의
지면 분류
• 문장 및 기사 클러스터링을
통해 유사 문장의 추출
• Inverted index Join
algorithm을 활용한 All-pair
similarity 의 빠른 계산
• TF-IDF 및 정보원의 중요도에
따른 대표 문장의 추출
오픈 소스를 활용한
범용성 확보
• JAVA 기반
• Lucene 검색엔진
• 서울대 꼬꼬마 형태소
분석기
• Weka의 기계학습
라이브러리
• Hadoop framework
17
18.
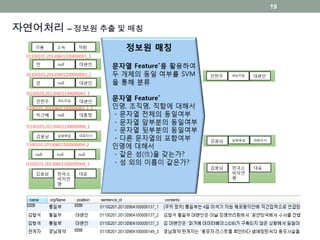
자연어처리 – 정보원추출 및 매칭
- 뉴스의 인용문으로 부터 인명/직함/소속을 추출하고 동일 개체를 판단하여 하나의 개체로 매칭
18
빅데이터 처리속도
68
90
63
1048
처리 시간(초)
기사와무관한 텍스트 제거
정보원 추출 및 매칭
Lucene indexing
다매체 기사 요약 및 중요 문장 추출
- 1일치 평균 뉴스 기사 수 3,300개 기준일 때 21분 소요
- 실행 환경 CPU: Intel i3-2100 CPU @ 3.10GHz, RAM: 4GB, OS : Ubuntu 12.04
- 서비스 시작 후 1일 치 씩 처리시는 문제 없음
- Single machine에서 모든 데이터(365(일) * 23(년))를 처리 하기 위해서는 49일 소요 예상됨
22
23.
빅데이터 기술을 이용한자연어 처리
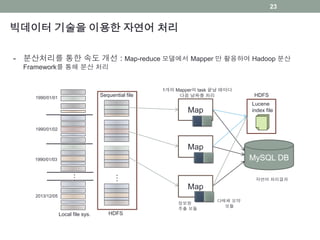
- 분산처리를 통한 속도 개선 : Map-reduce 모델에서 Mapper 만 활용하여 Hadoop 분산
Framework를 통해 분산 처리
… Map
Map
Map
MySQL DB
…
1990/01/01
1990/01/02
1990/01/03
2013/12/05
1개의 Mapper의 task 끝날 때마다
다음 날짜를 처리
정보원
추출 모듈
HDFSSequential file
Lucene
index file
다매체 요약
모듈
HDFSLocal file sys.
자연어 처리결과
23
24.
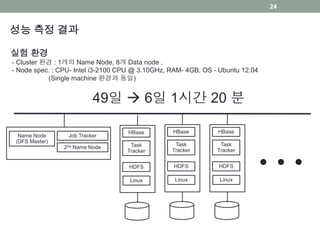
성능 측정 결과
실험환경
- Cluster 환경 : 1개의 Name Node, 8개 Data node ,
- Node spec. : CPU- Intel i3-2100 CPU @ 3.10GHz, RAM- 4GB, OS - Ubuntu 12.04
(Single machine 환경과 동일)
49일 6일 1시간 20 분
Name Node
(DFS Master)
Job Tracker
2nd Name Node
HBase
Task
Tracker
HDFS
Linux
HBase
Task
Tracker
HDFS
Linux
HBase
Task
Tracker
HDFS
Linux
24
25.
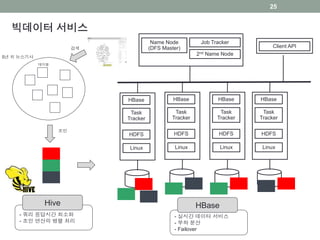
빅데이터 서비스
검색
조인
테이블
5년 치뉴스기사
- 쿼리 응답시간 최소화
- 조인 연산의 병렬 처리
Hive
- 실시간 데이터 서비스
- 부하 분산
- Failover
HBase
Name Node
(DFS Master)
Job Tracker
2nd Name Node
Client API
HBase
Task
Tracker
HDFS
Linux
HBase
Task
Tracker
HDFS
Linux
HBase
Task
Tracker
HDFS
Linux
HBase
Task
Tracker
HDFS
Linux
25
26.
