Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Co-graph Inc.
PDF, PPTX
3,760 views
[コグラフ]spss modelerによるデータ加工入門
本スライドは、SPSS Modelerに興味を持った人/使い始めた人のために、SPSS Modelerを使ったデータ加工の進め方を解説した資料です。
Data & Analytics
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 23
2
/ 23
3
/ 23
4
/ 23
5
/ 23
6
/ 23
7
/ 23
8
/ 23
9
/ 23
10
/ 23
11
/ 23
12
/ 23
13
/ 23
14
/ 23
15
/ 23
16
/ 23
17
/ 23
18
/ 23
19
/ 23
20
/ 23
21
/ 23
22
/ 23
23
/ 23
More Related Content
PDF
趣味と仕事の違い、現場で求められるアプリケーションの可観測性
by
LIFULL Co., Ltd.
PDF
systemdを始めよう
by
Preferred Networks
PDF
データベース技術の羅針盤
by
Yoshinori Matsunobu
PPT
Lessons Learnt from Building Bubblino (a Thing on the Internet)
by
Adrian McEwen
PDF
Elasticsearch勉強会#39 LT 20201217
by
Tetsuya Sodo
PDF
エクストリーム ネットワークス レイヤ2/3スイッチ基本設定ガイド
by
エクストリーム ネットワークス / Extreme Networks Japan
PPT
547.02 intro to eeg
by
fizyoloji12345
PPT
Emg fundamental
by
Sherwan Omer
趣味と仕事の違い、現場で求められるアプリケーションの可観測性
by
LIFULL Co., Ltd.
systemdを始めよう
by
Preferred Networks
データベース技術の羅針盤
by
Yoshinori Matsunobu
Lessons Learnt from Building Bubblino (a Thing on the Internet)
by
Adrian McEwen
Elasticsearch勉強会#39 LT 20201217
by
Tetsuya Sodo
エクストリーム ネットワークス レイヤ2/3スイッチ基本設定ガイド
by
エクストリーム ネットワークス / Extreme Networks Japan
547.02 intro to eeg
by
fizyoloji12345
Emg fundamental
by
Sherwan Omer
More from Co-graph Inc.
PPTX
ITベンチャー社長が語る!《新時代の採用戦略!》
by
Co-graph Inc.
PDF
MongoDB + XSD/XML
by
Co-graph Inc.
PPTX
Hadoop cluster setup by using cloudera manager
by
Co-graph Inc.
PPTX
Watch Your Log!
by
Co-graph Inc.
PDF
業務システムにおけるMongoDB活用法
by
Co-graph Inc.
PPTX
HAL東京インターン生業務成果プレゼン
by
Co-graph Inc.
ITベンチャー社長が語る!《新時代の採用戦略!》
by
Co-graph Inc.
MongoDB + XSD/XML
by
Co-graph Inc.
Hadoop cluster setup by using cloudera manager
by
Co-graph Inc.
Watch Your Log!
by
Co-graph Inc.
業務システムにおけるMongoDB活用法
by
Co-graph Inc.
HAL東京インターン生業務成果プレゼン
by
Co-graph Inc.
[コグラフ]spss modelerによるデータ加工入門
1.
SPSS Modelerによる データ加工入門 Co-graph Inc. Takahashi
Masaki
2.
Co-graph confidential 2 本スライドは、SPSS
Modelerに興味を持った 人/使い始めた人のために、SPSS Modelerを 使ったデータ加工の進め方を解説した資料です。 IBM(R) SPSS Modeler(以下、Modeler)の独自形式の ファイルのことをストリームファイルと言います。 本スライドで使用しているサンプルデータと ストリームファイルは、「コグラフ公式テクニカルWeb」から ダウンロードできます。 http://www.co-graph.net/ 「コグラフ公式テクニカルWeb」には、本スライドに 記載しきれなかった情報もたくさんありますので是非ご覧ください。 IBM、IBM ロゴ、ibm.com、SPSSは、世界の多くの国で 登録されたInternational Business Machines Corp.の商標です。
3.
Co-graph confidential 3 SPSS
Modelerとは? そもそも…
4.
Co-graph confidential 4 ・データの加工と分析をするソフトです。 ・データマイニングに必要な機能は ほぼ揃っています。 ・データ加工がしやすいです。 ・本格的なわりに、習得のハードルが低いので 大企業を中心に世界中で使われています。
5.
Co-graph confidential 5 ではさっそく… CSVデータの取り込みと内容表示 についてご説明します
6.
