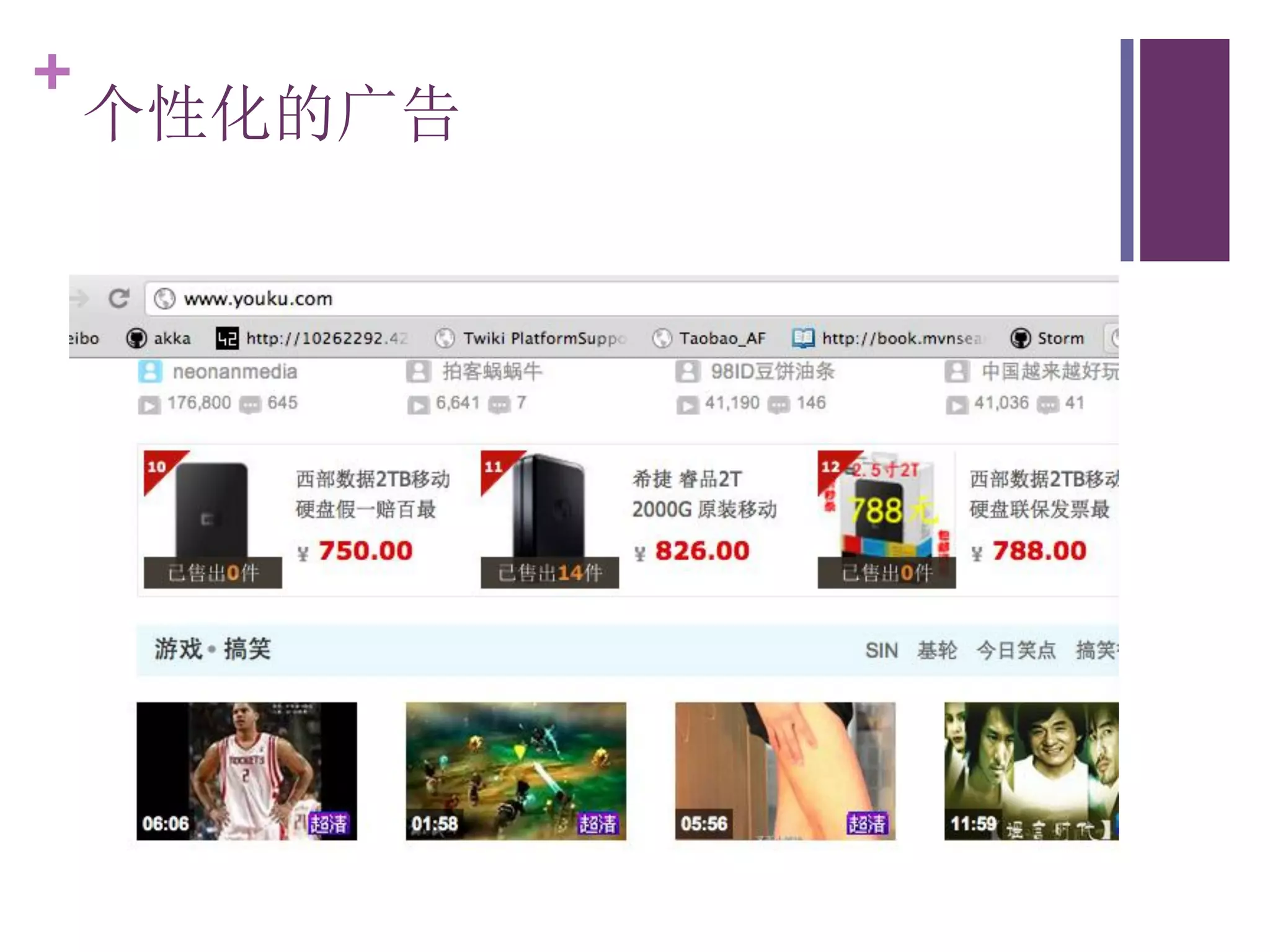
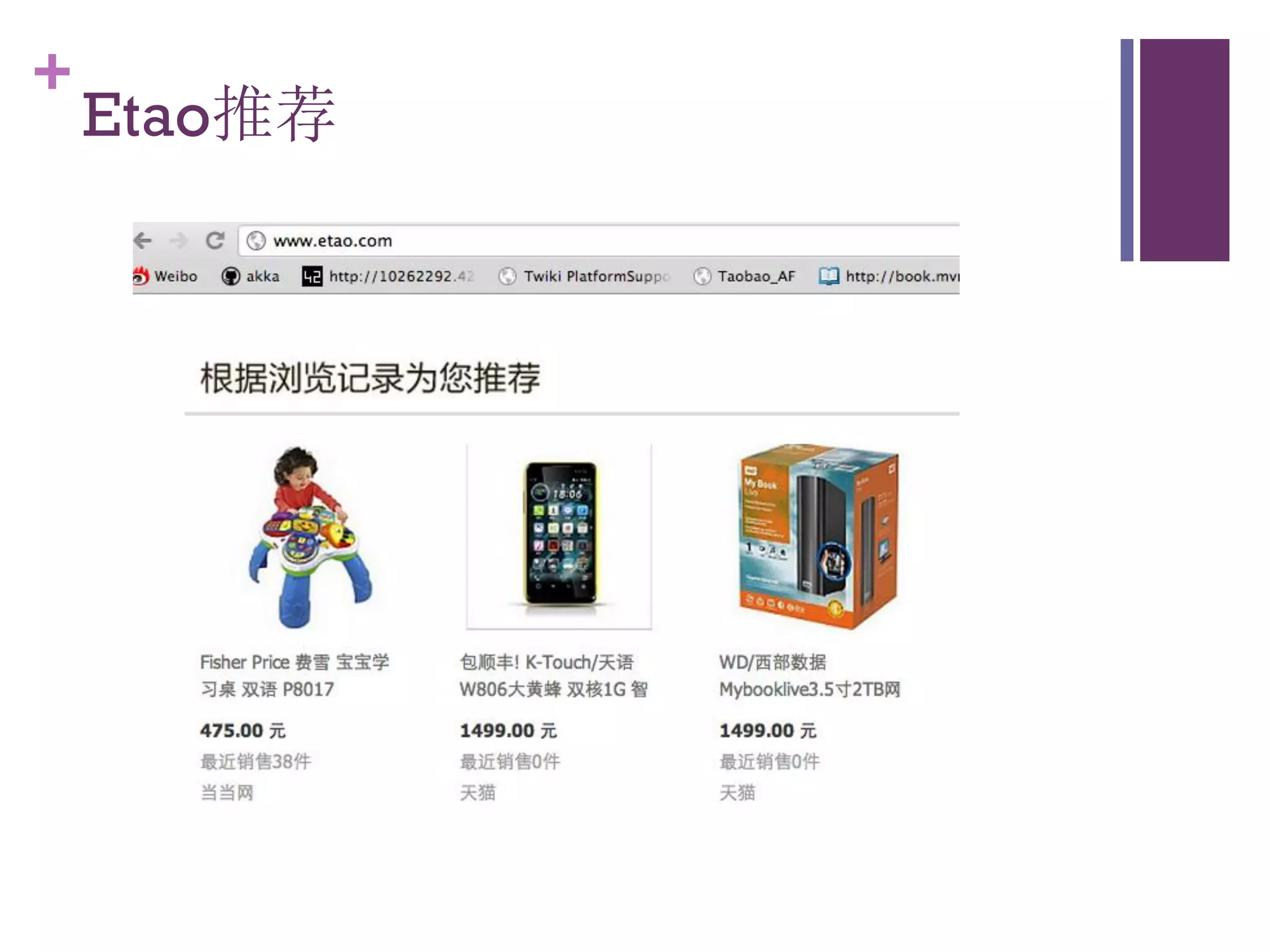
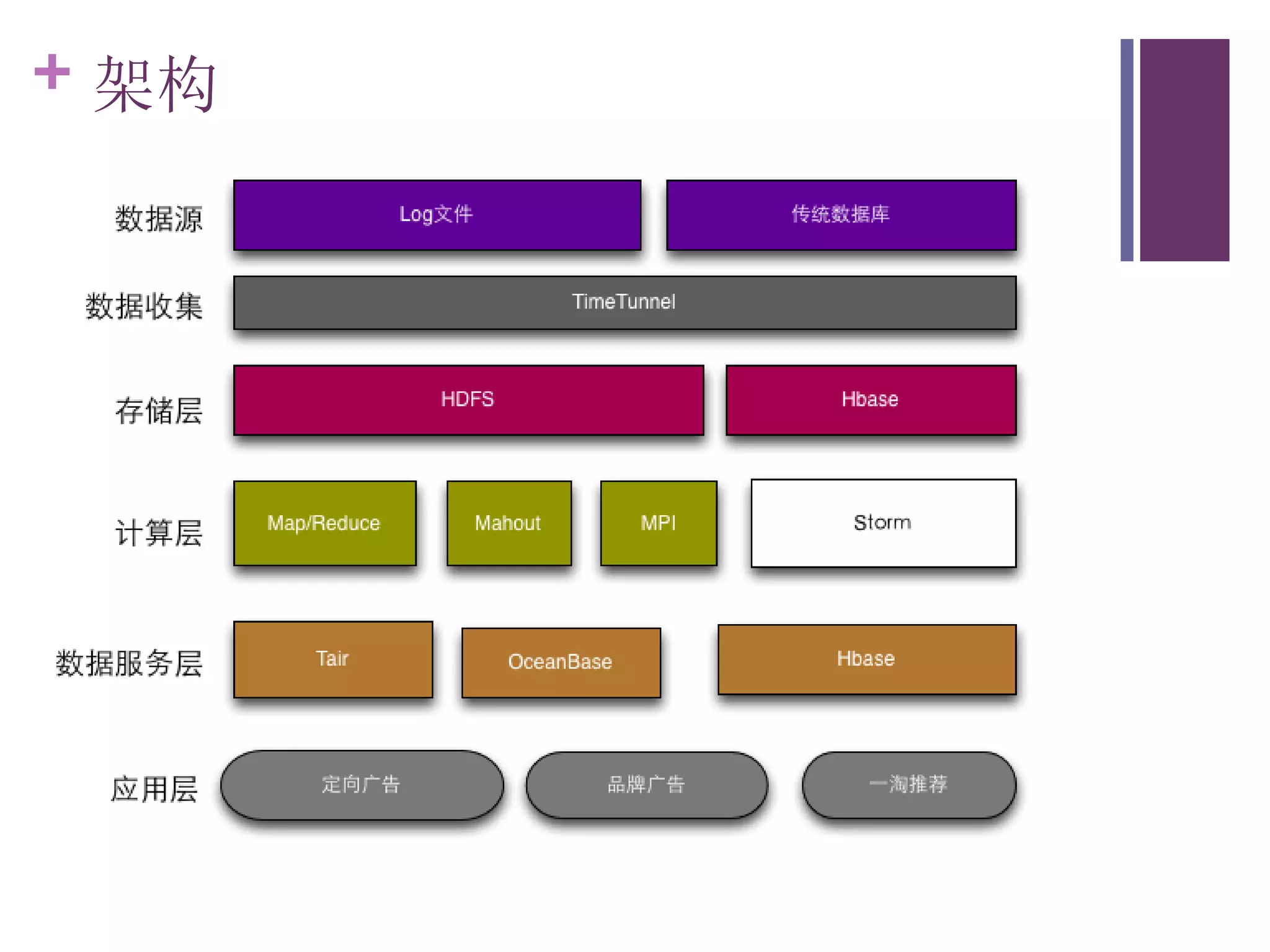