26
26
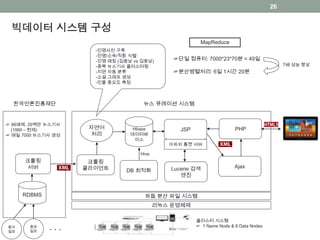
☞ 66매체, 29백만뉴스기사
(1990 – 현재)
☞ 매일 7000 뉴스기사 생성
크롤링
서버
크롤링
클라이언트
Hbase
데이터베
이스
자연어
처리
JSP
아파치 톰캣 서버
Lucene 검색
엔진
PHP
Ajax
한국언론진흥재단
하둡 분산 파일 시스템
리눅스 운영체제
DB 최적화
Hive
뉴스 큐레이션 시스템
RDBMS
동아
일보
중앙
일보
. . .
-인명사전 구축
-인명/소속/직함 식별
-인명 매칭 (김웅남 vs 김웅남)
-중복 뉴스기사 클러스터링
-지면 자동 분류
-소셜 그래프 생성
-인물 중요도 측정
☞단일 컴퓨터: 7000*23*70분 = 49일
☞분산병렬처리: 6일 1시간 20분
7배 성능 향상
클러스터 시스템
☞ 1 Name Node & 8 Data Nodes
빅데이터 시스템 구성
MapReduce
27.
News Source: Journalism가치에 기반한 뉴스 제공
• Journalism적인 가치: 사실성, 다양성, 심층성
• 목표: 뉴스를 정보원 간의 관계를 통해 분류, 정리
• 정보원 (News Source)
• 인용대상
• 기사 내용의 핵심 제공자 & 저널리즘 연구의 주요 주제
• 뉴스 정보원 연결망
• 언론에서 중시되는 인물의 중요도를 소셜그래프의 중요도 척도로 추정
• 같은 정보원이 있는 뉴스를 클러스터링 중복기사를 사건별로 정리
• 뉴스 소스 (News Source) – 새로운 뉴스제공 웹 어플리케이션
• 뉴스 기사들을 뉴스기사 내의 사실을 중심으로 요약해서 제공 함
• 중요한 순서대로 기사를 배열
• 의미 관계를 파악하게 도와주는 스마트 뉴스 서비스
• 인물 중심의 시각화(visualization)을 통한 사건의 새로운 측면 확인
• 한 기사에 대한 분야별 시각을 쉽게 확인할 수 있다
• 타겟 유저: 뉴스 중 이용자(heavy user)
• 기자, 언론학자, 정치인, 법률가, 컨설턴트, 대학생 등을 위한 서비스
• 뉴스를 쟁점 중심으로 심층적으로 분석하기 위한 사람을 위한 서비스
자연어 처리
대용량 데이
터
정보 시각화
27


![Journalism적인 가치
• 사실성, 다양성, 심층성
• 사실성을 드러내는 관례
• 인용, 수치, 사례 등 [van Dijk 1988]
• 정보원 (News Source)
• 인용대상
• 기사 내용의 핵심 제공자
• 저널리즘 연구의 주요 주제
• [Sigal 1973], [Schudson 1978], & [Gans 1979]
5](https://image.slidesharecdn.com/3-150420213453-conversion-gate01/85/slide-5-320.jpg)






























































![[UDIS_6_2nd] Data Journalism_20140712](https://cdn.slidesharecdn.com/ss_thumbnails/udis62datajournalism20140712-140712215647-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[뉴스젤리] 무엇이 뉴스인가](https://cdn.slidesharecdn.com/ss_thumbnails/random-131230034213-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