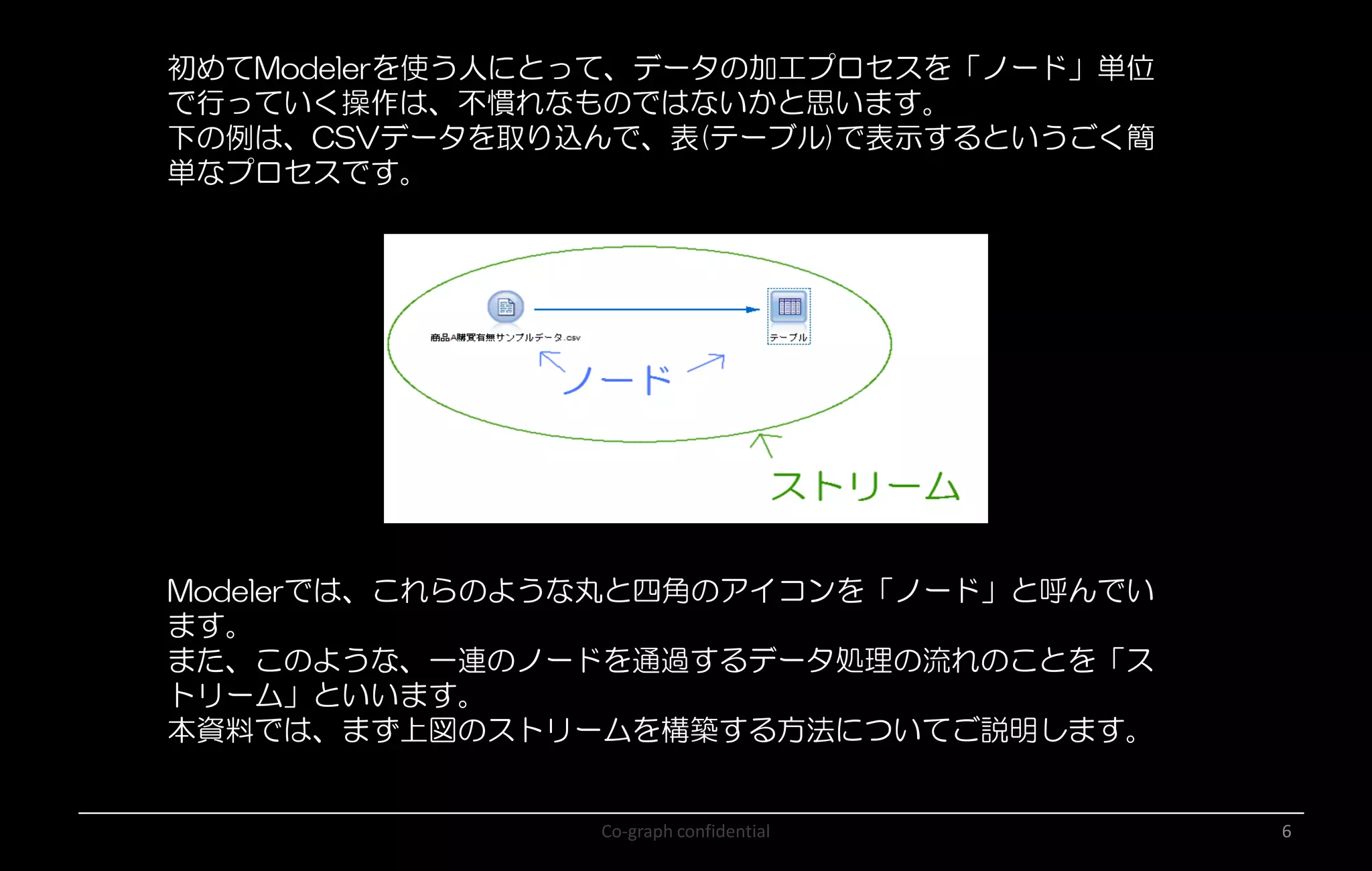
Co-graph confidential 6 初めてModelerを使う人にとって、データの加工プロセスを「ノード」単位 で行っていく操作は、不慣れなものではないかと思います。 下の例は、CSVデータを取り込んで、表(テーブル)で表示するというごく簡 単なプロセスです。 Modelerでは、これらのような丸と四角のアイコンを「ノード」と呼んでい ます。 また、このような、一連のノードを通過するデータ処理の流れのことを「ス トリーム」といいます。 本資料では、まず上図のストリームを構築する方法についてご説明します。
7.
Co-graph confidential 7 とりあえず… CSVファイルを取り込んでみましょう
8.
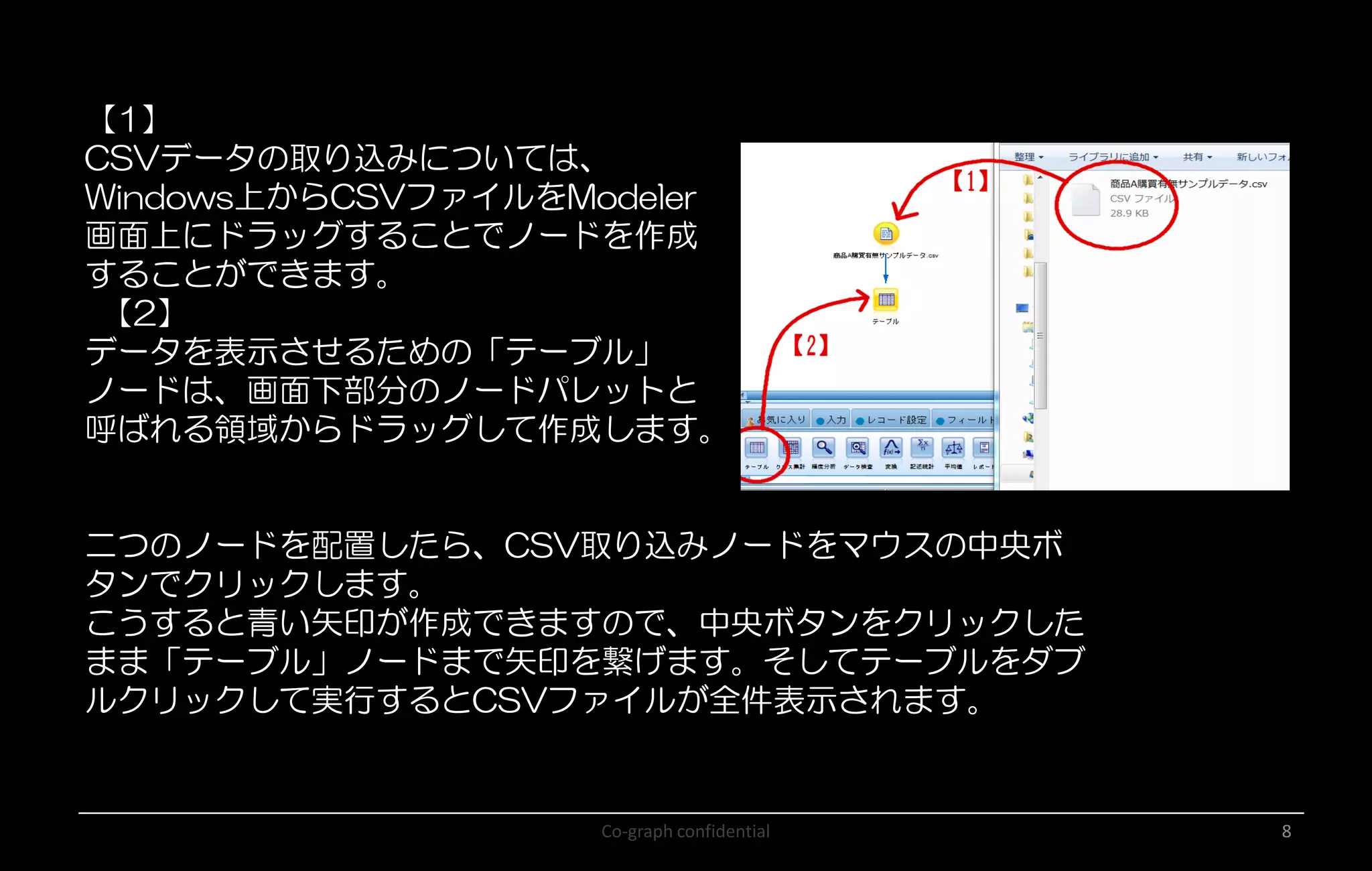