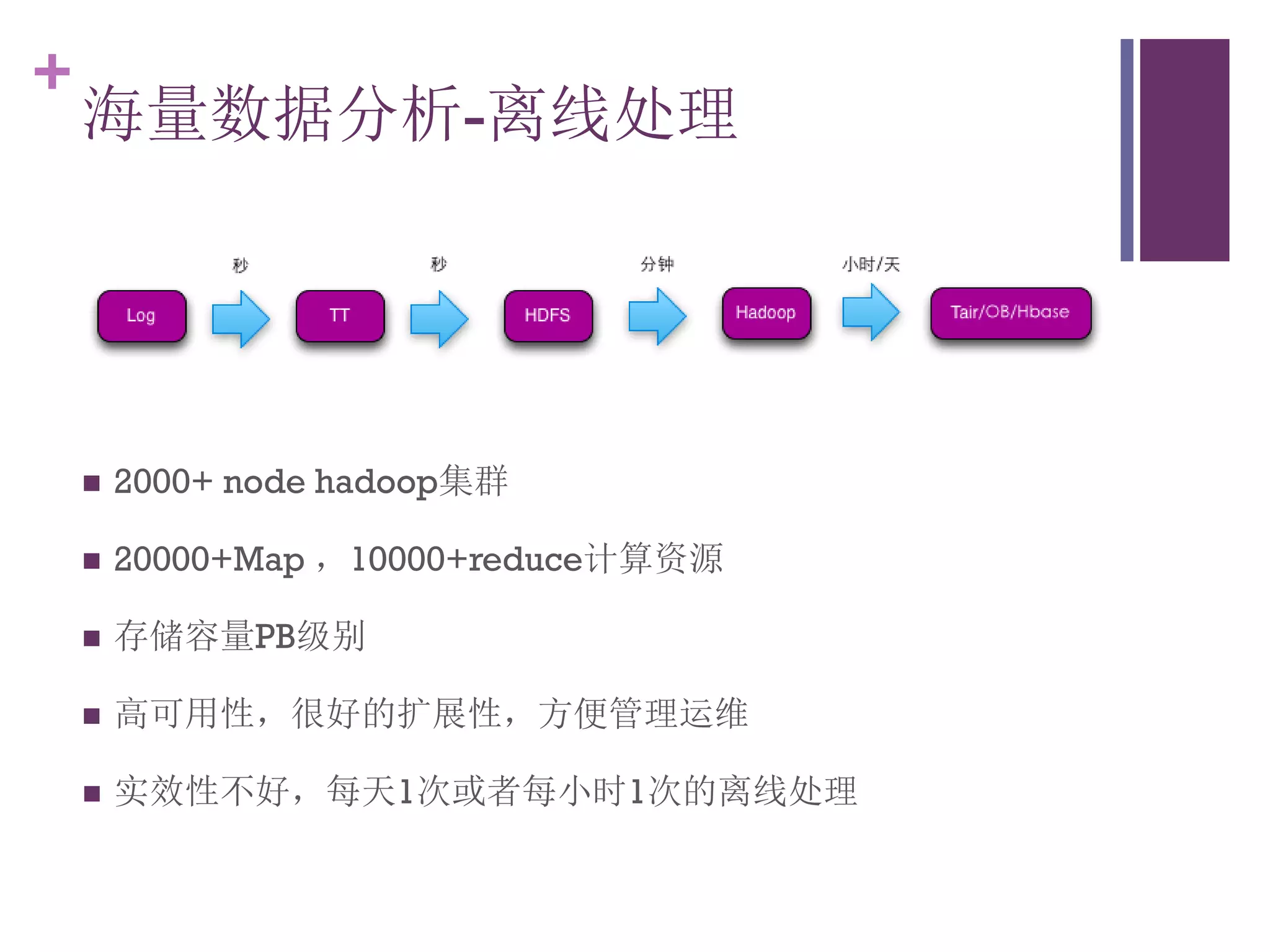
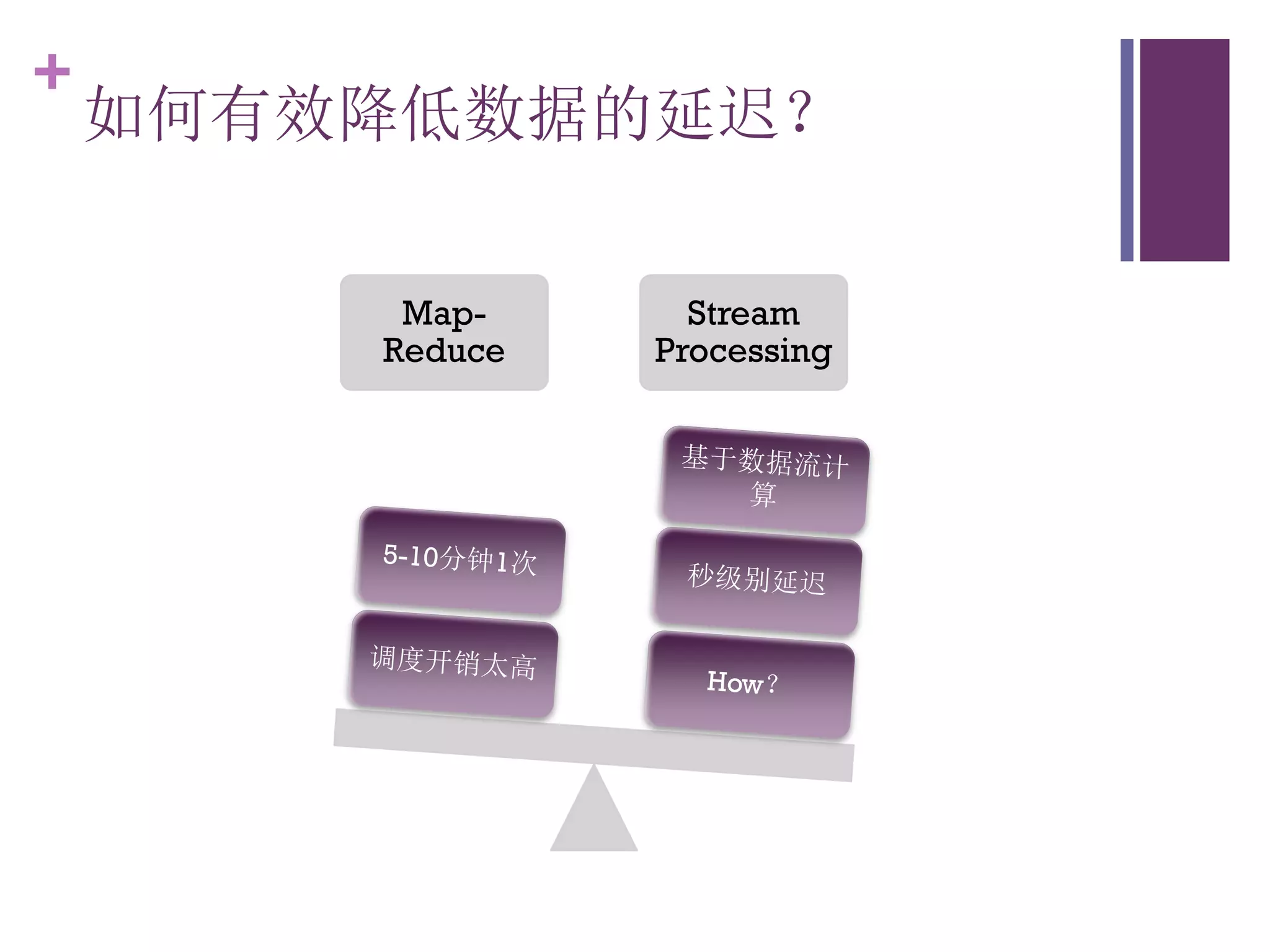
