Download as PDF, PPTX





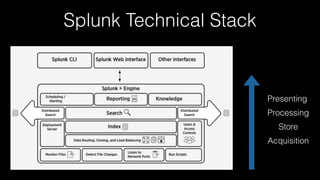
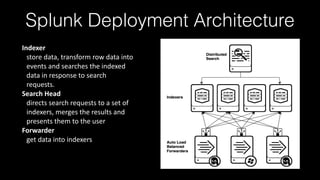

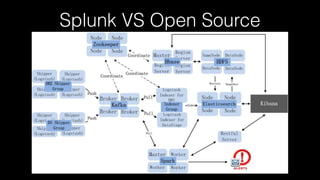

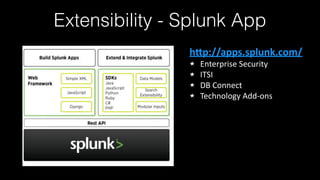

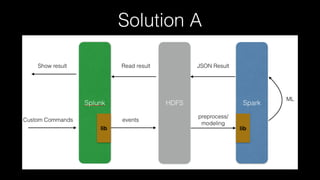
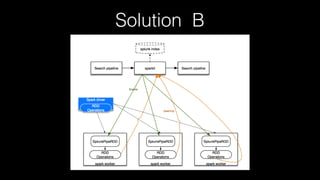
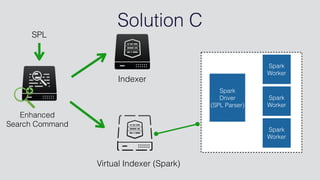


This document discusses Splunk Spark Integration. It provides an overview of Splunk including its products, customers, and deployment architecture. It then discusses the benefits of integrating Splunk with Spark, including leveraging Spark's powerful computing capabilities for machine learning while indexing unstructured data in Splunk. Finally, it presents three potential solutions for the integration and some challenges to address like avoiding moving large amounts of data and maintaining a good user experience while adapting to Splunk's query language.






![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)






































