Co-graph confidential 8 【1】 CSVデータの取り込みについては、 Windows上からCSVファイルをModeler 画面上にドラッグすることでノードを作成 することができます。 【2】 データを表示させるための「テーブル」 ノードは、画面下部分のノードパレットと 呼ばれる領域からドラッグして作成します。 二つのノードを配置したら、CSV取り込みノードをマウスの中央ボ タンでクリックします。 こうすると青い矢印が作成できますので、中央ボタンをクリックした まま「テーブル」ノードまで矢印を繋げます。そしてテーブルをダブ ルクリックして実行するとCSVファイルが全件表示されます。
9.
Co-graph confidential 9 ここまでで、CSVファイルを取り込んで表示させるだけ のシンプルなストリームを作成することができました。 次に、ノードの設定方法についてご説明します。
10.
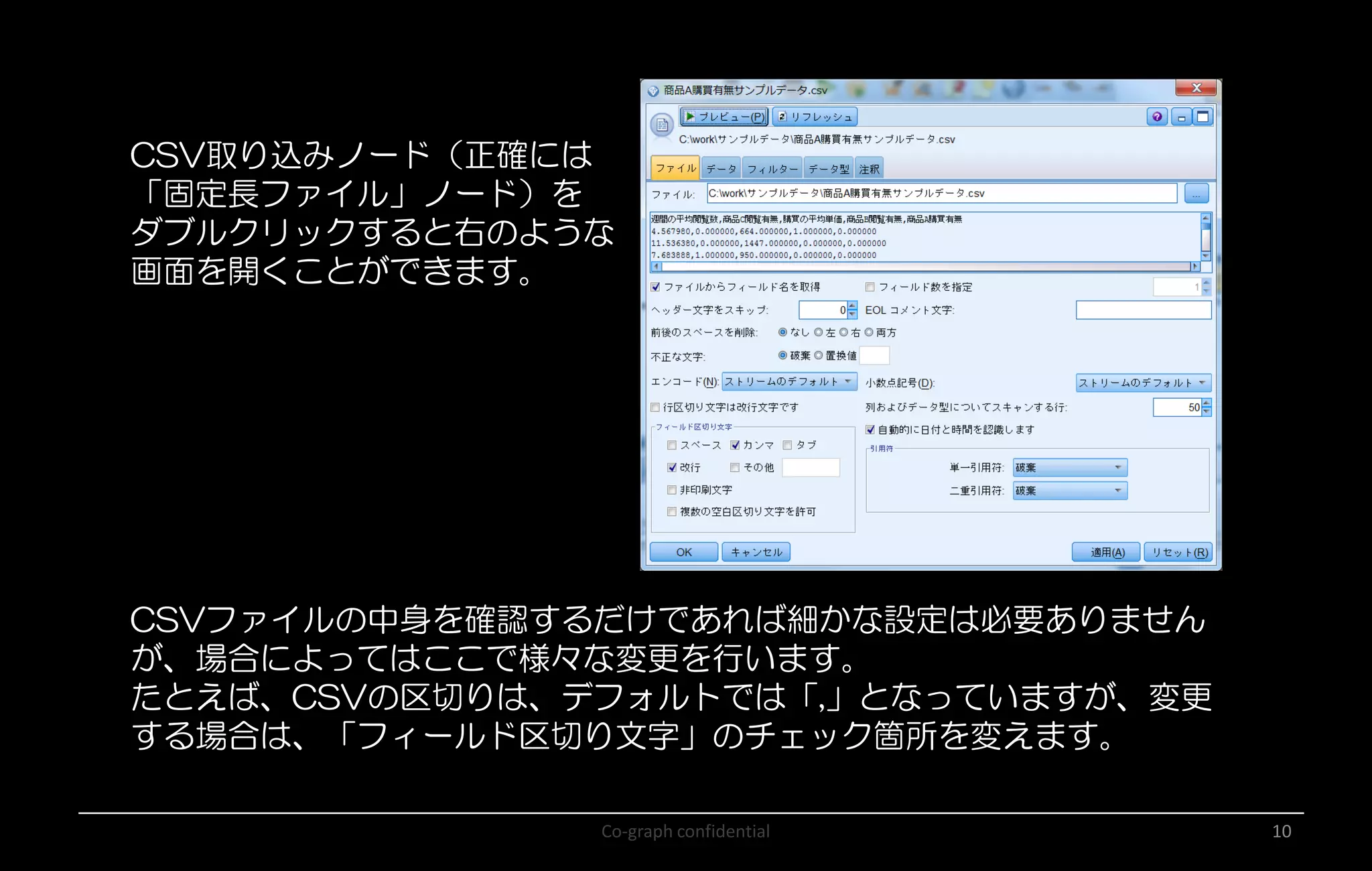