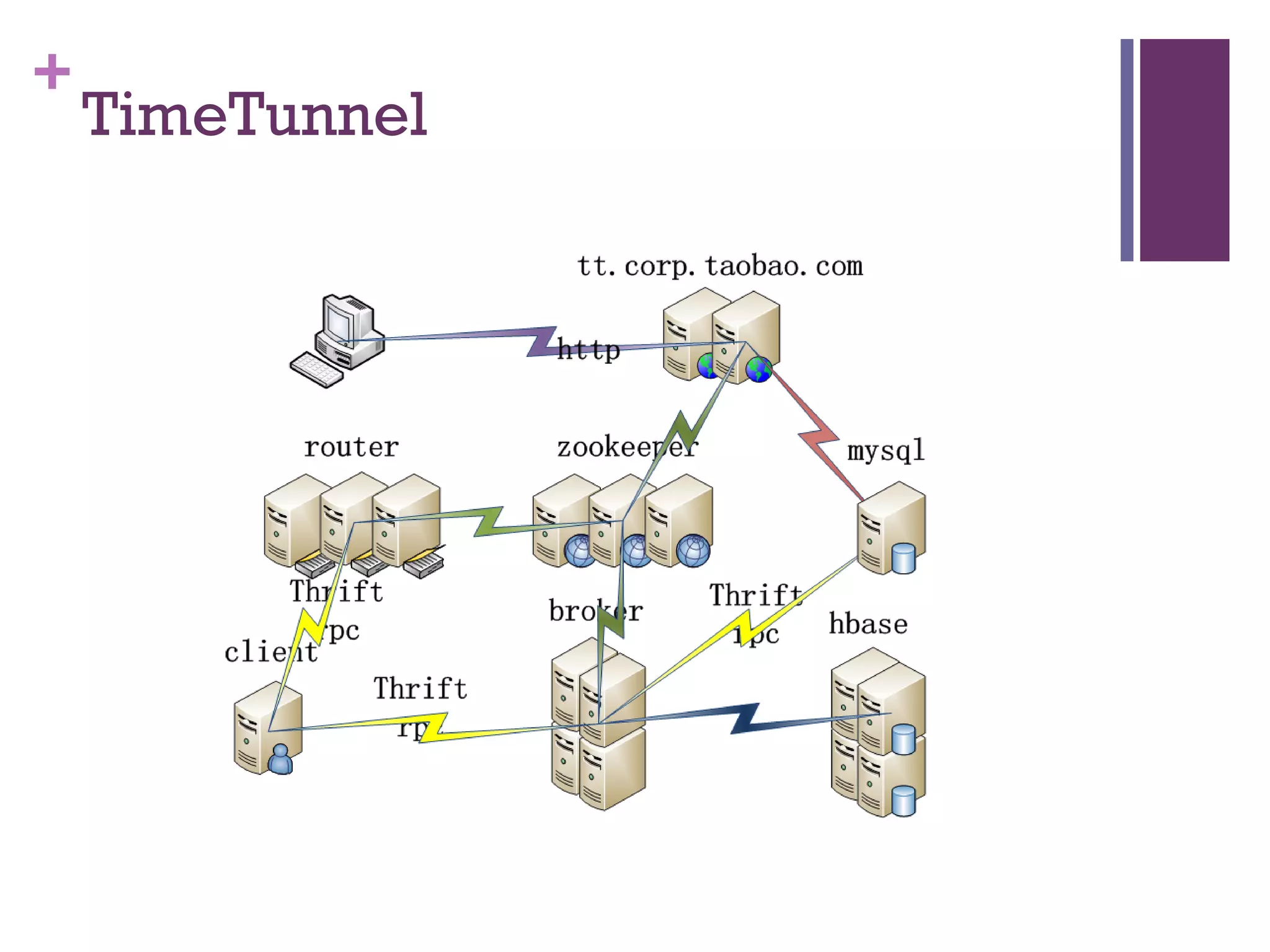
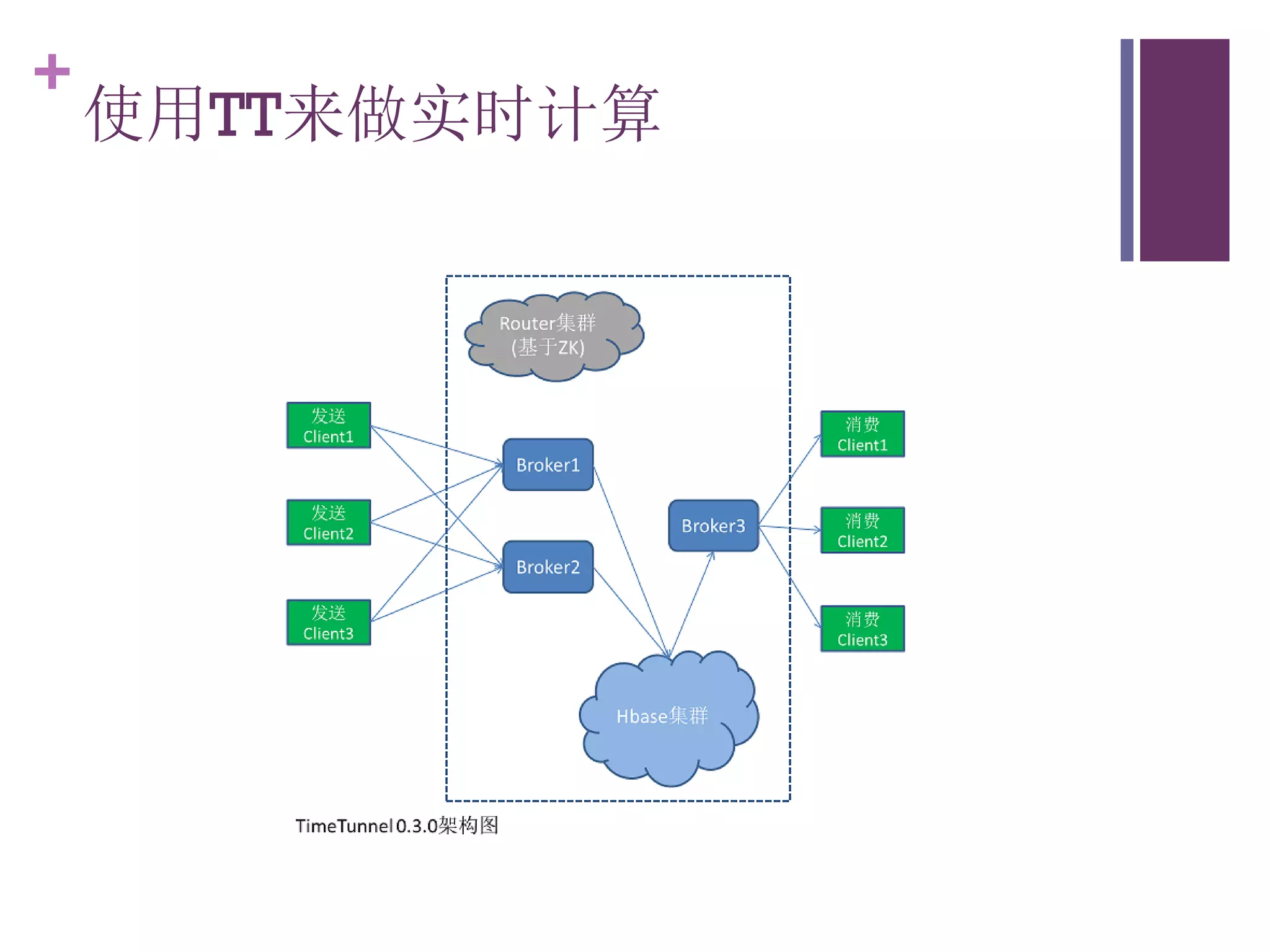
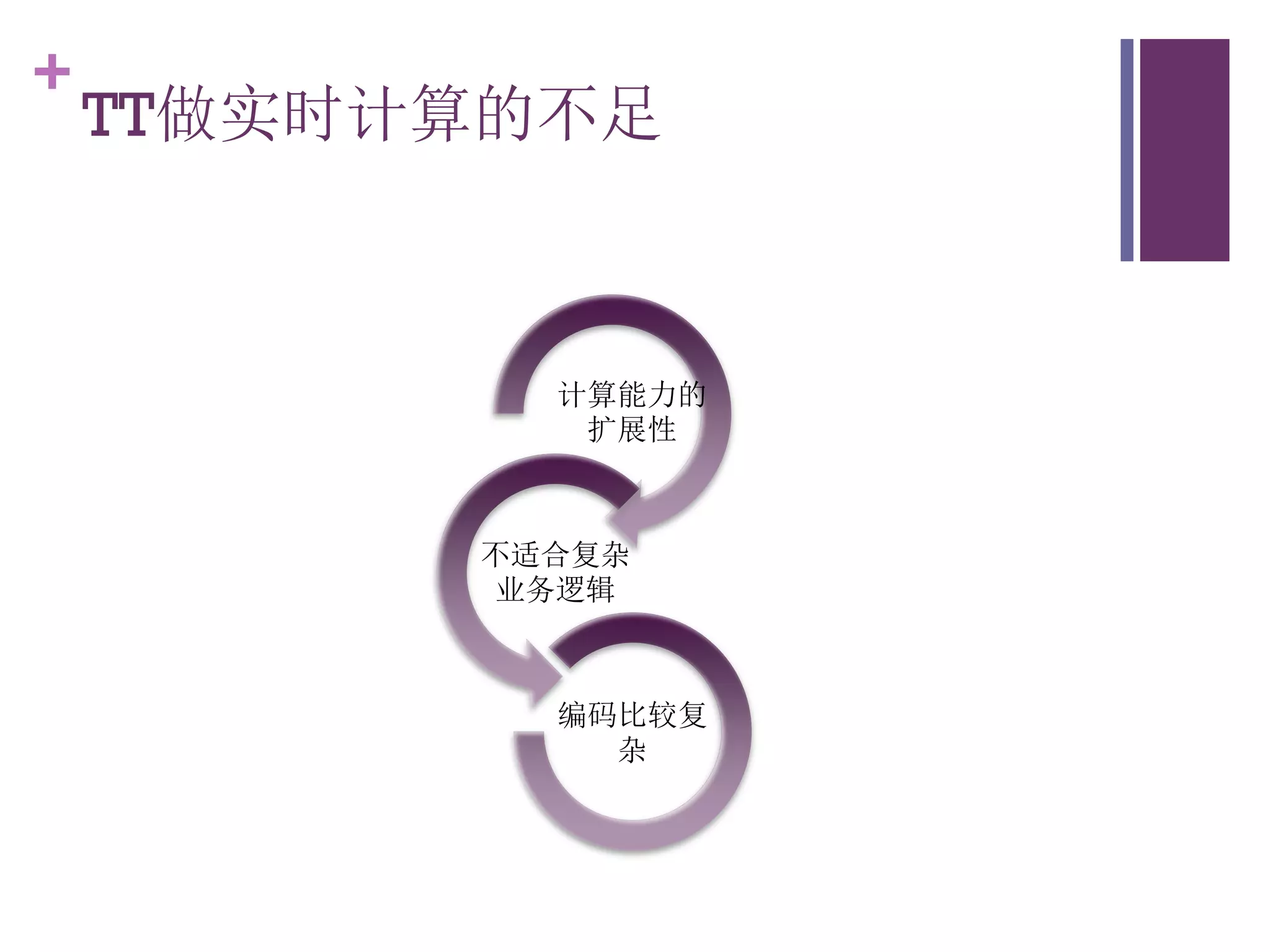