Co-graph confidential 10 CSV取り込みノード(正確には 「固定長ファイル」ノード)を ダブルクリックすると右のような 画面を開くことができます。 CSVファイルの中身を確認するだけであれば細かな設定は必要ありません が、場合によってはここで様々な変更を行います。 たとえば、CSVの区切りは、デフォルトでは「,」となっていますが、変更 する場合は、「フィールド区切り文字」のチェック箇所を変えます。
11.
Co-graph confidential 11 次は… 簡単な集計をしてみましょう
12.
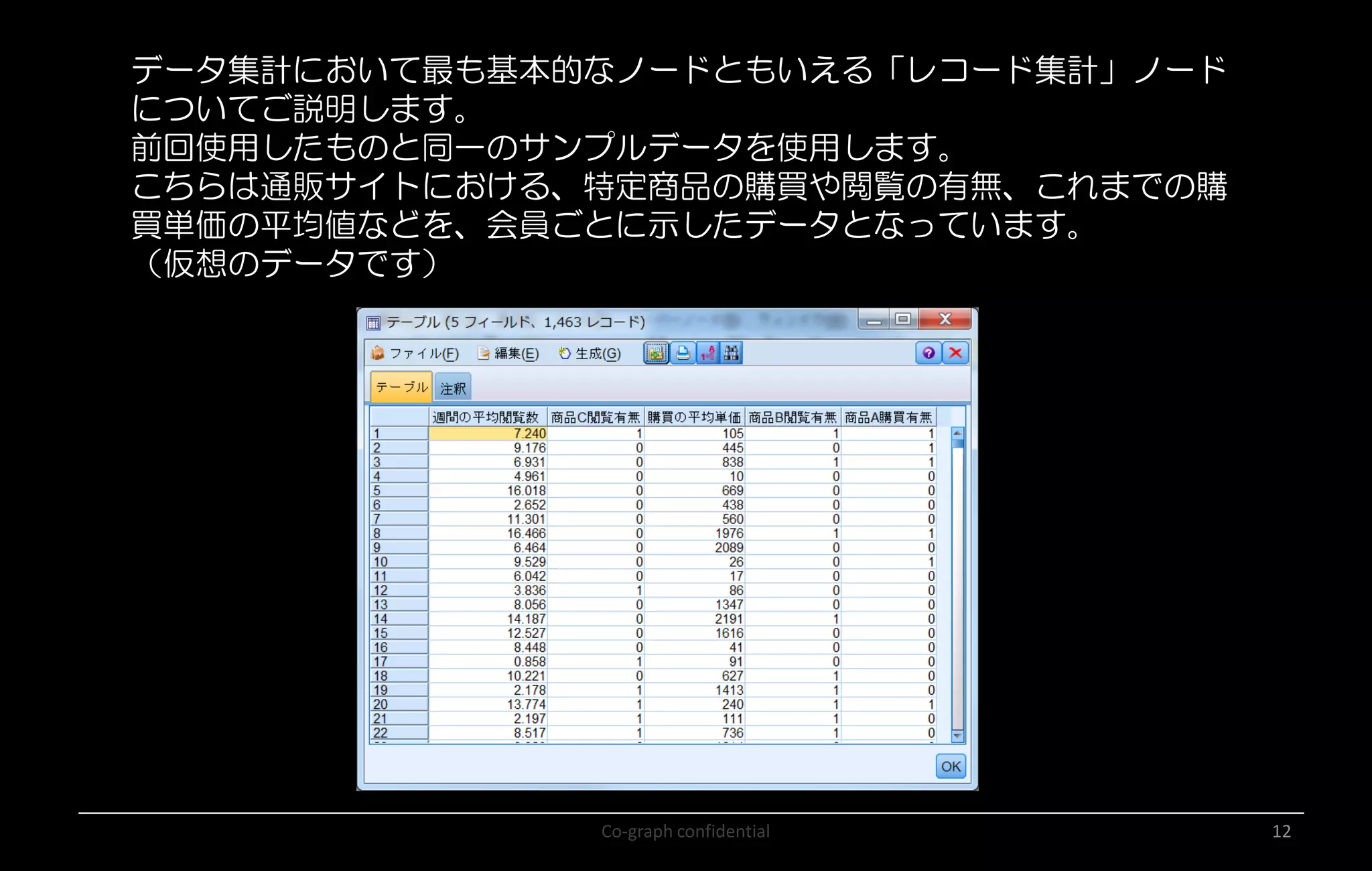
Co-graph confidential 12 データ集計において最も基本的なノードともいえる「レコード集計」ノード についてご説明します。 前回使用したものと同一のサンプルデータを使用します。 こちらは通販サイトにおける、特定商品の購買や閲覧の有無、これまでの購 買単価の平均値などを、会員ごとに示したデータとなっています。 (仮想のデータです)
13.