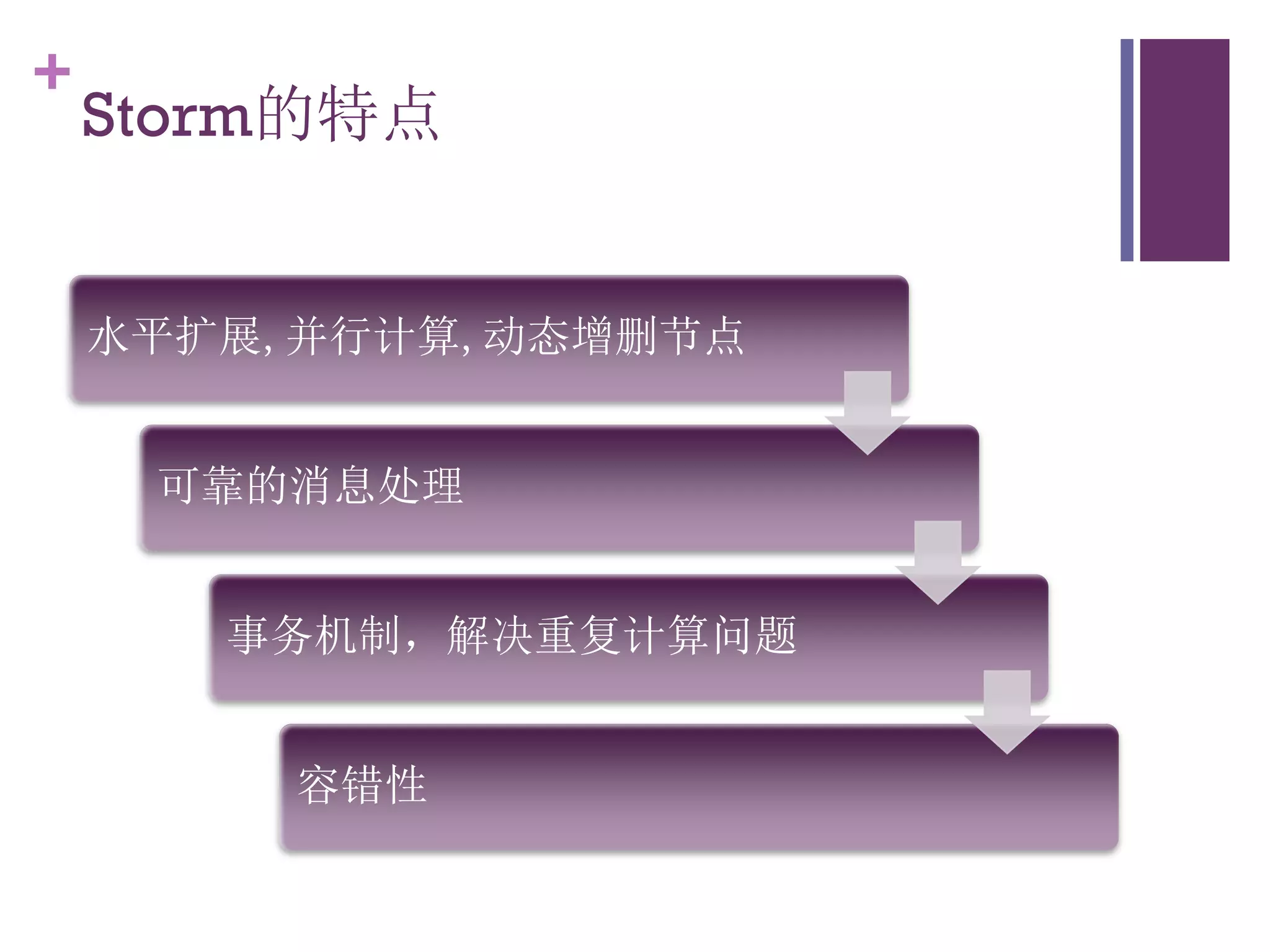
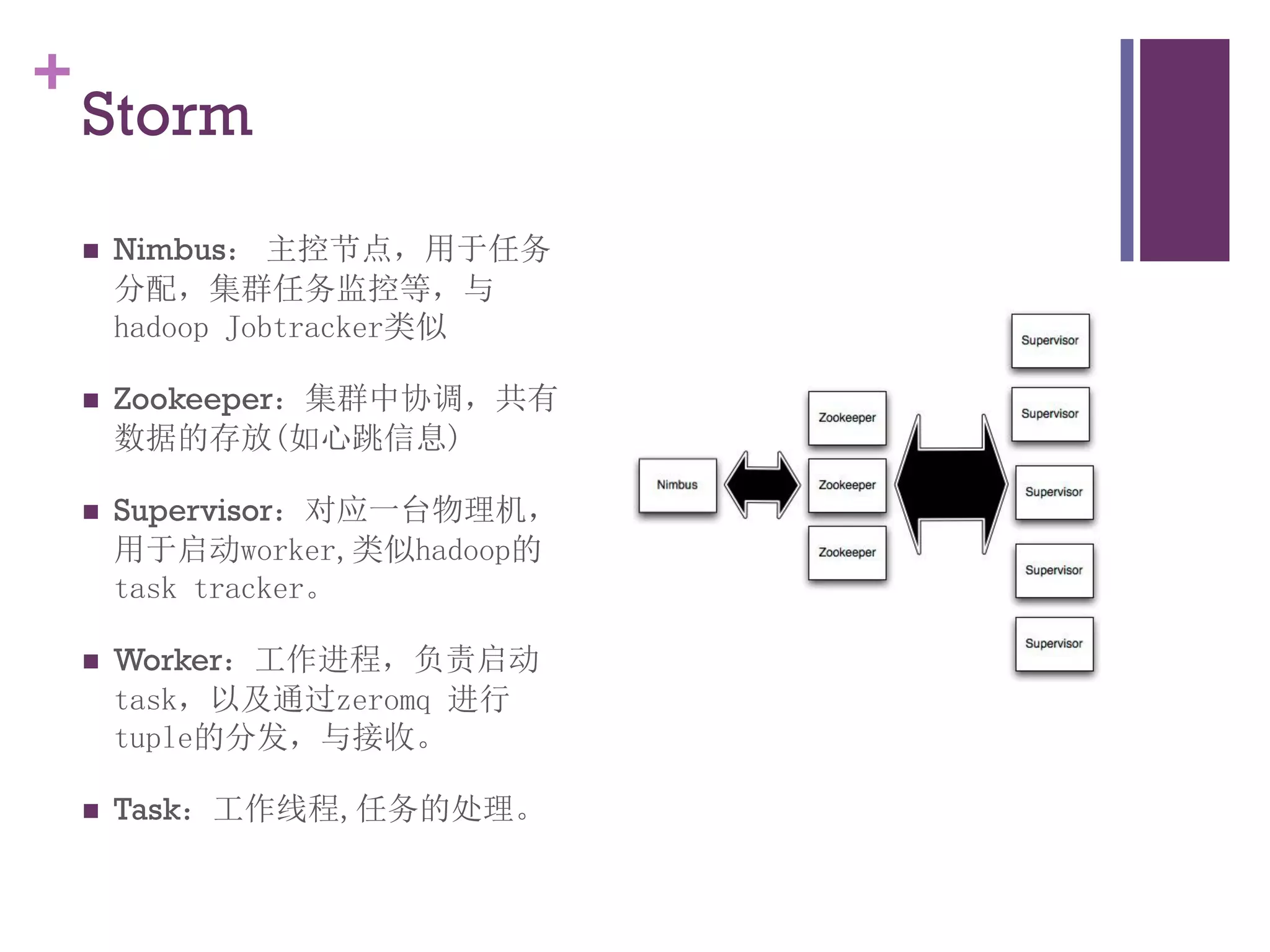
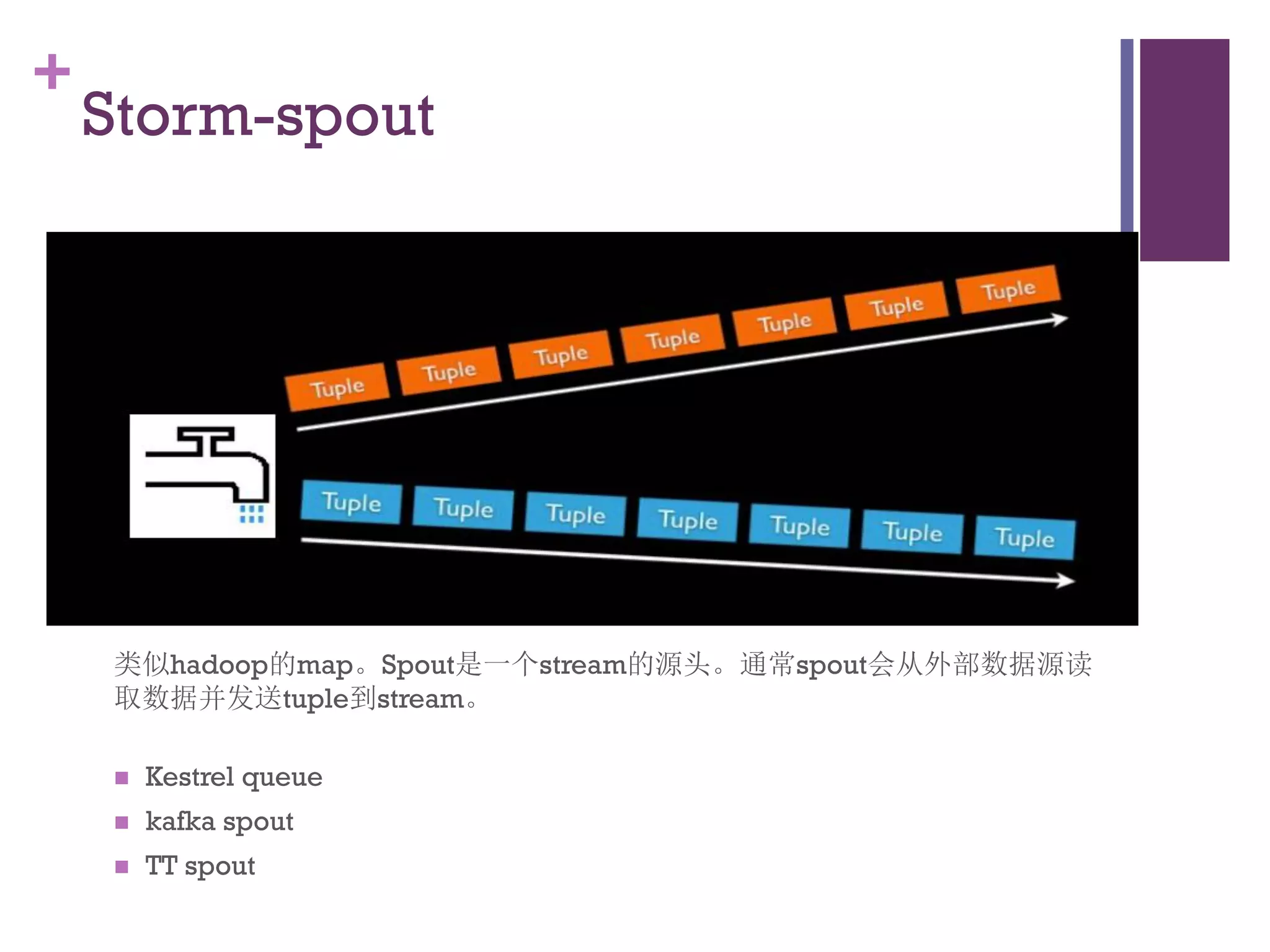
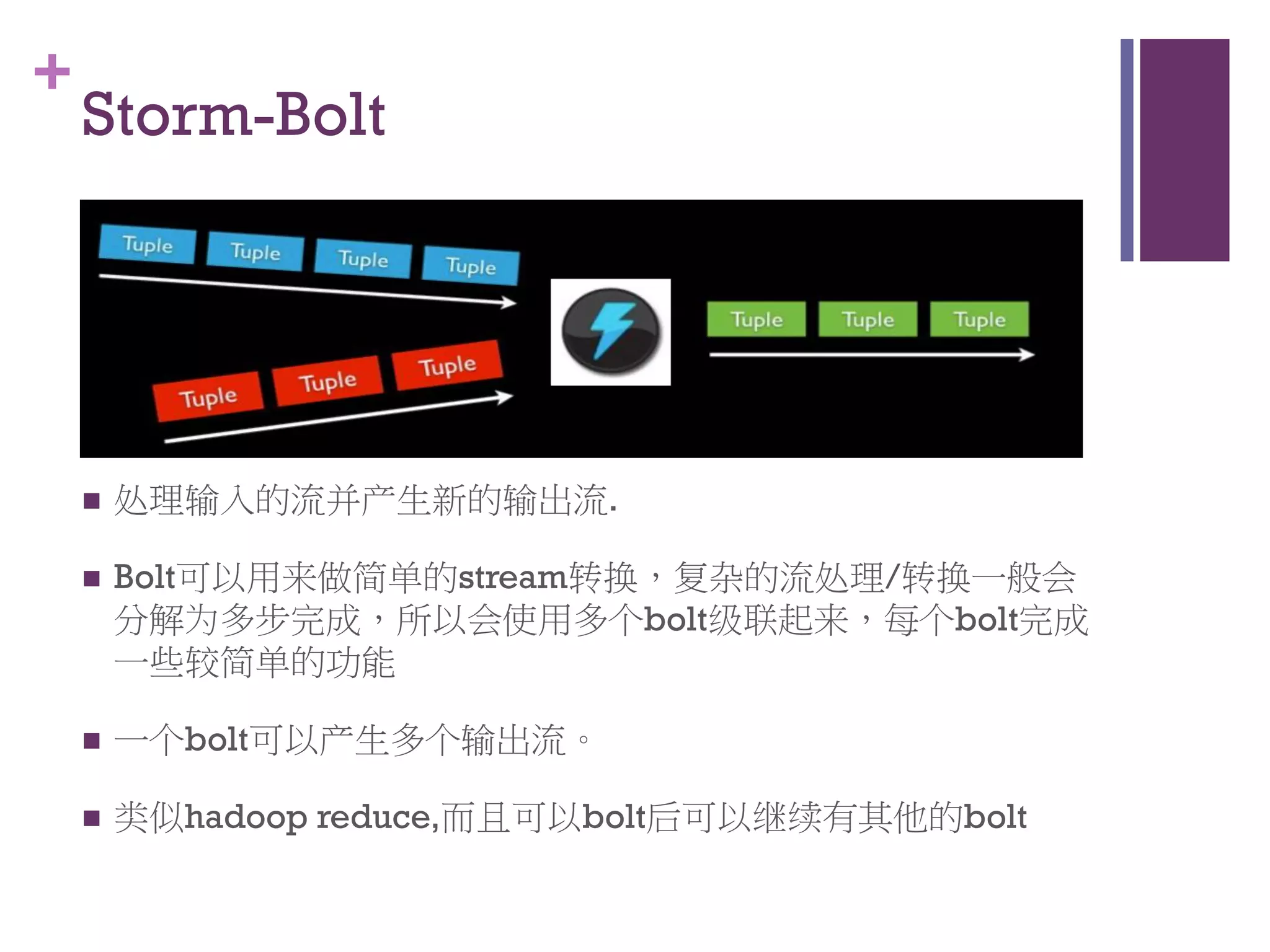
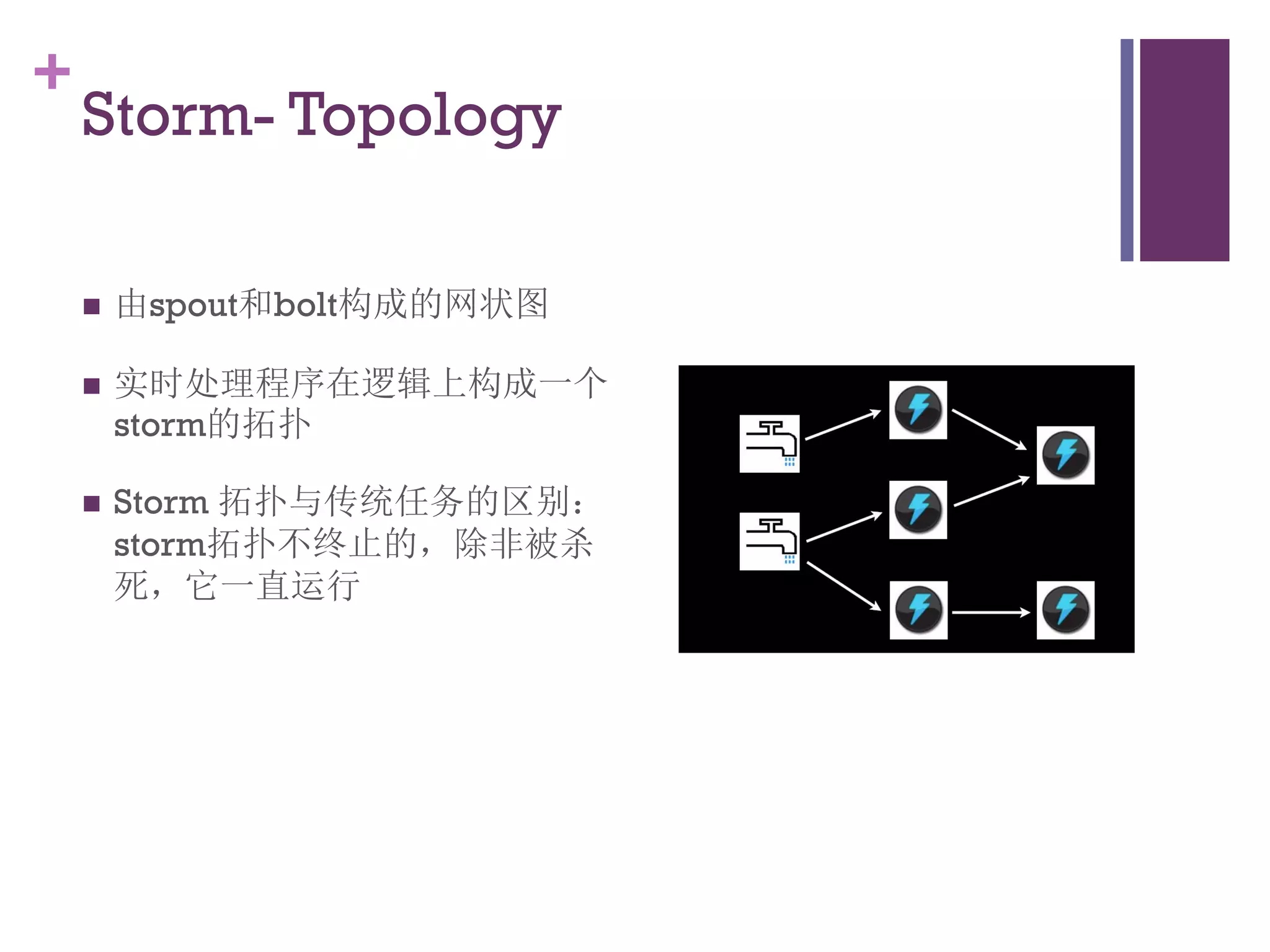