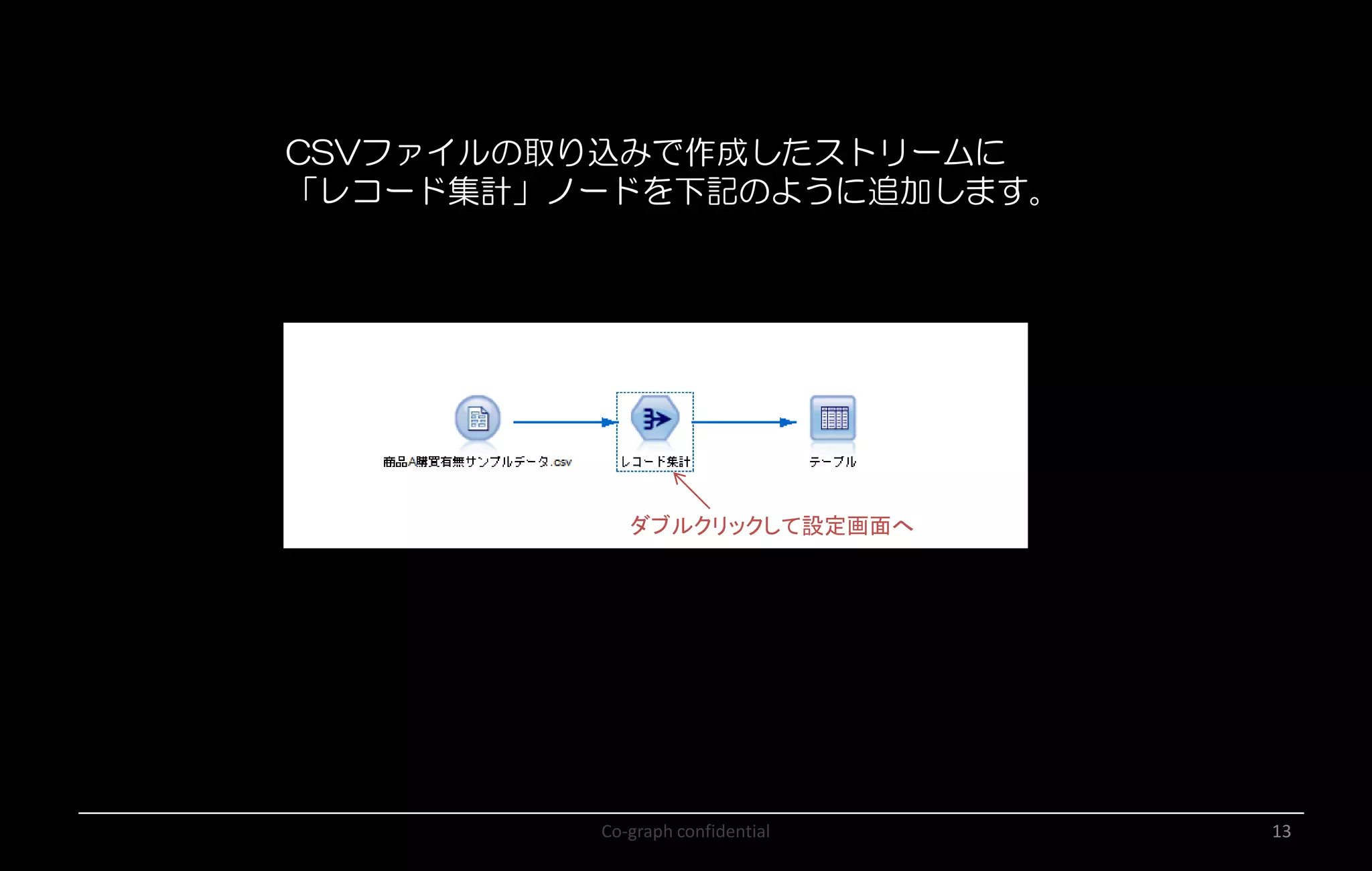
Co-graph confidential 13 CSVファイルの取り込みで作成したストリームに 「レコード集計」ノードを下記のように追加します。 ダブルクリックして設定画面へ
14.
Co-graph confidential 14 「レコード集計」ノードをダブルクリックして編集します。 今回は「キーフィールド」と「集計フィールド」を下記のように 設定します。 (解説と実行結果は次ページです)
15.
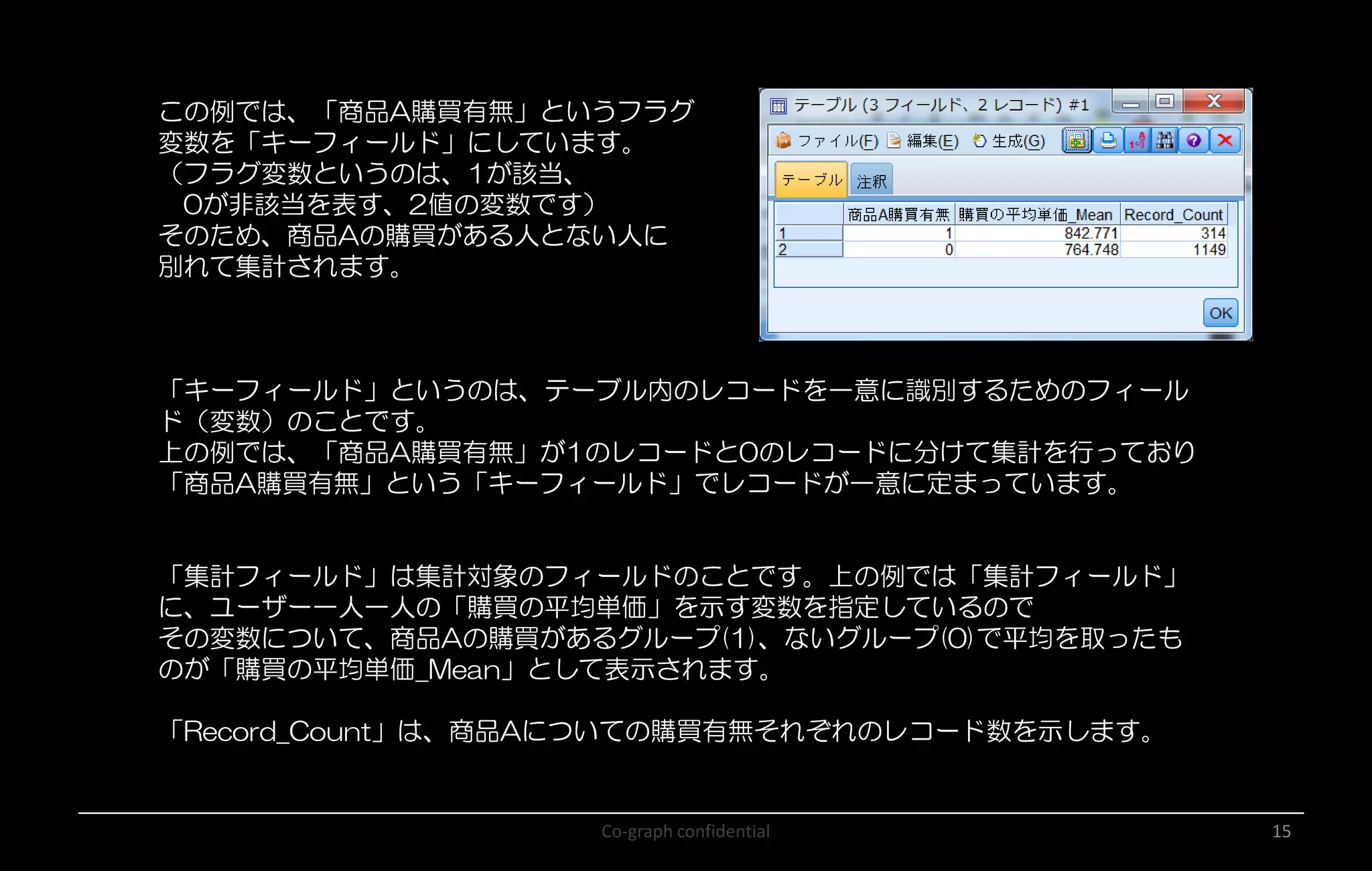
Co-graph confidential 15 この例では、「商品A購買有無」というフラグ 変数を「キーフィールド」にしています。 (フラグ変数というのは、1が該当、 0が非該当を表す、2値の変数です) そのため、商品Aの購買がある人とない人に 別れて集計されます。 「キーフィールド」というのは、テーブル内のレコードを一意に識別するためのフィール ド(変数)のことです。 上の例では、「商品A購買有無」が1のレコードと0のレコードに分けて集計を行っており 「商品A購買有無」という「キーフィールド」でレコードが一意に定まっています。 「集計フィールド」は集計対象のフィールドのことです。上の例では「集計フィールド」 に、ユーザー一人一人の「購買の平均単価」を示す変数を指定しているので その変数について、商品Aの購買があるグループ(1)、ないグループ(0)で平均を取ったも のが「購買の平均単価_Mean」として表示されます。 「Record_Count」は、商品Aについての購買有無それぞれのレコード数を示します。
16.
Co-graph confidential 16 次は… 複数のデータを結合してみましょう
17.
Co-graph confidential 17 「レコード結合」ノードは、2つ以上のデータを特定のフィールド(変数)をキーにして結合 するときに使います。 下記の2つのCSVデータを例にしてご説明します。 これらは商品ごとの値段のデータ(price.csv)と発売年のデータ(year.csv)を想定しています。
18.