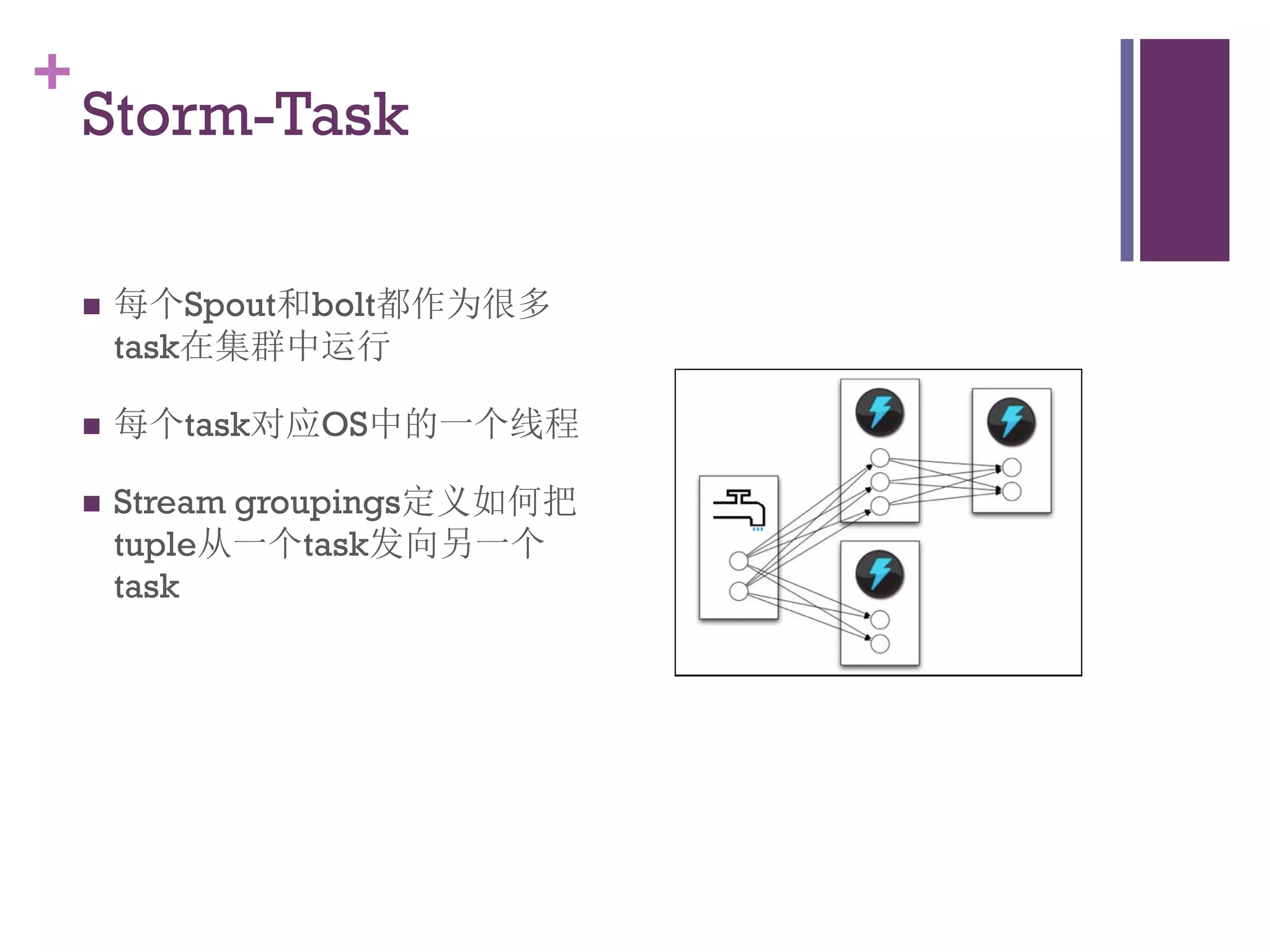
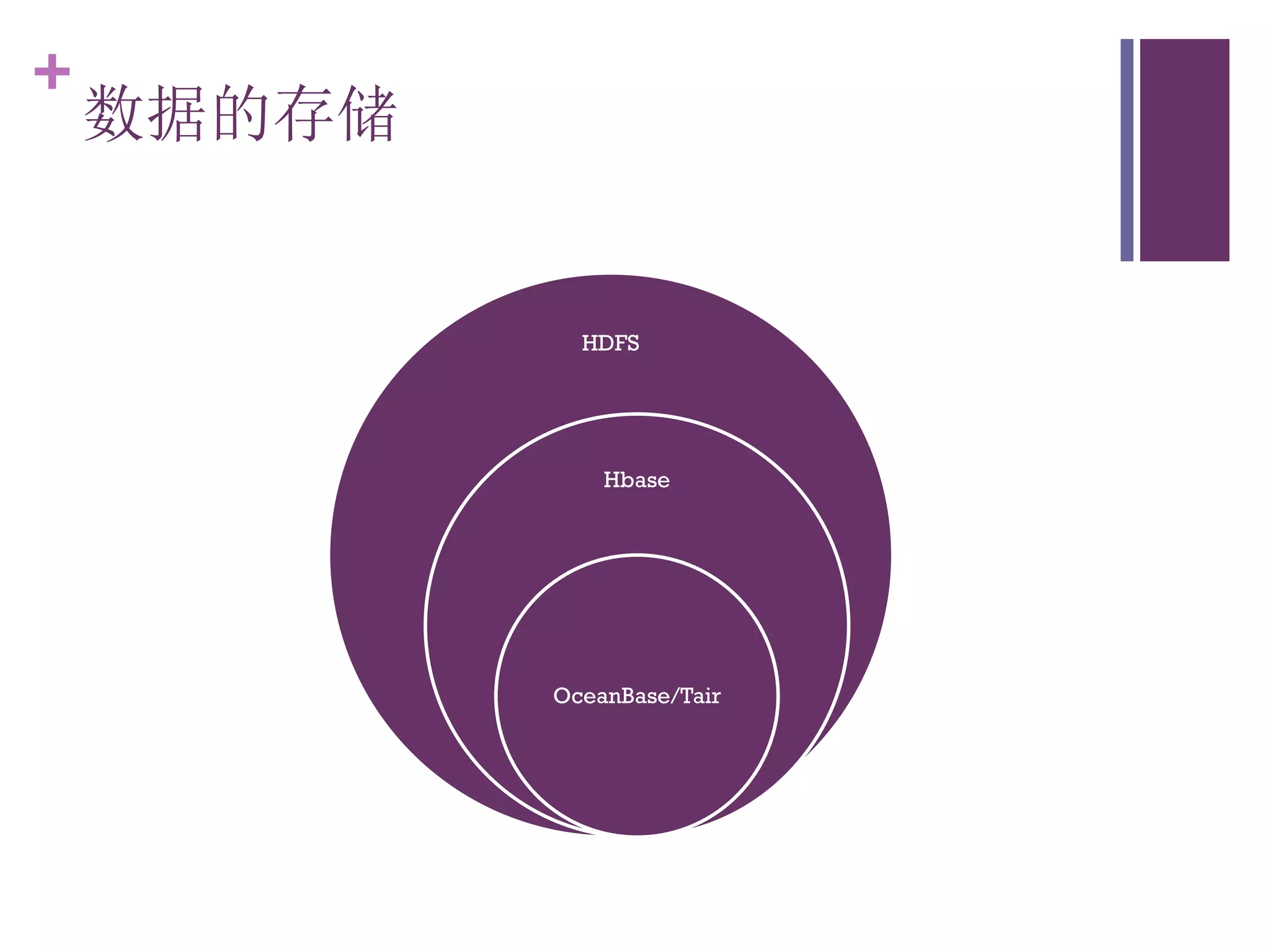