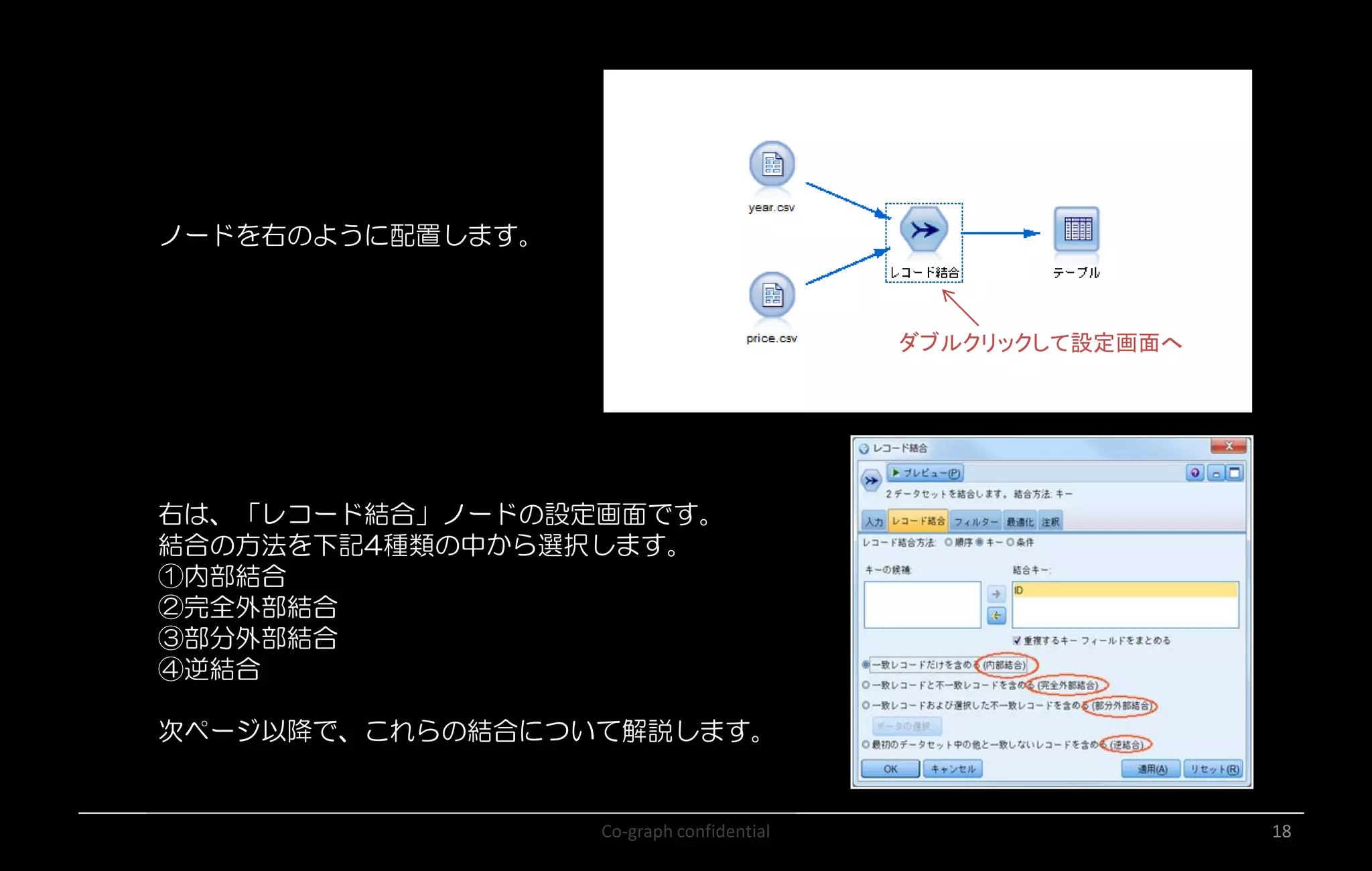
Co-graph confidential 18 ノードを右のように配置します。 右は、「レコード結合」ノードの設定画面です。 結合の方法を下記4種類の中から選択します。 ①内部結合 ②完全外部結合 ③部分外部結合 ④逆結合 次ページ以降で、これらの結合について解説します。 ダブルクリックして設定画面へ
19.
Co-graph confidential 19 ①内部結合 内部結合は、両方のCSVで、結合キー(ID)が一致する レコードだけを取得する結合方法です。 この場合、右のように出力されます。 値段は、元のcsvには下記4商品についてレコードが 存在しました。 【price.csv:1,2,3,5】 一方、発売年については、下記3商品について レコードが存在しました。 【year.csv
:1,2,4】 内部結合では、両方に共通してIDが存在するレコード を取得しますので、下記2つが出力されます。 【内部結合後→1,2】
20.
Co-graph confidential 20 ②完全外部結合 内部結合での結果に加えて、どちらかのCSVにしか 存在しないレコードも取得するのが完全外部結合です。 完全外部結合では右のようになります。 元の各csvファイルのIDは下記です。 【price.csv:1,2,3,5】 【year.csv
:1,2,4】 結合後のIDは下記となります。 【完全外部結合後→1,2,3,4,5】 IDの3~5は片方のcsvにしか存在しないため、取得で きないデータ(欠損値)が発生します。 Modeler上では、欠損値は「$null$」と表示されます。
21.
Co-graph confidential 21 ③部分外部結合 選択したCSVのレコードをすべて取得す るのが、部分外部結合です。 部分外部結合では、右のような選択画面が 表示されます。 price.csvを選択すると、price.csvに含ま れるすべてのレコードが取得されます。 この場合、year.csvにもIDが存在するレ コードには、yearの値が入り、それ以外は 欠損値となります。 元の各csvファイルのIDは下記です。 【price.csv:1,2,3,5】 【year.csv
:1,2,4】 結合後のIDは下記となります。 【部分外部結合後→1,2,3,5】
22.
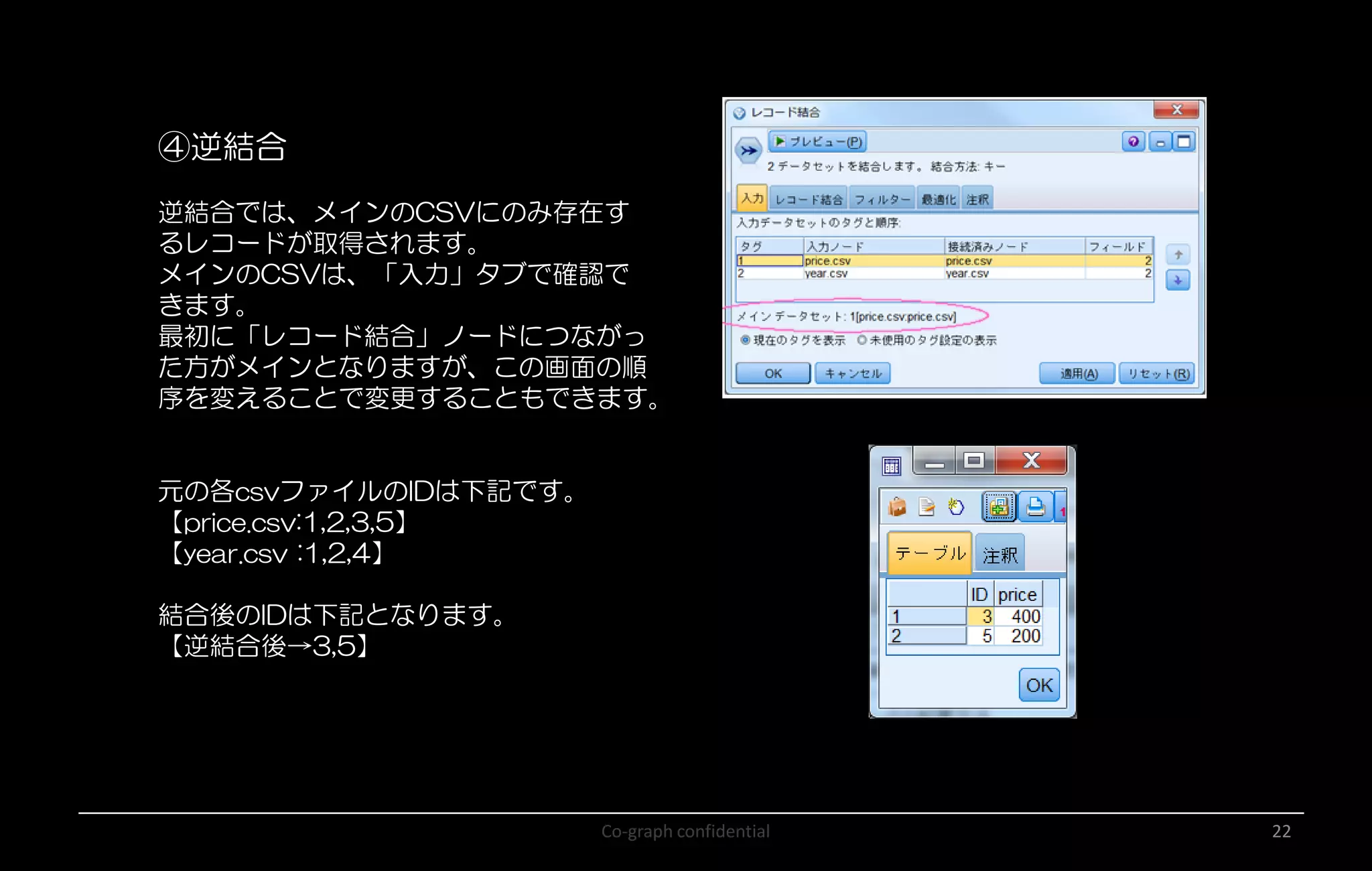
Co-graph confidential 22 ④逆結合 逆結合では、メインのCSVにのみ存在す るレコードが取得されます。 メインのCSVは、「入力」タブで確認で きます。 最初に「レコード結合」ノードにつながっ た方がメインとなりますが、この画面の順 序を変えることで変更することもできます。 元の各csvファイルのIDは下記です。 【price.csv:1,2,3,5】 【year.csv
:1,2,4】 結合後のIDは下記となります。 【逆結合後→3,5】
23.
Co-graph confidential 23 本スライドで使用しているサンプルデータと ストリームファイルは、「コグラフ公式テクニカルWeb」から ダウンロードできます。 「コグラフ公式テクニカルWeb」には、本スライドに 記載しきれなかった情報もたくさんありますので是非ご覧ください。 http://www.co-graph.net/ 本スライドは以上となります。 ご覧頂き、ありがとうございました。
Download