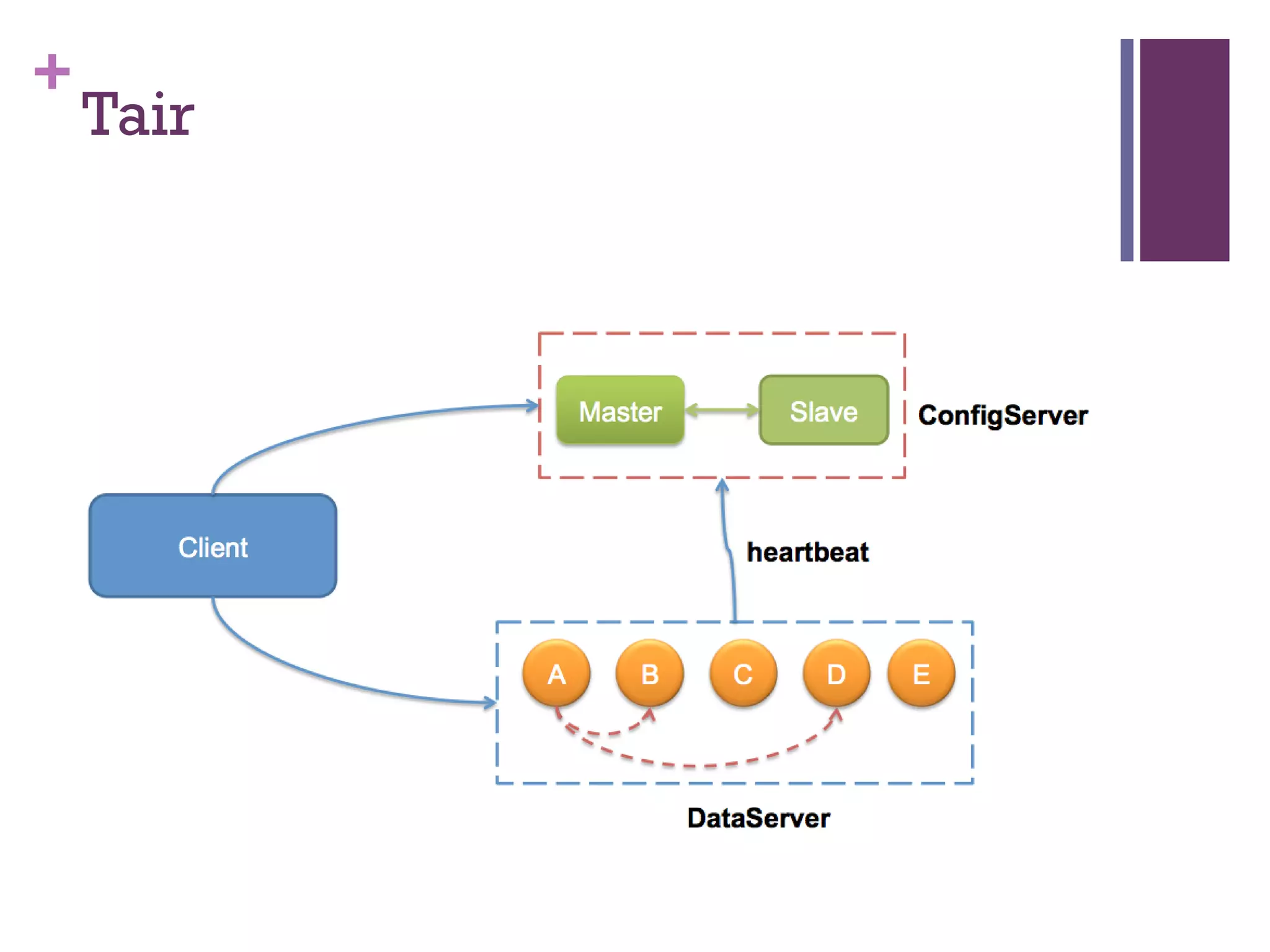
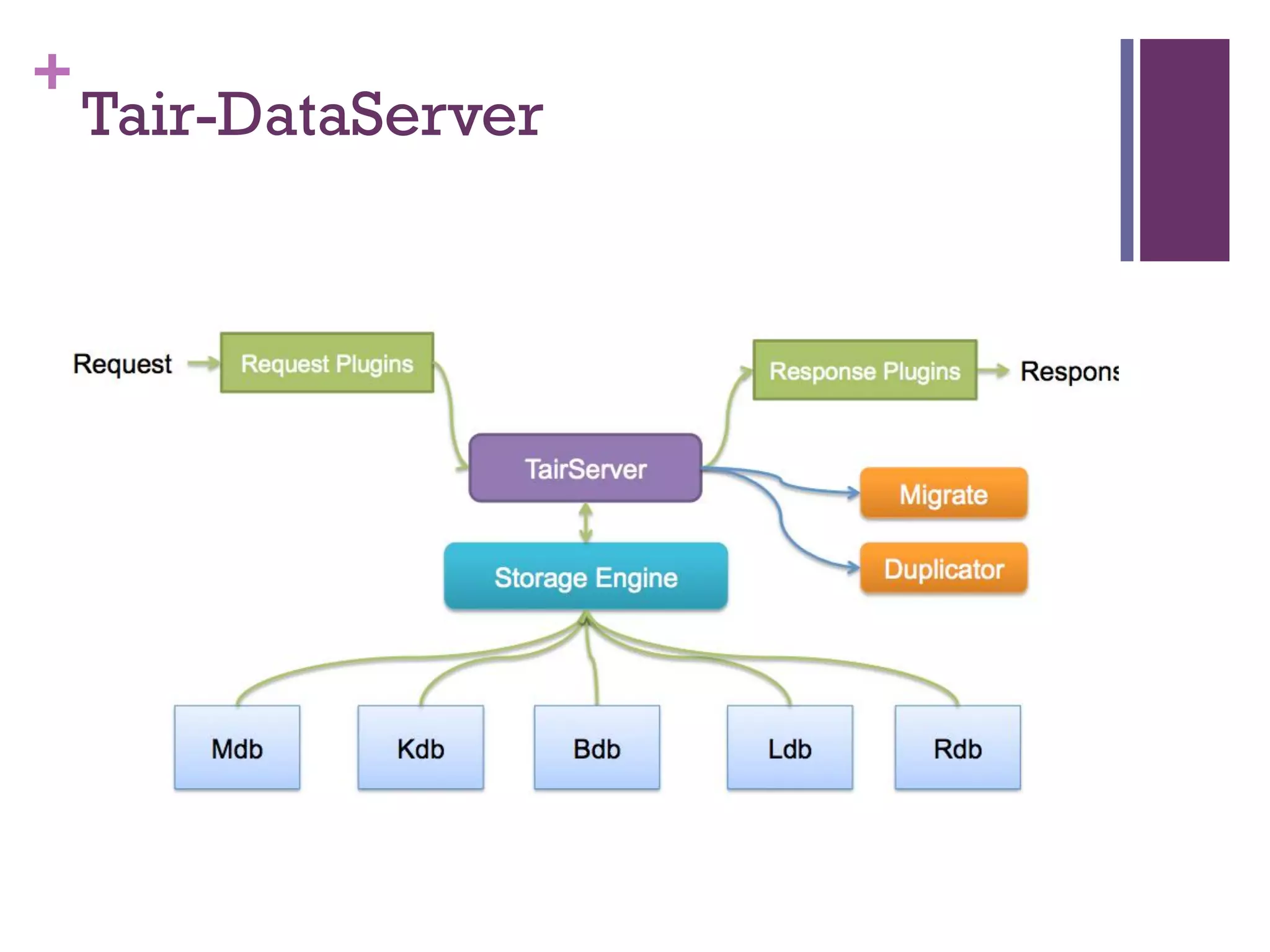
该文档探讨了海量用户数据处理在一淘广告和推荐中的应用,以及相关的技术架构和挑战。重点提到了实时计算框架Timetunnel和Storm的特点与功能,以及如何处理高并发数据和提高处理效率。文档还介绍了基于Hadoop和其他分布式技术的离线和实时数据分析方法。